OO_BLOG3_规格化设计(JML学习)
JML语言学习笔记
理论基础
1. 注释结构
2. JML表达式
- 原子表达式,量化表达式,集合表达式,操作符,etc.
3. 方法规格
- 前置条件(pre-condition)
- 后置条件(post-condition)
- 副作用范围限定(side-effects)
4. 类型规格
- 不变式(invariant)
- 状态变化约束(constraint)
应用工具链情况
1. OpenJML & SMT Solver
- 首先由OpenJML将JML规格转换乘SMT-LIB格式的代码,然后调用SMT solver进行检查。用于静态检查。
2. JMLUnitNG
- 根据规格自动生成测试文件。用于自动测试。
3. JMLdoc
- 可以快速生成JML文档的相关文件
4. Junit
- Junit主要用于单元化测试与一定的自动化测试,配合JML食用效果极佳。
JMLUnit/JMLUnitNG
1. 前期准备
- 简单代码示例与jar包配置


2. 命令行操作
java -jar jmlunitng.jar src/Demo.java
javac -cp jmlunitng.jar src/*.java
3. 测试结果


4. 结果分析
- 我们可以看出,自动生成的测试样例对各种极端情况进行了测试,具有较好的覆盖性。
- 但是,在试验过程中,JML测试的局限性也被暴露出来了。
UNIT3 作业分析
作业 3-1 实现两个容器类Path和PathContainer
1. 架构设计
1)度量分析
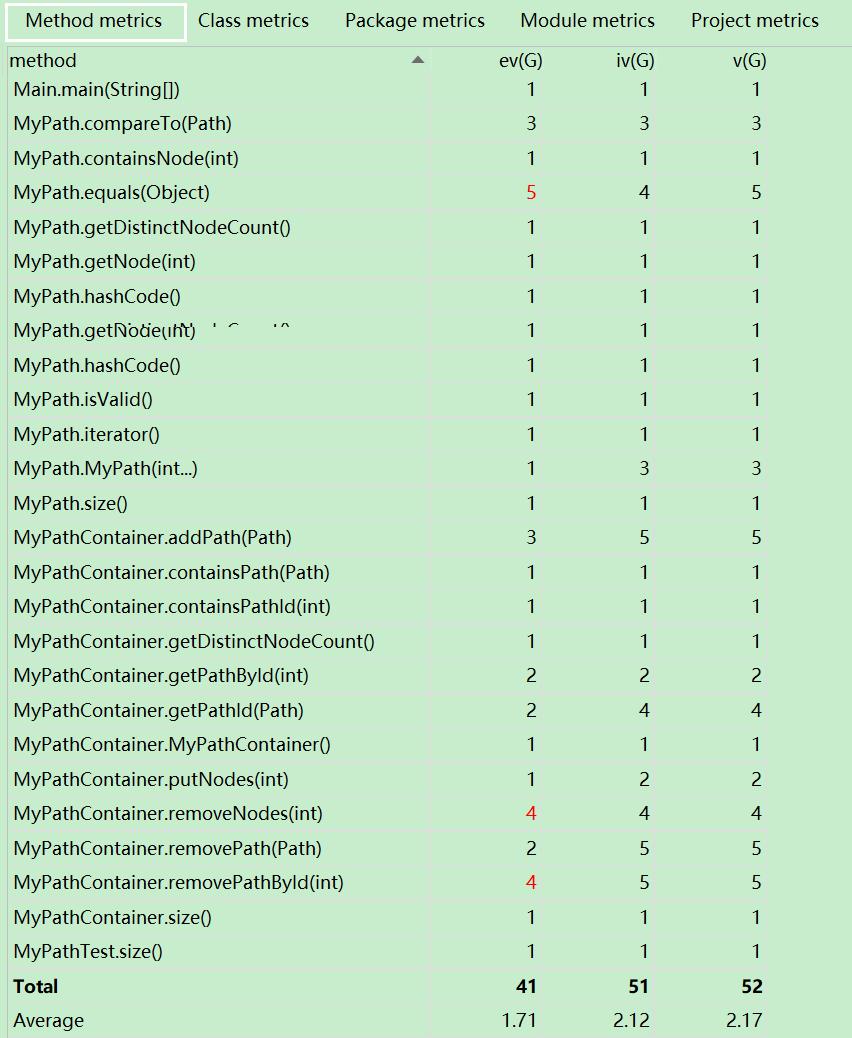
2)结构分析
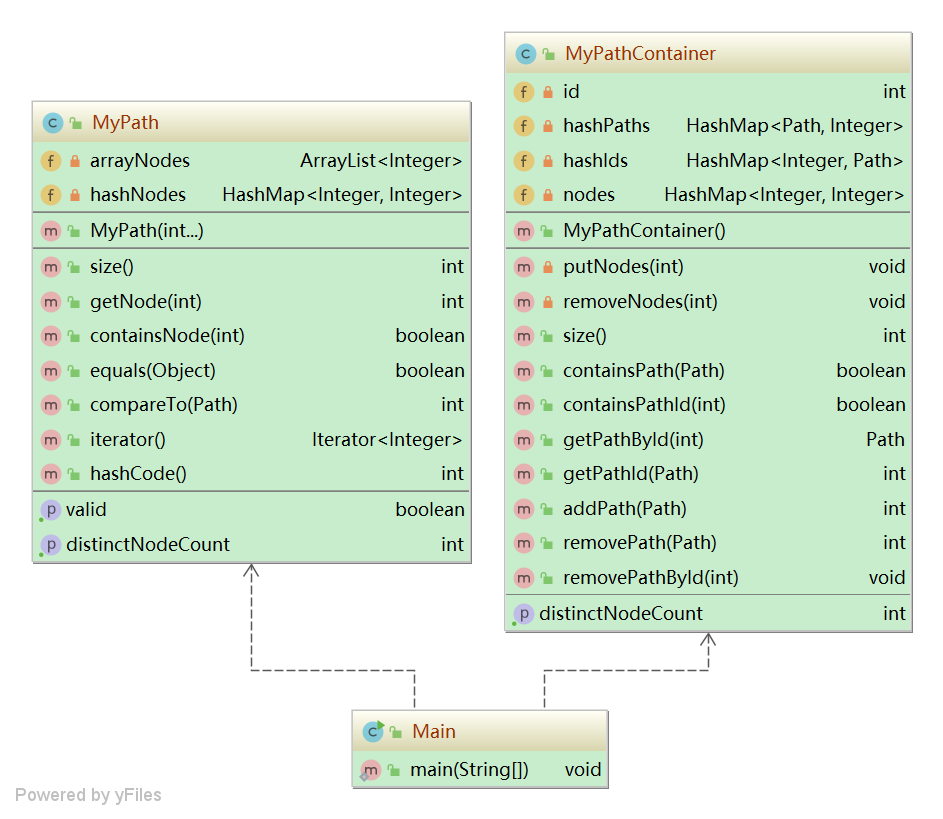
3)算法分析
-
MyPath
-
