数据库相关知识总结
concat可以拼接字段:
比如select concat(name,':',salary) from .....
当然拼接的字段我们也可以起个别名:
select concat(name,':',salary) as NameSalary from .....
string的空格处理:
链接:https://www.cnblogs.com/redb52/p/3245507.html
MyVar = RTrim(" vbscript "),MyVar 包含 " vbscript" ---返回不带后空格
三种连接:
1. 自然连接(natural join)
自然连接是一种特殊的等值连接,他要求两个关系表中进行连接的必须是相同的属性列(名字相同),无须添加连接条件,并且在结果中消除重复的属性列。
Select * from table1 natural join table2
结果: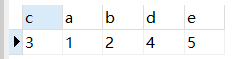
2. 内连接(inner join)
内连接基本与自然连接相同,不同之处在于自然连接的是同名属性列的连接,而内连接则不要求两属性列同名,可以用using或on来指定某两列字段相同的连接条件。
Select * from table1 inner join table2 on table1.A=table2.E
结果: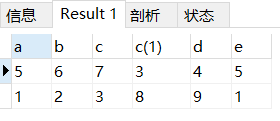
自然连接时某些属性值不同则会导致这些元组会被舍弃,那如何保存这些会被丢失的信息呢,外连接就解决了相应的问题。外连接分为左外连接、右外连接、全外连接。外连接必须用using或on指定连接条件。
3.1左外连接(left outer join,outer可以省略)
左外连接是在两表进行自然连接,只把左表要舍弃的保留在结果集中,右表对应的列上填null。
Select * from table1 left outer join table2 on table1.C=table2.C
结果:
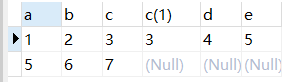
3.2右外连接(rignt outer join,outer可以省略)
右外连接是在两表进行自然连接,只把右表要舍弃的保留在结果集中,左表对应的列上填null。
right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
