

深入理解C#(第3版)-- 【C#3】第11章 查询表达式和LINQ to Objects(学习笔记)
11.1 LINQ介绍
11.1.1 LINQ中的基础概念
1. 序列(sequence)
序列通过IEnumerable 和IEnumerable<T>接口进行封装,就像数据项的传送带——你每次只能获取它们一个,直到你不再想获取数据,或者序列中没有数据了。
序列和其他集合数据结构(比如列表和数组)之间最大的区别就是,当你从序列读取数据的时候,通常不知道还有多少数据项等待读取,或者不能访问任意的数据项——只能是当前的这个。
序列是LINQ的基础。
var adultNames = from person in people where person.Age >= 18 select person.Name;
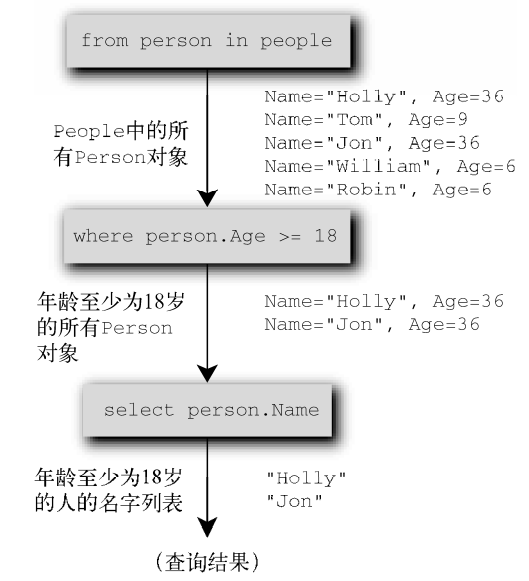
将一个简单的查询表达式分解为相关的序列和转换
2. 延迟执行和流处理
延迟执行 查询表达式被创建的时候,不会处理任何数据,也不会访问原始的人员列表也未被访问。而是在内存中生成了这个查询的表现形式。判断是否为成人的谓词,以及人到人名的转换,都是通过委托实例来表示的。
在最终结果的第一个元素被访问的时候,Select转换才会为它的第一个元素调用Where 转换。而Where 转换会访问列表中的第一个元素,检查这个谓词是否匹配(在这个例子中,是匹配的),并把这个元素返回给Select。最后,依次提取出名称作为结果返回。
有些时候,为了提取查询的第一个结果,你不得不对数据源中所有数据进行计算。Enumerable.Reverse。
一般来说,返回另外一个序列的操作(通常是IEnumerable<T>或IQueryable<T> )使用延迟执行,而返回单一值的运算使用立即执行。
3. 标准查询操作符
11.1.2 定义示例数据模型
11.2 简单的开始:选择元素
11.2.1 以数据源作为开始,以选择作为结束
在C# 3 中每个查询表达式都以同样的方式开始——声明一个数据序列的数据源:
from element in source
element只是一个标识符,它前面可以放置一个类型名称。大多数情况下,你都不需要类型名称,因而我们在第一个例子中也省略了。source 是一个普通的表达式。在第一个子句出现之后,许多不同的事情会发生,不过迟早都会以一个select子句或group 子句来结束。
代码清单11-1 打印出所有用户的袖珍查询
var query = from user in SampleData.AllUsers select user; foreach (var user in query) { Console.WriteLine(user); }
11.2.2 编译器转译是查询表达式基础的转译
代码清单11-2 代码清单 11-1 的查询表达式被转译为一个方法调用
var query = SampleData.AllUsers.Select(user => user); foreach (var user in query) { Console.WriteLine(user); }
记住在LINQ to Objects 中只进行一种调用——任何时候,参数(大部分)都是委托类型,编译器将Lambda表达式作为实参,并尽量查找具有合适签名的方法。
还必须记住,在转译执行之后,不管Lambda表达式中的普通变量(比如方法内部的局部变量)在哪出现,它都会以我们在第5章看到的方式转换成捕获变量。
为什么写成from...where...select ,而不是写成select...from...where ?
