数据探索性分析案例实现diamonds.csv
《数据探索性分析案例实现(EDA) 》
一、数据描述
1.1数据集描述
diamonds数据框包含53940行,有carat、cut、color、clarity、depth、table、price、x、y、z共10列,对应每个钻石的一些参数值。
carat:克拉,钻石的重量
cut:代表了钻石的切工,由低到高依次为Fair, Good, Very Good, Premium, Ideal
color:代表了钻石的颜色从最低的J到最高的D
clarity:钻石的纯净度,代表了钻石的透明程度从低到高依次为I1, SI1, SI2, VS1, VS2, VVS1, VVS2, IF
depth:深度比例
table:代表了钻石的桌面比例
price:代表了钻石的价格
x,y,z:分别代表了钻石的长/宽/高
1.2数据展示
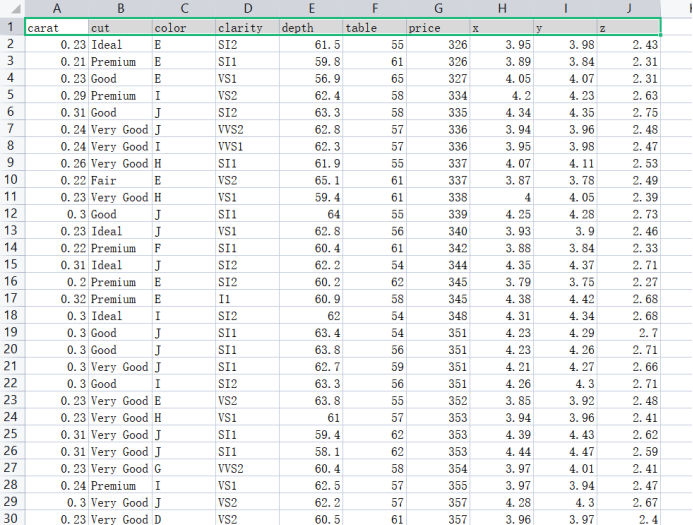
1.3导入数据