Select * from table1 right outer join table2 on table1.C=table2.C
结果: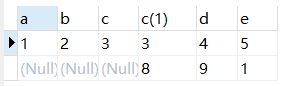
mysql的默认join就是inner join,如果不加on条件的话,join和inner join都相当于笛卡尔积。但natural join和他们不同,不需要加on条件,而是会自动去找相同的属性去进行连接。
三种join不带on:
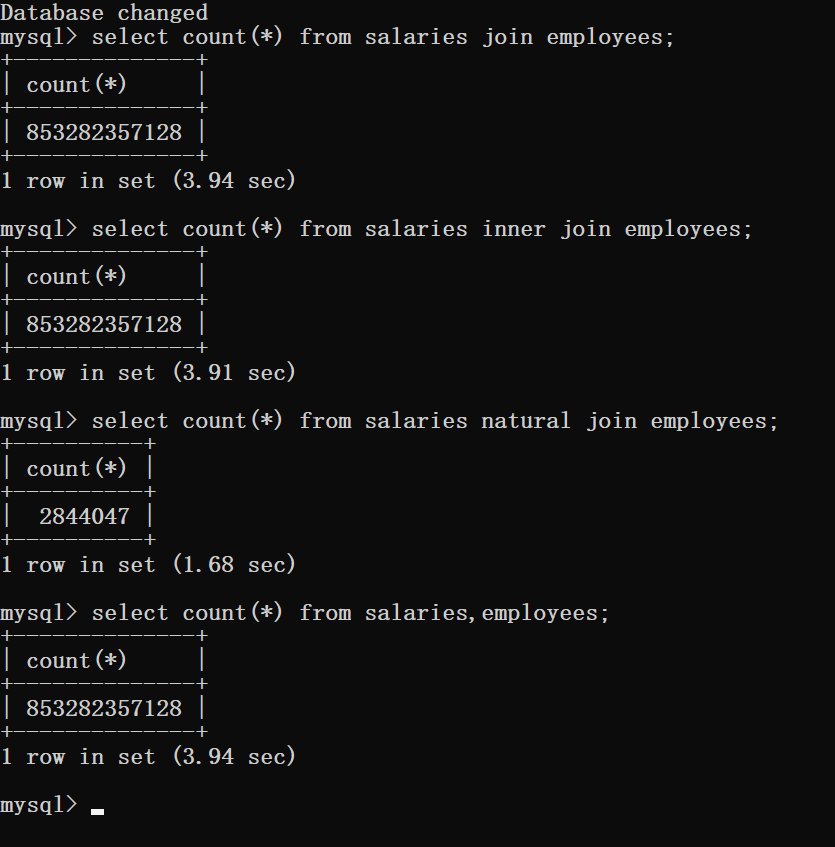
三种join带on(自然连接不能带):
实际上,上面join和inner join查询的时间和直接用笛卡尔积再筛选的from where语句时间相同:

但是我们尽量在多表连接时还是要使用join,毕竟join前面说了,本质背后的方法是Nested Loops,Hash Join 和 Sort Merge Join。但where一定是先笛卡尔积再筛选的。所以where也许会接近join的时间,但join一定不比where操作的时间长。另外join的条件如果写错了还会报错,这样可以方便我们查错。
多个select语句结果进行union操作时,会自动去掉重复行。如果想保留重复行可以用union all。
数据库三范式:
第一范式:属性不能分割,比如你不能定义一个个人信息的属性,因为显然应该至少分成名字、住址、学校等等。
第二范式:首先满足第一范式的前提下,整个表要有主键,别的属性依赖于主键。
第三范式:首先满足第二范式的前提下,表的非主属性互相之间不能有传递依赖。举个栗子:主键是学生学号,另外有两个属性,该学生的班主任名字和班号。显然班主任名字依赖于班号,那么班主任和班号就应该存在另一张表里。
数据库索引:
主键索引,就是主键,不需要额外建立,只要表里有主键,默认的索引就是主键索引。
唯一索引:如果是单属性,那么这个属性所有的行都不一样(可以有NULL)。如果是多属性,那么这些属性的组合所有的行都不一样。
唯一索引本质上是辅助索引,然后加了唯一约束。
CREATE UNIQUE INDEX indexName ON mytable(username(length))
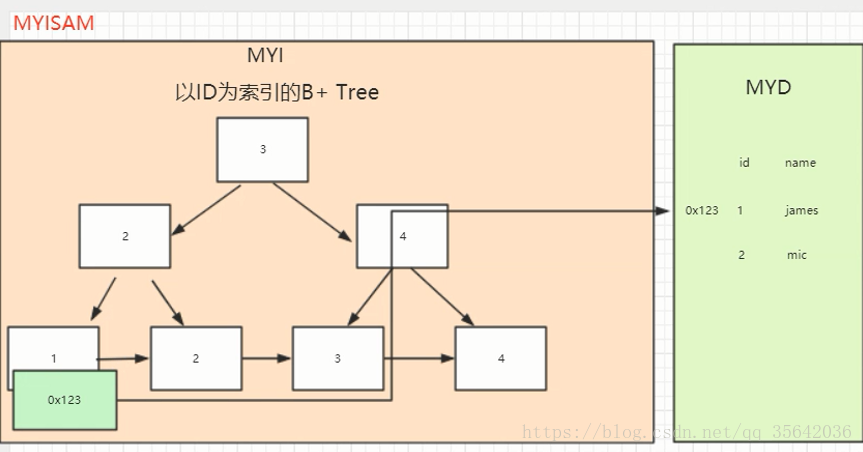
聚集索引:数据库物理上存储数据的顺序就是聚集索引的顺序。由于数据库物理存储顺序只有一种(还有什么好说),所以聚集索引也最多一个!
