TCP/IP协议栈在Linux内核中的运行时序分析
TCP/IP协议栈
TCP/IP 协议栈是一系列网络协议的总和,是构成网络通信的核心骨架,它定义了电子设备如何连入因特网,以及数据如何在它们之间进行传输。TCP/IP 协议采用4层结构,分别是应用层、传输层、网络层和链路层,每一层都使用它的下一层所提供的服务来完成自己的需求。

对四层模型的职责简要总结为下:
- 链路层:对0和1进行分组,定义数据帧,确认主机的物理地址,传输数据;
- 网络层:定义IP地址,确认主机所在的网络位置,并通过IP进行MAC寻址,对外网数据包进行路由转发;
- 传输层:定义端口,确认主机上应用程序的身份,并将数据包交给对应的应用程序;
- 应用层:定义数据格式,并按照对应的格式解读数据。
网络接口层(链路层)
要传输有意义的数据,就需要以字节为单位对 0 和 1 进行分组,并且要标识好每一组电信号的信息特征,然后按照分组的顺序依次发送。以太网规定一组电信号就是一个数据包,一个数据包被称为一帧, 制定这个规则的协议就是以太网协议。一个完整的以太网数据包如下图所示:

以太网规协议定,接入网络的设备都必须安装网络适配器,即网卡, 数据包必须是从一块网卡传送到另一块网卡。而网卡地址就是数据包的发送地址和接收地址,也就是帧首部所包含的MAC地址,MAC地址是每块网卡的身份标识,就如同我们身份证上的身份证号码,具有全球唯一性。MAC地址采用十六进制标识,共6个字节, 前三个字节是厂商编号,后三个字节是网卡流水号,例如 4C-0F-6E-12-D2-19。
有了MAC地址以后,以太网采用广播形式,把数据包发给该子网内所有主机,子网内每台主机在接收到这个包以后,都会读取首部里的目标MAC地址,然后和自己的MAC地址进行对比,如果相同就做下一步处理,如果不同,就丢弃这个包。
所以链路层的主要工作就是对电信号进行分组并形成具有特定意义的数据帧,然后以广播的形式通过物理介质发送给接收方。
网络层
IP协议
MAC地址只与厂商有关,与所处的网络无关,所以无法通过MAC地址来判断两台主机是否属于同一个子网。因此,网络层引入了IP协议,制定了一套新地址,使得我们能够区分两台主机是否同属一个网络,这套地址就是网络地址,也就是的P地址。
IP地址目前有两个版本,分别是IPv4和IPv6,IPv4是一个32位的地址,常采用4个十进制数字表示。IP协议将这个32位的地址分为两部分,前面部分代表网络地址,后面部分表示该主机在局域网中的地址(这种分法现已过时)。由于各类地址的分法不尽相同,以C类地址192.168.24.1为例,其中前24位就是网络地址,后8位就是主机地址。因此, 如果两个IP地址在同一个子网内,则网络地址一定相同。为了判断IP地址中的网络地址,IP协议还引入了子网掩码, IP地址和子网掩码通过按位与运算后就可以得到网络地址。
由于发送者和接收者的IP地址是已知的(应用层的协议会传入), 因此我们只要通过子网掩码对两个IP地址进行AND运算后就能够判断双方是否在同一个子网了。
在网络层被包装的数据包为IP数据包,IPv4数据包的结构如下图所示:

IP数据包由首部和数据两部分组成,首部长度为20个字节,主要包含了目标IP地址和源IP地址,目标IP地址是网关路由的线索和依据;数据部分的最大长度为65515字节,理论上一个IP数据包的总长度可以达到65535个字节,而以太网数据包的最大长度是1500个字符,如果超过这个大小,就需要对IP数据包进行分割,分成多帧发送。
ARP协议
ARP是局域网概念。数据包在Internet间传播需要依靠IP地址,但进入目的地址的局域网内后,需要根据目的地址的IP得到MAC地址,将该包通过MAC地址送到目的主机。毕竟IP仅仅是个逻辑地址。因此需要ARP地址解析协议,是根据IP地址获取MAC地址的一个网络层协议。
ARP协议属于和IP协议同级的协议。
过程:
- 主机 A 希望与主机B通信,但是只知道主机B的IP地址。
- 主机A广播主机B的IP地址的ARP请求。
- 所有本局域网内的主机都能收到这个广播包。
- 只有主机B回复此包,携带上自己的MAC地址。
- 主机A将B的IP地址和MAC地址的对应关系添加到自己的ARP缓存中。
- 主机A构造对B的数据包。
这一过程是通过本机(或路由器)ARP缓存表辅助实现的。
综上,网络层的主要工作是定义网络地址,区分网段,子网内MAC寻址,对于不同子网的数据包进行路由。
传输层
链路层定义了主机的身份,即MAC地址, 而网络层定义了IP地址,明确了主机所在的网段,有了这两个地址,数据包就从可以从一个主机发送到另一台主机。但实际上数据包是从一个主机的某个应用程序发出,然后由对方主机的应用程序接收。而每台电脑都有可能同时运行着很多个应用程序,所以当数据包被发送到主机上以后,是无法确定哪个应用程序要接收这个包。
UDP
因此传输层引入了UDP协议来解决这个问题,为了给每个应用程序标识身份,UDP协议定义了端口,同一个主机上的每个应用程序都需要指定唯一的端口号,并且规定网络中传输的数据包必须加上端口信息。 这样,当数据包到达主机以后,就可以根据端口号找到对应的应用程序了。UDP定义的数据包就叫做UDP数据包,结构如下所示:

首部长度为8个字节,主要包括源端口和目标端口。
UDP协议比较简单,实现容易,但它没有确认机制, 为了网络可靠性,需要TCP协议,TCP即传输控制协议,是一种面向连接的、可靠的、基于字节流的通信协议。简单来说TCP就是有确认机制的UDP协议,每发出一个数据包都要求确认,如果有一个数据包丢失,就收不到确认,发送方就必须重发这个数据包。
TCP
为了保证传输的可靠性,TCP 协议在 UDP 基础之上建立了三次对话的确认机制,也就是说,在正式收发数据前,必须和对方建立可靠的连接。
TCP将用户数据打包构成报文段,它发送数据时启动一个定时器,另一端收到数据进行确认,对失序的数据重新排序,丢弃重复的数据。TCP提供一种面向连接的可靠的字节流服务,面向连接意味着两个使用TCP的应用(B/S)在彼此交换数据之前,必须先建立一个TCP连接,类似于打电话过程,先拨号振铃,等待对方说喂,然后应答。在一个TCP连接中,只有两方彼此通信。
TCP可靠性来自于:
(1)应用数据被分成TCP最合适的发送数据块
(2)当TCP发送一个段之后,启动一个定时器,等待目的点确认收到报文,如果不能及时收到一个确认,将重发这个报文。
(3)当TCP收到连接端发来的数据,就会推迟几分之一秒发送一个确认。
(4)TCP将保持它首部和数据的检验和,这是一个端对端的检验和,目的在于检测数据在传输过程中是否发生变化。(有错误,就不确认,发送端就会重发)
(5)TCP是以IP报文来传送,IP数据是无序的,TCP收到所有数据后进行排序,再交给应用层
(6)IP数据报会重复,所以TCP会去重
(7)TCP能提供流量控制,TCP连接的每一个地方都有固定的缓冲空间。TCP的接收端只允许另一端发送缓存区能接纳的数据。
(8)TCP对字节流不做任何解释,对字节流的解释由TCP连接的双方应用层解释。
TCP报文结构

- 源端口和目的端口:各占2个字节,分别写入源端口号和目的端口号。
- 序号:占4个字节。序号使用mod运算。TCP是面向字节流的,在一个TCP连接中传送的字节流中的每一个字节都按顺序编号。故该字段也叫做“报文段序号”。
- 确认序号:占4个字节,是期望收到对方下一个报文段的第一个数据字节的序号。若确认序号=N,则表明:到序号N-1为止的所有数据都已正确收到。
- 数据偏移:占4位,表示TCP报文段的首部长度。注意,“数据偏移”的单位是32位字(即以4字节长的字为计算单位)。故TCP首部的最大长度为60字节。
- 保留:占6位,保留为今后使用,目前置为0;
- 紧急URG:当URG=1,表明紧急指针字段有效。这时发送方TCP就把紧急数据插入到本报文段数据的最前面,而在紧急数据后面的数据仍是普通数据。
- 确认ACK:当ACK=1时,确认字段才有效。当ACK=0时,确认号无效。TCP规定,在连接建立后所有传送的报文段都必须把ACK置1。
- 推送PSH:接收方TCP收到PSH=1的报文段,就尽快地交付给接收应用进程,而不再等到整个缓存都填满了后再向上交付。
- 复位RST:当RST=1时,表明TCP连接中出现严重差错,必须释放连接,然后再重新建立运输连接。
- 同步SYN:在连接建立时用来同步序号。当SYN=1而ACK=0时,表明这是一个连接请求报文段。对方若同意建立连接,则应在响应的报文段中使SYN=1和ACK=1。故SYN置为1,就表示这是一个连接请求和连接接收报文。
- 终止FIN:用来释放连接。当FIN=1时,表明此报文段的发送方的数据已发送完毕,并要求释放运输连接。
- 窗口:占2个字节。窗口值作为接收方让发送方设置其发送窗口的依据。
- 检验和:占2字节。检验和字段检验的范围包括首部和数据这两部分。和UDP数据报一样,在计算检验和时,也要在TCP报文段的前面加上12字节的伪首部。伪首部的格式与UDP用户数据报的伪首部一样,但要将伪首部第四个字段中的17 改为6(协议号),把第5字段中的UDP长度改为TCP长度。
- 紧急指针:占2字节。紧急指针仅在URG=1时才有意义,它指出本报文段中的紧急数据的字节数。
TCP三次握手

首先,客户端开始的时候,首先创建sock文件描述符,接着就进行connect发起连接服务器请求,阻塞等待服务器应答。
接着,服务器开始的时候,分配一个listen_sock文件描述符,接着进行bind绑定,绑定完毕之后进行listen监听,最后进行accept,此时阻塞等待客户端的连接。连接建立accept返回之后,分配一个新的文件描述符与客户端通信。
第一次握手:Client先产生一个初始序列号seq:8000,SYN标志位置1,将该数据包发送给Server端,之后Client端进入SYN_SENT状态,等待Client确认。
第二次握手:Server收到数据包后也发送自己的SYN报文作为响应,并初始化序列号seq=15000,为了确认Client的seq,Server将Client发送的seq加1作为ACK发送给Client,Server进入SYN_RCVD状态。
第三次握手:为了确认Server的SYN,Client将Server发送的seq加1作为ACK发送给Server。Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
通过这样的三次握手,客户端和服务端建立起可靠的全双工的连接,开始传送数据。三次握手的最主要目的是保证连接是全双工的,可靠更多的是通过重传机制来保证的。