1.4查看数据集信息
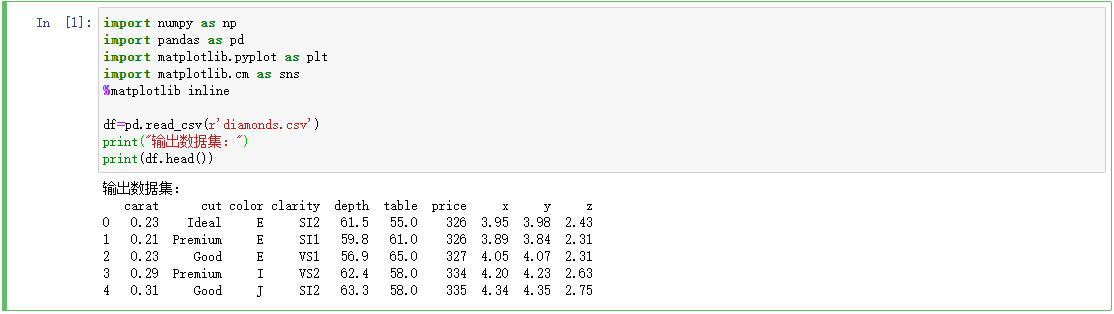
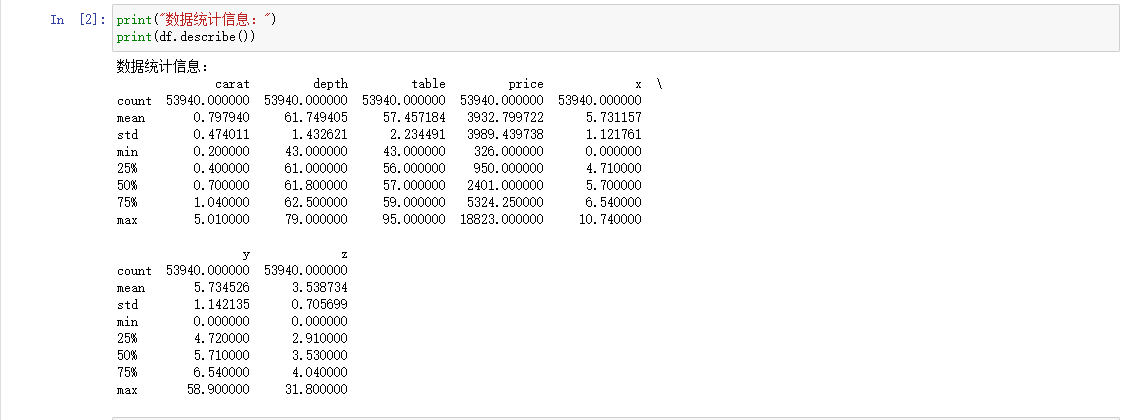
从统计信息可以看出数字型的总数、count,数据个数(非空数据),mean,均值,std,标准差,min,最小值,25%,第1四分位数,即第25百分位数,50%,第2四分位数,即第50百分位数,75%,第3四分位数,即第75百分位数,max,最大值等信息。
二、问题提出
1、每个数据有什么特征?
3、价格和什么成正比?
2、克拉、切割、颜色、钻石的纯净度对价格的影响?
三、数据清洗和预处理
3.1查找缺失值
pd.isnull(df).sum()
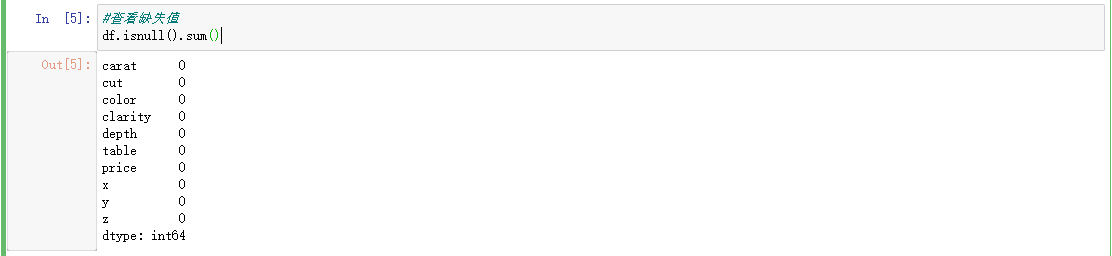
可以看出,该数据集没有缺失值。
3.2查看数据集类型
df.info()
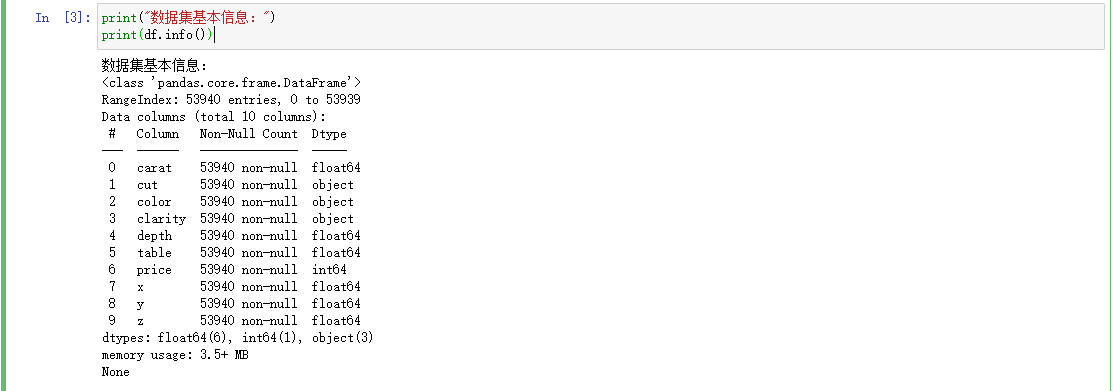
查看数据集类型,可以看到一个10x3的列表,该数据集有10列,53940条数据。Not-Null记录该列是否有空值,Dtype描述每列数据的类型。
四、各变量相关性数据分析与可视化
4.1通过库,用代码实现可视化
查看数据描述
df.describe()

对每个特征绘制柱状图

扇形图

如上绘制clarity列扇形图。同理绘制color、cut列扇形图。图片如下:

可以看到clarity主要分布在VS2、SI1、SI2、VS1,I1、IF占比很少。
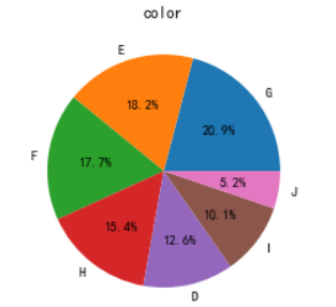
可以看到,color为G占比最大,J最小。

可以看出,cut切割理想(Ideal)的占比最大,失败的很少。
单个特征的分布情况(直方图)
sns.distplot(df['price'],kde=False)

由直方图可以看出加出价格的分布情况。
4.2使用dtale可视化数据
查看数据
结果如下:

通过左上角的三角形打开功能菜单(通过language可将语言切换为中文)
描述
以price为例详细展开说明:
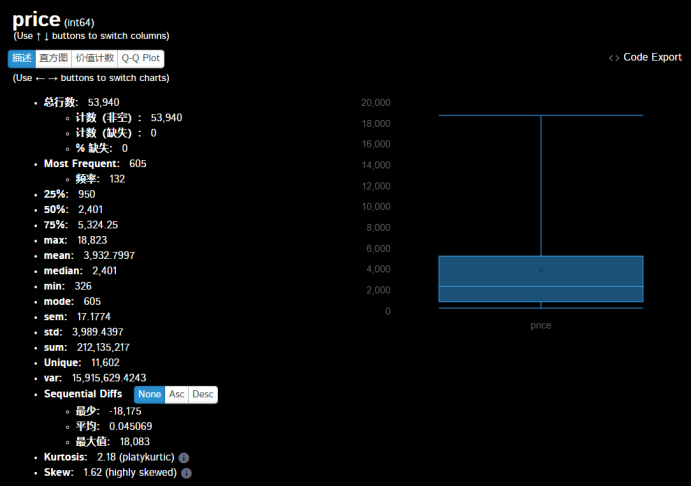
查看描述,可知价格分布及频率,还有最大值、中值、最小值、总和等。通过箱式图可知道:
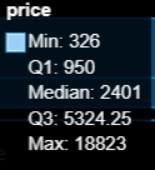
最小值:326
1/4分位点:950
中位数:2401
3/4分位点:5324.25
最大值:18823
直方图:

可以看到价格为1250左右的最多,2000-7000其次,更贵就更少了。
细分
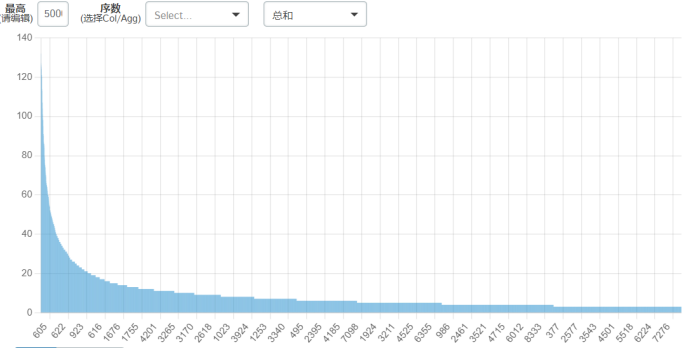
500个数据
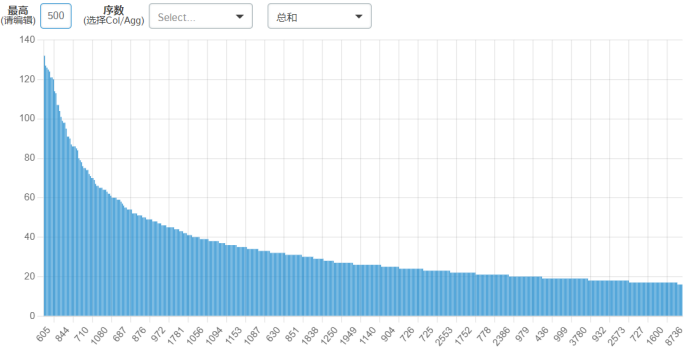
5000个数据
50000条数据
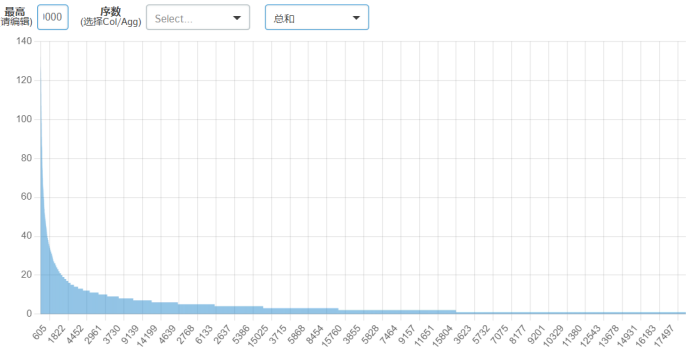
从此细分计数图可以看出,价格为600左右的最多。
price-carat
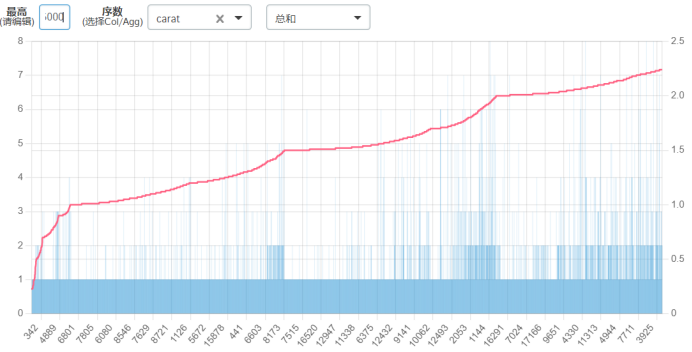
可以看出price-carat是正比例相关,价格越高,carat越高
以下给出了其他列和price计数图


