
一文弄懂分布式场景中各种锁的原理及使用
1. 语言层面的锁
乐观锁:
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) func CompareAndSwapPointer(addr *unsafe.Pointer,old, new unsafe.Pointer) (swapped bool)
func main() {
var n int32
var wg sync.WaitGroup
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
atomic.AddInt32(&n, 1)
wg.Done()
}()
}
wg.Wait()
fmt.Println(atomic.LoadInt32(&n)) // output:1000
}
golang中原子操作CompareAndSwap:

互斥锁:
golang中互斥锁的一个经典实现就是sync包下的sync.mutex,下面以并发访问slice为例:
func main() {
slc := make([]int, 0, 1000)
var wg sync.WaitGroup
var lock sync.Mutex
for i := 0; i < 1000; i++ {
wg.Add(1)
go func(a int) {
defer wg.Done()
// 加锁
lock.Lock()
defer lock.Unlock()
slc = append(slc, a)
}(i)
}
wg.Wait()
fmt.Println(len(slc))
}
缺点:分布式部署环境下锁会失效
2. mysql数据库实现锁
SET AUTOCOMMIT=0; BEGIN WORK; SELECT category_id FROM blog_article WHERE id=3 FOR UPDATE; UPDATE blog_article SET category_id = 3; # 在commit前其它事物无法对此行数据进行修改 COMMIT WORK;
UPDATE blog_article SET category_id = 2 WHERE id = 3;
会发现事物无法立即执行,会等待for update那条事物commit,如果此时长时间未commit则会超时:
[SQL]UPDATE blog_article SET category_id = 2 WHERE id = 3; [Err] 1205 - Lock wait timeout exceeded; try restarting transaction
3. zookeeper、etcd实现分布式锁
zookeeper实现分布式锁:

// 创建zookeeper连接,并创建永久父级节点
func NewZkConn(address, parentPath string) *zk.Conn {
hosts := []string{address}
conn, _, err := zk.Connect(hosts, time.Second*5)
if err != nil {
panic(err)
}
ok, _, _ := conn.Exists(parentPath)
if !ok {
// 创建永久节点
nodeName, err := conn.Create(parentPath, nil, zk.FlagSequence, acls)
if err != nil {
panic(err)
}
fmt.Println("create node name :", nodeName)
}
return conn
}
// nodeCreateSuccess 当前节点是否已成功创建
func nodeCreateSuccess(conn *zk.Conn, path string, id int) bool {
ok, _, ch, err := conn.ExistsW(path)
if err != nil {
return false
}
ex := false
// 节点已存在,则监听状态变化
if ok {
for {
select {
case c := <-ch:
{
if c.Type == zk.EventNodeDeleted {
ex = true
break
}
}
}
if ex {
break
}
}
}
// 节点不存在则尝试创建
_, err = conn.Create(path, nil, flags, acls)
if err != nil {
return false
}
