
03Linux与Hadoop操作实验
《大数据应用技术》实验1
第二章 熟悉常用的Linux操作和Hadoop操作
1.实验目的
- 为后续上机实验做准备,熟悉常用的Linux操作和Hadoop操作。
2.实验平台
操作系统:Linux
Hadoop版本:2.7.1
3.实验内容和要求
(一)熟悉常用的Linux操作
请按要求上机实践如下linux基本命令。
cd命令:切换目录
(1)切换到目录 /usr/local :cd /usr/local
(2)去到目前的上层目录 :cd ..
(3)回到自己的主文件夹 :cd ~
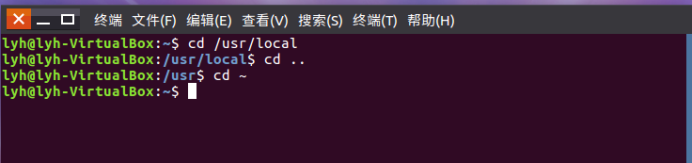
ls命令:查看文件与目录
(4)查看目录/usr下所有的文件 :ls -all ~
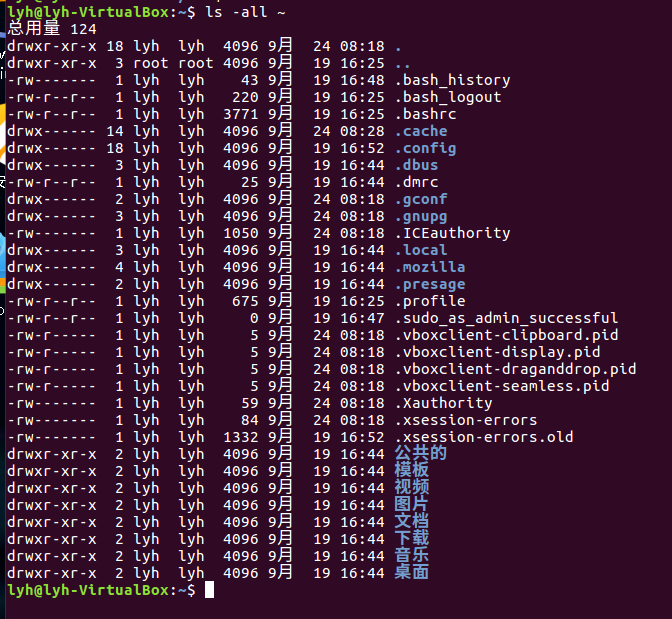
mkdir命令:新建新目录
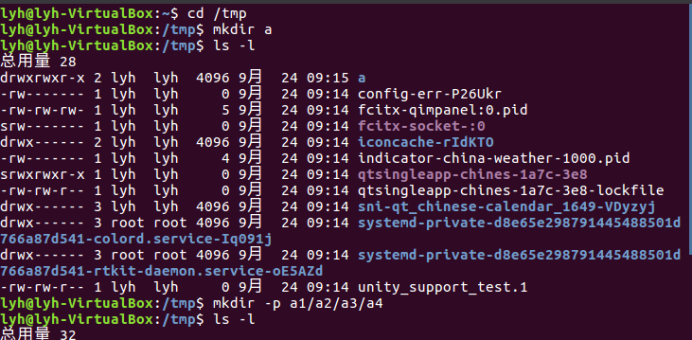
(5)进入/tmp目录,创建一个名为a的目录,并查看有多少目录存在:cd /tmp
mkdir a
ls -l
(6)创建目录a1/a2/a3/a4:mkdir -p a1/a2/a3/a4
rmdir命令:删除空的目录
(7)将上例创建的目录a(/tmp下面)删除 :rmdir a/
(8)删除目录a1/a2/a3/a4,查看有多少目录存在 :rmdir -p a1/a2/a3/a4
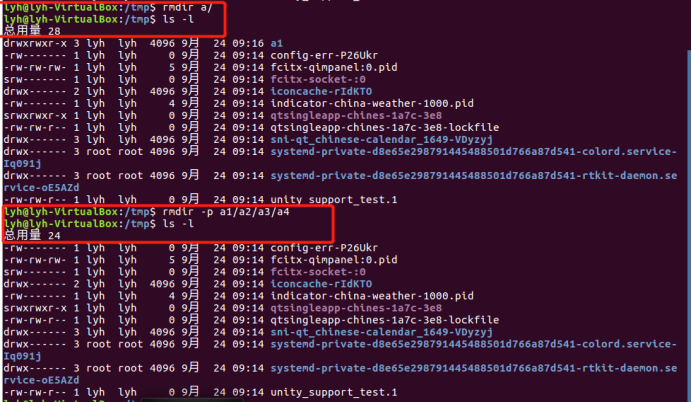
ls -l
cp命令:复制文件或目录
(9)将主文件夹下的.bashrc复制到/usr下,命名为bashrc1
