Redis数据结构
Redis: Remote Dictionary Service(远程字典服务)。主要存储键值对类型的数据,对于键(key) 来讲,只能是String类型的,而对于 值(value) 来讲,可以是其它的数据类型。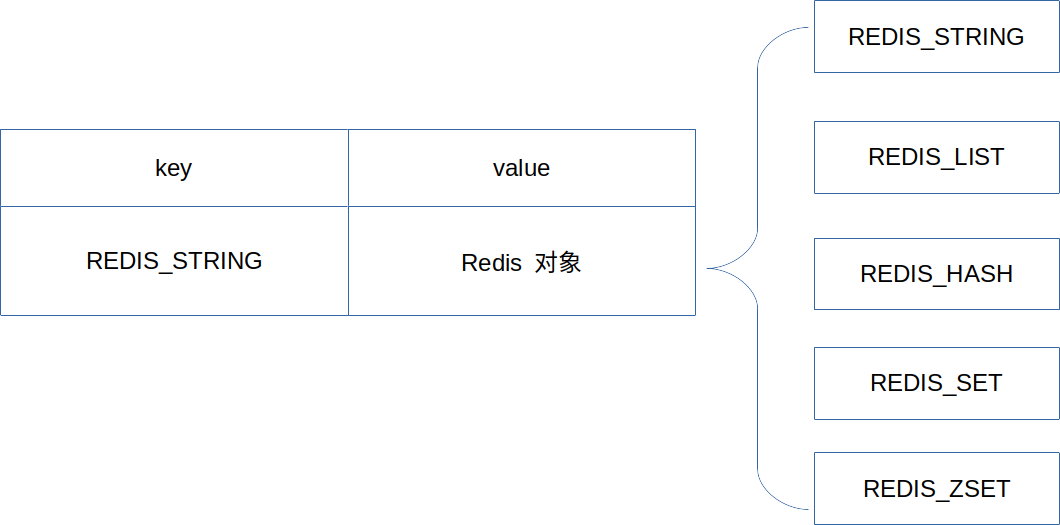
基本数据结构
Redis 中存在五种常见的数据结构,分别是 String(字符串)、List(列表)、Hash(哈希)、Set(集合)、ZSet(有序集合)
Redis 对象
一个 Redis 对象由以下字段组成:
// server.h —— redis.h
typedef struct redisObject {
// 对象的类型,取值范围:REDIS_STRING、REDIS_LIST、REDIS_HASH、REDIS_SET、REDIS_ZSET
unsigned type:4;