fmt.Printf("[%s] 创造节点的id为 [%d] \n", path, id)
return true
}
func main() {
conn := NewZkConn(zkHosts, parentPath)
// 假设临时节点
path := parentPath + "/001_test_zookeeper_lock"
for i := 0; i < 10; i++ {
go func(conn *zk.Conn, path string, id int) {
// 节点未创建成功则阻塞等待
for {
ok := nodeCreateSuccess(conn, path, id)
// ok=true表示当前节点已成功创建
if ok {
// 释放当前节点锁
err := conn.Delete(path, 0)
if err != nil {
fmt.Println(err)
}
fmt.Printf("删除成功 id为[%d] \n", id)
break
}
}
}(conn, path, i)
}
time.Sleep(time.Second * 10)
}
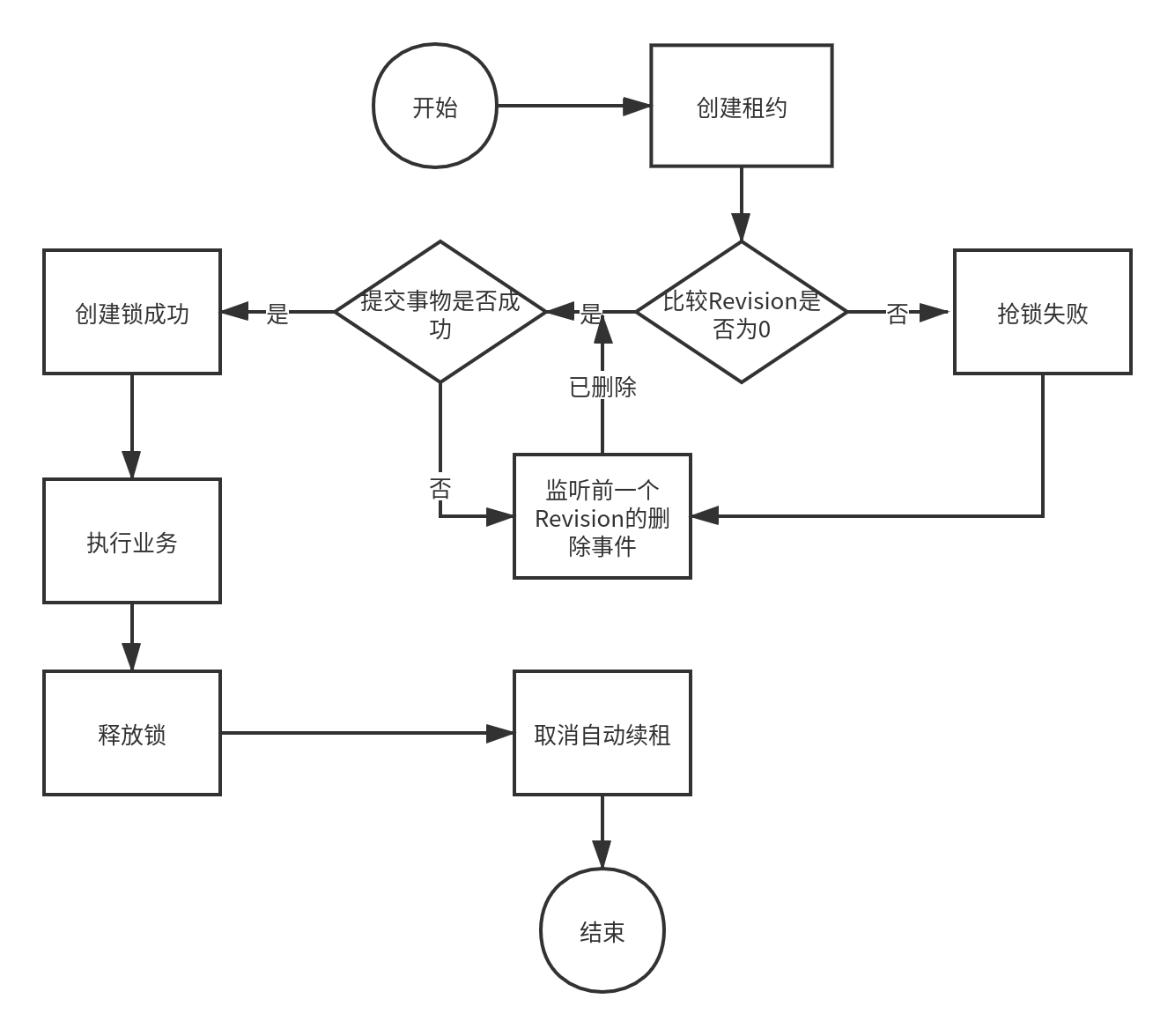 etcd有个很重要的特性,它的key value是多版本的,当有了一个值之后,再put时它的版本是不断地往上加的,这里跟zookeeper类似,判断是否是最小的版本
etcd有个很重要的特性,它的key value是多版本的,当有了一个值之后,再put时它的版本是不断地往上加的,这里跟zookeeper类似,判断是否是最小的版本- 利用租约在etcd集群中创建多个key,这个key有两种形态,存在和不存在,而这两种形态就是互斥量。
- 通过Prefix前缀机制获取前缀目录下所有KV及Revision,通过Revision机制判断当前线程是否能获取到锁。
- 通过Watch监听机制来监听前一个Revision的删除事件。
func main() {
var (
config clientv3.Config
client *clientv3.Client
lease clientv3.Lease
leaseResp *clientv3.LeaseGrantResponse
leaseId clientv3.LeaseID
leaseRespChan <-chan *clientv3.LeaseKeepAliveResponse
err error
)
//客户端配置
config = clientv3.Config{
Endpoints: []string{"etcd2.sndu.cn:2379"},
DialTimeout: 5 * time.Second,
}
//建立连接
if client, err = clientv3.New(config); err != nil {
fmt.Println(err)
return
}
//上锁(创建租约,自动续租)
lease = clientv3.NewLease(client)
//设置1个ctx取消自动续租 执行cancleFunc即执行cancel操作
ctx, cancleFunc := context.WithCancel(context.TODO())
//设置10秒租约(过期时间)
if leaseResp, err = lease.Grant(context.TODO(), 10); err != nil {
fmt.Println(err)
return
}
//拿到租约id
leaseId = leaseResp.ID
//自动续租(不停地往管道中扔租约信息)
if leaseRespChan, err = lease.KeepAlive(ctx, leaseId); err != nil {
fmt.Println(err)
}
//启动多个协程去监听
go listenLeaseChan(leaseRespChan)
//业务处理
kv := clientv3.NewKV(client)
//创建事务
txn := kv.Txn(context.TODO())
txn.If(clientv3.Compare(clientv3.CreateRevision("/lock/20201029-etcd"), "=", 0)).
Then(clientv3.OpPut("/lock/20201029-etcd", "true",
clientv3.WithLease(leaseId))).
Else(clientv3.OpGet("/lock/20201029-etcd")) //否则抢锁失败
//提交事务