sudo cp ~/.bashrc /usr/bashrc1
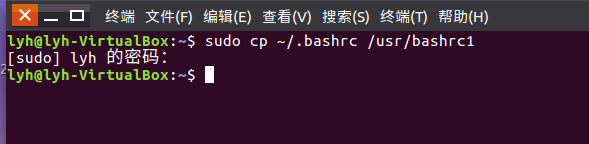
(10)在/tmp下新建目录test,再复制这个目录内容到/usr
cd /tmp
mkdir test
sudo cp -r /tmp/test /usr

mv命令:移动文件与目录,或更名
(11)将上例文件bashrc1移动到目录/usr/test
Cd /usr
Sudo cp /usr/bashrc1 /usr/test

(12)将上例test目录重命名为test2
Sudo mv test test2

rm命令:移除文件或目录
(13)将上例复制的bashrc1文件删除
Sudo rm brashrc1

(14)将上例的test2目录删除
Sudo rm -r test2

cat命令:查看文件内容
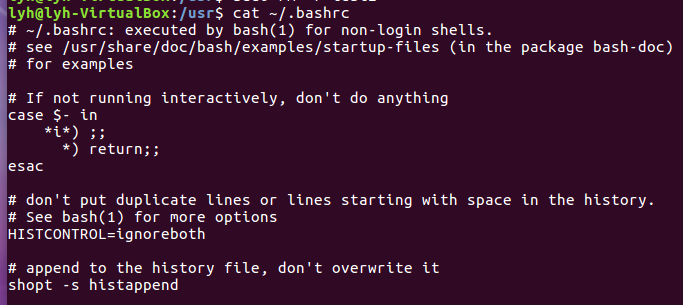
(15)查看主文件夹下的.bashrc文件内容
Cat ~/.bashrc
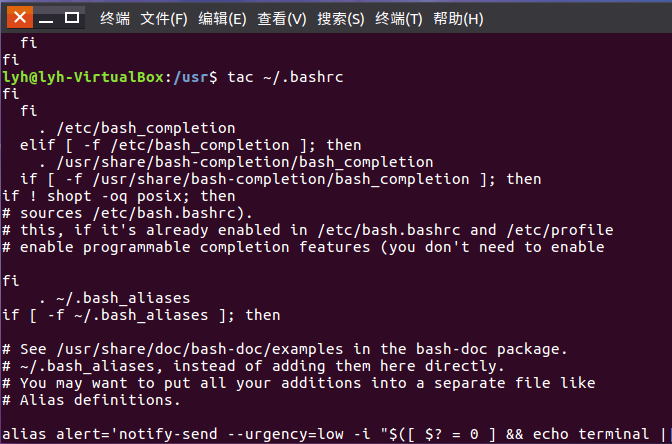
tac命令:反向列示
(16)反向查看主文件夹下.bashrc文件内容
Tac ~/.bashrc
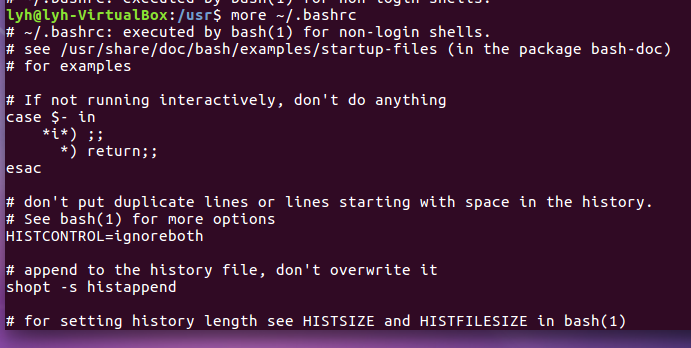
more命令:一页一页翻动查看
(17)翻页查看主文件夹下.bashrc文件内容
More ~/.bashrc
head命令:取出前面几行
(18)查看主文件夹下.bashrc文件内容前20行
Head -n 20 ~/.bashrc
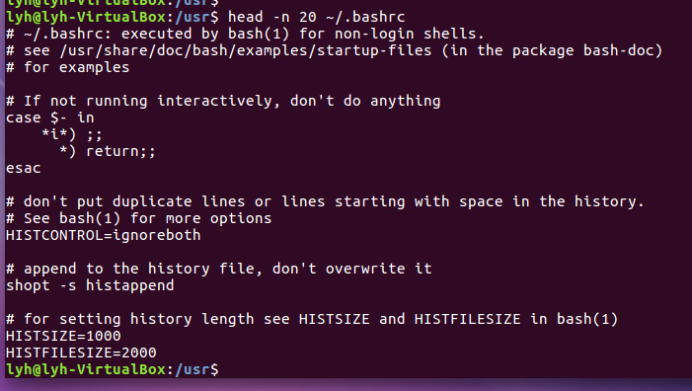