// 对象的编码,取值范围:REDIS_ENCODING_INT、REDIS_ENCODING_EMBSTR、REDIS_ENCODING_RAW、REDIS_ENCODING_HT、REDIS_ENCODING_LINKEDLIST、REDIS_ENCODING_ZIPLIST、REDIS_ENCODING_INTSET、REDIS_ENCODING_SKIPLIST
unsigned encoding:4; // 每种 type 对应着两个或两个以上的编码
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
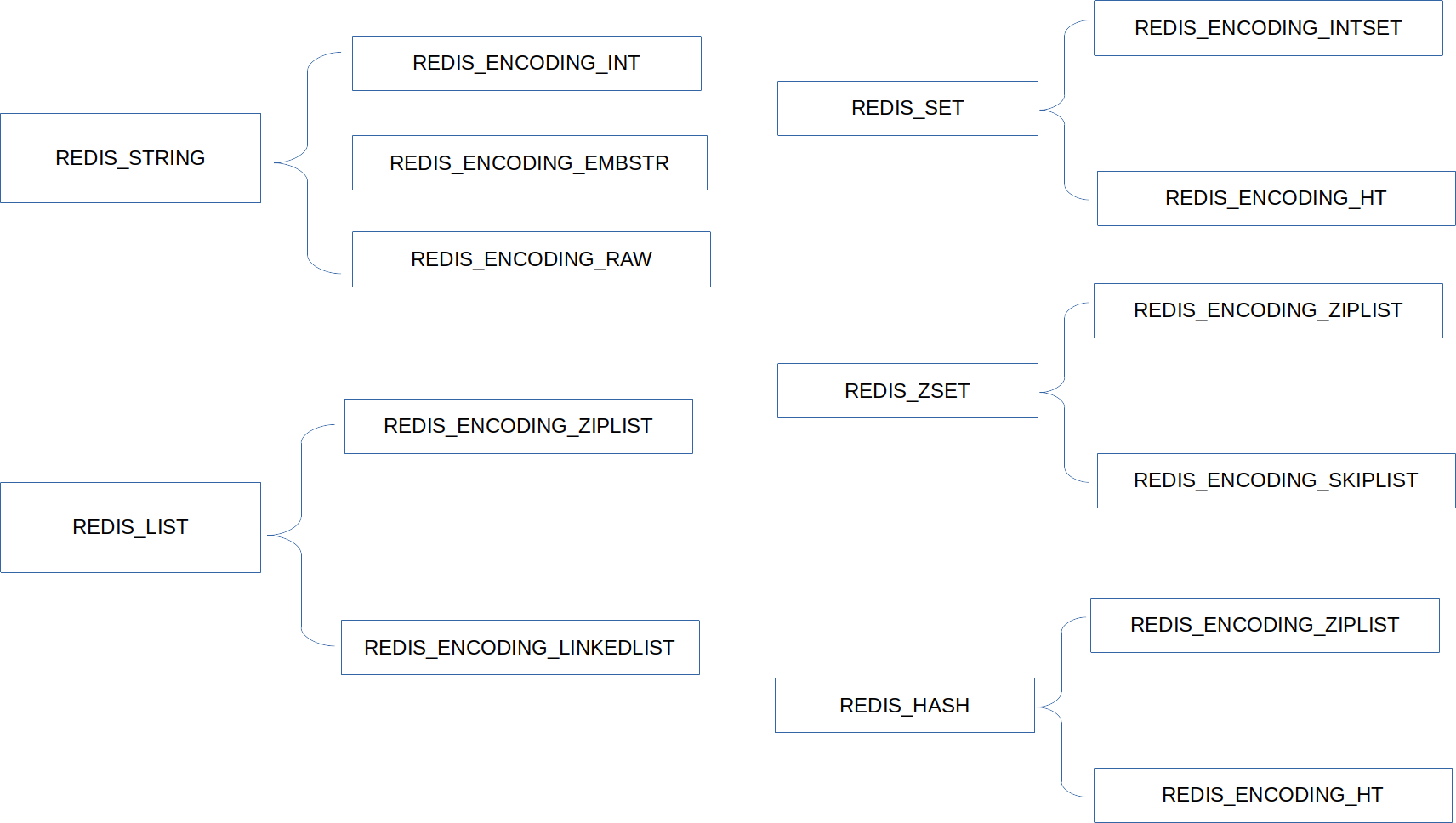
基本数据类型就是上文提到的几种数据类型,而这些数据类型之间的编码方式有所不同。这是因为为了适应不同的需求,每个基本数据类型都会有不同的实现方式(可以类比为面向对象设计中的 接口 和 实现类 的关系)
基本类型与编码的对应关系如下所示:
字符串
字符串对应的 Redis 数据类型是 REDIS_STRING,具体的编码有 REDIS_ENCODIGN_INT、REDIS_ENCODIGN_EMBSTR、REDIS_ENCODIGN_RAW