应用层
主要是提供网络任意端上应用程序之间的接口。比起其它层来说,应用层需要的标准最多,但也是最不成熟的一层。
这一层的协议很多,应用层是大多数普通与网络相关的程序为了通过网络与其他程序通信所使用的层。这个层的处理过程是应用特有的。主要应用层协议有HTTP(万维网服务)、FTP(文件传输)、SMTP(电子邮件)、SSH(安全远程登录)、DNS(域名服务)等等。可以使用传输层的TCP或UDP服务。
socket通信
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。socket一种特殊的文件,一些Socket函数就是对其进行的操作(读/写IO、打开、关闭)。
图为socket通信流程图:

TCP"三次握手"建立连接的过程中服务端会依次调用socket()、bind()、listen()、accept(),客户端会依次调用socket()、connect()。接下来先来对三次握手过程中涉及到的这几个函数调用的源码来进行下分析。
socket()
在 Linux 下使用 <sys/socket.h> 头文件中 socket() 函数来创建套接字,原型为:
int socket(int af, int type, int protocol);
- af 为地址族(Address Family),也就是 IP 地址类型,常用的有 AF_INET 和 AF_INET6。AF 是“Address Family”的简写,INET是“Inetnet”的简写。AF_INET 表示 IPv4 地址,例如 127.0.0.1;AF_INET6 表示 IPv6 地址,如 1030::C9B4:FF12:48AA:1A2B。
- type 为数据传输方式/套接字类型,常用的有 SOCK_STREAM(流格式套接字/面向连接的套接字) 和 SOCK_DGRAM(数据报套接字/无连接的套接字)。
- protocol 表示传输协议,常用的有 IPPROTO_TCP 和 IPPTOTO_UDP,分别表示 TCP 传输协议和 UDP 传输协议。
int __sys_socket(int family, int type, int protocol)
{
int retval;
struct socket *sock;
int flags;
/* Check the SOCK_* constants for consistency. */
BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC);
BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK);
flags = type & ~SOCK_TYPE_MASK;
if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return -EINVAL;
type &= SOCK_TYPE_MASK;
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
return retval;
return sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
}
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
return __sys_socket(family, type, protocol);
}
bind()
socket() 函数用来创建套接字,确定套接字的各种属性,然后服务器端要用 bind() 函数将套接字与特定的 IP 地址和端口绑定起来,只有这样,流经该 IP 地址和端口的数据才能交给套接字处理。类似地,客户端也要用 connect() 函数建立连接。 在linux下bind() 函数的原型为:
int bind(int sock, struct sockaddr *addr, socklen_t addrlen);
其中sock 为 socket 文件描述符,addr 为 sockaddr 结构体变量的指针,addrlen 为 addr 变量的大小,可由 sizeof() 计算得出。
int __sys_bind(int fd, struct sockaddr __user *umyaddr, int addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
err = move_addr_to_kernel(umyaddr, addrlen, &address);
if (!err) {
err = security_socket_bind(sock,
(struct sockaddr *)&address,
addrlen);
if (!err)
err = sock->ops->bind(sock,
(struct sockaddr *)
&address, addrlen);
}
fput_light(sock->file, fput_needed);
}
return err;
}
SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
{
return __sys_bind(fd, umyaddr, addrlen);
}
listen()
对于服务器端程序,使用 bind() 绑定套接字后,还需要使用 listen() 函数让套接字进入被动监听状态,再调用 accept() 函数,就可以随时响应客户端的请求了。
通过 listen() 函数可以让套接字进入被动监听状态,它的原型为:
int listen(int sock, int backlog);
其中,sock 为需要进入监听状态的套接字,backlog 为请求队列的最大长度。所谓被动监听,是指当没有客户端请求时,套接字处于“睡眠”状态,只有当接收到客户端请求时,套接字才会被“唤醒”来响应请求。
int __sys_listen(int fd, int backlog)
{
struct socket *sock;
int err, fput_needed;
int somaxconn;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
err = security_socket_listen(sock, backlog);
if (!err)
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
return __sys_listen(fd, backlog);
}
connect()
connect() 函数用来建立连接,它的原型为:
int connect(int sock, struct sockaddr *serv_addr, socklen_t addrlen);
其中sock 为 socket 文件描述符,addr 为 sockaddr 结构体变量的指针,addrlen 为 addr 变量的大小,可由 sizeof() 计算得出。
int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
err = move_addr_to_kernel(uservaddr, addrlen, &address);
if (err < 0)
goto out_put;
err =
security_socket_connect(sock, (struct sockaddr *)&address, addrlen);
if (err)
goto out_put;
err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen,
sock->file->f_flags);
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
int, addrlen)
{
return __sys_connect(fd, uservaddr, addrlen);
}
accept()
当套接字处于监听状态时,可以通过 accept() 函数来接收客户端请求。它的原型为:
int accept(int sock, struct sockaddr *addr, socklen_t *addrlen);
它的参数与 listen() 和 connect() 是相同的:sock 为服务器端套接字,addr 为 sockaddr_in 结构体变量,addrlen 为参数 addr 的长度,可由 sizeof() 求得。
accept() 返回一个新的套接字来和客户端通信,addr 保存了客户端的IP地址和端口号,而 sock 是服务器端的套接字。后面和客户端通信时,要使用这个新生成的套接字,而不是原来服务器端的套接字。
int __sys_accept4(int fd, struct sockaddr __user *upeer_sockaddr,
int __user *upeer_addrlen, int flags)
{
struct socket *sock, *newsock;
struct file *newfile;
int err, len, newfd, fput_needed;
struct sockaddr_storage address;
if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return -EINVAL;
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
err = -ENFILE;
newsock = sock_alloc();
if (!newsock)
goto out_put;
newsock->type = sock->type;
newsock->ops = sock->ops;
/*
* We don't need try_module_get here, as the listening socket (sock)
* has the protocol module (sock->ops->owner) held.