(19)查看主文件夹下.bashrc文件内容,后面50行不显示,只显示前面几行
Head -n -50 ~/.bashrc
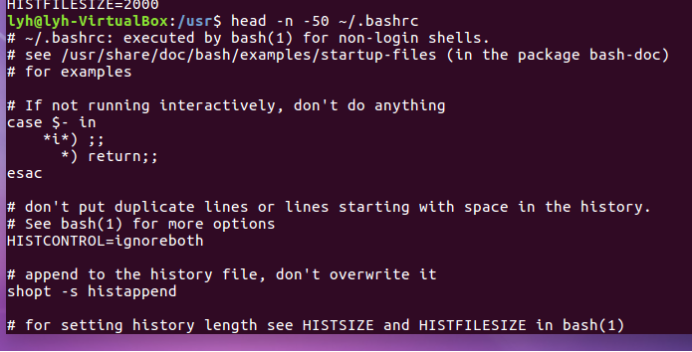
tail命令:取出后面几行
(20)查看主文件夹下.bashrc文件内容最后20行
Tail -n 20 ~/.bashrc
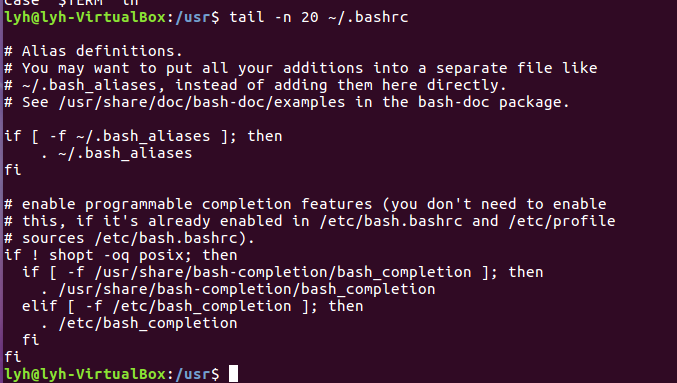
(21)查看主文件夹下.bashrc文件内容,只列出50行以后的数据
Tail -n +50 ~/.bashrc
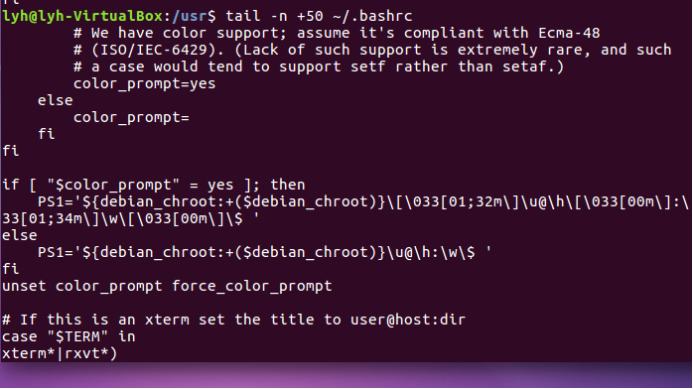
chown命令:修改文件所有者权限
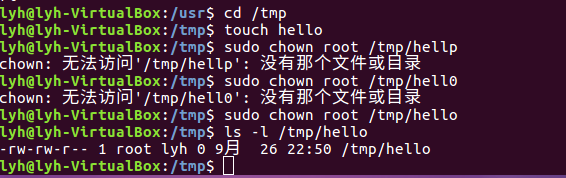
(22)将hello文件所有者改为root帐号,并查看属性
Cd /tmp
Touch hello
Sudo chown root /tmp/hello
Ls -l /tmp/hello
Vim/gedit/文本编辑器:新建文件
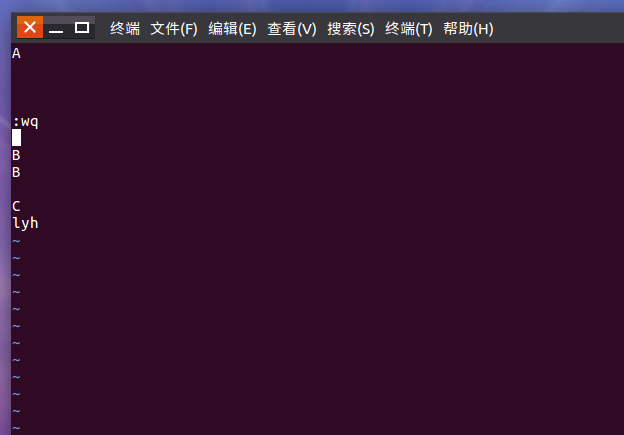
(23)在主文件夹下创建文本文件my.txt,输入文本保存退出。
Vi ~/my.txt
:wq

tar命令:压缩命令
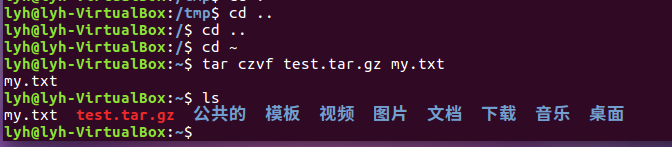
(24)将my.txt打包成test.tar.gz
Cd ..
Cd ~
Tar czvf test.tar.gz my.txt
ls
(25)解压缩到~/tmp目录
Mkdir tmp
Tar -zxvf test.tar.gz -C ~/tmp