// path的存储结构,用来顺序存储结点 private ArrayList<Integer> arrayNodes; // 用来存储一条path中的node的个数(无重复)。key:结点名称;value:该结点出现的次数 private HashMap<Integer, Integer> hashNodes; -
ADD: 1)读入一个结点数组 2)将结点顺序存入arrayNodes 3)遍历结点数组,对于任一结点node,若node不在hashNodes中,即存入(node, 1);若已存在,即存入(node, value + 1)。
-
-
MyPathContainer
-
private int id = 0; // pathID private HashMap<Path, Integer> hashPaths; // Path --> PathID private HashMap<Integer, Path> hashIds; // PathID --> Path private HashMap<Integer, Integer> nodes; // Node --> frequentNumber -
ADD: 原理与path相同 REMOVE: 1)hashIds.remove(pathID),hashPaths.remove(path) 2)对于path中的每一个node,(设node的出现次数为frequentNumber),若frequentNumber=1,则将node从nodes中移除;若frequentNumber>1,则 nodes.replace(node, frequentNumber-1)。
-
2. BUG分析
1)bug情况
- 由于测试数据量的限制,程序在评测与互测环节没有出现错误。
2)修复情况
- 该程序存在一些不优美的地方,如MyPath中,利用HashMap来存储不同结点是复杂的,可以说是自己造了个轮子,改正方法为使用HashSet进行存储,通过容器的特性来减少手动判断。
作业 3-2 实现容器类Path和数据结构类Graph
1. 架构设计
1)度量分析
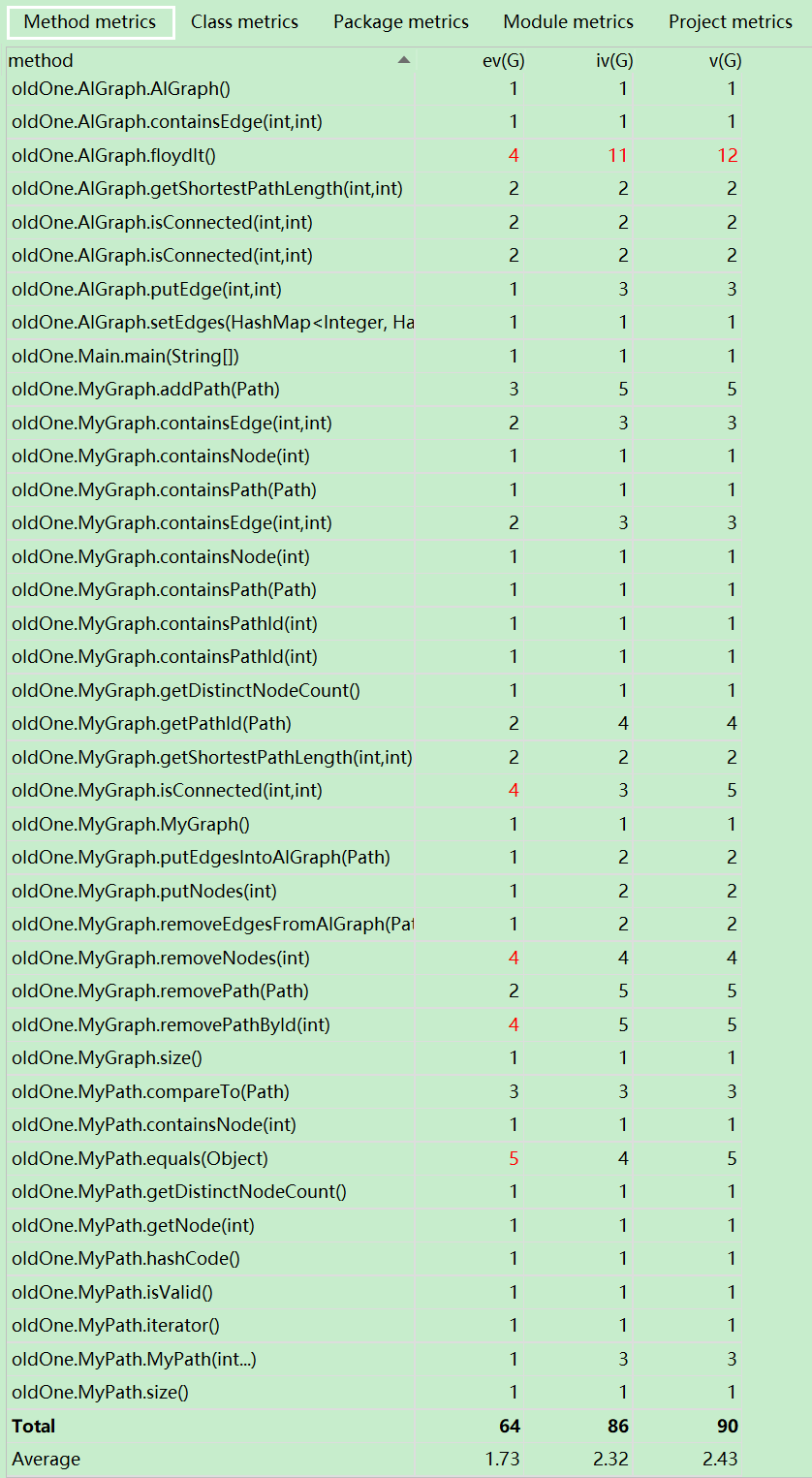
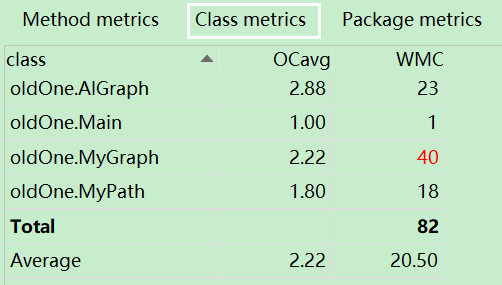
2)结构分析
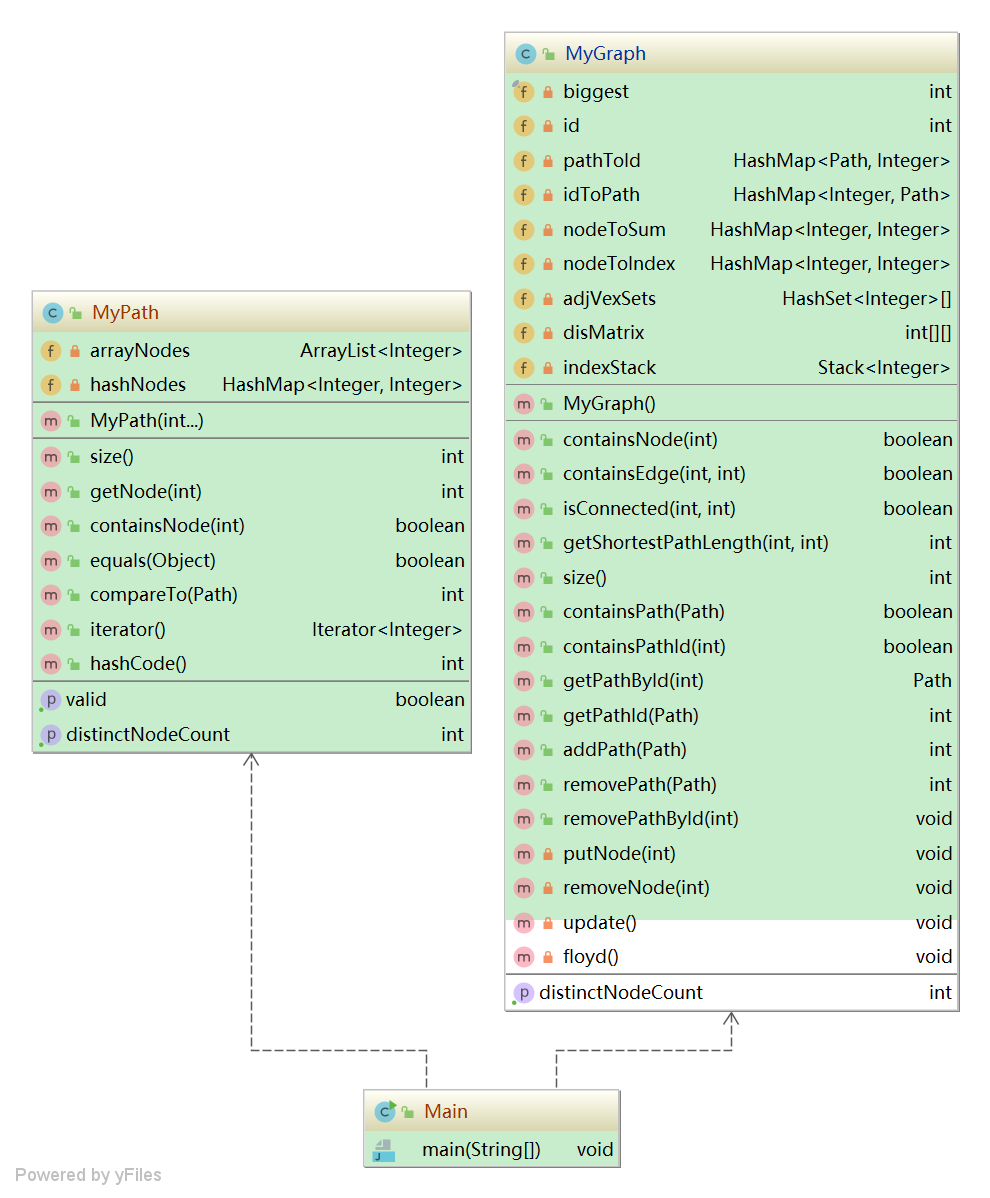
3)算法分析
-
AlGraph
-
// alGraph: node1 --> (node2 -> node2_frequentNumber) private HashMap<Integer, HashMap<Integer, Integer>> alGraph; // edges: node1 --> (node2 -> shortestPathLength_From_Node1_To_Node2) private HashMap<Integer, HashMap<Integer, Integer>> edges; -
// 由原始图(alGraph)生成距离图(edges)的算法 ———— Floyd算法 for (k = 0; k< MAX; k++) for (i = 0; i < MAX; i++) for (j = 0; j < MAX; j++) if (Graph[i][j] > Graph[i][k] + Graph[k][j]) Graph[i][j] = Graph[i][k] + Graph[k][j]; -