*/
__module_get(newsock->ops->owner);
newfd = get_unused_fd_flags(flags);
if (unlikely(newfd < 0)) {
err = newfd;
sock_release(newsock);
goto out_put;
}
newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name);
if (IS_ERR(newfile)) {
err = PTR_ERR(newfile);
put_unused_fd(newfd);
goto out_put;
}
err = security_socket_accept(sock, newsock);
if (err)
goto out_fd;
err = sock->ops->accept(sock, newsock, sock->file->f_flags, false);
if (err < 0)
goto out_fd;
if (upeer_sockaddr) {
len = newsock->ops->getname(newsock,
(struct sockaddr *)&address, 2);
if (len < 0) {
err = -ECONNABORTED;
goto out_fd;
}
err = move_addr_to_user(&address,
len, upeer_sockaddr, upeer_addrlen);
if (err < 0)
goto out_fd;
}
/* File flags are not inherited via accept() unlike another OSes. */
fd_install(newfd, newfile);
err = newfd;
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
out_fd:
fput(newfile);
put_unused_fd(newfd);
goto out_put;
}
SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen, int, flags)
{
return __sys_accept4(fd, upeer_sockaddr, upeer_addrlen, flags);
}
SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen)
{
return __sys_accept4(fd, upeer_sockaddr, upeer_addrlen, 0);
}
调试截图
在上诉函数处打断点,成功捕获:
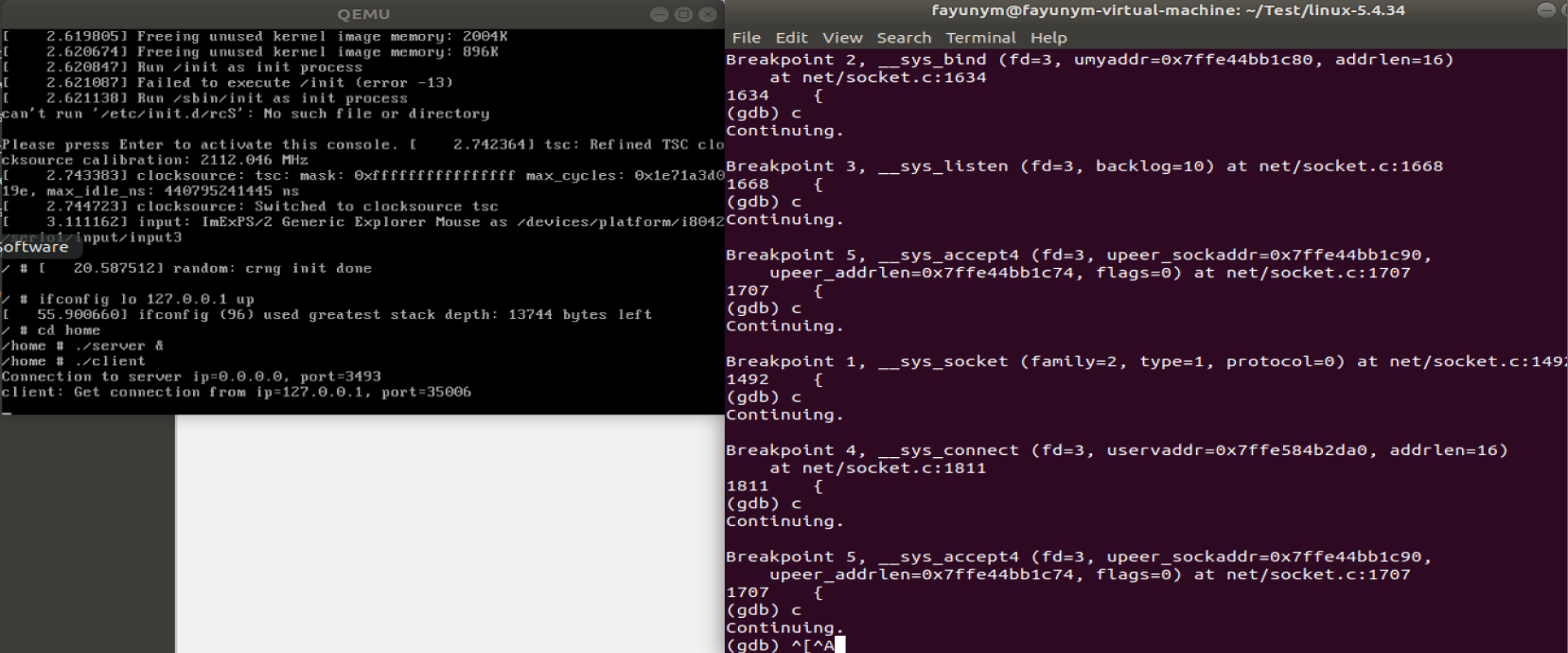
建立连接后就可以通信了。接下来就socket通信过程中的发送和接收数据做深入分析,分析梳理send和recv过程中TCP/IP协议栈相关的运行任务实体及相互协作的时序分析。
发送接收数据过程分析
传输层
发送
send和recv时首先会进入socketcall函数,这是所有socket函数进入内核空间的入口。其中参数call是具体的操作码。源码如下:
SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args)
{
unsigned long a[AUDITSC_ARGS];
unsigned long a0, a1;
int err;
unsigned int len;
if (call < 1 || call > SYS_SENDMMSG)
return -EINVAL;
call = array_index_nospec(call, SYS_SENDMMSG + 1);
len = nargs[call];
if (len > sizeof(a))
return -EINVAL;
/* copy_from_user should be SMP safe. */
if (copy_from_user(a, args, len))
return -EFAULT;
err = audit_socketcall(nargs[call] / sizeof(unsigned long), a);
if (err)
return err;
a0 = a[0];
a1 = a[1];
switch (call) {
case SYS_SOCKET:
err = __sys_socket(a0, a1, a[2]);
break;
case SYS_BIND:
err = __sys_bind(a0, (struct sockaddr __user *)a1, a[2]);
break;
case SYS_CONNECT:
err = __sys_connect(a0, (struct sockaddr __user *)a1, a[2]);
break;
case SYS_LISTEN:
err = __sys_listen(a0, a1);
break;
case SYS_ACCEPT:
err = __sys_accept4(a0, (struct sockaddr __user *)a1,
(int __user *)a[2], 0);
break;
case SYS_GETSOCKNAME:
err =
__sys_getsockname(a0, (struct sockaddr __user *)a1,
(int __user *)a[2]);
break;
case SYS_GETPEERNAME:
err =
__sys_getpeername(a0, (struct sockaddr __user *)a1,
(int __user *)a[2]);
break;
case SYS_SOCKETPAIR:
err = __sys_socketpair(a0, a1, a[2], (int __user *)a[3]);
break;
case SYS_SEND:
err = __sys_sendto(a0, (void __user *)a1, a[2], a[3],
NULL, 0);
break;
case SYS_SENDTO:
err = __sys_sendto(a0, (void __user *)a1, a[2], a[3],
(struct sockaddr __user *)a[4], a[5]);
break;
case SYS_RECV:
err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3],
NULL, NULL);
break;
case SYS_RECVFROM:
err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3],
(struct sockaddr __user *)a[4],
(int __user *)a[5]);
break;
case SYS_SHUTDOWN:
err = __sys_shutdown(a0, a1);
break;
case SYS_SETSOCKOPT:
err = __sys_setsockopt(a0, a1, a[2], (char __user *)a[3],
a[4]);
break;
case SYS_GETSOCKOPT:
err =
__sys_getsockopt(a0, a1, a[2], (char __user *)a[3],
(int __user *)a[4]);
break;
case SYS_SENDMSG:
err = __sys_sendmsg(a0, (struct user_msghdr __user *)a1,
a[2], true);
break;
case SYS_SENDMMSG:
err = __sys_sendmmsg(a0, (struct mmsghdr __user *)a1, a[2],
a[3], true);
break;
case SYS_RECVMSG:
err = __sys_recvmsg(a0, (struct user_msghdr __user *)a1,
a[2], true);
break;
case SYS_RECVMMSG:
if (IS_ENABLED(CONFIG_64BIT) || !IS_ENABLED(CONFIG_64BIT_TIME))
err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1,
a[2], a[3],
(struct __kernel_timespec __user *)a[4],
NULL);
else
err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1,
a[2], a[3], NULL,
(struct old_timespec32 __user *)a[4]);
break;
case SYS_ACCEPT4:
err = __sys_accept4(a0, (struct sockaddr __user *)a1,