(二)熟悉使用MySQL shell操作
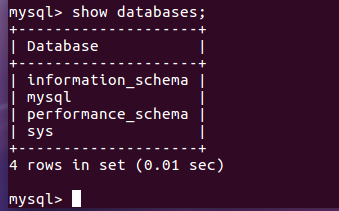
(26)显示库:show databases;
(27)进入到库:use 库名;

(28)展示库里表格:show tables;
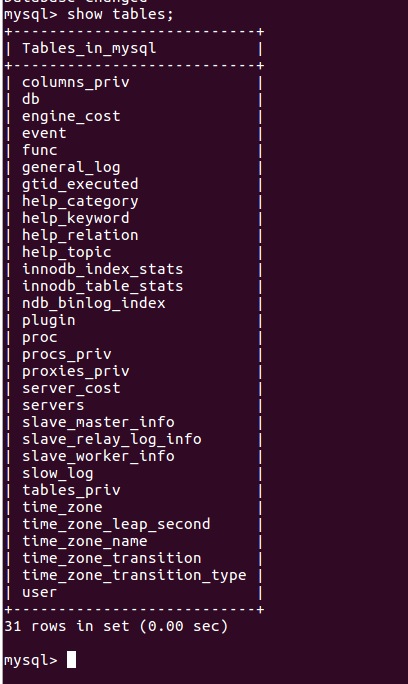
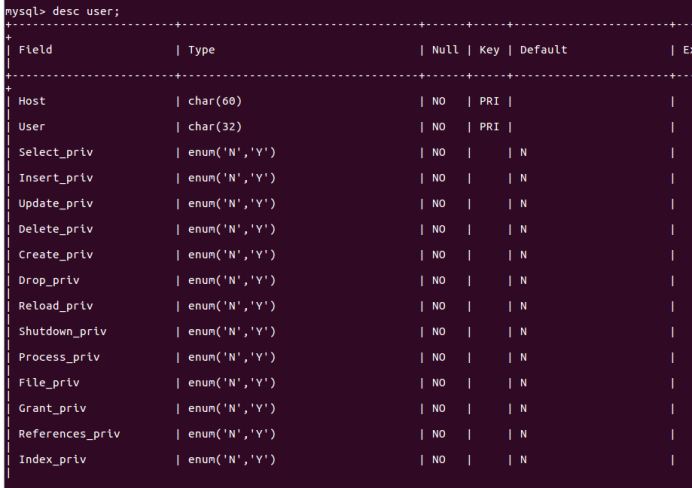
(29)显示某一个表格属性:desc 表格名;
desc user;
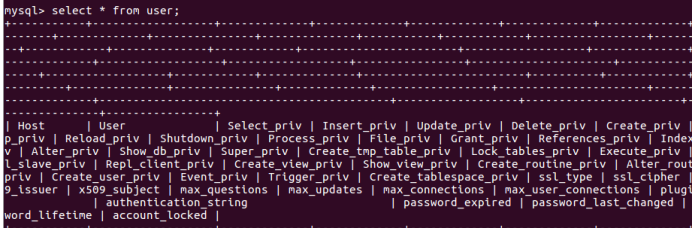
(30)显示某一个表格内的具体内容:select *form 表格名;
select * from user;
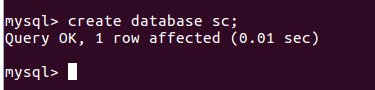
(31)创建一个数据库:create databases sc;
(32)在sc中创建一个表格:create table if not exists student(id varchar(30),name varchar(60))character set utf 8;

(33)向表格student中插入具体内容:insert into 表格名(名)values(value);
插入记录包含自己的学号姓名。
Insert into student values(“201906110097”,”lyh”);

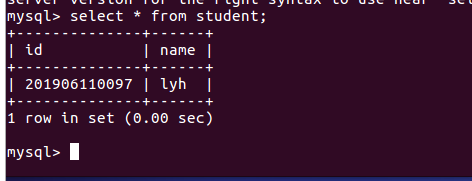
(33)显示表的内容。
Select * from student;
(三)熟悉Hadoop及其操作
34.用图文与自己的话,简要描述Hadoop起源与发展阶段。
