
solrcloud jsonfacet分组聚合 unique计数不准确
jsonfacet分组聚合查询
unique、hll函数问题:
对不同的值进行估算,并非准确的值,
优点:节省内存消耗,用分组算法对不同的值count进行估算
缺点:无法准确统计count(distinct key)
区别:
unique给定字段的惟一值的数量。超过100个值,它不会产生精确的估计,惟一的facet函数是Solr最快速的实现来计算不同值的数量
hll通过超log-log算法的分布式基数估计
记录:
json.facet={fz:{type:terms,field:khid,refine:true,overrequest:100000,limit:10,facet:{summy:"sum(my)",sumcnt:"hll(posid)"}}}&fq=month:(201808)
json.facet={fz:{type:terms,field:khid,refine:true,overrequest:100000,limit:10,facet:{summy:"sum(my)",sumcnt:"unique(posid)"}}}&fq=month:(201808)
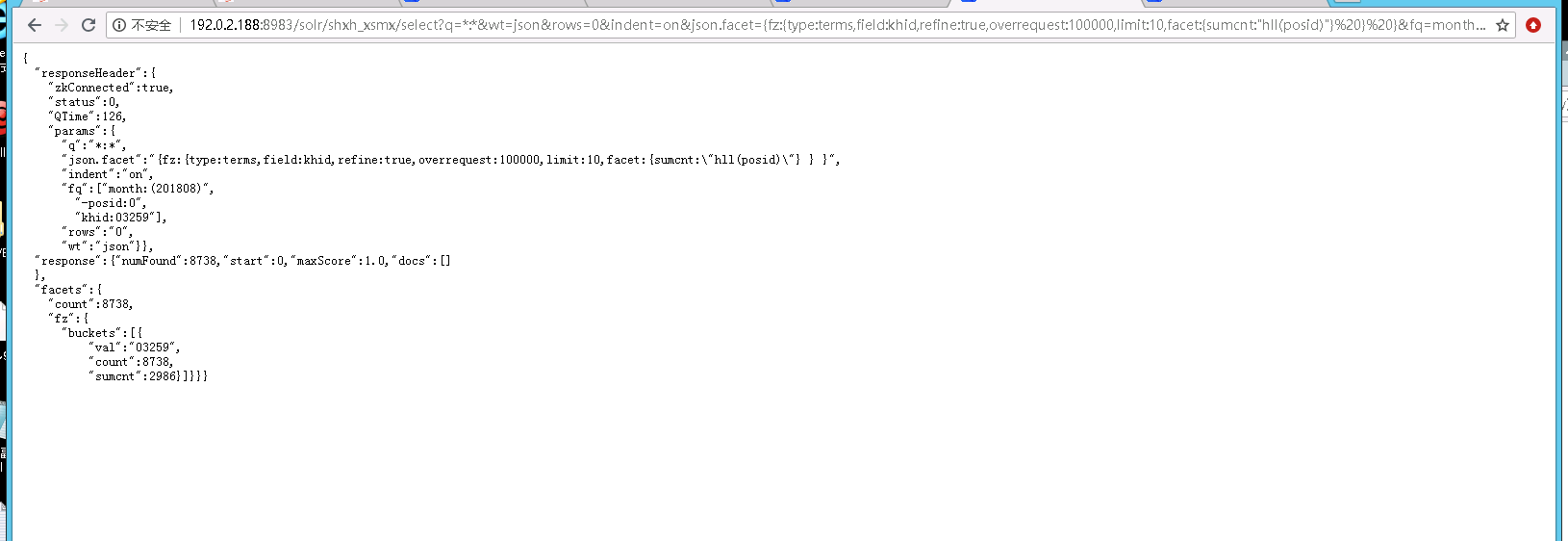
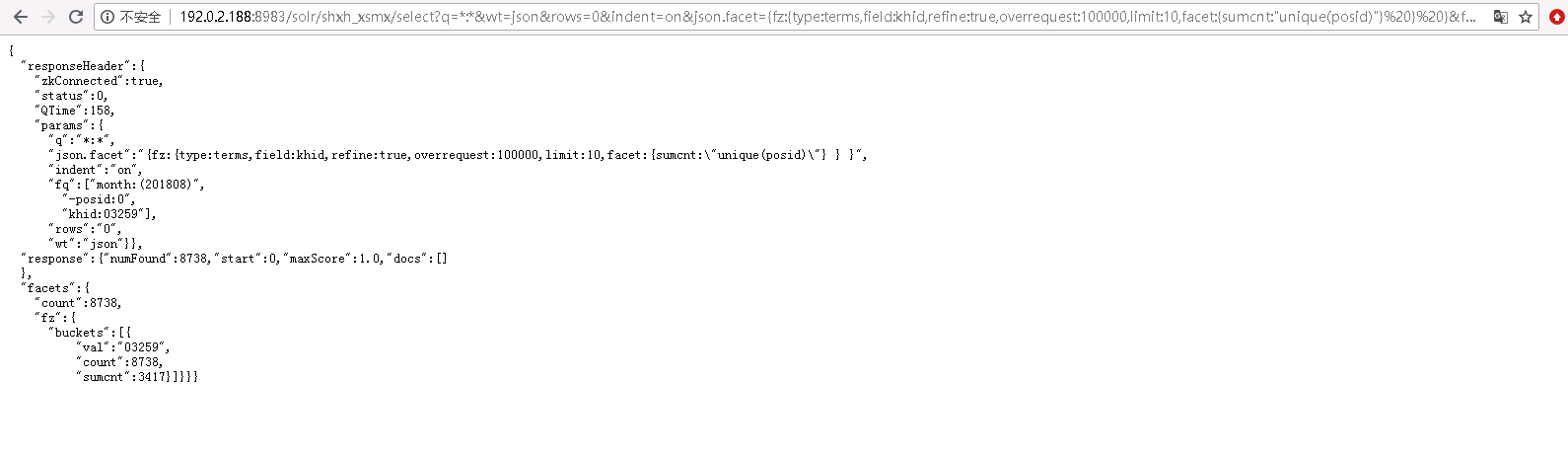
计算出的sumcnt是估算,而不是精确计数
hll函数比unqie函数估算的准确些,但都不精确
解决方法:
1、用stats语法对count(distinct)统计
stats=true&stats.field={!countDistinct=true}posid&fq=month:(201808)
精确统计,对所有节点的数据进行全面统计,耗时高,吃内存

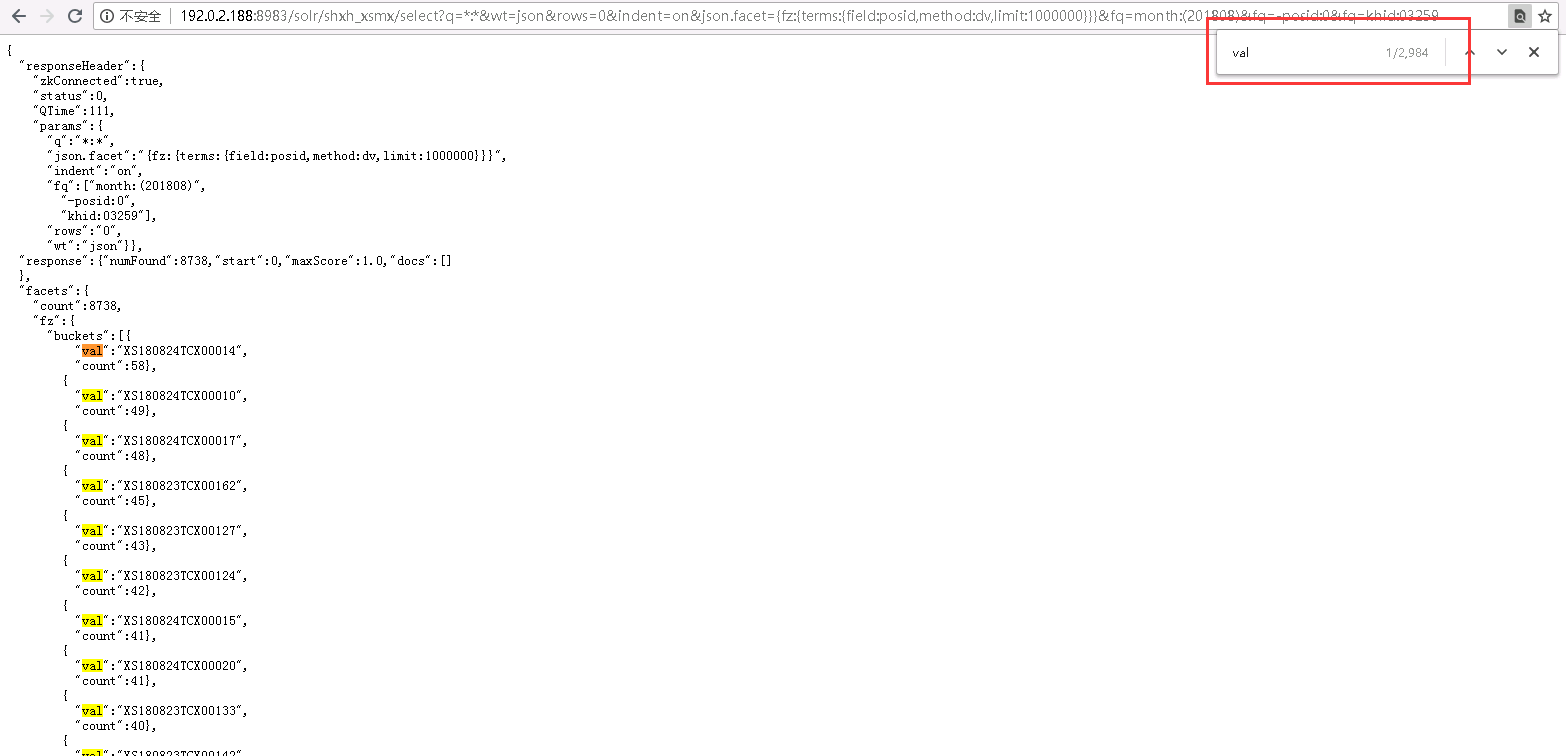
2、dv函数解决
&indent=on&json.facet={fz:{terms:{field:posid,method:dv,limit:1000000}}}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号