(int __user *)a[2], a[3]);
break;
default:
err = -EINVAL;
break;
}
return err;
}
因此send的入口函数是 __sys_sendto,recv函数的入口是 _ _sys_recvfrom()函数。
socketcall截图如下:
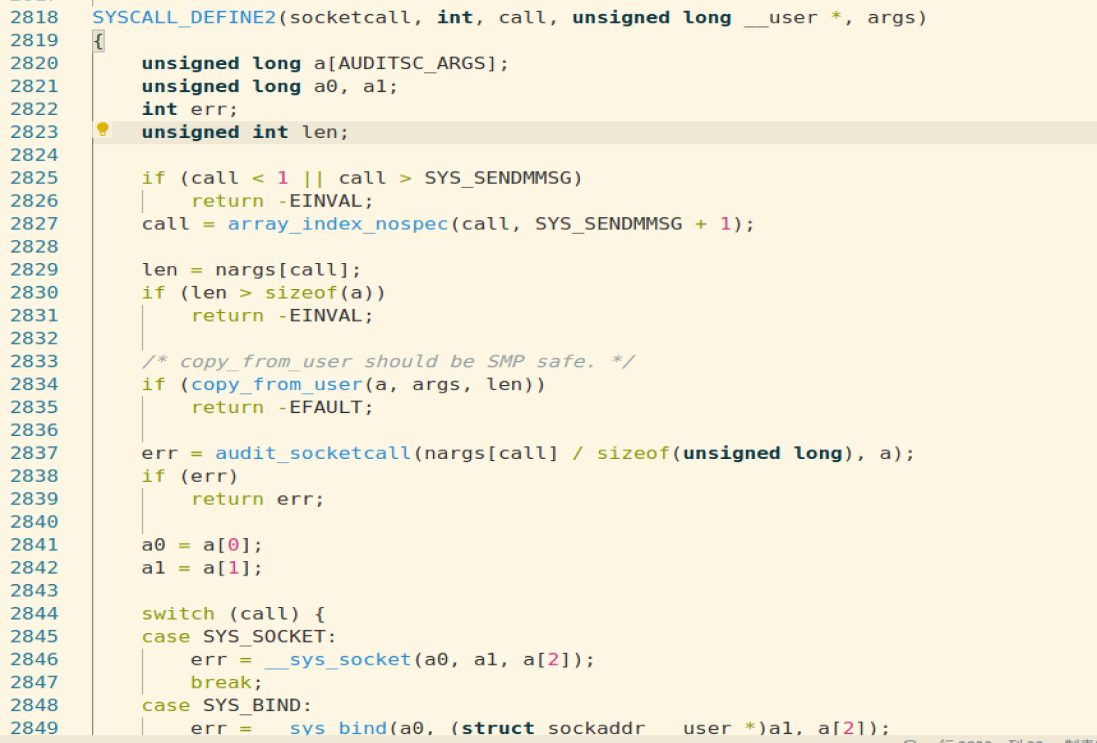
我们跟踪至 __sys_sendto看看:
int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags,
struct sockaddr __user *addr, int addr_len)
{
struct socket *sock;
struct sockaddr_storage address;
int err;
struct msghdr msg;
struct iovec iov;
int fput_needed;
err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter);
if (unlikely(err))
return err;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
msg.msg_name = NULL;
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_namelen = 0;
if (addr) {
err = move_addr_to_kernel(addr, addr_len, &address);
if (err < 0)
goto out_put;
msg.msg_name = (struct sockaddr *)&address;
msg.msg_namelen = addr_len;
}
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
msg.msg_flags = flags;
err = sock_sendmsg(sock, &msg);
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
该函数会创建两个结构体,分别是:struct msghdr msg和struct iovec iov
msghdr结构定义如下:
/* Structure describing messages sent by
`sendmsg' and received by `recvmsg'. */
struct msghdr
{
void *msg_name; /* Address to send to/receive from. */
socklen_t msg_namelen; /* Length of address data. */
struct iovec *msg_iov; /* Vector of data to send/receive into. */
size_t msg_iovlen; /* Number of elements in the vector. */
void *msg_control; /* Ancillary data (eg BSD filedesc passing). */
size_t msg_controllen; /* Ancillary data buffer length.
!! The type should be socklen_t but the
definition of the kernel is incompatible
with this. */
int msg_flags; /* Flags on received message. */
};
它用于接收来自应用层的数据包。结构成员可以分为四组。他们是:
- 套接口地址成员msg_name与msg_namelen。
- I/O向量引用msg_iov与msg_iovlen。
- 附属数据缓冲区成员msg_control与msg_controllen。
- 接收信息标记位msg_flags。
可以看到他最终是通过调用sock_sendmsg函数实现的:
int sock_sendmsg(struct socket *sock, struct msghdr *msg)
{
int err = security_socket_sendmsg(sock, msg,
msg_data_left(msg));
return err ?: sock_sendmsg_nosec(sock, msg);
}
security_socket_sendmsg函数主要是做一些简单的安全检查,实际的数据发送由sock_sendmsg_nosec完成。
static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg)
{
int ret = INDIRECT_CALL_INET(sock->ops->sendmsg, inet6_sendmsg,
inet_sendmsg, sock, msg,
msg_data_left(msg));
BUG_ON(ret == -EIOCBQUEUED);
return ret;
}
我们在上述两个函数处断点调试:
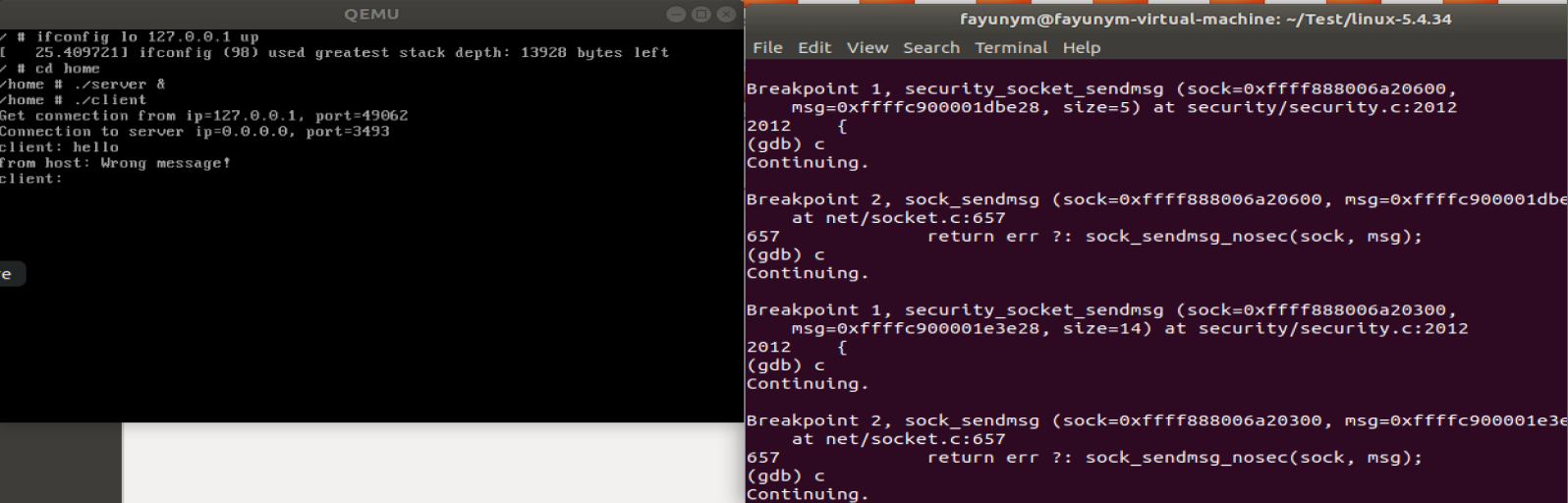
可以看到sock_sendmsg_nosec调用了inet_sendmsg函数,它会根据参数调用 tcp_sendmsg或udp_sendmsg:
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
struct sock *sk = sock->sk;
if (unlikely(inet_send_prepare(sk)))
return -EAGAIN;
return INDIRECT_CALL_2(sk->sk_prot->sendmsg, tcp_sendmsg, udp_sendmsg,
sk, msg, size);
}
我们的示例程序为tcp连接,继续跟踪tcp_sendmsg函数:
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size)
{
int ret;
lock_sock(sk);
ret = tcp_sendmsg_locked(sk, msg, size);
release_sock(sk);
return ret;
}
可以看到发送前后有个加锁释放锁的操作,我们进入tcp_sendmsg_locked查看,该函数的主要功能是申请SKB和缓存空间, 将用户空间数据复制到缓存空间中,然后发送出去:
而该函数主要调用了tcp_push函数:
wait_for_memory:
//如果已经有数据拷贝至发送队列,那就先把这部分发送,再等待内存释放
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now,
TCP_NAGLE_PUSH, size_goal);
if ((err = sk_stream_wait_memory(sk, &timeo)) != 0)
goto do_error;
mss_now = tcp_send_mss(sk, &size_goal, flags);
}
}
out:
//如果已经有数据拷贝至发送队列,那就发送数据
if (copied)
tcp_push(sk, flags, mss_now, tp->nonagle, size_goal);
继续跟踪tcp_push函数:
static void tcp_push(struct sock *sk, int flags, int mss_now,
int nonagle, int size_goal)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
skb = tcp_write_queue_tail(sk);
if (!skb)
return;
if (!(flags & MSG_MORE) || forced_push(tp))
tcp_mark_push(tp, skb);
tcp_mark_urg(tp, flags);
if (tcp_should_autocork(sk, skb, size_goal)) {
/* avoid atomic op if TSQ_THROTTLED bit is already set */
if (!test_bit(TSQ_THROTTLED, &sk->sk_tsq_flags)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPAUTOCORKING);
set_bit(TSQ_THROTTLED, &sk->sk_tsq_flags);
}
/* It is possible TX completion already happened
* before we set TSQ_THROTTLED.