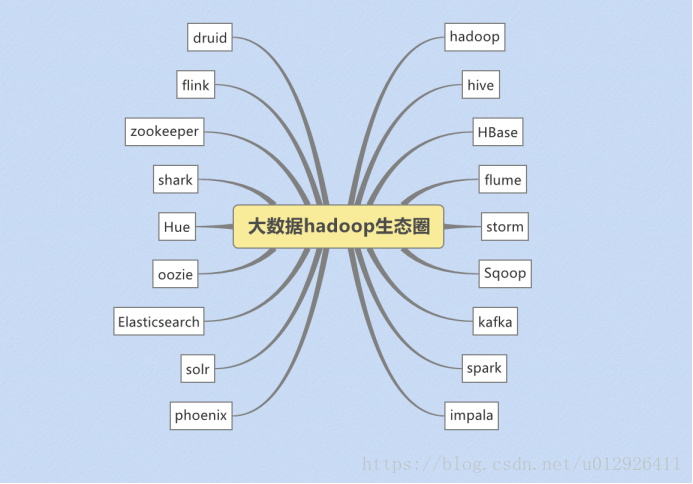
起源:hadoop实现在大量计算机组成的集群中对海量数据进行分布式计算。适合大数据的分布式存储和计算平台。
发展阶段:
-
2002~2004
当时第一轮互联网泡沫刚刚破灭, 一个对搜索引擎特别了解但是同时又失去工作的屌丝
Doug Cutting(1), 当时主要靠写点技术专栏文章赚赚稿费。同时, 他联合了另外一个RD
Mike Cafarella, 当时两人觉得以后搜索被一个大公司给一统天下是一个很可怕的事情, 这家公司掌握信息入口, 能翻手为云覆手为雨。所以决定自己搞一个开源的搜索引擎出来, 于是说干就干, 干了个项目叫
Nutch。两人吭哧吭哧干了一年之后, 终于把这个系统干到能支持1亿网页的抓取, 索引和搜索了。但是当时的网站差不多就有10亿, 网页数量是万亿这个规模。这两哥们也没多想, 就是干, 继续把网页量给干到下一个数量级。
-
2004~2006
结果很不巧, 在那个时候, Google公布了GFS和MapReduce两篇Paper。这两哥们一看, 完了, 这两年白干了, 人家干得那才是漂亮, 自己现在干得实在是太苦逼了, 所有工作都处于人肉运维的状态。
那咋办呢, 重构呗, 咋重构啊, 抄一个呗。于是就开始抄GFS和MapReduce, Google用的C++做, 他们用的Java做。到2004年的时候, 已经差不多能在40台左右的机器上运行了。
-
2006以后
