

深入理解C#(第3版)-- 【附录】附录B .NET 中的泛型集合(学习笔记)
B.1 接口
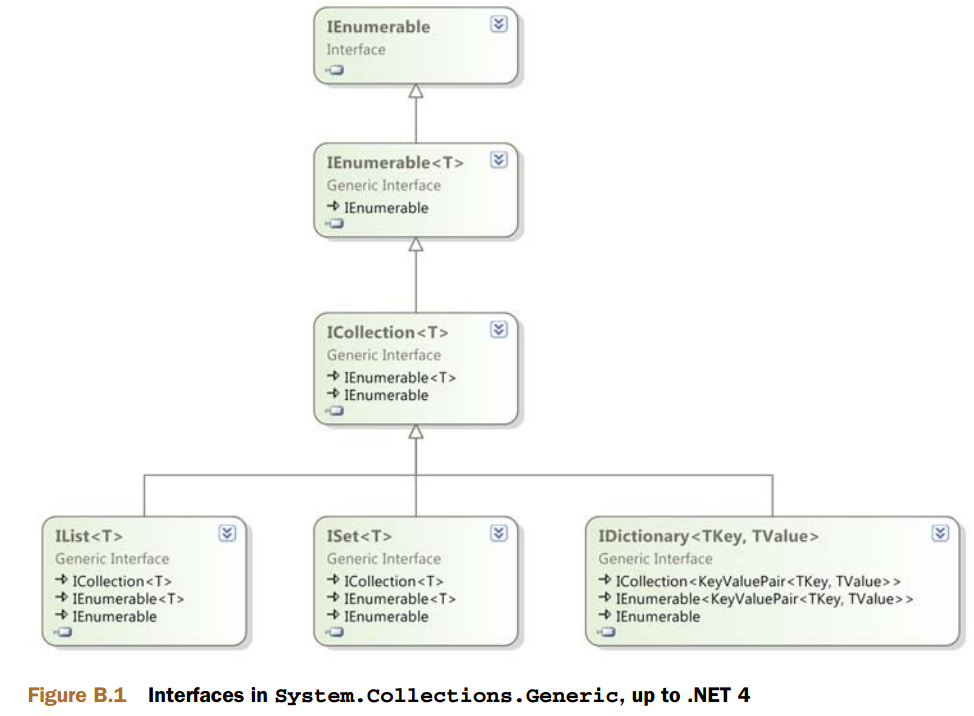
几乎所有要学习的接口都位于System.Collections.Generic 命名空间。
IEnumerable<T>
最基础的泛型集合接口为IEnumerable<T>,表示可迭代的项的序列。
IEnumerable<T>可以请求一个IEnumerator<T>类型的迭代器。由于分离了可迭代序列和迭代器,这样多个迭代器可以同时独立地操作同一个序列。
如果从数据库角度来考虑,表就是IEnumerable<T>,而游标是IEnumerator<T>。
本附录仅有的两个可变(variant )集合接口为.NET 4中的IEnumerable<out T> 和IEnumerator<out T> ;其他所有接口的元素类型值均可双向进出,因此必须保持不变。
ICollection<T>
接下来是ICollection<T>,它扩展了IEnumerable<T>,添加了两个属性(Count和IsReadOnly)、变动方法( Add 、Remove和Clear)、CopyTo(将内容复制到数组中)和Contains(判断集合是否包含特殊的元素)。
所有标准的泛型集合实现都实现了该接口。
IList<T>
IList<T> 全都是关于定位的:它提供了一个索引器、InsertAt 和RemoveAt (分别与Add和Remove 相同,但可以指定位置),以及IndexOf(判断集合中某元素的位置)。
通常认为可以快速通过索引对IList<T> 进行随机访问。
IDictionary<TKey, TValue>
IDictionary<TKey, TValue> 表示一个独一无二的键到它所对应的值的映射。值不必是唯一的,而且也可以为空;而键不能为空。
可以将字典看成是键/ 值对的集合,因此IDictionary<TKey, TValue>扩展了ICollection<KeyValuePair<TKey, TValue>>。
获取值可以通过索引器或TryGetValue 方法;与非泛型IDictionary 类型不同,如果试图用不存在的键获取值,IDictionary<TKey, TValue> 的索引器将抛出一个KeyNotFoundException。TryGetValue 的目的就是保证在用不存在的键进行探测时还能正常运行。
ISet<T>
ISet<T>是.NET 4 新引入的接口,表示唯一值集。
它反过来应用到了.NET 3.5 中的HashSet<T>上,以及.NET 4 引入的一个新的实现——SortedSet<T>。
B.2 列表
B.2.1 List<T>
在大多数情况下,List<T>都是列表的默认选择。它实现了IList<T> ,因此也实现了ICollection<T>、IEnumerable<T> 和IEnumerable。
List<T>在内部保存了一个数组,它跟踪列表的逻辑大小和后台数组的大小。
向列表中添加元素,在简单情况下是设置数组的下一个值,或(如果数组已经满了)将现有内容复制到新的更大的数组中,然后再设置值。这意味着该操作的复杂度为O(1) 或O(n ),取决于是否需要复制值。
从List<T>中移除元素需要复制所有的后续元素,因此其复杂度为O(n k) ,其中k 为移除元素的索引。从列表尾部移除要比从头部移除廉价得多。另一方面,如果要通过值移除元素而不是索引(通过Remove 而不是RemoveAt ),那么不管元素位置如何复杂度都为O(n ) :每个元素都将得到平等的检查或打乱。