*/
if (refcount_read(&sk->sk_wmem_alloc) > skb->truesize)
return;
}
if (flags & MSG_MORE)
nonagle = TCP_NAGLE_CORK;
__tcp_push_pending_frames(sk, mss_now, nonagle);
}
可以看到tcp_push调用了__tcp_push_pending_frames函数:
/* Push out any pending frames which were held back due to
* TCP_CORK or attempt at coalescing tiny packets.
* The socket must be locked by the caller.
*/
void __tcp_push_pending_frames(struct sock *sk, unsigned int cur_mss,
int nonagle)
{
/* If we are closed, the bytes will have to remain here.
* In time closedown will finish, we empty the write queue and
* all will be happy.
*/
if (unlikely(sk->sk_state == TCP_CLOSE))
return;
if (tcp_write_xmit(sk, cur_mss, nonagle, 0,
sk_gfp_mask(sk, GFP_ATOMIC)))
tcp_check_probe_timer(sk);
}
tcp_write_xmit函数会把数据写到缓存里,实现拥塞控制,然后调用tcp_transmit_skb传输数据(它实际调用__tcp_transmit_skb)
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it,
gfp_t gfp_mask)
{
return __tcp_transmit_skb(sk, skb, clone_it, gfp_mask,
tcp_sk(sk)->rcv_nxt);
}
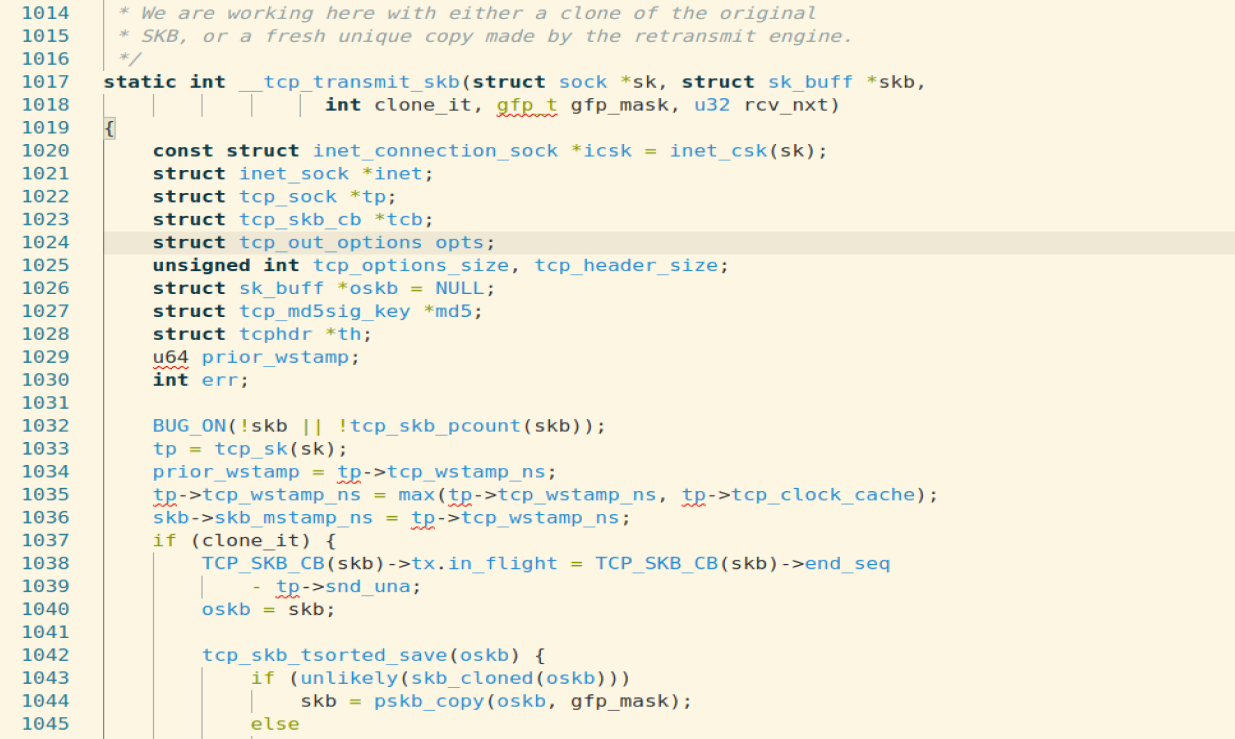
该函数复制skb,构造tcp首部和校验和,然后调用网络层的回调函数queue_xmit发送skb,至此传输层的任务就完成了。
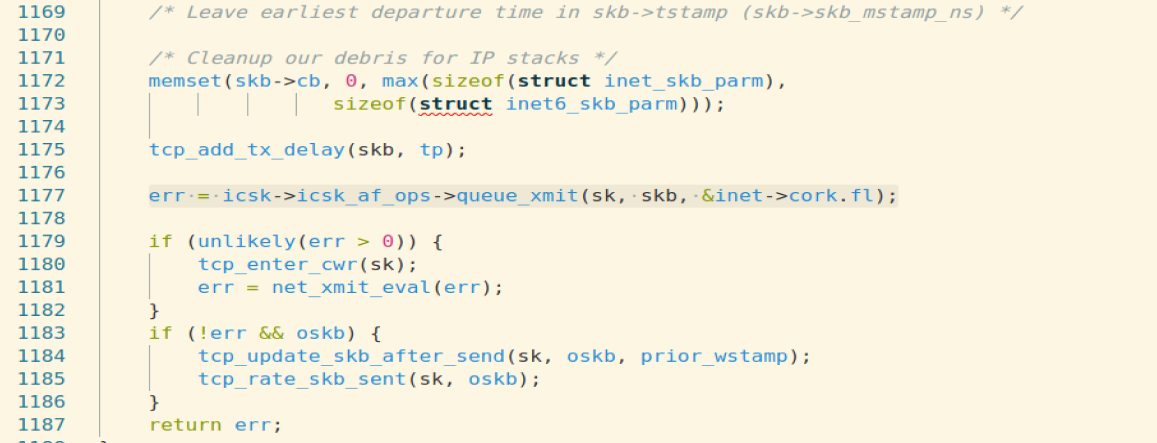
跟踪调试截图:
接收
前面分析得到recv函数的入口是 _ _sys_recvfrom()函数。
int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags,
struct sockaddr __user *addr, int __user *addr_len)
{
struct socket *sock;
struct iovec iov;
struct msghdr msg;
struct sockaddr_storage address;
int err, err2;
int fput_needed;
err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter);
if (unlikely(err))
return err;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
msg.msg_control = NULL;
msg.msg_controllen = 0;
/* Save some cycles and don't copy the address if not needed */
msg.msg_name = addr ? (struct sockaddr *)&address : NULL;
/* We assume all kernel code knows the size of sockaddr_storage */
msg.msg_namelen = 0;
msg.msg_iocb = NULL;
msg.msg_flags = 0;
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
err = sock_recvmsg(sock, &msg, flags);
if (err >= 0 && addr != NULL) {
err2 = move_addr_to_user(&address,
msg.msg_namelen, addr, addr_len);
if (err2 < 0)
err = err2;
}
fput_light(sock->file, fput_needed);
out:
return err;
}
它调用了sock_recvmsg函数:
int sock_recvmsg(struct socket *sock, struct msghdr *msg, int flags)
{
int err = security_socket_recvmsg(sock, msg, msg_data_left(msg), flags);
return err ?: sock_recvmsg_nosec(sock, msg, flags);
}
EXPORT_SYMBOL(sock_recvmsg);
类似地,接收时也会首先进行安全检查再进行实际的发送:
static inline int sock_recvmsg_nosec(struct socket *sock, struct msghdr *msg,
int flags)
{
return INDIRECT_CALL_INET(sock->ops->recvmsg, inet6_recvmsg,
inet_recvmsg, sock, msg, msg_data_left(msg),
flags);
}
int inet_recvmsg(struct socket *sock, struct msghdr *msg, size_t size,
int flags)
{
struct sock *sk = sock->sk;
int addr_len = 0;
int err;
if (likely(!(flags & MSG_ERRQUEUE)))
sock_rps_record_flow(sk);
err = INDIRECT_CALL_2(sk->sk_prot->recvmsg, tcp_recvmsg, udp_recvmsg,
sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
if (err >= 0)
msg->msg_namelen = addr_len;
return err;
}
根据程序调用了tcp_recvmsg,接受函数比发送函数做更多工作,因为数据接收不仅仅只是接收,tcp的三次握手也是在接收函数实现的。