如果你回顾一下转译到方法的过程,你就会明白背后的主要原因。查询表达式以书写的顺序来被处理:我们从from子句中的数据源开始,在where子句中进行过滤,然后在select 子句中进行投影。另外一种理解方法就是,思考一下贯穿本章的那个图表。在从上到下的数据流中,图表中的框的出现顺序和在查询表达式中对应的子句的出现顺序是相同的。
11.2.3 范围变量和重要的投影
范围变量不像其他种类的变量。在某些方面,它根本就不是变量。它们只能用于查询表达式中,实际代表了从一个表达式传递给另外一个表达式的上下文信息。
11.2.4 Cast、OfType和显式类型的范围变量
Cast和OfType都可以处理任意非类型化的序列
Cast通过把每个元素都转换为目标类型(遇到不是正确类型的任何元素的时候,就会出错)来处理。
OfType 首先进行一个测试,以跳过任何具有错误类型的元素。
代码清单11-5 使用Cast和OfType来处理弱类型集合
ArrayList list = new ArrayList { "First", "Second", "Third" }; IEnumerable<string> strings = list.Cast<string>(); foreach (string item in strings) { Console.WriteLine(item); } list = new ArrayList { 1, "not an int", 2, 3 }; IEnumerable<int> ints = list.OfType<int>(); foreach (int item in ints) { Console.WriteLine(item); }
在你引入了具有显式类型的范围变量后,编译器就调用Cast来保证在查询表达式的剩余部分中使用的序列具有合适的类型。
没有这个类型转换,我们根本就不能调用Select ,因为该扩展方法只用于IEnumerable<T>而不能用于IEnumerable 。
LINQ重要概念概括
LINQ以数据序列为基础,在任何可能的地方都进行流处理。
创建一个查询并不会立即执行它:大部分操作都会延迟执行。
C# 3的查询表达式包括一个把表达式转换为普通C#代码的预处理阶段,接着使用类型推断、重载、Lambda表达式等这些常规的规则来恰当地对转换后的代码进行编译。
在查询表达式中声明的变量的作用:它们仅仅是范围变量,通过它们你可以在查询表达式内部一致地引用数据。
11.3 对序列进行过滤和排序
11.3.1 使用where 子句进行过滤
过滤表达式当作进入数据流的每个元素的谓词,只有返回true的元素才能出现在结果序列中。
11.3.2 退化的查询表达式
到目前为止,我们所有转换后的查询表达式都包含了对Select的调用。如果我们的select子句什么都不做,只是返回同给定的序列相同的序列,会发生什么?答案是编译器会删除所有对Select 的调用。
11.3.3 使用orderby子句进行排序
11.4 let 子句和透明标识符
11.4.1 用let 来进行中间计算
let 子句只不过引入了一个新的范围变量,它的值是基于其他范围变量。
代码清单11-10 在不使用let 子句的情况下,按用户名称的长度来排序
var query = from user in SampleData.AllUsers orderby user.Name.Length select user.Name; foreach (var name in query) { Console.WriteLine("{0}: {1}", name.Length, name); }
代码清单11-11 使用 let 子句来消除冗余的计算
var query = from user in SampleData.AllUsers let length = user.Name.Length orderby length select new { Name = user.Name, Length = length }; foreach (var entry in query) { Console.WriteLine("{0}: {1}", entry.Length, entry.Name); }
11.4.2 透明标识符
11.5 连接