List<T>中的各种方法在一定程度上扮演着LINQ前身的角色。ConvertAll 可进行列表投影;FindAll对原始列表进行过滤,生成只包含匹配指定谓词的值的新列表。Sort使用类型默认的或作为参数指定的相等比较器进行排序。但Sort与LINQ中的OrderBy有个显著的不同:Sort修改原始列表的内容,而不是生成一个排好序的副本。并且,Sort是不稳定的,而OrderBy是稳定的;使用Sort时,原始列表中相等元素的顺序可能会不同。
List<T>中略有争议的部分是ForEach方法。“foreach” vs “ForEach”
B.2.2 数组
所有数组都直接派生自System.Array,也是唯一的CLR 直接支持的集合。
一维数组实现了IList<T> (及其扩展的接口)和非泛型的IList、ICollection 接口;矩形数组只支持非泛型接口。数组从元素角度来说是易变的,从大小角度来说是固定的。
引用类型的数组通常是协变的;如Stream[] 引用可以隐式转换为Object[] ,并且存在显式的反向转换。
CLR 包含两种不同风格的数组。向量是下限为0的一维数组,其余的统称为数组(array)。向量的性能更佳,是C#中最常用的。T[][] 形式的数组仍然为向量,只不过元素类型为T[] ;只有C#中的矩形数组,如string[10, 20],属于CLR 术语中的数组。
Arrays considered somewhat harmful
B.2.3 LinkedList<T>
什么时候列表不是list呢?答案是当它为链表的时候。
LinkedList<T> 在很多方面都是一个列表,特别的,它是一个保持项添加顺序的集合——但它却没有实现IList<T> 。因为它无法遵从通过索引进行访问的隐式契约。
它是经典的计算机科学中的双向链表:包含头节点和尾节点,每个节点都包含对链表中前一个节点和后一个节点的引用。每个节点都公开为一个LinkedListNode<T>,这样就可以很方便地在链表的中部插入或移除节点。链表显式地维护其大小,因此可以访问Count属性。
在空间方面,链表比维护后台数组的列表效率要低,同时它还不支持索引操作,但在链表中的任意位置插入或移除元素则非常快,前提是只要在相关位置存在对该节点的引用。这些操作的复杂度为O(1) ,因为所需要的只是对周围的节点修改前/后的引用。插入或移除头尾节点属于特殊情况,通常可以快速访问需要修改的节点。迭代(向前或向后)也是有效的,只需要按引用链的顺序即可。
尽管LinkedList<T> 实现了Add 等标准方法(向链表末尾添加节点),我还是建议使用显式的AddFirst 和AddLast方法,这样可以使意图更清晰。它还包含匹配的RemoveFirst 和RemoveLast方法,以及First 和Last属性。所有这些操作返回的都是链表中的节点而不是节点的值;如果链表是空(empty )的,这些属性将返回空(null )。
B.2.4 Collection<T> 、BindingList<T>、ObservableCollection<T>和 KeyedCollection<TKey, TItem>
Collection<T>
Collection<T> 与我们将要介绍的剩余列表一样,位于System.Collections.ObjectModel命名空间。与List<T>类似,它也实现了泛型和非泛型的集合接口。
常扮演其他列表的包装器的角色:要么在构造函数中指定一个列表,要么在后台新建一个List<T>。所有对于集合的变动行为,都通过受保护的虚方法(InsertItem、SetItem、RemoveItem和ClearItems)实现。
BindingList<T>和ObservableCollection<T>