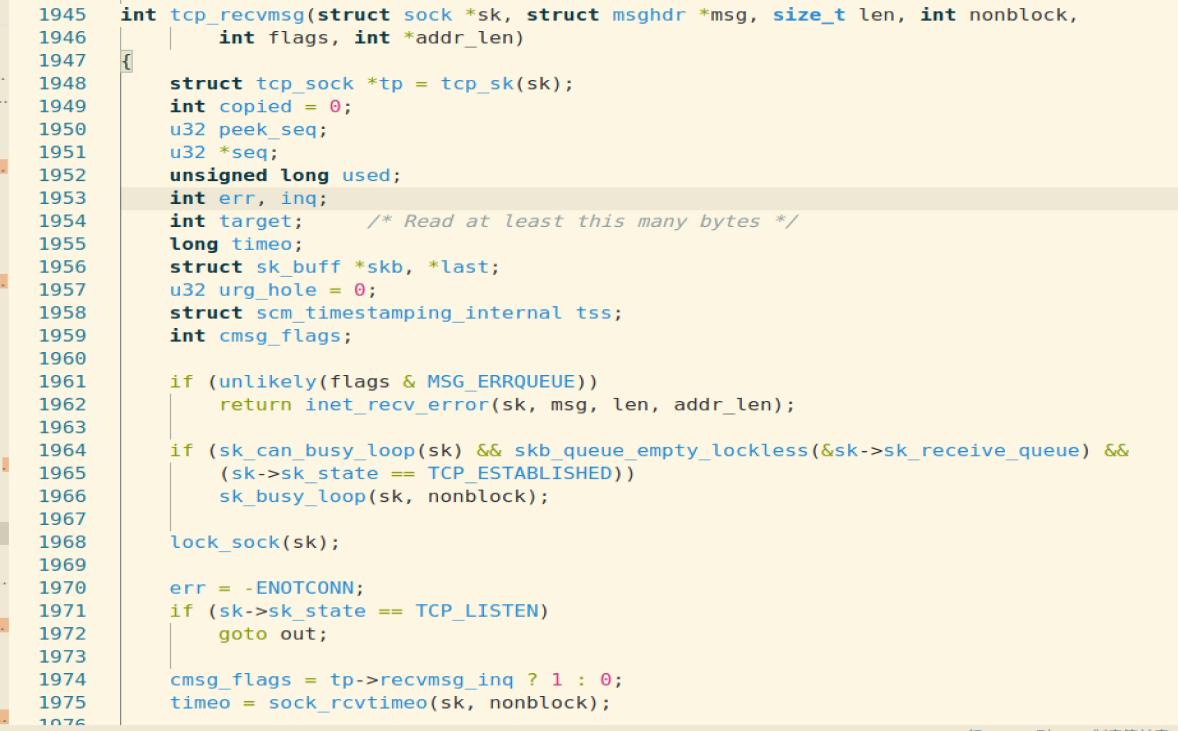
这里共维护了三个队列:prequeue、backlog、receive_queue,分别为预处理队列,后备队列和接收队列,在连接建立后,若没有数据到来,接收队列为空,进程会在sk_busy_loop函数内循环等待,直到接收队列不为空,并调用函数数skb_copy_datagram_msg将接收到的数据拷贝到用户态,该函数调用skb_copy_datagram_iter,实际调用的是__skb_datagram_iter,这里同样用了struct msghdr *msg来实现。
static int __skb_datagram_iter(const struct sk_buff *skb, int offset,
struct iov_iter *to, int len, bool fault_short,
size_t (*cb)(const void *, size_t, void *,
struct iov_iter *), void *data)
{
int start = skb_headlen(skb);
int i, copy = start - offset, start_off = offset, n;
struct sk_buff *frag_iter;
/* Copy header. */
if (copy > 0) {
if (copy > len)
copy = len;
n = cb(skb->data + offset, copy, data, to);
offset += n;
if (n != copy)
goto short_copy;
if ((len -= copy) == 0)
return 0;
}
/* Copy paged appendix. Hmm... why does this look so complicated? */
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
int end;
const skb_frag_t *frag = &skb_shinfo(skb)->frags[i];
WARN_ON(start > offset + len);
end = start + skb_frag_size(frag);
if ((copy = end - offset) > 0) {
struct page *page = skb_frag_page(frag);
u8 *vaddr = kmap(page);
if (copy > len)
copy = len;
n = cb(vaddr + skb_frag_off(frag) + offset - start,
copy, data, to);
kunmap(page);
offset += n;
if (n != copy)
goto short_copy;
if (!(len -= copy))
return 0;
}
start = end;
}
skb_walk_frags(skb, frag_iter) {
int end;
WARN_ON(start > offset + len);
end = start + frag_iter->len;
if ((copy = end - offset) > 0) {
if (copy > len)
copy = len;
if (__skb_datagram_iter(frag_iter, offset - start,
to, copy, fault_short, cb, data))
goto fault;
if ((len -= copy) == 0)
return 0;
offset += copy;
}
start = end;
}
if (!len)
return 0;
/* This is not really a user copy fault, but rather someone
* gave us a bogus length on the skb. We should probably
* print a warning here as it may indicate a kernel bug.
*/
fault:
iov_iter_revert(to, offset - start_off);
return -EFAULT;
short_copy:
if (fault_short || iov_iter_count(to))
goto fault;
return 0;
}
可以看到,该函数拷贝了TCP头部和数据部分。
调试跟踪截图:
网络层
发送
发送进入IP层的入口函数为ip_queue_xmit:
static inline int ip_queue_xmit(struct sock *sk, struct sk_buff *skb,
struct flowi *fl)
{
return __ip_queue_xmit(sk, skb, fl, inet_sk(sk)->tos);
}
它实际调用__ip_queue_xmit函数:
int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl,
__u8 tos)
{
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
struct ip_options_rcu *inet_opt;
struct flowi4 *fl4;
struct rtable *rt;
struct iphdr *iph;
int res;
/* Skip all of this if the packet is already routed,
* f.e. by something like SCTP.
*/
rcu_read_lock();
inet_opt = rcu_dereference(inet->inet_opt);
fl4 = &fl->u.ip4;
rt = skb_rtable(skb);
if (rt)
goto packet_routed;
/* Make sure we can route this packet. */
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (!rt) {
__be32 daddr;
/* Use correct destination address if we have options. */
daddr = inet->inet_daddr;
if (inet_opt && inet_opt->opt.srr)
daddr = inet_opt->opt.faddr;
/* If this fails, retransmit mechanism of transport layer will
* keep trying until route appears or the connection times
* itself out.