不同数据库引擎实现不同,myisam引擎没有聚集索引概念。innodb默认主键是聚集索引,如果没有主键,则非空的索引是聚集索引,如果都没有则生成一个隐藏列为聚集索引。
FULLTEXT(全文索引):ALTER TABLE 'table_name' ADD FULLTEXT('col')
仅可用于MyISAM和InoDB,针对较大的数据,生成全文索引很耗时耗空间
哈希索引:memory引擎默认使用的索引,不支持范围查询。
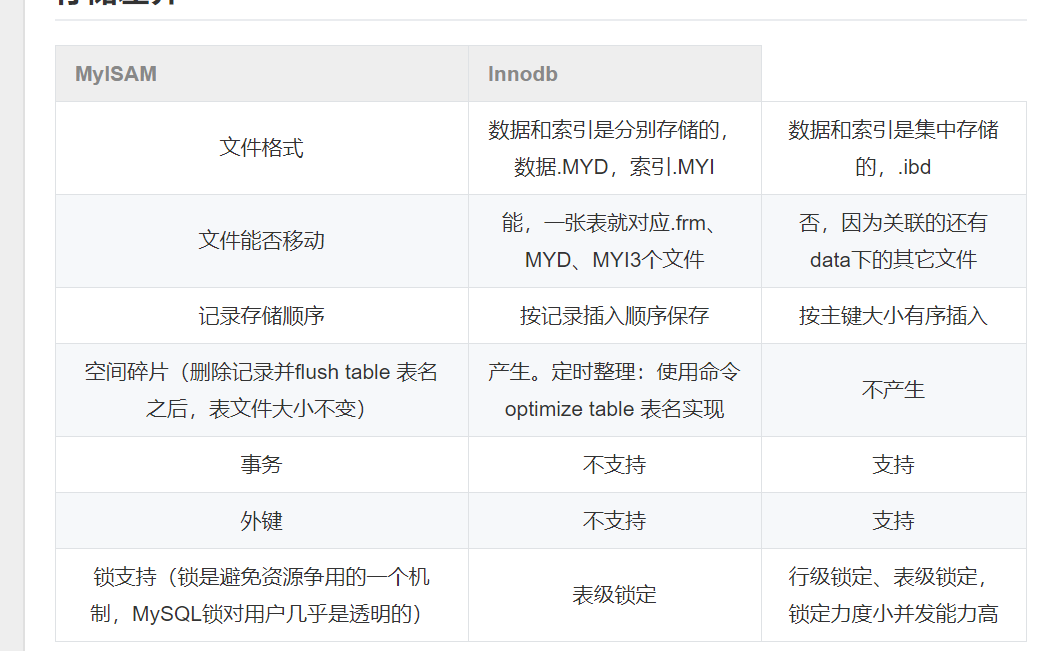
顺便记录一下myisam和innodb引擎的区别:
1. InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
2. InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
3. InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。
二者的结构图:
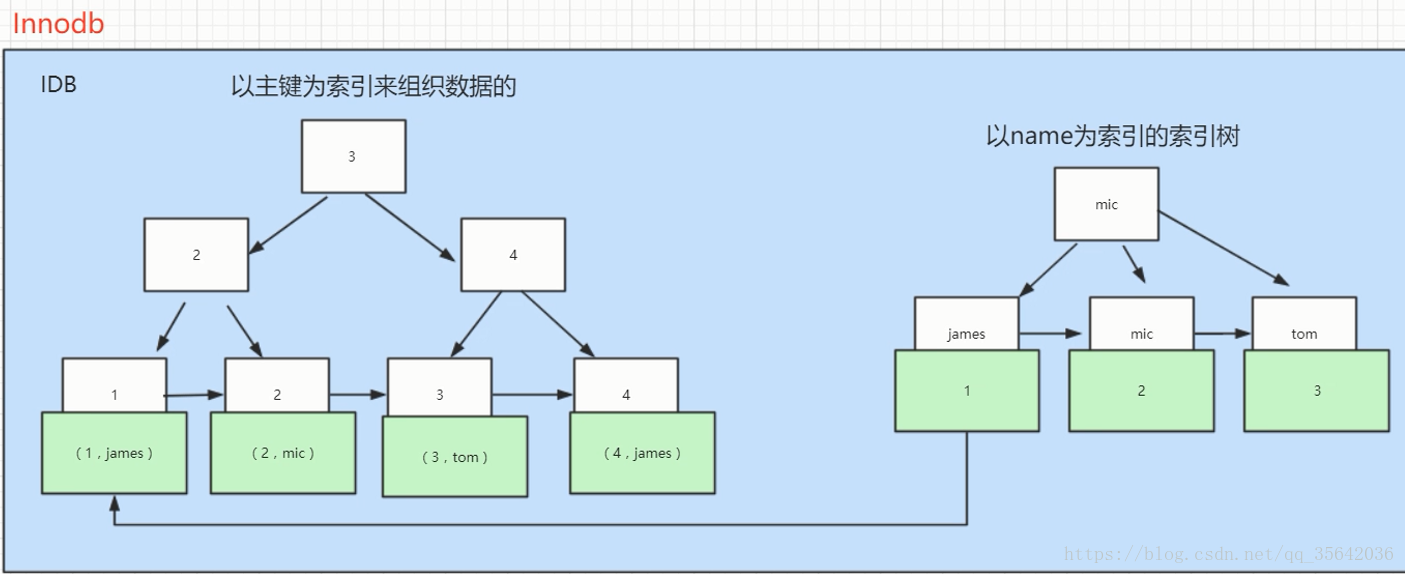
二者的区别:
另外还有一个memory引擎:
MEMORY是MySQL中一类特殊的存储引擎。它使用存储在内存中的内容来创建表,而且数据全部放在内存中。这些特性与前面的两个很不同。