-
REDIS_ENCODIGN_INT-
对应
long类型的整数,当输入的字符串为数字并且在long类型表示的数字的范围内时,String会使用这种编码格式。 -
对象此时的具体内容如下图所示:
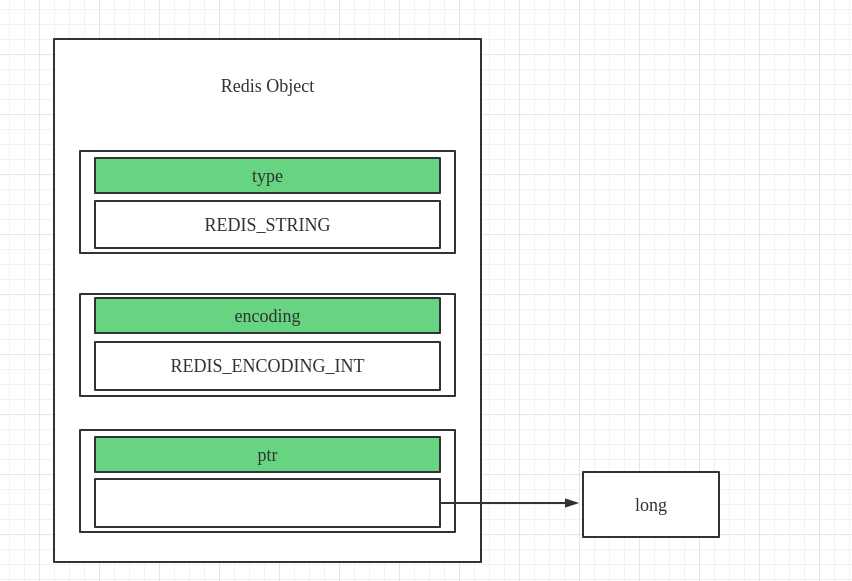
-
-
REDIS_ENCODIGN_EMBSTR-
当字符串的长度小于某个阈值时,会采用
embstr的编码方式进行编码。这是因为embstr的编码方式只需要分配一次sdshdr的空间,因此速度更快。 -
embstr编码的方式是不可变的,因此如果对embstr编码的字符串进行修改,会首先讲字符串变为raw的编码方式再进行修改 -
embstr编码的对象的内容存储表示: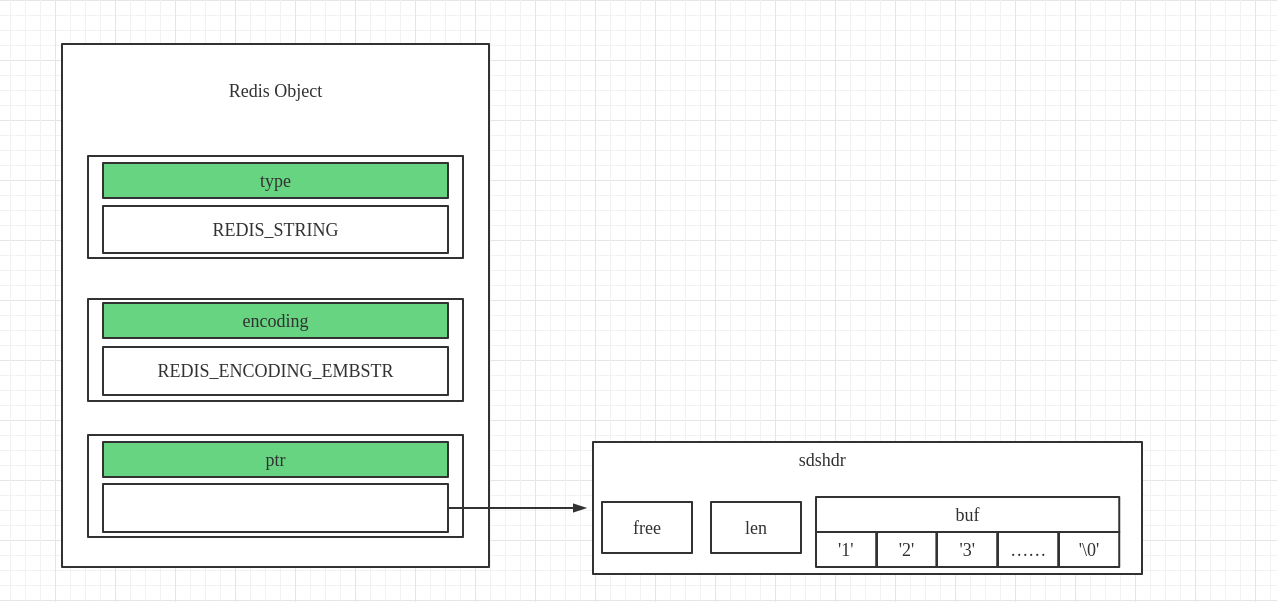
-
-
REDIS_ENCODIGN_RAW-
除了上述的两种编码格式之外,其它的
String都是使用raw的方式进行编码的 -