*/
rt = ip_route_output_ports(net, fl4, sk,
daddr, inet->inet_saddr,
inet->inet_dport,
inet->inet_sport,
sk->sk_protocol,
RT_CONN_FLAGS_TOS(sk, tos),
sk->sk_bound_dev_if);
if (IS_ERR(rt))
goto no_route;
sk_setup_caps(sk, &rt->dst);
}
skb_dst_set_noref(skb, &rt->dst);
packet_routed:
if (inet_opt && inet_opt->opt.is_strictroute && rt->rt_uses_gateway)
goto no_route;
/* OK, we know where to send it, allocate and build IP header. */
skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
skb_reset_network_header(skb);
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (tos & 0xff));
if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->protocol = sk->sk_protocol;
ip_copy_addrs(iph, fl4);
/* Transport layer set skb->h.foo itself. */
if (inet_opt && inet_opt->opt.optlen) {
iph->ihl += inet_opt->opt.optlen >> 2;
ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0);
}
ip_select_ident_segs(net, skb, sk,
skb_shinfo(skb)->gso_segs ?: 1);
/* TODO : should we use skb->sk here instead of sk ? */
skb->priority = sk->sk_priority;
skb->mark = sk->sk_mark;
res = ip_local_out(net, sk, skb);
rcu_read_unlock();
return res;
no_route:
rcu_read_unlock();
IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES);
kfree_skb(skb);
return -EHOSTUNREACH;
}
可以看到上面函数进行了如下工作:
- 相关合法性检查;
- 防火墙过滤;
- 对数据包是否需要分片发送进行检查;
- 进行可能的数据包缓存处理;
- 对多播和广播数据报是否需要回送本机进行检查;
- 调用函数 ip_local_out 进行处理。
函数调用了skb_rtable函数进行路由缓存,在本地构造好IP头部后接着调用ip_local_out进行数据处理,ip_local_out直接调用了__ip_local_out:
int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len);
ip_send_check(iph);
/* if egress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_out(sk, skb);
if (unlikely(!skb))
return 0;
skb->protocol = htons(ETH_P_IP);
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT,
net, sk, skb, NULL, skb_dst(skb)->dev,
dst_output);
}
它调用了一个钩子函数,可以看到这个钩子函数如果检查点LOCAL_OUT通过,会调用dst_output,我们继续跟踪:
static inline int dst_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
return skb_dst(skb)->output(net, sk, skb);
}
这里实际上调用了ip数据包输出函数ip_output:
int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb_dst(skb)->dev;
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUT, skb->len);
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING,
net, sk, skb, NULL, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}
这里同样是钩子函数,这个钩子函数如果检查点POST_ROUTING通过,会调用ip_finish_output,它实际调用__ip_finish_output,我们继续跟踪:
static int __ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
unsigned int mtu;
#if defined(CONFIG_NETFILTER) && defined(CONFIG_XFRM)
/* Policy lookup after SNAT yielded a new policy */
if (skb_dst(skb)->xfrm) {
IPCB(skb)->flags |= IPSKB_REROUTED;
return dst_output(net, sk, skb);
}
#endif
mtu = ip_skb_dst_mtu(sk, skb);
if (skb_is_gso(skb))
return ip_finish_output_gso(net, sk, skb, mtu);
if (skb->len > mtu || (IPCB(skb)->flags & IPSKB_FRAG_PMTU))
return ip_fragment(net, sk, skb, mtu, ip_finish_output2);
return ip_finish_output2(net, sk, skb);
}
这里如果skb长度超过了MTU,则需要ip_fragment函数进行分片,否则直接执行ip_finish_output2
static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct dst_entry *dst = skb_dst(skb);
struct rtable *rt = (struct rtable *)dst;
struct net_device *dev = dst->dev;
unsigned int hh_len = LL_RESERVED_SPACE(dev);
struct neighbour *neigh;
bool is_v6gw = false;
if (rt->rt_type == RTN_MULTICAST) {
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUTMCAST, skb->len);
} else if (rt->rt_type == RTN_BROADCAST)
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUTBCAST, skb->len);
/* Be paranoid, rather than too clever. */
if (unlikely(skb_headroom(skb) < hh_len && dev->header_ops)) {
struct sk_buff *skb2;
skb2 = skb_realloc_headroom(skb, LL_RESERVED_SPACE(dev));
if (!skb2) {
kfree_skb(skb);
return -ENOMEM;
}
if (skb->sk)
skb_set_owner_w(skb2, skb->sk);
consume_skb(skb);
skb = skb2;
}
if (lwtunnel_xmit_redirect(dst->lwtstate)) {
int res = lwtunnel_xmit(skb);
if (res < 0 || res == LWTUNNEL_XMIT_DONE)
return res;
}
rcu_read_lock_bh();
neigh = ip_neigh_for_gw(rt, skb, &is_v6gw);
if (!IS_ERR(neigh)) {
int res;
sock_confirm_neigh(skb, neigh);
/* if crossing protocols, can not use the cached header */
res = neigh_output(neigh, skb, is_v6gw);
rcu_read_unlock_bh();
return res;
}
rcu_read_unlock_bh();
net_dbg_ratelimited("%s: No header cache and no neighbour!\n",
__func__);
kfree_skb(skb);
return -EINVAL;
}
ip_finish_output2函数会检测skb的前部空间是否还能存储链路层首部。如果不够,就会申请更大的存储空间,最终会调用邻居子系统的输出函数neigh_output进行输出。
static inline int neigh_output(struct neighbour *n, struct sk_buff *skb,
bool skip_cache)
{
const struct hh_cache *hh = &n->hh;
if ((n->nud_state & NUD_CONNECTED) && hh->hh_len && !skip_cache)
return neigh_hh_output(hh, skb);
else
return n->output(n, skb);
}
输出分为有二层头缓存和没有两种情况,有缓存时调用neigh_hh_output进行快速输出,没有缓存时,则调用邻居子系统的输出回调函数进行慢速输出。不管执行哪个函数,最终都会调用dev_queue_xmit将数据包传入数据链路层:
static inline int neigh_hh_output(const struct hh_cache *hh, struct sk_buff *skb)
{
unsigned int hh_alen = 0;
unsigned int seq;
unsigned int hh_len;
do {
seq = read_seqbegin(&hh->hh_lock);
hh_len = READ_ONCE(hh->hh_len);
if (likely(hh_len <= HH_DATA_MOD)) {
hh_alen = HH_DATA_MOD;
/* skb_push() would proceed silently if we have room for
* the unaligned size but not for the aligned size:
* check headroom explicitly.
*/
if (likely(skb_headroom(skb) >= HH_DATA_MOD)) {
/* this is inlined by gcc */
memcpy(skb->data - HH_DATA_MOD, hh->hh_data,
HH_DATA_MOD);
}
} else {
hh_alen = HH_DATA_ALIGN(hh_len);
if (likely(skb_headroom(skb) >= hh_alen)) {
memcpy(skb->data - hh_alen, hh->hh_data,
hh_alen);
}
}
} while (read_seqretry(&hh->hh_lock, seq));
if (WARN_ON_ONCE(skb_headroom(skb) < hh_alen)) {
kfree_skb(skb);
return NET_XMIT_DROP;
}
__skb_push(skb, hh_len);
return dev_queue_xmit(skb);
}
调试跟踪截图:
接收
网络层接收时入口函数为ip_recv
* IP receive entry point
*/
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,
struct net_device *orig_dev)
{
struct net *net = dev_net(dev);
skb = ip_rcv_core(skb, net);
if (skb == NULL)
return NET_RX_DROP;
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
}
跟踪钩子函数(监测点为PRE_ROUTING),它调用ip_rcv_finish:
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
int ret;
/* if ingress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_rcv(skb);
if (!skb)
return NET_RX_SUCCESS;
ret = ip_rcv_finish_core(net, sk, skb, dev);
if (ret != NET_RX_DROP)
ret = dst_input(skb);
return ret;
}
继续跟踪dst_input,它调用了ip_local_deliver:
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
struct net *net = dev_net(skb->dev);
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,
net, NULL, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
有分片则执行分片操作,否则钩子检测点LOCAL_IN,继续跟踪ip_local_deliver_finish:
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
__skb_pull(skb, skb_network_header_len(skb));
rcu_read_lock();
ip_protocol_deliver_rcu(net, skb, ip_hdr(skb)->protocol);
rcu_read_unlock();
return 0;
}
进行了加锁释放锁操作,期间调用了ip_protocol_deliver_rcu:
void ip_protocol_deliver_rcu(struct net *net, struct sk_buff *skb, int protocol)
{
const struct net_protocol *ipprot;
int raw, ret;
resubmit:
raw = raw_local_deliver(skb, protocol);
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot) {
if (!ipprot->no_policy) {
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
kfree_skb(skb);
return;
}
nf_reset_ct(skb);
}
ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv,
skb);
if (ret < 0) {
protocol = -ret;
goto resubmit;
}
__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
} else {
if (!raw) {
if (xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
__IP_INC_STATS(net, IPSTATS_MIB_INUNKNOWNPROTOS);
icmp_send(skb, ICMP_DEST_UNREACH,
ICMP_PROT_UNREACH, 0);
}
kfree_skb(skb);
} else {
__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
consume_skb(skb);
}
}
}
数据至此离开IP层。调试跟踪截图:
链路层
发送
上面提到,链路层入口为dev_queue_xmit,它实际调用__dev_queue_xmit。
-
设备在调用这个函数之前,必须设置设备优先级 和缓冲区buffer
-
如果此函数发送失败,会返回一个负数的Error number,不过即使返回正数,也不一定保证发送成功,封包也许会被网络拥塞给drop掉
-
这个函数也可以从队列规则中返回error,NET_XMIT_DROP, 这个错误是一个整数,所以错误也有可能是整数,也验证了点2 ,所以在协议栈的上一层使用这个函数的时候,可能需要注意error的处理部分
static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev)
{
struct net_device *dev = skb->dev;
struct netdev_queue *txq;
struct Qdisc *q;
int rc = -ENOMEM;
bool again = false;
skb_reset_mac_header(skb);
if (unlikely(skb_shinfo(skb)->tx_flags & SKBTX_SCHED_TSTAMP))
__skb_tstamp_tx(skb, NULL, skb->sk, SCM_TSTAMP_SCHED);
/* Disable soft irqs for various locks below. Also
* stops preemption for RCU.
*/
rcu_read_lock_bh();
skb_update_prio(skb);
qdisc_pkt_len_init(skb);
#ifdef CONFIG_NET_CLS_ACT
skb->tc_at_ingress = 0;
# ifdef CONFIG_NET_EGRESS
if (static_branch_unlikely(&egress_needed_key)) {
skb = sch_handle_egress(skb, &rc, dev);
if (!skb)
goto out;
}
# endif
#endif
/* If device/qdisc don't need skb->dst, release it right now while
* its hot in this cpu cache.