if txtResp, err := txn.Commit(); err != nil {
fmt.Println(err)
return
} else {
//判断是否抢锁
if !txtResp.Succeeded {
fmt.Println("锁被占用:",
string(txtResp.Responses[0].GetResponseRange().Kvs[0].Value))
return
}
}
fmt.Println("处理任务")
//释放锁(停止续租,终止租约)
defer cancleFunc() //函数退出取消自动续租
defer lease.Revoke(context.TODO(), leaseId) //终止租约(去掉过期时间)
time.Sleep(10 * time.Second)
}
// listenLeaseChan 监听租约情况
func listenLeaseChan(leaseRespChan <-chan *clientv3.LeaseKeepAliveResponse) {
var leaseKeepResp *clientv3.LeaseKeepAliveResponse
for {
select {
case leaseKeepResp = <-leaseRespChan:
if leaseKeepResp == nil {
fmt.Println("租约失效了")
goto END
} else {
fmt.Println(leaseKeepResp.ID)
}
}
}
END:
}
在etcd官方的实现中其实已经实现了分布式锁,具体实现代码在https://github.com/etcd-io/etcd/blob/master/client/v3/concurrency/mutex.go目录下:
// TryLock 尝试加锁 比较revision是否为最小版本
func (m *Mutex) TryLock(ctx context.Context) error {
resp, err := m.tryAcquire(ctx)
if err != nil {
return err
}
// if no key on prefix / the minimum rev is key, already hold the lock
ownerKey := resp.Responses[1].GetResponseRange().Kvs
if len(ownerKey) == 0 || ownerKey[0].CreateRevision == m.myRev {
m.hdr = resp.Header
return nil
}
client := m.s.Client()
// Cannot lock, so delete the key
if _, err := client.Delete(ctx, m.myKey); err != nil {
return err
}
m.myKey = "\x00"
m.myRev = -1
return ErrLocked
}
// Lock locks the mutex with a cancelable context. If the context is canceled
// while trying to acquire the lock, the mutex tries to clean its stale lock entry.
func (m *Mutex) Lock(ctx context.Context) error {
resp, err := m.tryAcquire(ctx)
if err != nil {
return err
}
// if no key on prefix / the minimum rev is key, already hold the lock
ownerKey := resp.Responses[1].GetResponseRange().Kvs
if len(ownerKey) == 0 || ownerKey[0].CreateRevision == m.myRev {
m.hdr = resp.Header
return nil
}
client := m.s.Client()
// wait for deletion revisions prior to myKey
// TODO: early termination if the session key is deleted before other session keys with smaller revisions.