具体的对象的存储内容如下图所示
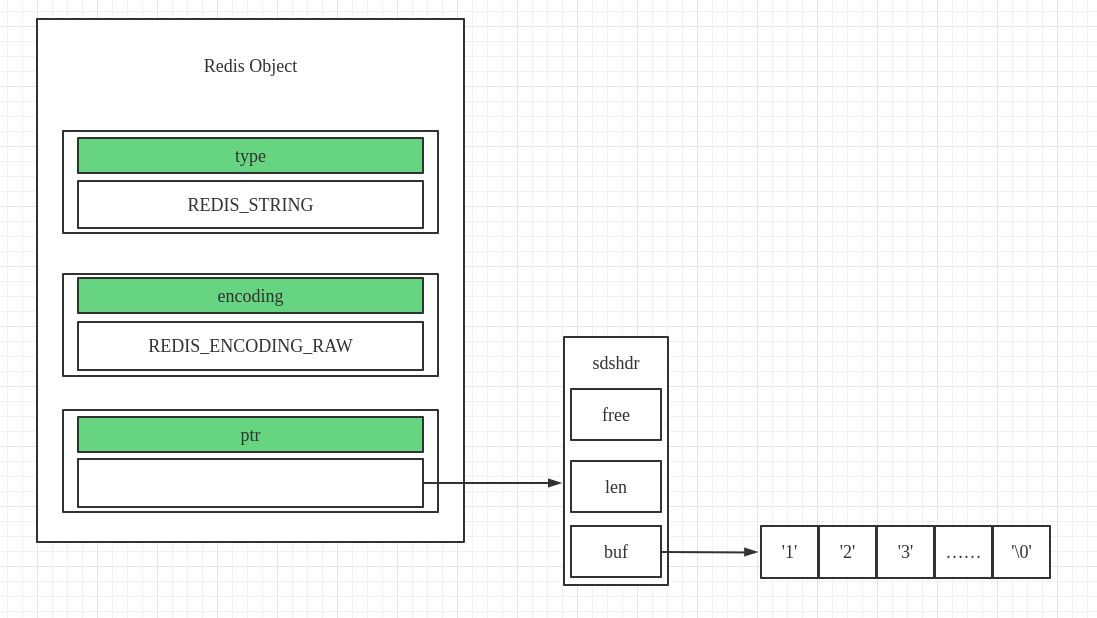
-
-
SDSSDS:Simple Dynamic String (简单动态字符串),由Redis定义的字符串类型。与 C 的字符串相比,有以下优势:
-
能够提高访问速度
- C 语言计算字符串时需要再次遍历整个字符串,因此会浪费许多的时间
-
能够避免缓存区溢出
- C 语言字符串的操作存在缓存区溢出的问题,前提是在增加元素之前没有足够的内存分配。
SDS通过动态地执行空间地扩充,API 会自动进行空间地扩展
-
通过预分配内存空间和惰性释放的方式来提高内存的分配速度
-
空间预分配
对
SDS进行修改之后,如果SDS的长度小于某个阈值,这个时候会分配len = free对
SDS进行修改之后,如果SDS的长度大于阈值,这个时候会按照一定的固定大小进行分配 -
惰性释放
再删除一段内容后,当前的存储空间不会立刻释放,从而减少了再次分配空间的时间
-
-
C 语言保存的数据内容有限;而