*/
if (dev->priv_flags & IFF_XMIT_DST_RELEASE)
skb_dst_drop(skb);
else
skb_dst_force(skb);
txq = netdev_core_pick_tx(dev, skb, sb_dev);
q = rcu_dereference_bh(txq->qdisc);
trace_net_dev_queue(skb);
if (q->enqueue) {
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
/* The device has no queue. Common case for software devices:
* loopback, all the sorts of tunnels...
* Really, it is unlikely that netif_tx_lock protection is necessary
* here. (f.e. loopback and IP tunnels are clean ignoring statistics
* counters.)
* However, it is possible, that they rely on protection
* made by us here.
* Check this and shot the lock. It is not prone from deadlocks.
*Either shot noqueue qdisc, it is even simpler 8)
*/
if (dev->flags & IFF_UP) {
int cpu = smp_processor_id(); /* ok because BHs are off */
if (txq->xmit_lock_owner != cpu) {
if (dev_xmit_recursion())
goto recursion_alert;
skb = validate_xmit_skb(skb, dev, &again);
if (!skb)
goto out;
HARD_TX_LOCK(dev, txq, cpu);
if (!netif_xmit_stopped(txq)) {
dev_xmit_recursion_inc();
skb = dev_hard_start_xmit(skb, dev, txq, &rc);
dev_xmit_recursion_dec();
if (dev_xmit_complete(rc)) {
HARD_TX_UNLOCK(dev, txq);
goto out;
}
}
HARD_TX_UNLOCK(dev, txq);
net_crit_ratelimited("Virtual device %s asks to queue packet!\n",
dev->name);
} else {
/* Recursion is detected! It is possible,
* unfortunately
*/
recursion_alert:
net_crit_ratelimited("Dead loop on virtual device %s, fix it urgently!\n",
dev->name);
}
}
rc = -ENETDOWN;
rcu_read_unlock_bh();
atomic_long_inc(&dev->tx_dropped);
kfree_skb_list(skb);
return rc;
out:
rcu_read_unlock_bh();
return rc;
}
从对_dev_queue_xmit函数的分析来看,发送报文有2中情况:
-
有拥塞控制策略的情况,比较复杂,但是目前最常用
-
没有enqueue的状况,比较简单,直接发送到driver,如loopback等使用
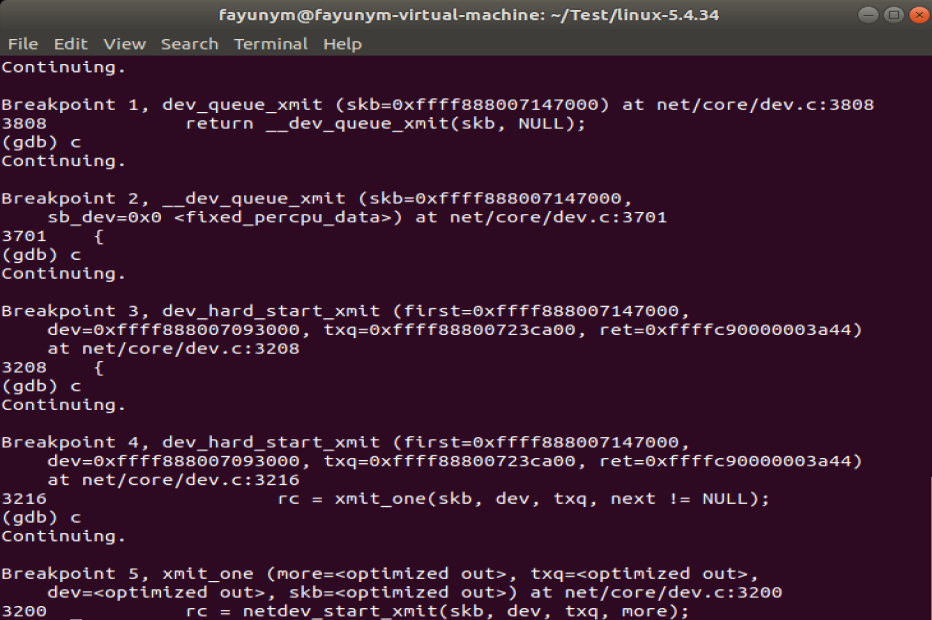
先检查是否有enqueue的规则,如果有即调用__dev_xmit_skb进入拥塞控制的flow,如果没有且txq处于On的状态,那么就调用dev_hard_start_xmit直接发送到driver,我们分析dev_hard_start_xmit:
struct sk_buff *dev_hard_start_xmit(struct sk_buff *first, struct net_device *dev,
struct netdev_queue *txq, int *ret)
{
struct sk_buff *skb = first;
int rc = NETDEV_TX_OK;
while (skb) {
struct sk_buff *next = skb->next;
skb_mark_not_on_list(skb);
rc = xmit_one(skb, dev, txq, next != NULL);
if (unlikely(!dev_xmit_complete(rc))) {
skb->next = next;
goto out;
}
skb = next;
if (netif_tx_queue_stopped(txq) && skb) {
rc = NETDEV_TX_BUSY;
break;
}
}
out:
*ret = rc;
return skb;
}
dev_hard_start_xmit函数会循环调用xmit_one函数,直到将待输出的数据包提交给网络设备的输出接口,完成数据包的输出:
static int xmit_one(struct sk_buff *skb, struct net_device *dev,
struct netdev_queue *txq, bool more)
{
unsigned int len;
int rc;
if (dev_nit_active(dev))
dev_queue_xmit_nit(skb, dev);
len = skb->len;
trace_net_dev_start_xmit(skb, dev);
rc = netdev_start_xmit(skb, dev, txq, more);
trace_net_dev_xmit(skb, rc, dev, len);
return rc;
}
在xmit_one中调用netdev_start_xmit函数。一旦网卡完成报文发送,将产生中断通知 CPU,然后驱动层中的中断处理程序就可以删除保存的 skb。
调试跟踪截图:
接收
入口函数为net_rx_action,
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
unsigned long time_limit = jiffies +
usecs_to_jiffies(netdev_budget_usecs);
int budget = netdev_budget;
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
if (list_empty(&list)) {
if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
goto out;
break;
}
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 ||
time_after_eq(jiffies, time_limit))) {
sd->time_squeeze++;
break;
}
}
local_irq_disable();
list_splice_tail_init(&sd->poll_list, &list);
list_splice_tail(&repoll, &list);
list_splice(&list, &sd->poll_list);
if (!list_empty(&sd->poll_list))
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
net_rps_action_and_irq_enable(sd);
out:
__kfree_skb_flush();
}
在net_rx_action函数中会去调用设备的napi_poll函数, 它是设备自己注册的。在设备的napi_poll函数中, 它负责调用napi_gro_receive函数:
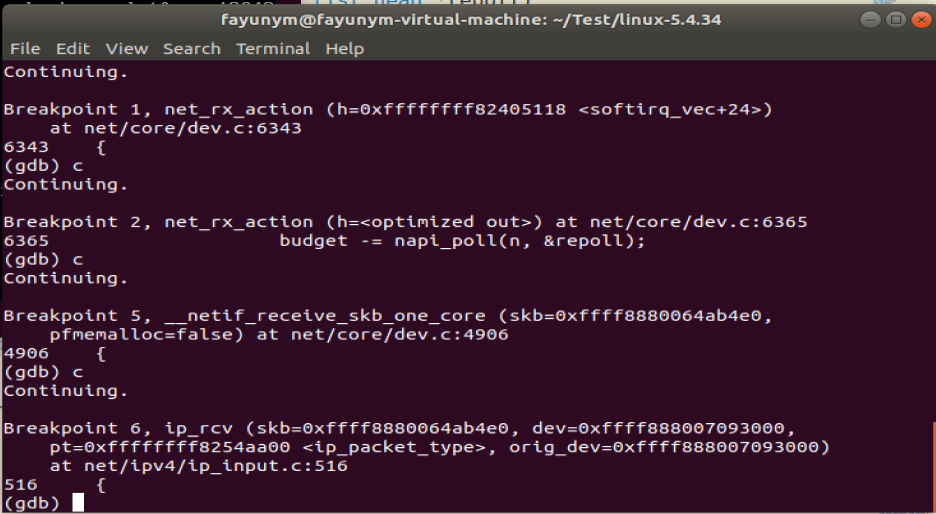
napi_gro_receive用来将网卡上的数据包发给协议栈处理。它会调用 netif_receive_skb_core。而它会调用__netif_receive_skb_one_core,将数据包交给上层 ip_rcv 进行处理。
调试截图:
时序图
通过对linux系统源码剖析,可以大致搞清楚整个TCP/IP协议栈的调用过程,用时序图总结如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号