BindingList<T>和ObservableCollection<T> 派生自Collection<T> ,可以提供绑定功能。BindingList<T>在.NET 2.0 中就存在了,而ObservableCollection<T> 是WPF
(Windows Presentation Foundation)引入的。
KeyedCollection<TKey, TItem>
KeyedCollection<TKey, TItem>是列表和字典的混合产物,可以通过键或索引来获取项。
与普通字典不同的是,键不能独立存在,应该有效地内嵌在项中。
B.2.5 ReadOnlyCollection<T>和ReadOnlyObservableCollection<T>
最后两个列表更像是包装器,即使基础列表为易变的也只提供只读访问。
B.3 字典
B.3.1 Dictionary<TKey, TValue>
如果没有特殊需求,Dictionary<TKey, TValue>将是字典的默认选择,就像List<T>是列表的默认实现一样。
它使用了散列表,可以实现有效的查找,虽然这意味着字典的效率取决于散列函数的优劣。
可使用默认的散列和相等函数(调用键对象本身的Equals 和GetHashCode),也可以在构造函数中指定IEqualityComparer<TKey> 作为参数。
代码清单B-1 在字典中使用自定义键比较器
var comparer = StringComparer.OrdinalIgnoreCase; var dict = new Dictionary<String, int>(comparer); dict["TEST"] = 10; Console.WriteLine(dict["test"]); //输出10
与List<T>一样,Dictionary<TKey, TValue>将条目保存在数组中,并在必要的时候进行扩充,且扩充的平摊复杂度为O(1) 。如果散列合理,通过键访问的复杂度也为O(1) ;而如果所有键的散列码都相等,由于要依次检查各个键是否相等,因此最终的复杂度为O(n) 。
B.3.2 SortedList<TKey, TValue>和SortedDictionary<TKey, TValue>
乍一看可能会以为名为SortedList<,> 的类为列表,但实则不然。这两个类型都是字典,并且谁也没有实现IList<T> 。如果取名为ListBackedSortedDictionary 和TreeBackedSortedDictionary 可能更加贴切。
比较键时都使用IComparer<TKey>而不是IEqualityComparer<TKey>,并且键是根据比较器排好序的。
SortedList<,> 维护一个排序的条目数组,而SortedDictionary<,> 则使用的是红黑树结构,这导致了插入和移除时间以及内存效率上的显著差异。
B.3.3 ReadOnlyDictionary<TKey, TValue>
ReadOnlyDictionary<TKey, TValue>也只是一个围绕IDictionary<TKey, TValue>的包装器
B.4 集
在.NET 3.5 之前,框架中根本没有公开集(set)集合。如果要在.NET 2.0 中表示集,通常会使用Dictionary<,> ,用集的项作为键,用假数据作为值。.NET3.5 的HashSet <T>在一定程度上改变了这一局面,现在.NET 4 还添加了SortedSet<T>和通用的ISet<T>接口。
B.4.1 HashSet<T>
HashSet<T>是不含值的Dictionary<,> 。它们具有相同的性能特征,并且你也可以指定一个IEqualityComparer<T>来自定义项的比较。同样,HashSet<T>所维护的顺序也不一定就是值添加的顺序。