SDS可以保存任意类型的内容
-
列表(List)
列表的编码方式有 REDIS_ENCODING_ZIPLIST、REDIS_ENCODING_LINKEDLIST
特点:有序、可重复、插入和删除的速度较快
-
- 存储结构:
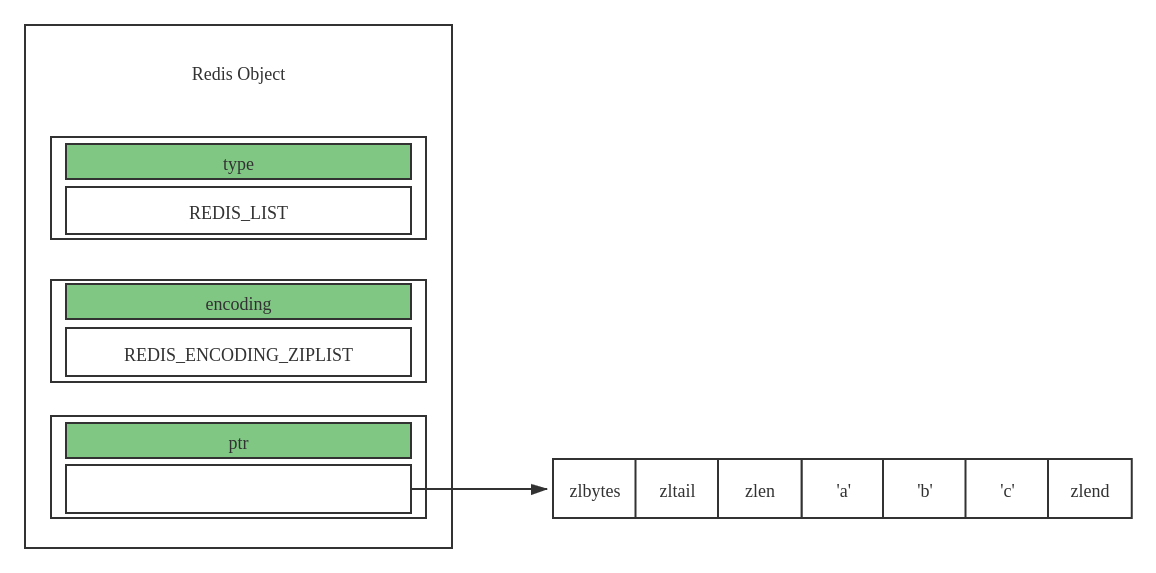
zlbytes:表示压缩链表的总字节数zltail:表示距离尾部节点的偏移量zlend:表示这个压缩链表的长度 -
REDIS_ENCODING_LINKEDLIST(双向链表)-
一般意义上的双向链表
-
具体结构如下所示:
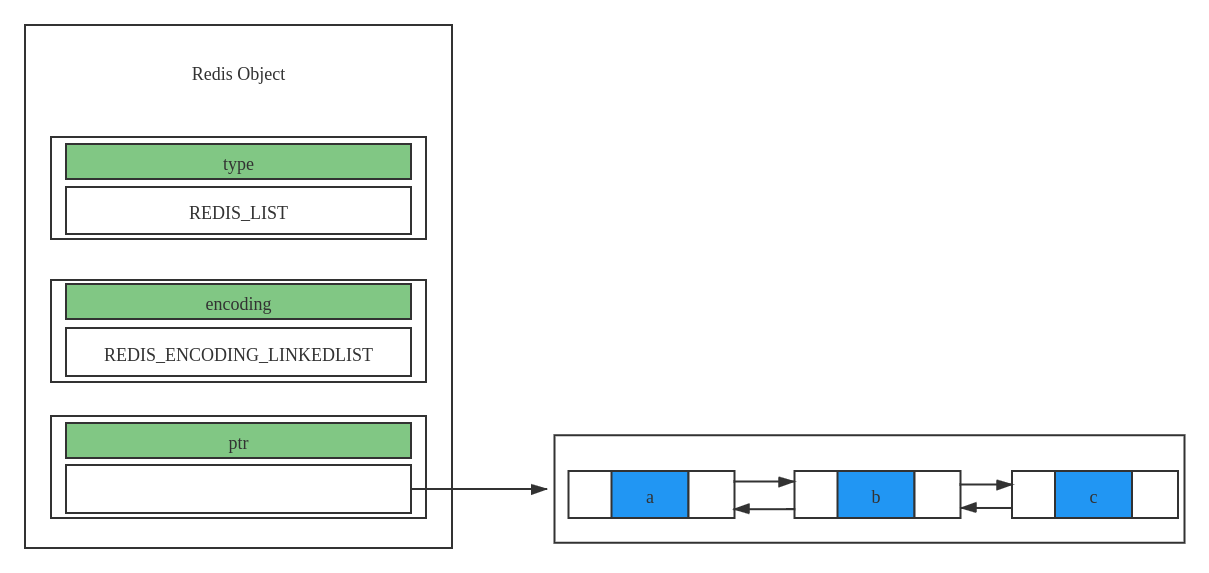
-
集合(Set)
表示没有重复元素的无序即可,对应的编码方式有:REDIS_ENCODING_INTSET、REDIS_ENCODING_HT
-
REDIS_ENCODING_INTSET- 针对整形集合作为底层实现
- 使用整形集合时集合时有序的
- 具体结构如下所示:
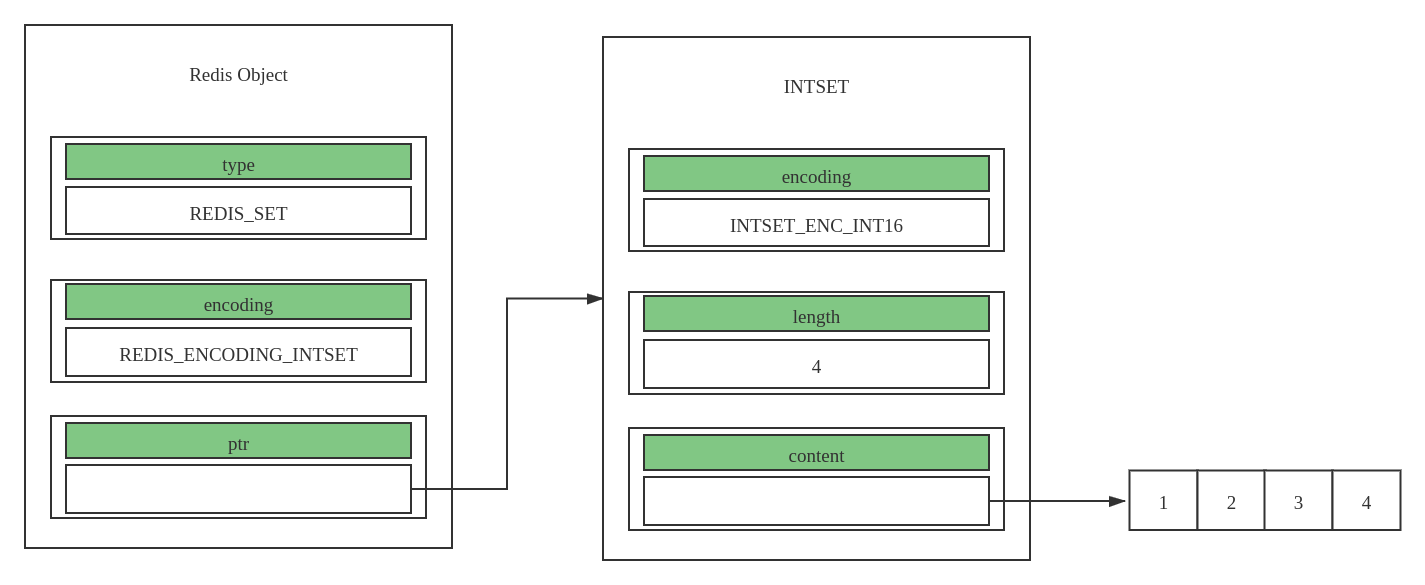
-
- 底层时字典的存储结构,字典的每个键和
Redis的key一样都只能是字符串类型的。在处理Set数据类型时,字典每个键对应的值都是NULL - 当达到一定条件时,会从整形集合转变为字典
- 当插入元素的数量大于某个阈值时,将会从
REDIS_ENCODING_INTSET的编码方式转换为REDIS_ENCODING_HT的编码方式 - 当插入的元素为非数字时,将会直接使用
REDIS_ENCODING_HT的编码方式
- 当插入元素的数量大于某个阈值时,将会从
- 具体结构如下所示:
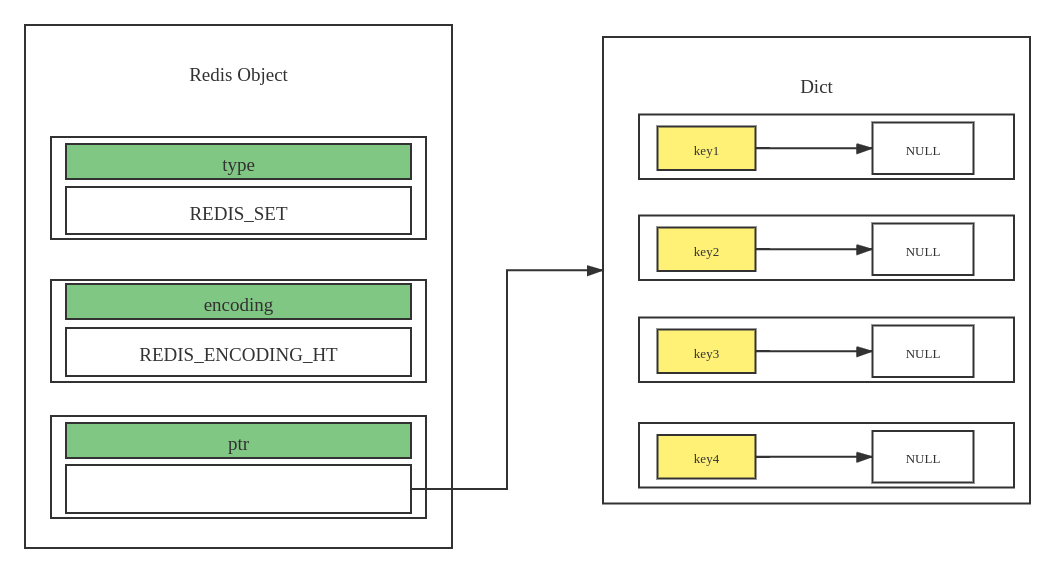
- 底层时字典的存储结构,字典的每个键和
有序集合
有顺序的集合。存在两种编码方式:REDIS_ENCODING_ZIPLIST、REDIS_ENCODING_SKIPLIST
-
REDIS_ENCODING_ZIPLIST(ziplist) -
REDIS_ENCODING_SKIPLIST(zset)-