_, werr := waitDeletes(ctx, client, m.pfx, m.myRev-1)
// release lock key if wait failed
if werr != nil {
m.Unlock(client.Ctx())
return werr
}
// make sure the session is not expired, and the owner key still exists.
gresp, werr := client.Get(ctx, m.myKey)
if werr != nil {
m.Unlock(client.Ctx())
return werr
}
if len(gresp.Kvs) == 0 { // is the session key lost?
return ErrSessionExpired
}
m.hdr = gresp.Header
return nil
}
// tryAcquire 尝试释放锁
func (m *Mutex) tryAcquire(ctx context.Context) (*v3.TxnResponse, error) {
s := m.s
client := m.s.Client()
m.myKey = fmt.Sprintf("%s%x", m.pfx, s.Lease())
cmp := v3.Compare(v3.CreateRevision(m.myKey), "=", 0)
// put self in lock waiters via myKey; oldest waiter holds lock
put := v3.OpPut(m.myKey, "", v3.WithLease(s.Lease()))
// reuse key in case this session already holds the lock
get := v3.OpGet(m.myKey)
// fetch current holder to complete uncontended path with only one RPC
getOwner := v3.OpGet(m.pfx, v3.WithFirstCreate()...)
resp, err := client.Txn(ctx).If(cmp).Then(put, getOwner).Else(get, getOwner).Commit()
if err != nil {
return nil, err
}
m.myRev = resp.Header.Revision
if !resp.Succeeded {
m.myRev = resp.Responses[0].GetResponseRange().Kvs[0].CreateRevision
}
return resp, nil
}
// Unlock 释放锁 删除节点信息
func (m *Mutex) Unlock(ctx context.Context) error {
client := m.s.Client()
if _, err := client.Delete(ctx, m.myKey); err != nil {
return err
}
m.myKey = "\x00"
m.myRev = -1
return nil
}
4. redis实现分布式锁
Redis分布式锁控制并发主要是通过在Redis里面创建一个key,当其它进程准备占用的时候只能等待key释放再占用。Redis里面有一个原子性指令setnx,当key存在时,它返回0,表示当前已有进程占用,当它返回1时可以执行业务逻辑,此时没有进程占用,等逻辑执行完后,可以删除key释放锁,这样可以简单的控制并发:
127.0.0.1:6379> setnx distributedKey aaa (integer) 1 127.0.0.1:6379> setnx distributedKey aaa (integer) 0 127.0.0.1:6379> get distributedKey "aaa" 127.0.0.1:6379>
在业务逻辑执行的过程中如果发生异常,此时key并没有删除,这样就会造成死锁,死锁带来的后果想必大家都很清楚。为了解决这个问题,可以在setnx加锁后设置key的过期时间,当key到期自动删除:
127.0.0.1:6379> expire distributedKey 5 (integer) 1 127.0.0.1:6379>
如果在执行setnx后,执行expire前Redis发生宕机了,这样就不会执行expire,也会造成死锁。由于setnx与expire是两条命令,并且expire依赖setnx的执行结果,为了解决这个问题可以使用set key value [expiration EX seconds|PX milliseconds] [NX|XX] ,这是一条原子性的指令,同时包含setnx和expire:
127.0.0.1:6379> set distributedKey aaa ex 5 nx OK 127.0.0.1:6379> set distributedKey aaa ex 5 nx (nil)
key存在时执行会返回nil,只有key过期或不存在时才会返回ok
// DistributedLock 并发锁
func DistributedLock(key string, expire int, c redis.Conn, value time.Time) (bool, error) {
// 设置原子锁
defer c.Close()
exists, err := c.Do("set", key, value, "nx", "ex", expire)
if err != nil {
return false, errors.New("执行 set nx ex 失败")
}
// 锁已存在,已被占用
if exists != nil {
return false, nil
}
return true, nil
}
// ReleaseLock 释放锁
func ReleaseLock(c redis.Conn, key string) (bool, error) {
defer c.Close()
v, err := redis.Bool(c.Do("DEL", key))
return v, err
}
调用:
func DoSomething(c redis.Conn, key string, expire int, value time.Time) {
// 获取锁
defer c.Close()
canUse, err := DistributedLock(key, expire, c, value)
if err != nil {
panic(err)
}
// 占用锁
if canUse {
fmt.Println("start do something ...")