图表功能
以price为x轴,其他列为y轴,可以得到如下结果:
carat by price

随着钻石重量的增加钻石的价格也呈上升的趋势
depth by price
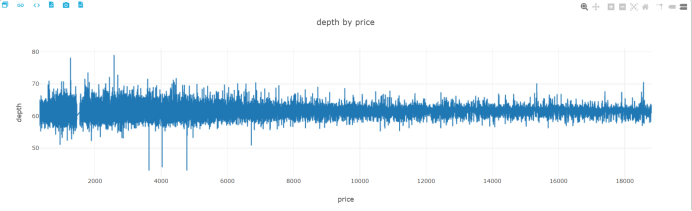
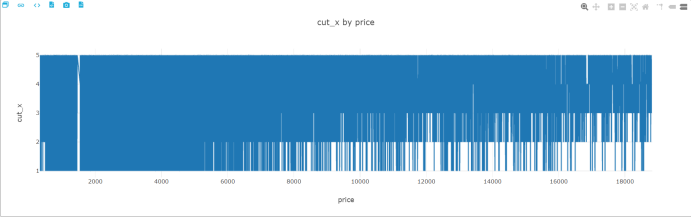
cut by price
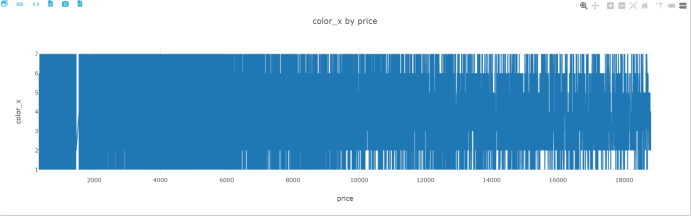
color by price
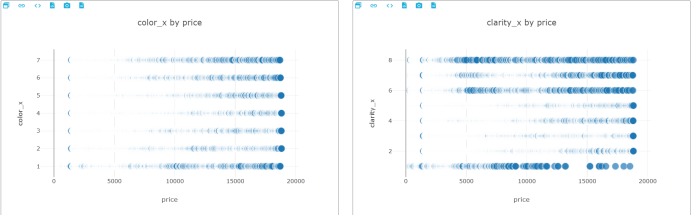
clarity by price

可以得出,克拉和价格成正相关,质量越重,价格越高,而价格高的钻石的切工、纯净度不会太差,而颜色没有太大相关。
ScatterPlot-散点图

Wordcloud-词云图


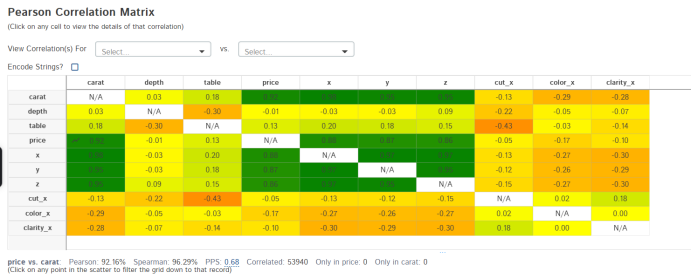
相关性
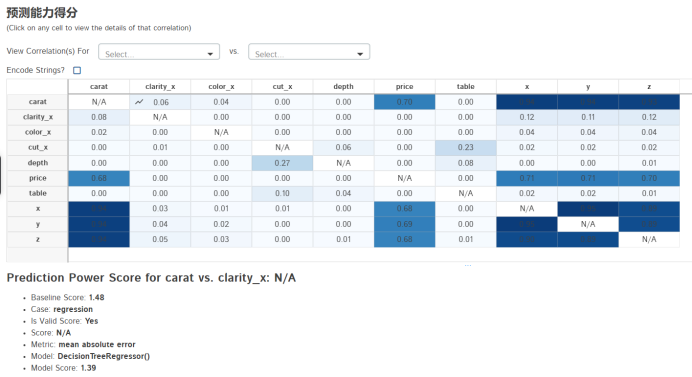
可以知道影响价格的最重要因素是carat。
五、主要结论
钻石的重量越高价格越高,钻石的重量越高其价格受其他因素的影响越大。
颜色、切工、透明度越好的钻石价格均值越低。
钻石的价格随克拉数的升高而升高,透明度越好(IF)的钻石的单价越高。
钻石的价格随克拉数的升高而升高,切工越好(Ideal)的钻石的单价越高。
钻石的价格随克拉数的升高而升高,颜色越好(D)的钻石的单价越高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号