SkipList在基于有序链表的数据结构的基础上,通过在相距随机距离的节点上添加额外的一个索引链接,通过这些索引链接可以提高查找速度。
可以看看:http://zhangtielei.com/posts/blog-redis-skiplist.html
优点:
- 相比较于于
B+树的数据结构,SkipList可以降低索引的内存使用。 - 对于经常性地访问一段连续区间的元素,
SkipList要比其它平衡树和哈希表更加高效 - 相比较其它的数据结构,调试起来更加简单
一个可能的
SkipList结构: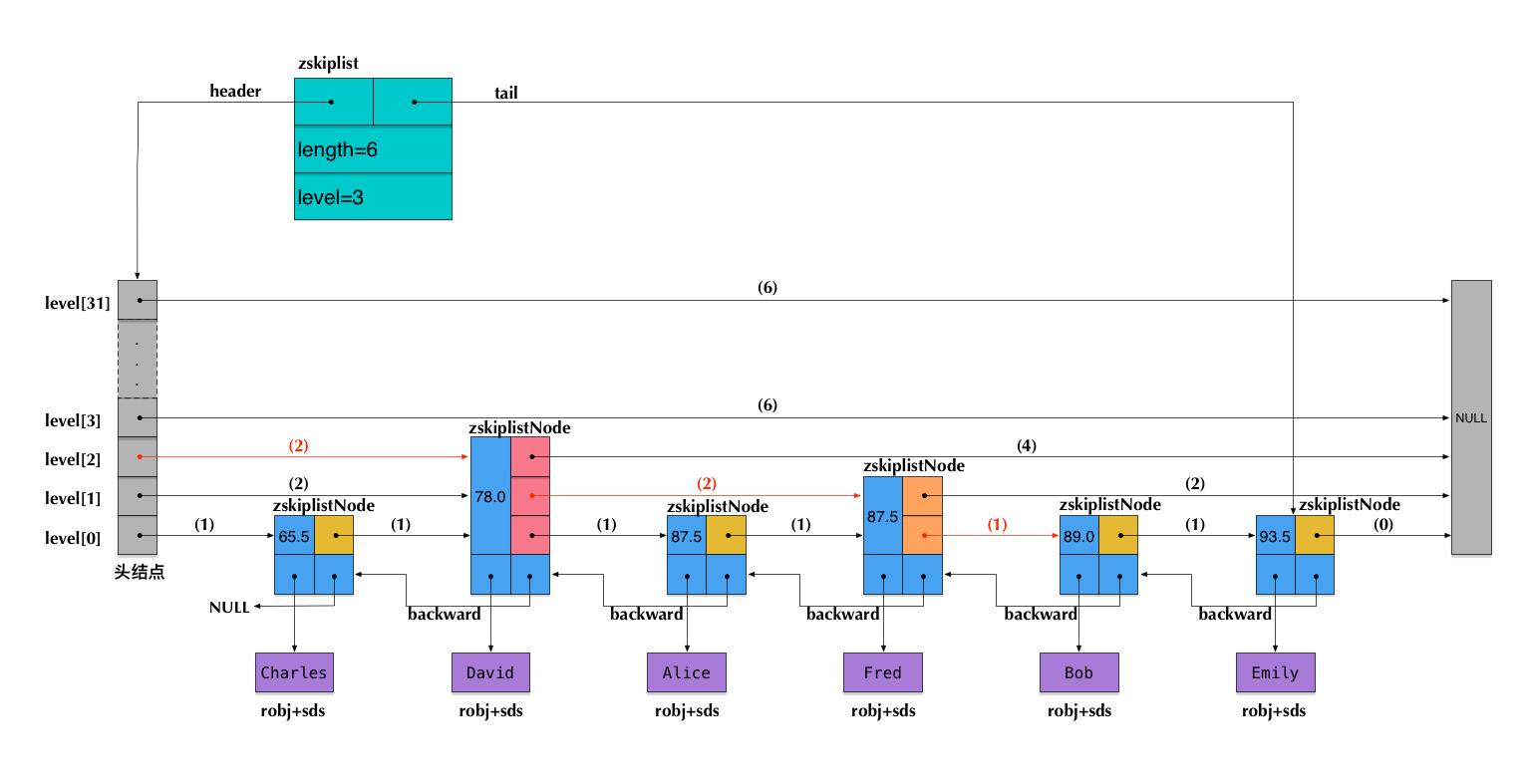
- 相比较于于
-
内部存储结构
# ZSet 存储结构 typedef struct zset { dict *dict; zskiplist *zsl; } zset;看起来像下面这样:
-
-
转换规则
zset-max-ziplist-entries 128 zset-max-ziplist-value 64- 当存储的元素个数大于
zset-max-ziplist-entries时,将自动从REDIS_ENCODING_ZIPLIST转换为REDIS_ENCODING_SKIPLIST - 当存储的单个数据元素的长度大于
zset-max-ziplist-value时,自动从REDIS_ENCODING_ZIPLIST转换为REDIS_ENCODING_SKIPLIST
- 当存储的元素个数大于

哈希
存储哈希表的数据对象。编码类型:REDIS_ENCODING_ZIPLIST、REDIS_ENCODING_HT
-
REDIS_ENCODING_ZIPLIST -
REDIS_ENCODING_HT -
转换规则
Hash中的键值对数量小于某个阈值时,使用REDIS_ENCODING_ZIPLISTHash里的key和value长度均小于某个阈值时,使用REDIS_ENCODING_ZIPLIST编码方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号