每个基于MEMORY存储引擎的表实际对应一个磁盘文件。该文件的文件名与表名相同,类型为frm类型。该文件中只存储表的结构。而其数据文件,都是存储在内存中,这样有利于数据的快速处理,提高整个表的效率。值得注意的是,服务器需要有足够的内存来维持MEMORY存储引擎的表的使用。如果不需要了,可以释放内存,甚至删除不需要的表。
MEMORY默认使用哈希索引。速度比使用B型树索引快。当然如果你想用B型树索引,可以在创建索引时指定。
注意,MEMORY用到的很少,因为它是把数据存到内存中,如果内存出现异常就会影响数据。如果重启或者关机,所有数据都会消失。因此,基于MEMORY的表的生命周期很短,一般是一次性的。
查看索引:
show index from table;
主键索引和普通索引的区别:都是B+树结构,但是主键索引的叶子节点就是数据,而普通索引的叶子节点只是主键的值。即使用普通索引查找数据要两步:1.找普通索引的叶子节点,找到主键值。2.通过这个主键值去查找实际数据。实际上这个查询过程的名字叫回表。
简单来说就是数据库根据索引找到了指定的记录所在行后,还需要根据主键号再次到数据块里取数据的操作。
比如这样的执行计划,先索引扫描,再通过rowid去取索引中未能提供的数据,即为回表。
“回表”一般就是指执行计划里显示的“TABLE ACCESS BY INDEX ROWID”。
再例如,虽然只查询索引里的列,但是需要回表过滤掉其他行。
怎么避免回表?