HashSet<T>添加了一个RemoveWhere 方法,可以移除所有匹配给定谓词的条目。这可以在迭代时对集进行删减,而不必担心在迭代时不能修改集合的禁令。
B.4.2 SortedSet<T>(.NET 4)
就像HashSet<T>之于Dictionary<,> 一样,SortedSet<T>是没有值的SortedDictionary<,>。它维护一个值的红黑树,添加、移除和包含检查(containment check )的复杂度为O(log n)。在对集进行迭代时,产生的是排序的值。
和HashSet<T>一样它也提供了RemoveWhere 方法(尽管接口中没有),并且还提供了额外的属性(Min 和Max )用来返回最小和最大值。
一个比较有趣的方法是GetViewBetween,它返回介于原始集上下限之内(含上下限)的另一个SortedSet<T>。这是一个易变的活动视图——对于它的改变将反映到原始集上,反之亦然。
代码清单B-2 通过视图观察排序集中的改变
var baseSet = new SortedSet<int> { 1, 5, 12, 20, 25 }; var view = baseSet.GetViewBetween(10, 20); view.Add(14); Console.WriteLine(baseSet.Count); //输出6 foreach (int value in view) { Console.WriteLine(value); //输出12、14、20 }
B.5 Queue<T> 和Stack<T>
队列和栈是所有计算机科学课程的重要组成部分。它们有时分别指FIFO(先进先出)和LIFO(后进先出)结构。这两种数据结构的基本理念是相同的:向集合添加项,并在其他时候移除。所不同的是移除的顺序:队列就像排队进商店,排在第一位的将是第一个被接待的;栈就像一摞盘子,最后一个放在顶上的将是最先被取走的。队列和栈的一个常见用途是维护一个待处理的工作项清单。
B.5.1 Queue<T>
Queue<T> 实现为一个环形缓冲区:本质上它维护一个数组,包含两个索引,分别用于记住下一个添加项和取出项的位置(slot )。如果添加索引追上了移除索引,所有内容将被复制到一个更大的数组中。
Queue<T> 提供了Enqueue和Dequeue方法,用于添加和移除项。Peek方法用来查看下一个出队的项,而不会实际移除。Dequeue和Peek 在操作空(empty )队列时都将抛出InvalidOperationException。对队列进行迭代时,产生的值的顺序与出队时一致。
B.5.2 Stack<T>
Stack<T> 的实现比Queue<T> 还简单——你可以把它想成是一个List<T>,只不过它还包含Push方法用于向列表末尾添加新项,Pop 方法用于移除最后的项,以及Peek方法用于查看而不移除最后的项。同样,Pop 和Peek在操作空(empty )栈时将抛出InvalidOperationException。
对栈进行迭代时,产生的值的顺序与出栈时一致——即最近添加的值将率先返回。
B.6 并行集合
作为.NET 4并行扩展的一部分,新的System.Collections.Concurrent命名空间中包含一些新的集合。它们被设计为在含有较少锁的多线程并发操作时是安全的。
B.6.1 IProducerConsumerCollection<T> 和BlockingCollection<T>
在描述队列和栈时,我说过它们通常用于为稍后的处理存储工作项;生产者/ 消费者模式是一种并行执行这些工作项的方式。有时只有一个生产者线程创建工作,多个消费者线程执行工作项。在其他情况下,消费者也可以是生产者.