11.5.1 使用join子句的内连接
通常来说,outer与左连接对应,inner与右连接对应。
static IEnumerable<TResult> Join<TOuter, TInner, TKey, TResult> ( this IEnumerable<TOuter> outer, IEnumerable<TInner> inner, Func<TOuter, TKey> outerKeySelector, Func<TInner, TKey> innerKeySelector, Func<TOuter, TInner, TResult> resultSelector )
右边序列被缓冲处理,不过左边序列仍然进行流处理——所以,如果你打算把一个巨大的序列连接到一个极小的序列上,应尽可能把小序列作为右边序列。
11.5.2 使用join...into子句进行分组连接
分组连接结果中的每个元素由左边序列(使用它的原始范围变量)的某个元素和右边序列的所有匹配元素的序列组成。后者用一个新的范围变量表示,该变量由join子句中into后面的标识符指定。
代码清单11-13 使用分组连接把缺陷和订阅连接到一起
var query = from defect in SampleData.AllDefects join subscription in SampleData.AllSubscriptions on defect.Project equals subscription.Project into groupedSubscriptions select new { Defect = defect, Subscriptions = groupedSubscriptions }; foreach (var entry in query) { Console.WriteLine(entry.Defect.Summary); foreach (var subscription in entry.Subscriptions) { Console.WriteLine (" {0}", subscription.EmailAddress); } }
内连接和分组连接之间的一个重要差异(即分组连接和普通分组之间的差异)是,对于分组连接来说,在左边序列和结果序列之间是一对一的对应关系,即使左边序列中的某些元素在右边序列中没有任何匹配的元素,也无所谓。这是非常重要的,有时会用于模拟SQL 的左外连接。在左边元素不匹配任何右边元素的时候,嵌入序列就是空的。与内连接一样,分组连接要对右边序列进行缓冲,而对左边序列进行流处理。
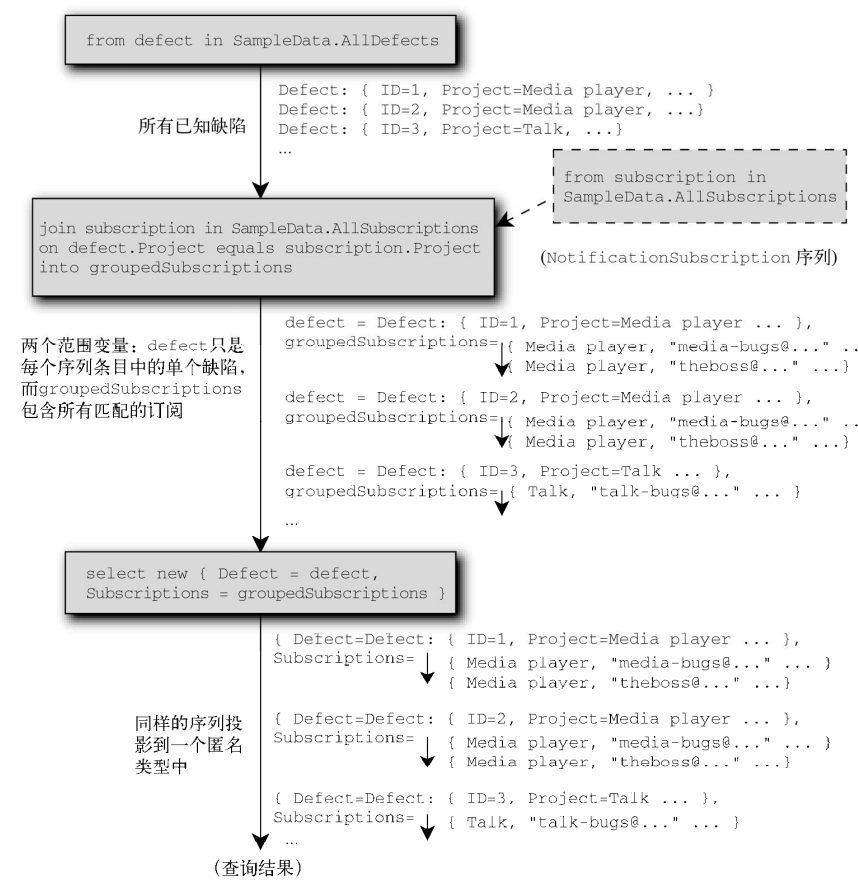
Enumerable. GroupJoin的签名如下:
static IEnumerable<TResult> GroupJoin<TOuter, TInner, TKey, TResult>( this IEnumerable<TOuter> outer, IEnumerable<TInner> inner, Func<TOuter, TKey> outerKeySelector, Func<TInner, TKey> innerKeySelector, Func<TOuter, IEnumerable<TInner>, TResult> resultSelector)
分组连接之后紧接着select子句,所以转译后的查询如下:
dates.GroupJoin(SampleData.AllDefects, date => date, defect => defect.Created.Date, (date, joined) => new { Date = date, Count = joined.Count() })
11.5.3 使用多个from子句进行交叉连接和合并序列
代码清单11-15 用户和项目的交叉连接
var query = from user in SampleData.AllUsers from project in SampleData.AllProjects select new { User = user, Project = project }; foreach (var pair in query) { Console.WriteLine("{0}/{1}", pair.User.Name, pair.Project.Name); }