将需要的字段放在索引中去。查询的时候就能避免回表。
但是不要刻意去避免回表,那样代价太了。也不是将所有的字段都放在所有中
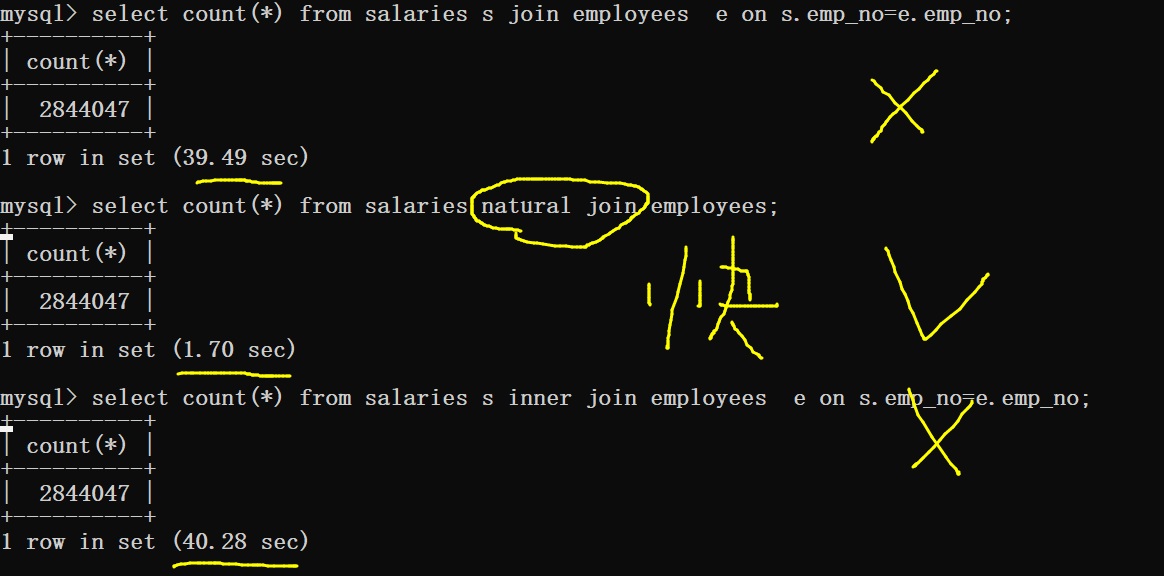
左右外连接使用索引的例子:
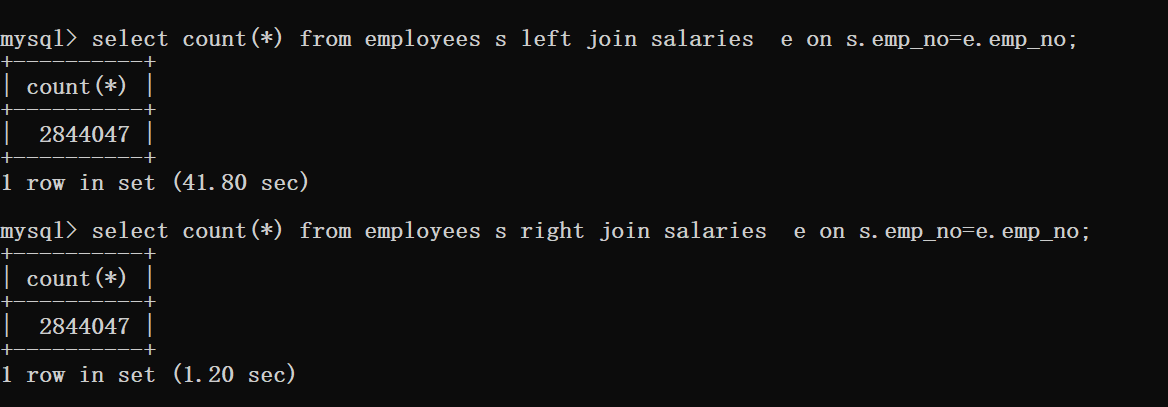
可以看到同样的查询,只是一个为左连接,一个是右连接,为什么性能差距这么大?且两个表中emp_no都是主索引。
两个表的长度:
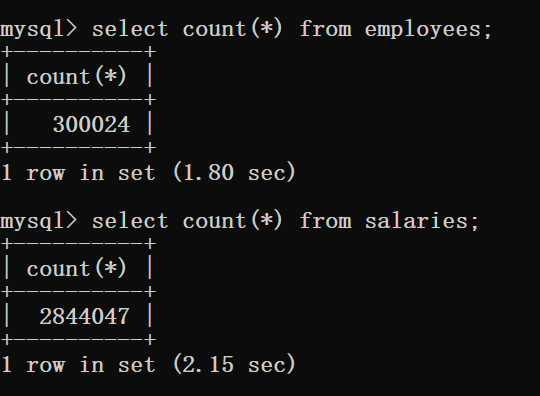
经过查询资料,a left join b是先把a的数据列出来,对于其中每一项去b里面找,当然这个过程是用了b的索引的。
所以对于employees left join salaries来说:employees表的索引没有使用,直接取employees中每一项去salaries中找对应项(会用到salaries的索引)。时间复杂度可以理解为300024乘以(2844047大小的b+树查询加内存交换时间)。
对于employees right join salaries,也就相当于salaries left join employees:salaries表的索引没有使用,直接取salaries中每一项去employees中找对应项(会用到employees的索引)。那么时间复杂度可以理解为2844047乘以(300024大小的b+树查询加内存交换时间)。
那应该是后者大的多,主要是括号里的因子更大,因为b+树的查询时间肯定不止线性增长。
这里我不能确定,网上一些答案也看不太懂,说得不明不白的,仅是自己推测!