// 释放锁
_, err := ReleaseLock(c, key)
if err != nil {
panic(err)
}
}
return
}
redis释放锁的问题:
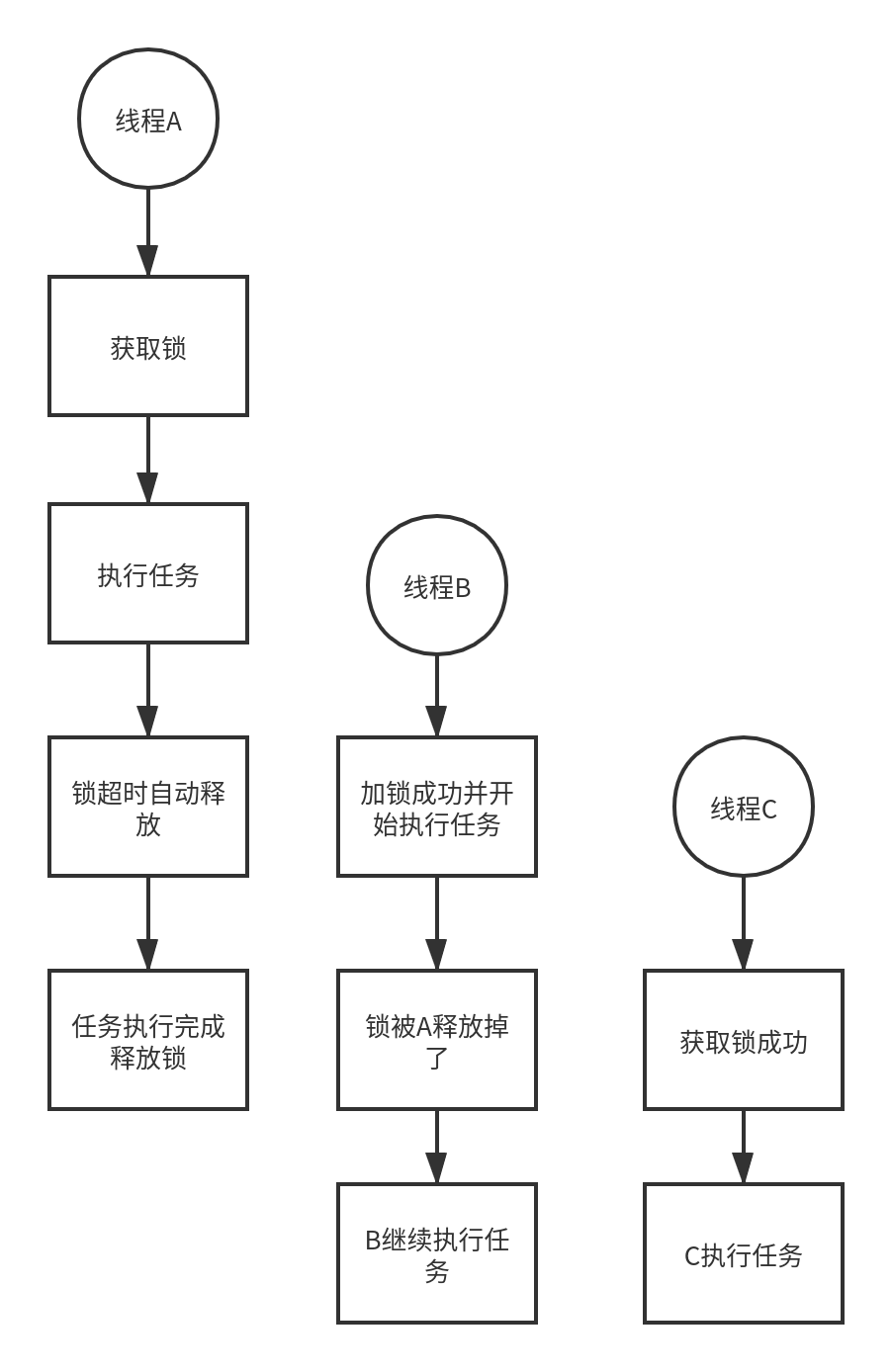
如上图所示,线程A先获得锁,执行超时锁自动释放,此时线程B获取锁开始执行,A执行完后释放了B所持有的锁,这时B继续执行,并且线程C能获取锁,同一时刻线程A和B同时执行锁,违背了分布式锁的安全性。
5. redis+lua实现原子性释放分布式锁
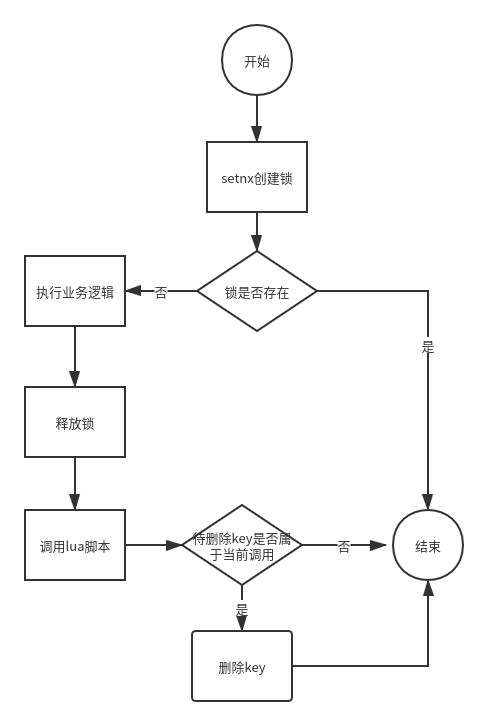
定义lua脚本释放锁:
const (
// ScriptDeleteLock 释放redis并发锁 lua脚本 判断value为本次锁的value才释放
ScriptDeleteLock = `
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
`
)
// ReleaseLockWithLua 释放锁 使用lua脚本执行
func ReleaseLockWithLua(c redis.Conn, key string, value time.Time) (int, error) {
// keyCount表示lua脚本中key的个数
defer c.Close()
lua := redis.NewScript(1, ScriptDeleteLock)
// lua脚本中的参数为key和value
res, err := redis.Int(lua.Do(c, key, value))
if err != nil {
return 0, err
}
return res, nil
}
调用:
func DoSomethingWithLua(c redis.Conn, key string, expire int, value time.Time) {
// 获取锁
defer c.Close()
canUse, err := DistributedLock(key, expire, c, value)
if err != nil {
panic(err)
}
// 占用锁
if canUse {
fmt.Println("start do something ...")