Dog Cutting跟好多我们同龄人一样, 做了几年公司, 发现干也干不过google了, 好像创业没啥前途了, 那咋办呢, 就找个大公司吧。这哥们本来一开始想去IBM, 但是人家IBM要做lucene, 不用Nutch。这哥们表示不开心, 就去问Yahoo愿不愿意要Nutch, 人家Yahoo有自己的搜索引擎, 也不愿意要Nutch。不过Yahoo考虑了一下, 说虽然不要你的搜索系统, 但是你底层那几个GFS/MapReduce那些东西还是挺有用的嘛, 要不你过来弄这个?Dog Cutting也就从了, 于是把底层系统剥离出来, 把自己儿子的一个大象的玩具的名字Hadoop赋予了这个项目。但是到目前为止, Hadoop其实还不能称之为一个独立的大数据项目, 顶多只能称之为一个搜索系统的子项目, 因为他只有一个应用方, 就是搜索。
-
2006~
当系统进入yahoo了以后, 项目逐渐发展并成熟了起来。首先是集群规模, 从最开始的几十台机器的规模发展到能支持上千个节点的机器, 中间做了很多工程性质的工作, 然后是除搜索以外的业务放, yahoo逐步将自己的广告系统的数据挖掘相关工作也迁移到了hadoop上面来, 进一步成熟化了hadoop系统。
当有多个用户方在使用hadoop系统的时候, 又必须要增加qos调度队列等机制, 也必须要增加数据安全认证授权机制等等, 各种功能都加到hadoop上面来的时候, hadoop就算是真正成熟起来了。必须要称道的一点是, 在成熟化整个系统的过程当中, yahoo一直都将hadoop做成一个开源软件, 而不是自己的私有软件。
35.对比操作三个文件系统:分别用命令行与窗口方式查看windows,Linux和Hadoop的文件系统的用户主目录。
localhost:50070
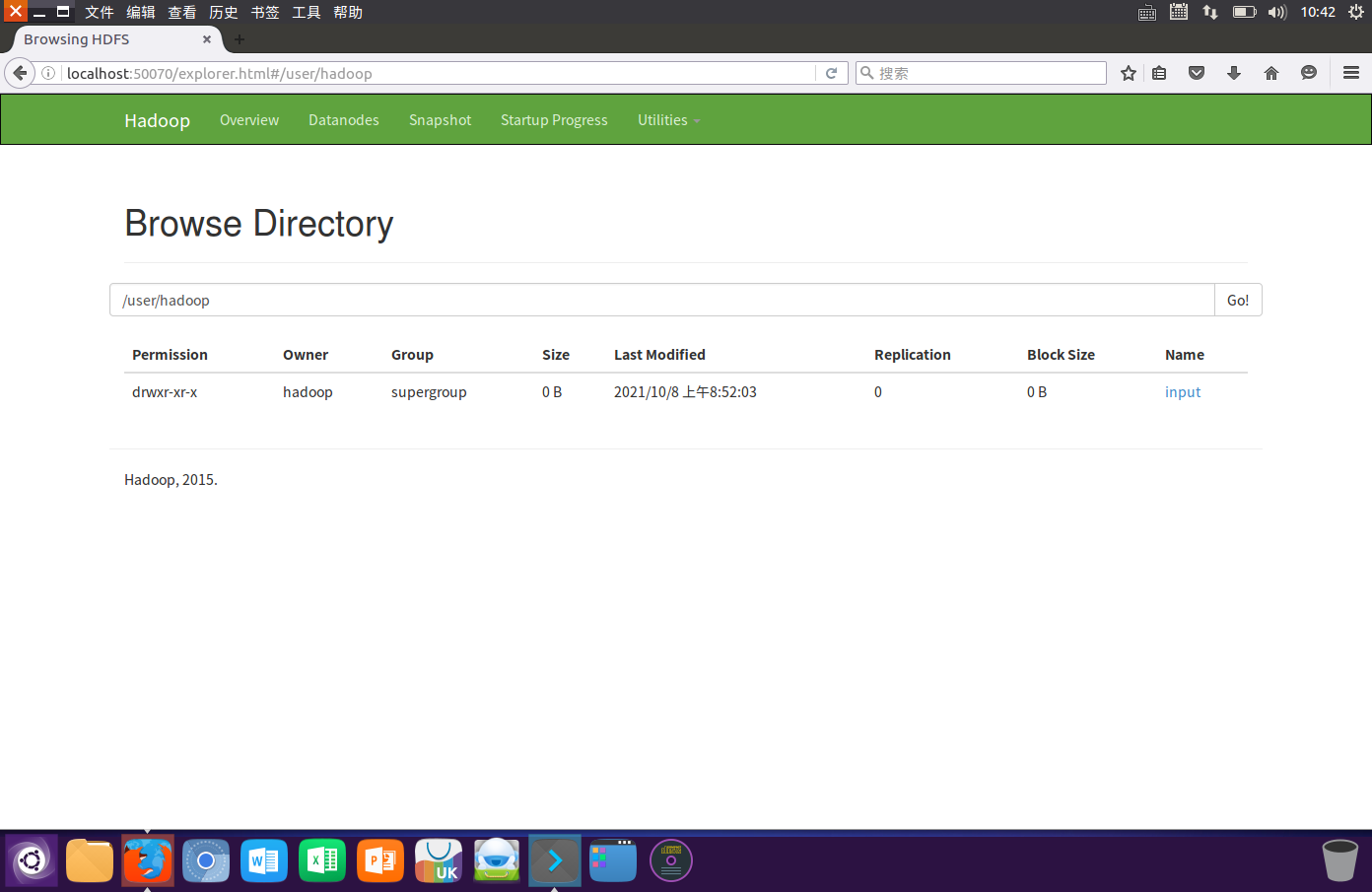
cd /usr/local/hadoop
./sbin/hdfs-dfs.sh.