在任意特定时刻使用的右边序列依赖于左边序列的“当前”值。也就是说,左边序列中的每个元素都用来生成右边的一个序列,然后左边这个元素与右边新生成序列的每个元素都组成一对。
代码清单11-16 右边序列依赖于左边元素的交叉连接
var query = from left in Enumerable.Range(1, 4) from right in Enumerable.Range(11, left) select new { Left = left, Right = right }; foreach (var pair in query) { Console.WriteLine("Left={0}; Right={1}", pair.Left, pair.Right); }
编译器用来生成这个序列所调用的方法是SelectMany。它使用单个的输入序列(以我们的说法就是左边序列),一个从左边序列任意元素上生成另外一个序列的委托,以及一个生成结果元素(其包含了每个序列中的元素)的委托。下面是这个方法的签名,再次写成Enumerable.SelectMany的实例方法:
static IEnumerable<TResult> SelectMany<TSource, TCollection, TResult>( this IEnumerable<TSource> source, Func<TSource, IEnumerable<TCollection>> collectionSelector, Func<TSource, TCollection, TResult> resultSelector )
SelectMany的一个有意思的特性是,执行完全是流式的——一次只需处理每个序列的一个元素,因为它为左边序列的每个不同元素使用最新生成的右边序列。把它与内连接和分组连接进行比较,就能看出:在开始返回任何结果之前,它们都要完全加载右边序列。
var query = from file in Directory.GetFiles(logDirectory, "*.log") from line in ReadLines(file) let entry = new LogEntry(line) where entry.Type == EntryType.Error select entry;
在短短的5行代码中,我们检索、解析并过滤了整个日志文件集,返回了表示错误的日志项的序列。至关重要的是,我们不会一次性向内存加载单个日志文件的全部内容,更不会一次性加载所有文件——所有的数据都采用流式处理。
11.6 分组和延续
11.6.1 使用group...by 子句进行分组
要在查询表达式中对序列进行分组,只需要使用group...by子句,语法如下:
group projection by grouping
该子句与select 子句一样,出现在查询表达式的末尾。
代码清单11-17 用分配者来分组缺陷——无比简单的投影
var query = from defect in SampleData.AllDefects where defect.AssignedTo != null group defect by defect.AssignedTo; foreach (var entry in query) { Console.WriteLine(entry.Key.Name); foreach (var defect in entry) { Console.WriteLine(" ({0}){1}", defect.Severity, defect.Summary); } Console.WriteLine(); }
注意,分组无法对结果进行流处理,它会对每个元素应用键选择和投影,并缓冲被投影元素的分组序列。尽管它不是流式的,但执行仍然是延迟的,直到开始获取其结果。
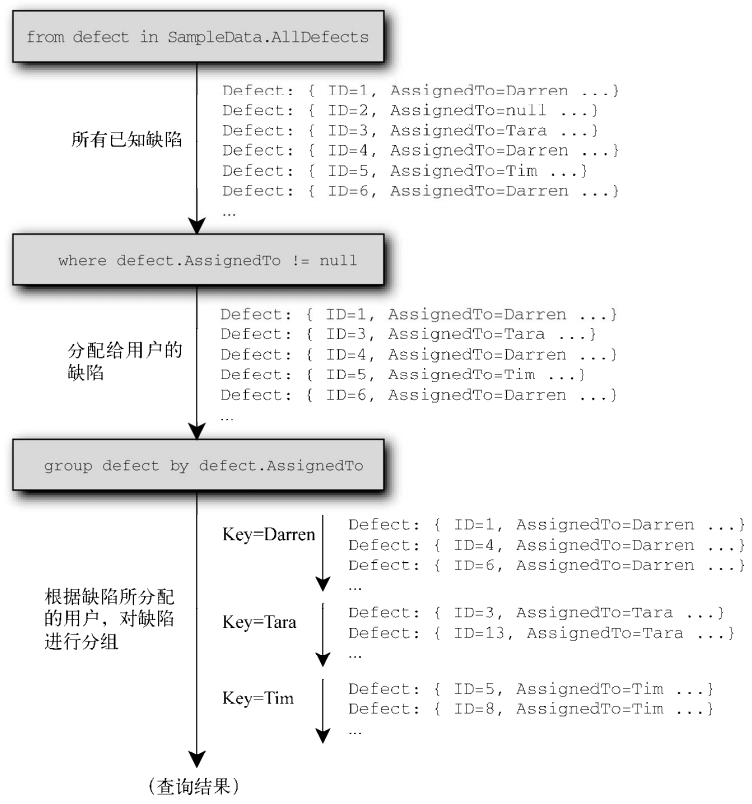
查询表达式会转译为:
SampleData.AllDefects.Where(defect => defect.AssignedTo != null) .GroupBy(defect => defect.AssignedTo)