// 释放锁 lua脚本执行原子性删除
_, err := ReleaseLockWithLua(c, key, value)
if err != nil {
panic(err)
}
}
return
}
redis sentinel集群下锁的同步问题:
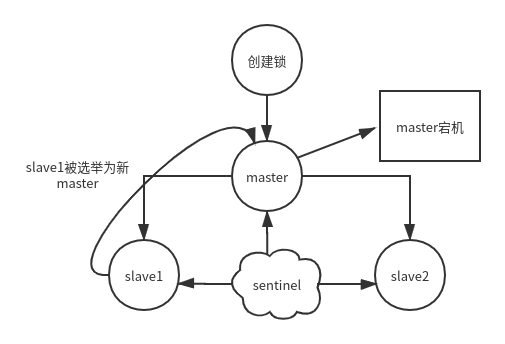
如上图所示,线程在master成功创建锁,此时锁还未同步到slave,master发生宕机,当slave1成我新master后锁丢失。
6. redlock算法及相关问题
redlock算法流程
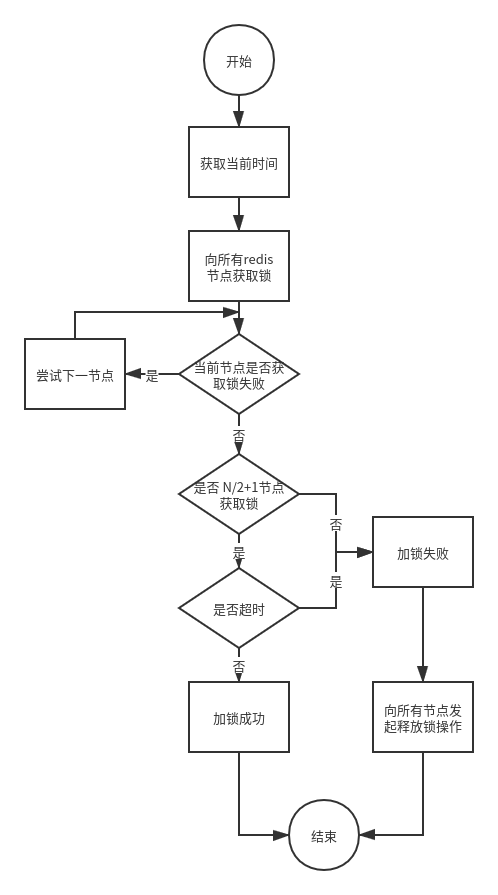
如上图所示,redlock算法的实现流程,每次加锁的时候尝试向redis集群中每个节点申请加锁,当前节点加锁失败则跳过继续向下一个节点执行加锁请求,只有大于一半的节点加锁成功才认为分布式锁成功;释放锁时同样需配合lua脚本向所有的redis节点发起释放锁请求。
redlock算法跳跃时钟问题

上述redlock算法已经解决了redis集群中master宕机导致锁失效的问题,但是它是否就是完美的呢?如上图所示,client1向redis集群申请加锁,此时节点A、B、C执行成功,client1成功获取锁,节点D和E由于网络原因加锁失败;这时节点C所在的服务器由于时钟向前跳跃导致锁快速过期了,client2执行加锁请求,显然此时是能加锁成功的;那么相当于在同一时刻两个进程能持有锁,这显然违背了分布式锁的互斥性的特点。
redlock算法GC停顿问题
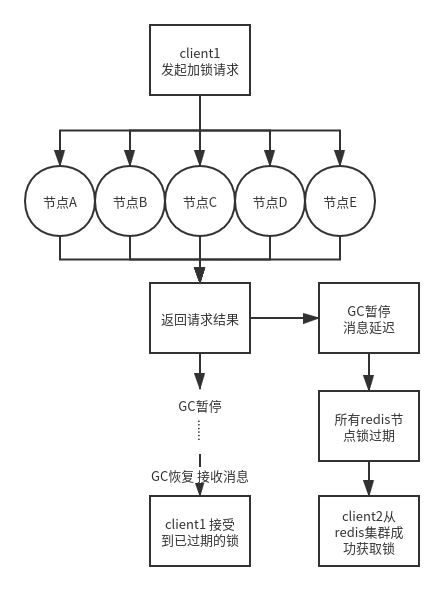
同样,还有一种特殊的情况就是GC停顿导致消息延迟的问题,当client1向redis集群发起加锁请求并返回加锁成功的结果,此时消息延迟到达client1导致在这段时间redis集群中的锁过期了,client2显然能够正常获取锁,当GC恢复时client1收到结果会认为自己持有锁,这同样违背了分布式锁互斥性的特点。
7. 总结
以上几种锁的实现方式并非说明哪种是最优解,具体场景需选择具体的锁。如果是单机环境建议直接使用语言层面的锁来实现,这样不需要引入额外的第三方依赖;如果是对数据库的并发更新操作,并且并发量不是太大,可以使用mysql的select for update或者select for update nowait实现,但是注意尽量不要使用表锁并且不要造成死锁的问题;如果是对锁的可靠性要求极高那么建议使用zookeeper、etcd实现;最后如果在开发环境中没有zookeeper、etcd等第三方组件,并且对锁的性能要求比较高,可以使用单机的redis配合lua脚本释放锁,这里我个人并不推荐使用redlock。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号