蓝桥云MySQL基础课程跟练
数据类型
CHAR 和 VARCHAR 的区别: CHAR 的长度是固定的,而 VARCHAR 的长度是可以变化的,比如,存储字符串 “abc",对于 CHAR(10),表示存储的字符将占 10 个字节(包括 7 个空字符),而同样的 VARCHAR(12) 则只占用 4 个字节的长度,增加一个额外字节来存储字符串本身的长度,12 只是最大值,当你存储的字符小于 12 时,按实际长度存储。
ENUM 和 SET 的区别: ENUM 类型的数据的值,必须是定义时枚举的值的其中之一,即单选,而 SET 类型的值则可以多选。
实操:搭建一个简易的成绩管理系统的数据库
介绍
现需要构建一个简易的成绩管理系统的数据库,来记录几门课程的学生成绩。数据库中有三张表分别用于记录学生信息、课程信息和成绩信息。
数据表结构如下:
学生表(student):学生 id 、学生姓名和性别
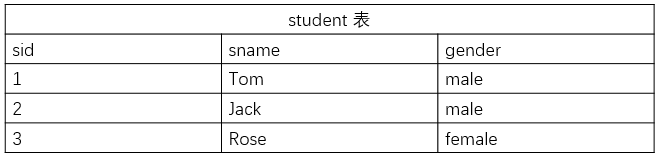
课程表:课程 id 和课程名
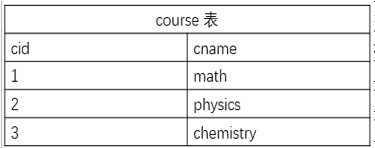
成绩表:成绩 id 、学生 id 、课程 id 和分数
服务器中的 MySQL 还没有启动,请注意 MySQL 的 root 账户默认密码为空。
目标
1.MySQL 服务处于运行状态
2.新建数据库的名称为 gradesystem
3.gradesystem 包含三个表:student、course、mark;
-
student 表包含 3 列:sid(主键)、sname、gender;
-
course 表包含 2 列:cid(主键)、cname;
-
mark 表包含 4 列:mid(主键)、sid、cid、score ,注意与其他两个表主键之间的关系。
4.将上述表中的数据分别插入到各个表中
提示
- 建立表时注意 id 自增(auto_increment)和键约束(如 not null)
- 每个表插入语句可通过一条语句完成
挑战参考代码
sudo service mysql start
mysql -u root
CREATE DATABASE gradesystem;
use gradesystem
CREATE TABLE student(
sid int NOT NULL AUTO_INCREMENT,
%% AUTO_INCREMENT可以设置逐渐递增 %%
sname varchar(20) NOT NULL,
gender varchar(10) NOT NULL,
PRIMARY KEY(sid)
%% 在最后补充某某字段是主键也是可以的 %%
);
CREATE TABLE course(
cid int NOT NULL AUTO_INCREMENT,
cname varchar(20) NOT NULL,
PRIMARY KEY(cid)
);
CREATE TABLE mark(
mid int NOT NULL AUTO_INCREMENT,
sid int NOT NULL,
cid int NOT NULL,
score int NOT NULL,
PRIMARY KEY(mid),
FOREIGN KEY(sid) REFERENCES student(sid),
%% 表示sid字段参考student表的sid字段
即只有student表中有相应的sid值
此表才可以应用该sid
删除同理 %%
FOREIGN KEY(cid) REFERENCES course(cid)
);
INSERT INTO student VALUES(1,'Tom','male'),(2,'Jack','male'),(3,'Rose','female');
INSERT INTO course VALUES(1,'math'),(2,'physics'),(3,'chemistry');
INSERT INTO mark VALUES(1,1,1,80),(2,2,1,85),(3,3,1,90),(4,1,2,60),(5,2,2,90),(6,3,2,75),(7,1,3,95),(8,2,3,75),(9,3,3,85);
IN和NOT IN
关键词 IN 和 NOT IN 的作用和它们的名字一样明显,用于筛选“在”或“不在”某个范围内的结果,比如说我们要查询在 dpt3 或 dpt4 的人:
SELECT name,age,phone,in_dpt FROM employee WHERE in_dpt IN ('dpt3','dpt4');

而 NOT IN 的效果则是,如下面这条命令,查询出了不在 dpt1 也不在 dpt3 的人:
SELECT name,age,phone,in_dpt FROM employee WHERE in_dpt NOT IN ('dpt1','dpt3');
通配符
关键字 LIKE 可用于实现模糊查询,常见于搜索功能中。
和 LIKE 联用的通常还有通配符,代表未知字符。SQL 中的通配符是 _ 和 % 。其中 _ 代表一个未指定字符,% 代表不定个未指定字符
比如,要只记得电话号码前四位数为 1101,而后两位忘记了,则可以用两个 _ 通配符代替:
SELECT name,age,phone FROM employee WHERE phone LIKE '1101__';
这样就查找出了 1101 开头的 6 位数电话号码:

另一种情况,比如只记名字的首字母,又不知道名字长度,则用 % 通配符代替不定个字符:
SELECT name,age,phone FROM employee WHERE name LIKE 'J%';
这样就查找出了首字母为 J 的人
对结果排序
为了使查询结果看起来更顺眼,我们可能需要对结果按某一列来排序,这就要用到 ORDER BY 排序关键词。默认情况下,ORDER BY 的结果是升序排列,而使用关键词 ASC 和 DESC 可指定升序或降序排序。 比如,我们按 salary 降序排列,SQL 语句为:
SELECT name,age,salary,phone FROM employee ORDER BY salary DESC;
如果后面不加 DESC 或 ASC 将默认按照升序排列。应用场景:博客系统中按时间先后顺序显示博文。
SQL的内置函数与计算
SQL 允许对表中的数据进行计算。对此,SQL 有 5 个内置函数,这些函数都对 SELECT 的结果做操作:
| 函数名: | COUNT | SUM | AVG | MAX | MIN |
|---|---|---|---|---|---|
| 作用: | 计数 | 求和 | 求平均值 | 最大值 | 最小值 |
其中 COUNT 函数可用于任何数据类型(因为它只是计数),而 SUM 、AVG 函数都只能对数字类数据类型做计算,MAX 和 MIN 可用于数值、字符串或是日期时间数据类型。
具体举例,比如计算出 salary 的最大、最小值,用这样的一条语句:
SELECT MAX(salary) AS max_salary,MIN(salary) FROM employee;
有一个细节你或许注意到了,使用 AS 关键词可以给值重命名,比如最大值被命名为了 max_salary
子查询
上面讨论的 SELECT 语句都仅涉及一个表中的数据,然而有时必须处理多个表才能获得所需的信息。例如:想要知道名为 "Tom" 的员工所在部门做了几个工程。员工信息储存在 employee 表中,但工程信息储存在 project 表中。
对于这样的情况,我们可以用子查询:
SELECT of_dpt,COUNT(proj_name) AS count_project FROM project GROUP BY of_dpt
HAVING of_dpt IN
(SELECT in_dpt FROM employee WHERE name='Tom');
上面代码包含两个 SELECT 语句,第二个 SELECT 语句将返回一个集合的数据形式,然后被第一个 SELECT 语句用 in 进行判断。
HAVING 关键字可以的作用和 WHERE 是一样的,都是说明接下来要进行条件筛选操作。
区别在于 HAVING 用于对分组后的数据进行筛选
子查询还可以扩展到 3 层、4 层或更多层。
连接查询
在处理多个表时,子查询只有在结果来自一个表时才有用。但如果需要显示两个表或多个表中的数据,这时就必须使用连接 (join) 操作。 连接的基本思想是把两个或多个表当作一个新的表来操作,如下:
SELECT id,name,people_num
FROM employee,department
WHERE employee.in_dpt = department.dpt_name
ORDER BY id;
这条语句查询出的是,各员工所在部门的人数,其中员工的 id 和 name 来自 employee 表,people_num 来自 department 表
另一个连接语句格式是使用 JOIN ON 语法,刚才的语句等同于:
SELECT id,name,people_num
FROM employee JOIN department
ON employee.in_dpt = department.dpt_name
ORDER BY id;
结果也与刚才的语句相同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号