代码清单11-18 按分配者来分组缺陷——投影只保留概要信息
var query = from defect in SampleData.AllDefects where defect.AssignedTo != null group defect.Summary by defect.AssignedTo; foreach (var entry in query) { Console.WriteLine(entry.Key.Name); foreach (var summary in entry) { Console.WriteLine(" {0}", summary); } Console.WriteLine(); }
查询表达式会转译为:
SampleData.AllDefects.Where(defect => defect.AssignedTo != null) .GroupBy(defect => defect.AssignedTo,defect => defect.Summary)
11.6.2 查询延续
查询延续提供了一种方式,把一个查询表达式的结果用作另外一个查询表达式的初始序列。
使用上下文关键字into,并为新的范围变量提供一个名称,可以应用于group...by和select子句上.
代码清单11-19 使用另外一个投影来延续分组结果
var query = from defect in SampleData.AllDefects where defect.AssignedTo != null group defect by defect.AssignedTo into grouped select new { Assignee = grouped.Key, Count = grouped.Count() }; foreach (var entry in query) { Console.WriteLine("{0}: {1}", entry.Assignee.Name, entry.Count); }
查询表达式被转译为如下形式:
from grouped in (from defect in SampleData.AllDefects where defect.AssignedTo != null group defect by defect.AssignedTo) select new { Assignee = grouped.Key, Count = grouped.Count() }
接着又执行余下的转译,结果就是如下代码:
SampleData.AllDefects .Where(defect => defect.AssignedTo != null) .GroupBy(defect => defect.AssignedTo) .Select(grouped => new { Assignee = grouped.Key, Count = grouped.Count() })
理解延续的另一种方式是,可以把它们看做两个分开的语句。
var tmp = from defect in SampleData.AllDefects where defect.AssignedTo != null group defect by defect.AssignedTo; var query = from grouped in tmp select new { Assignee = grouped.Key, Count = grouped.Count() };
join ... into不是延续 主要的区别在于,在分组连接中,你仍然可以使用所有的早期范围变量(用于连接右边名称的范围变量除外)。而对比本节的查询不难发现,延续会清除之前的范围变量,只有在延续中声明的范围变量才能在供后续使用。
11.7 在查询表达式和点标记之间作出选择
正如我们在本章看到的,查询表达式在编译之前,先被转译成普通的C#。用普通的C#调用LINQ查询操作符来代替查询表达式,很多开发者称其为点标记(dot notation)/流畅的标记(fluent notation )。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号