public boolean containsEdge(int node1, int node2) { return alGraph.get(node1).containsKey(node2); } public boolean isConnected(int node1, int node2) { if (node1 == node2) return true; else return edges.get(node1).containsKey(node2); } public int getShortestPathLength(int node1, int node2) { if (node1 == node2) return 0; else return edges.get(node1).get(node2); }
-
4)迭代中对架构的重构
- AlGraph继承了上一次作业中的PathContainer,并进行了适当的扩充(具体扩充见如上算法分析)。
2. BUG分析
1)bug情况
- 测试数据量增大时,程序出现
CPU_TIME_LIMIT_EXCEED的错误。 - 原因(据我分析):在Floyd算法中加入的大量的判断,当数据量增大时,造成CPU的负担过大,运算超时。
2)修复情况
- 重构后UML图
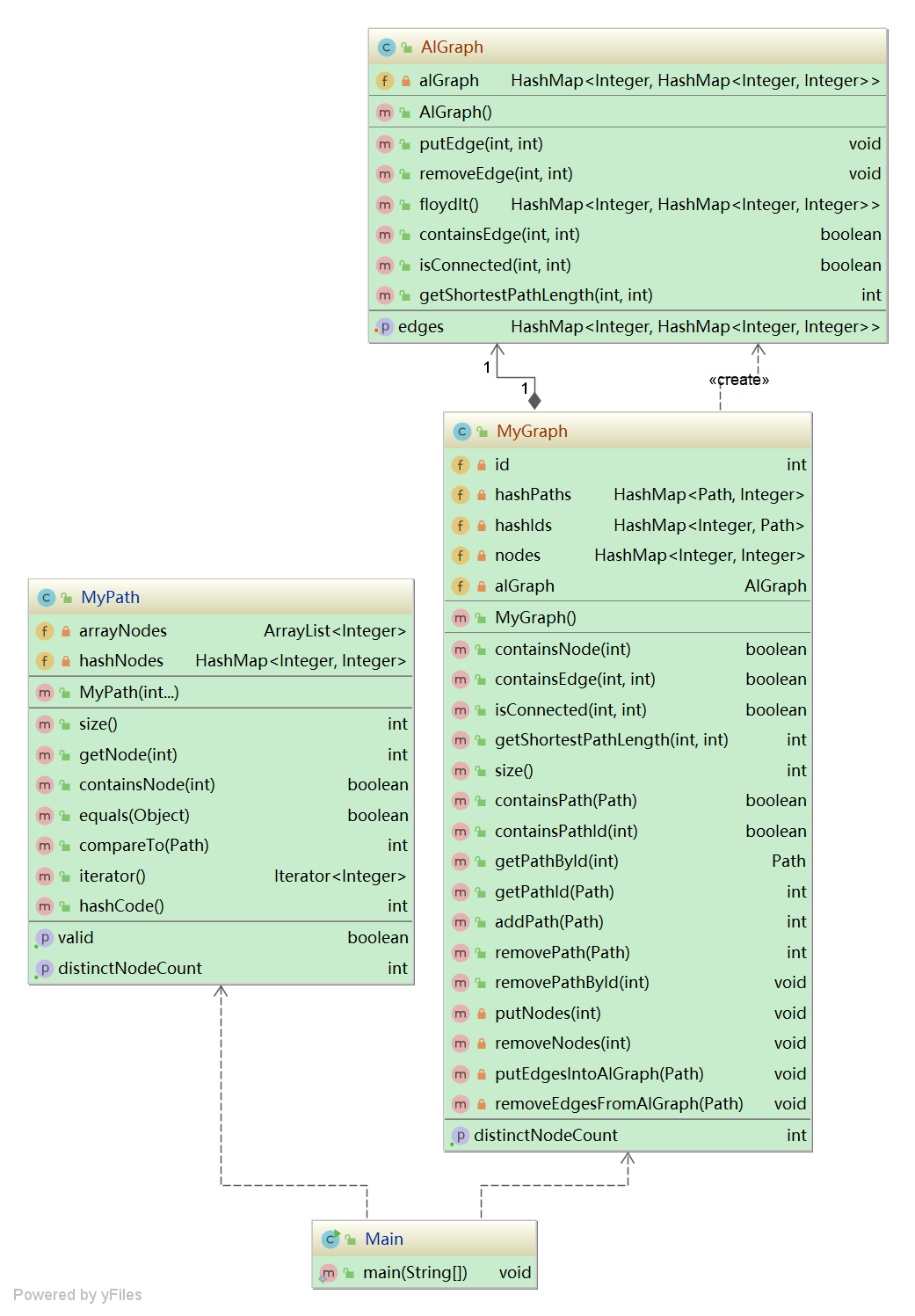
-
算法分析
-
private final int biggest = 999999999; // 极大数(自由定义,小于2^31即可) private int id = 0; // PathID(同上一次作业) private HashMap<Path, Integer> pathToId; // Path --> PathID(同上一次作业) private HashMap<Integer, Path> idToPath; // PathID --> Path(同上一次作业) private HashMap<Integer, Integer> nodeToSum; // Node --> Node_Sum(同上一次作业) private HashMap<Integer, Integer> nodeToIndex; // Node --> Node_index_in_matrix private HashSet<Integer>[] adjVexSets; // 临界表:Node--Set{node1, node2, ...} private int[][] disMatrix; // Graph生成的存储各点之间距离的距离矩阵 private Stack<Integer> indexStack; // 用来维护node<->index的映射的栈 -
'映射关系建立机制,搭建点与数组下标的关系 if put_New_Node_Into_Graph then bond_NewNode_to_IndexStack.pop() else if remove_Node_From_Graph then indexStack.push(oldNode.index)
-
3)前后对比
-
// 原程序,floyd部分代码 for (int k : tempEdges.keySet()) for (int i : tempEdges.keySet()) for (int j : tempEdges.keySet()) if (tempEdges.get(i).containsKey(k) && tempEdges.get(k).containsKey(j)) { int via = tempEdges.get(i).get(k) + tempEdges.get(k).get(j); if (tempEdges.get(i).containsKey(j)) { if (tempEdges.get(i).get(j) > via) { tempEdges.get(i).replace(j, via); } } else { tempEdges.get(i).put(j, via); } } -
// 重构后,floyd部分代码 for (int k = 0; k < 255; k++) for (int i = 0; i < 255; i++) for (int j = 0; j < 255; j++) if (disMatrix[i][j] > (newDis = disMatrix[i][k] + disMatrix[k][j])) disMatrix[i][j] = newDis;
作业 3-3 实现容器类Path,地铁系统类RailwaySystem
1. 架构设计
1)度量分析
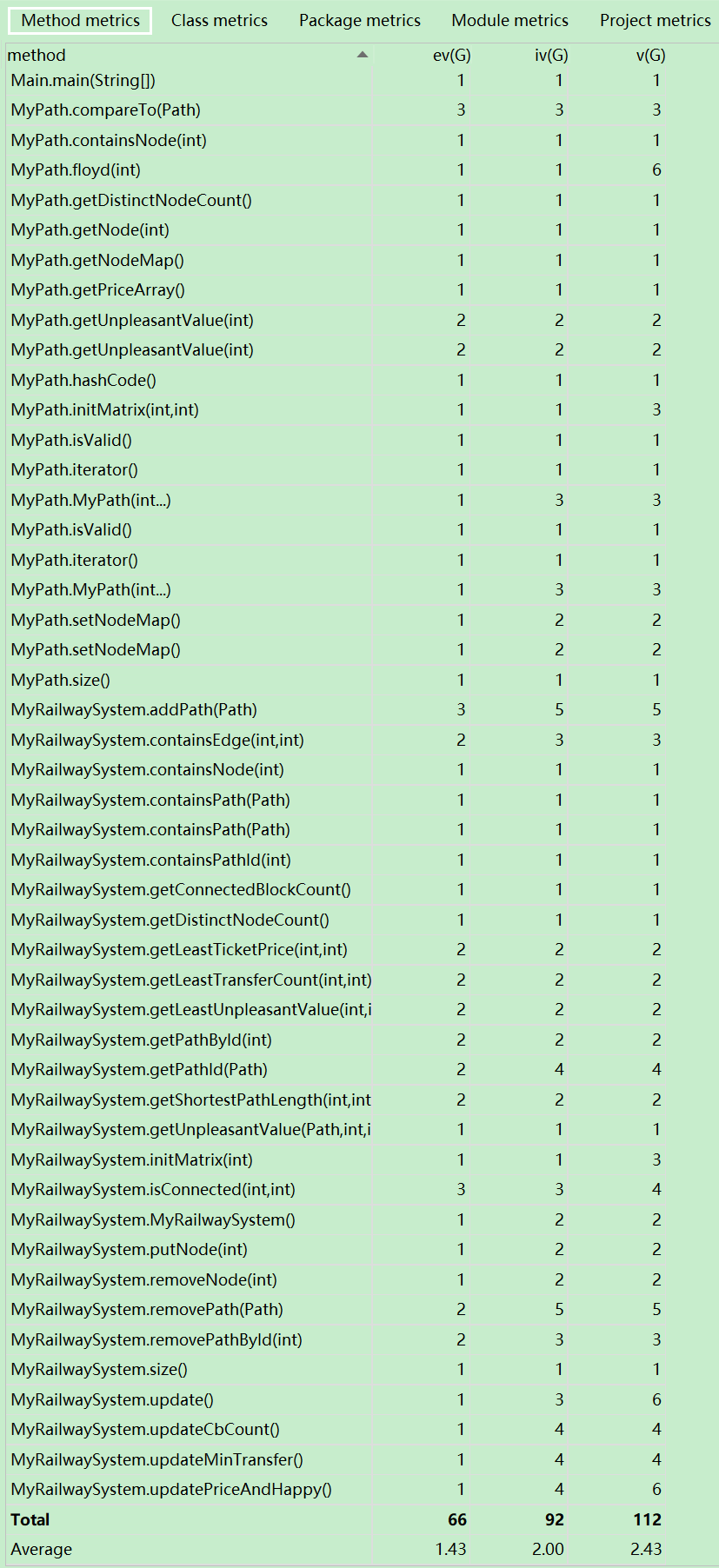
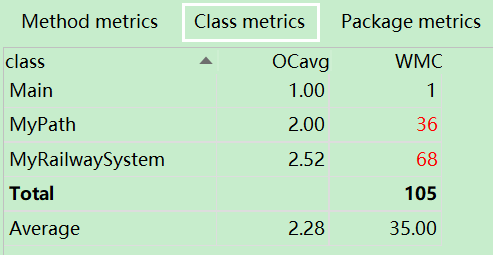
2)结构分析
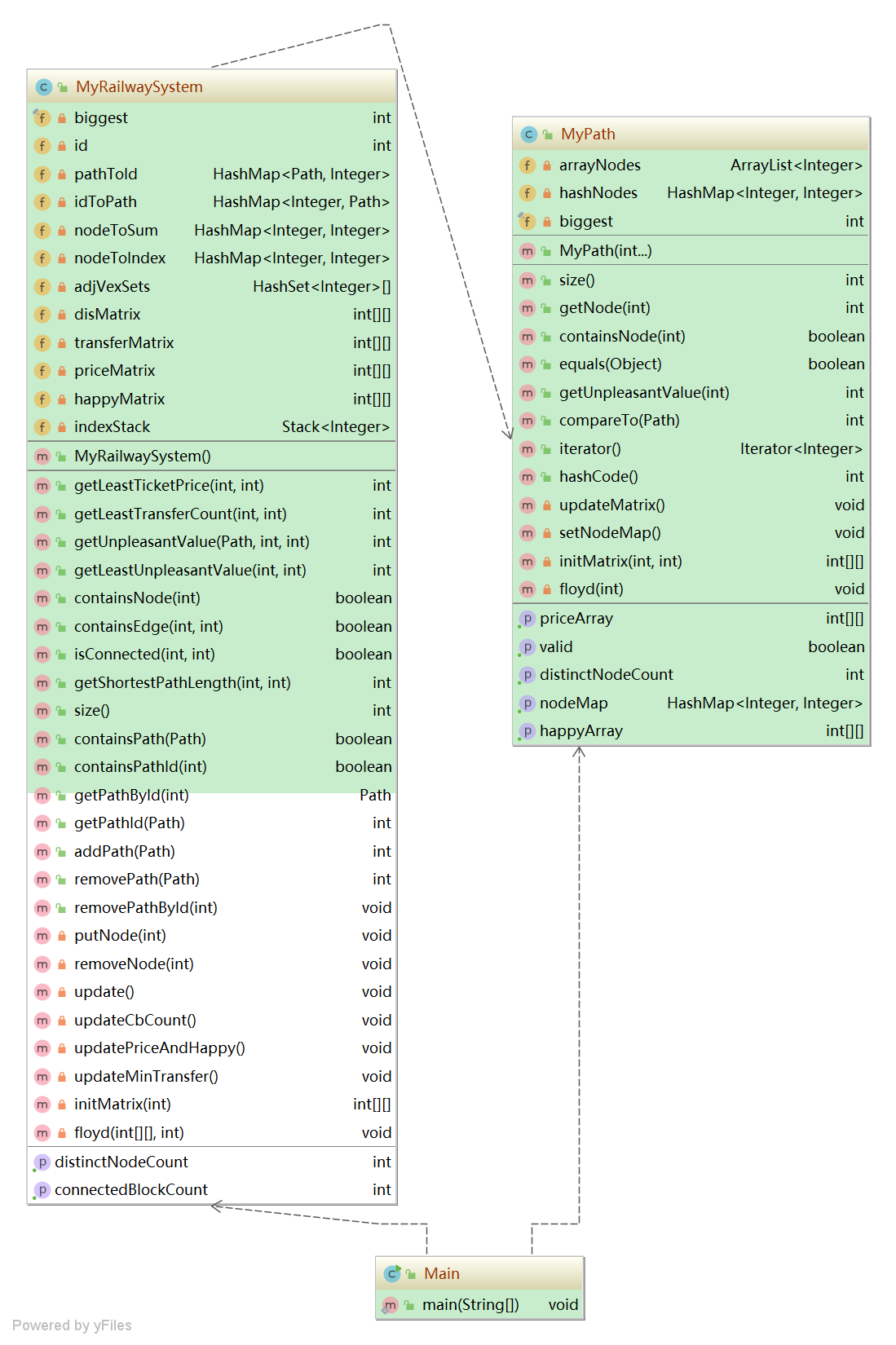
3)算法分析
-
MyRailwaySystem
-
private int cbCount = 0; // 连通块个数 private int[][] disMatrix; // 距离矩阵 private int[][] transferMatrix; // 最小换乘矩阵 private int[][] priceMatrix; // 价格矩阵 private int[][] happyMatrix; // 最低不满意度矩阵 -
// 下面是算法的伪代码,以价格矩阵的更新为例,其它类似 private void updatePriceMatrix() { priceMatrix = initMatrix(2); for (Each path : paths) { maxSize = path.size(); priceArray = ((MyPath)path).getPriceArray(); nodeMap = ((MyPath)path).getNodeMap(); for (Each node1, node2 : nodeMap) if (priceArray[tempId1][tempId2] + 2 < priceMatrix[index1][index2]) priceMatrix[index1][index2] = priceMatrix[index2][index1] = priceArray[tempId2][tempId1] + 2; } floyd(priceMatrix, 125); }
-
4)迭代中对架构的重构
-
MyPath
-
在MyPath添加了两个距离矩阵,用来存储一个Path(地铁线路)内部的(加权)距离信息。
-
首先,将Path构建成两个加权无向图(权值分别为价格和满意度);然后,通过Floyd算法生成各自的距离矩阵,存储下来。
-
private int[][] priceArray; // 加权(价钱)距离矩阵 private int[][] happyArray; // 加权(满意度)距离矩阵 // 以下是算法的伪代码 private void updateMatrix() { setNodeMap(); // 重新建立映射关系 priceArray = initMatrix(nodeCount, 2); // 距离矩阵初始化 happyArray = initMatrix(nodeCount, 32); // 距离矩阵初始化 for (Each node1, node2 :nodes) { // 建图赋权 priceArray[node1.index][node2.index] = priceArray[node2.index][node1.index] = 1; happyArray[node1.index][node2.index] = happyArray[node2.index][node1.index] = = CalculatePleasure(); } floyd(priceArray); floyd(happyArray); // 计算各点之间距离 }
-
2. BUG分析
1)bug情况
- 这种算法在测试数据(最多结点数以及最多图变动指令数)有所约束时,展现出非常出色的性能。在强测与互测中均未出现错误。
- 但是,我的代码结构有着较为严重的问题:几乎完全面向过程的写法严重违反了OOP的原则;多个相似结构重复计算等。
2)修复情况
- 尚未进行代码重构,仅对课程组给出的标程进行了研究,并进行了简单的算法优化尝试。
规格撰写的心得与体会
- 规格化设计和契约式编程,让人如沐清风,受益匪浅。 其实这次的代码工程量很大,但是由于课程组给出的JML的引导以及课程组已经将我们需要填写的代码抽象成了接口,这使得我们在写代码时会产生一种错觉——“这是面向对象课程吗?”、“这是数据结构补习课吧!”…… 这正是规格化设计和契约式编程 的巨大作用。
- JML语言——好用不好写。 JML语言书写的困难度过高(从课程组编写JML出现的各种状况可以看出),给我的感觉是“可远观而不可亵玩”。而且,由于DDL过多加上学习资料不足(网上、课程资料都几乎为零),我缺乏自己动手写JML的动力。
- 没有指引,路程变成了痛苦的过程。也许,是因为JML这一课还在探索阶段,课程对JML编写、检测、使用的工具的讲解和介绍颇少,基本全靠讨论区和大佬们的指点,自己摸索着完成任务。固然,可以说这是对我们自主学习能力的养成,但是,有必要吗?我相信JML单元会一步步从碎片化走向体系化,更加容易上手。
- 在路上 ……

 浙公网安备 33010602011771号
浙公网安备 33010602011771号