./bin/hdfs dfs -ls /

36.一个操作案例:
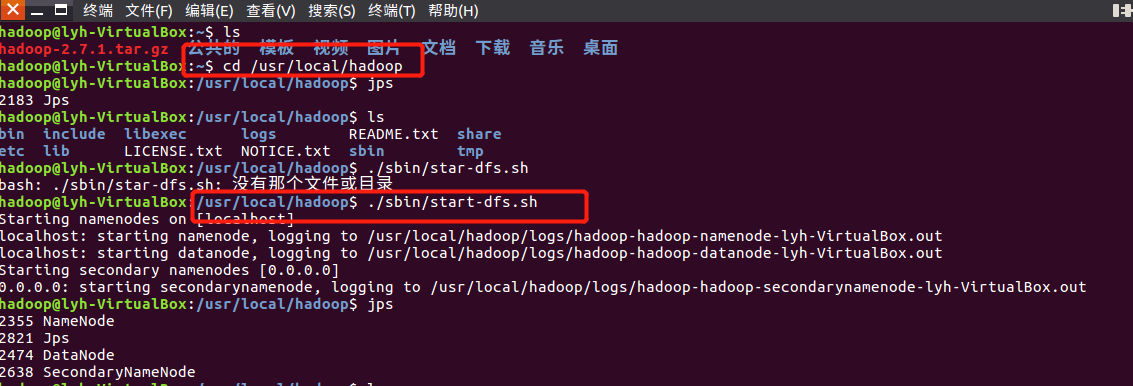
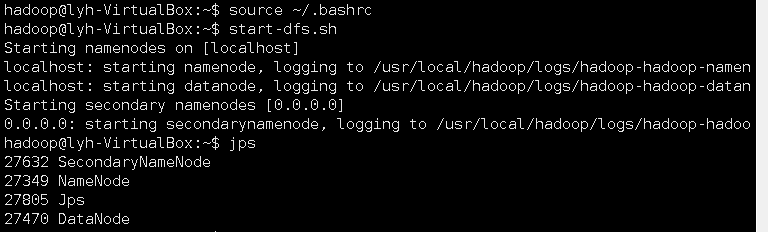
- 启动hdfs :cd /usr/local/hadoop
./sbin/start-dfs.sh![]()
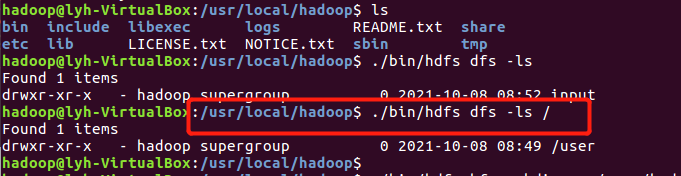
- 查看与创建hadoop用户目录。
./bin/hdfs dfs -ls /![]()
![]()
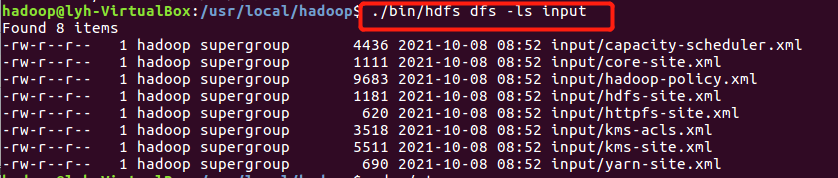
- 在用户目录下创建与查看input目录。
![]()
查看:./bin/hdfs dfs -ls input
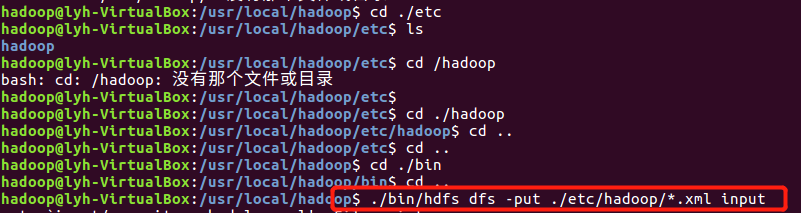
- 将hadoop的配置文件上传到hdfs上的input目录下。
![]()
![]()