IProducerConsumerCollection<T>是生产者/ 消费者模式中数据存储的抽象,
BlockingCollection<T> 以易用的方式包装该抽象,并提供了限制一次缓冲多少项的功能。
B.6.2 Concurre ntBag<T> 、ConcurrentQueue<T>和Concurre ntStack<T>
框架自带了三个IProducerConsumerCollection<T>的实现。本质上,它们在获取项的顺序上有所不同;队列和栈与它们非并发等价类的行为一致,而oncurrentBag<T> 没有顺序保证。
它们都以线程安全的方式实现了IEnumerable<T>。
B.6.3 ConcurrentDictionary<TKey, TValue>
ConcurrentDictionary<TKey, TValue>实现了标准的IDictionary<TKey, TValue>接口(但是所有的并发集合没有一个实现了IList<T> ),本质上是一个线程安全的基于散列的字典。
B.7 只读接口
NET 4.5引入了三个新的集合接口,即IReadOnlyCollection<T>、IReadOnlyList<T>和IReadOnlyDictionary<TKey, TValue> 。
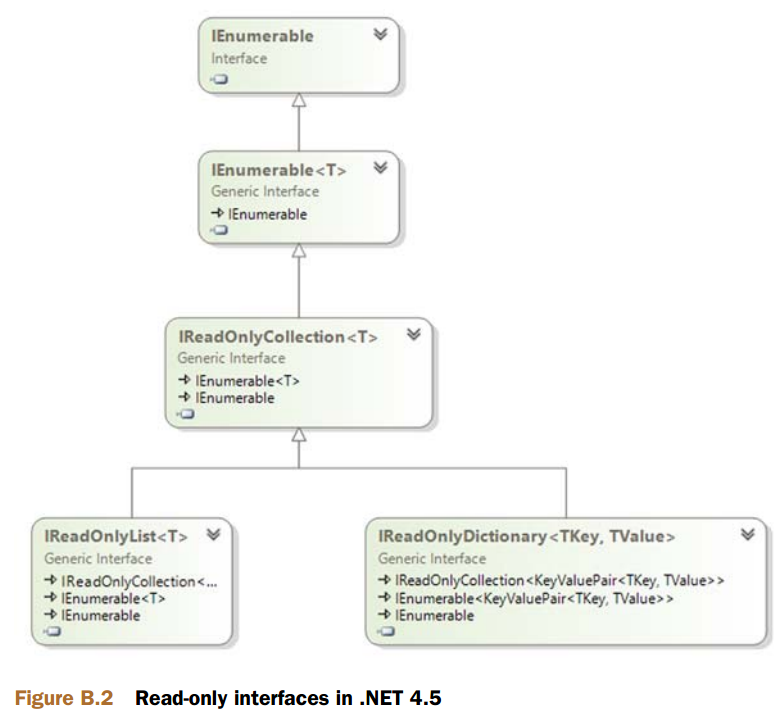
如果觉得ReadOnlyCollection<T> 的名字有点言过其实,那么这些接口则更加诡异。它们不仅允许其他代码对其进行修改,而且如果集合是可变的,甚至可以通过结合对象本身进行修改。例如,List<T>实现了IReadOnlyList<T> ,但显然它并不是一个只读集合。
然这并不是说这些接口没有用处。IReadOnlyCollection<T>和IReadOnlyList<T>对于T都是协变的,这与IEnumerable<T> 类似,但还暴露了更多的操作。可惜IReadOnlyDictionary <TKey, TValue>对于两个类型参数都是不变的,因为它实现了IEnumerable<KeyValuePair <TKey, TValue>> ,而KeyValuePair<TKey, TValue>是一个结构,本身就是不变的。此外,IReadOnlyList<T> 的协变性意味着它不能暴露任何以T 为参数的方法,如Contains 和IndexOf。其最大的好处在于它暴露了一个索引器,通过索引来获取项。
Preview of Immutable Collections Released on NuGet

 浙公网安备 33010602011771号
浙公网安备 33010602011771号