Mysql优化方式:
字段设计:
尽量使用整型表示字符串
单表字段不宜过多
尽可能使用 not null
表设计:
要至少满足第三范式
选择innodb引擎(Mysql默认就是innodb引擎)
sql语法:
模糊查询不能%开头,效率太低
按照索引查找,注意最左匹配原则。
最左匹配原则:目前有索引 index(a,b):
a=1 and b=1 可以匹配;
b=2 and a=3可以匹配,因为引擎会自动优化你的查询语句,变为a=3 and b=2;
1<a<3 and b=3只能匹配到a,即a是可以利用索引的,但是b无法使用该索引,即对于复合索引来说,索引只能维持有效直到范围查询截止。原因很简单,因为数据是按b+树存的,相邻的a都在一起,所以对于a的范围查询可以使用索引。对于a的等值查询,即a确定的情况下,b值是有序的。但我们查询的a是一个范围查询,查出来的这些条目的b值并不是有序的!
比如:
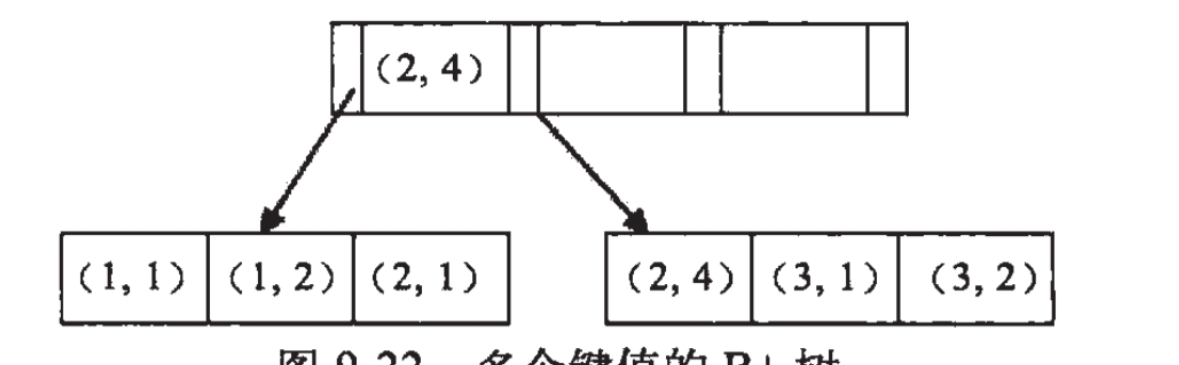
其中我们查询1<=a<=3 and b==1;
先查a,筛选出来的条目为:(1,1)、(1,2)、(2,1)、(2,4)、(3,1)、(3,2)。
显然其中的b值是1、2、1、4、1、2,并不是有序的,也就无法使用索引了。
分区:
如果数据表太大性能会下降,我们需要把一个大表分成多个小表。
视图只是虚拟的表,并不包含实际数据,所以对查询性能无甚影响。但是对于程序员来说,查询语句更清晰,并且可以指定用户能够查询的权限。
内外连接的区别:内连接只会筛选出两个表都符合条件的行,而外连接会保留不符合条件的行(左外连接保存左表,右外连接保存右表)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号