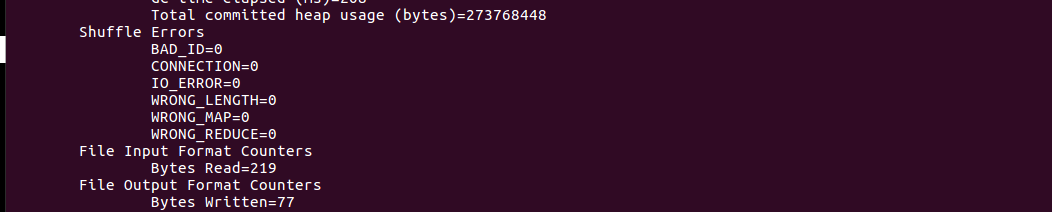
- 运行MapReduce示例作业,输出结果放在output目录下
![]()
![]()
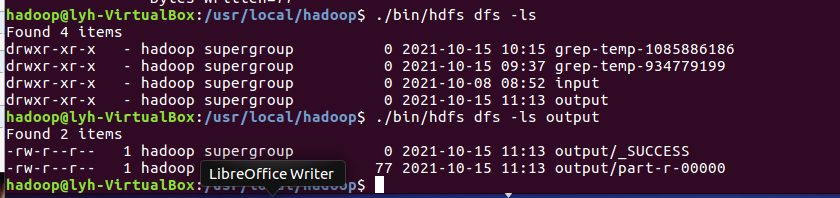
- 查看output目录下的文件
![]()
- 查看输出结果
![]()
- 将输出结果文件下载到本地。
![]()
- 查看下载的本地文件。
![]()
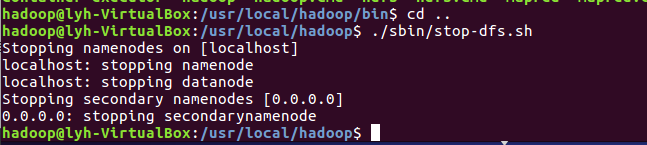
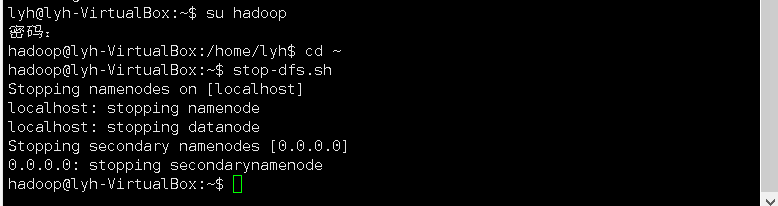
- 停止hdfs.
![]()
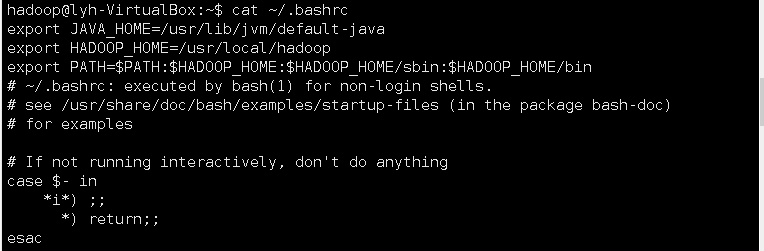
37、设置Hadoop环境变量,在本地用户主目录下启动hdfs,查看hdfs用户主目录,停止hdfs。
![]()
![]()
关闭:
![]()







 浙公网安备 33010602011771号
浙公网安备 33010602011771号