Python 系列--爬虫利器Playwright
和数据打交道,工作中难免会遇到一些需要爬取数据的场景,由于一些网站的反爬措施,模拟浏览器登录,从开发者选项的源代码中获取想要的数据就成了一种解决方案。此时,Playwright、selenium 这些原本的自动化测试工具就派上了大用场。亲自体验后,觉得前者用起来特别方便,各种网站基本都能应付。因此准备写一个playwright 爬虫专篇,今天为入门篇,话不多说。
一、Playwright 是什么?
它是微软在 2020 年初开源的新一代自动化测试工具,其功能和 selenium 类似,都可以驱动浏览器进行各种自动化操作。
二、特点是什么
- 支持当前所有的主流浏览器,包括 chrome、edge、firefox、safari;
- 支持浏览器有头和无头模式;
- 安装和配置过程简单,会自动安装对应的浏览器和驱动,不需要额外配置 WebDriver 等
三、如何安装
打开命令行,输入
pip install playwright
playwright install四、基本概念
browser
浏览器:支持多种浏览器:Chromium(chrome、edge)、Firefox、WebKit(Safari),一般每一种浏览器只需要创建一个 browser 实例。示例:
browser = playwright.chromium.launch(headless=False) # headless=False 是有头模式,也就是代码运行时候,需要浏览器页面
browser = playwright.firefox.launch()context
上下文:一个浏览器实例下可以有多个context,将浏览器分割成不同的上下文,以实现会话的分离,如需要不同用户登录同一个网页,不需要创建多个浏览器实例,只需要创建多个context即可
context = browser.new_context()page
页面:一个context下可以有多个page,一个page就代表一个浏览器的标签页或弹出窗口,用于进行页面操作。这个也是我们主要操作的对象。
page = context.new_page()五、快速入门
使用时,我已知的,目前不兼容 jupyter notebook,所以,我使用的是 vscode
下面是一段 html,用这段代码快速入门演示一下
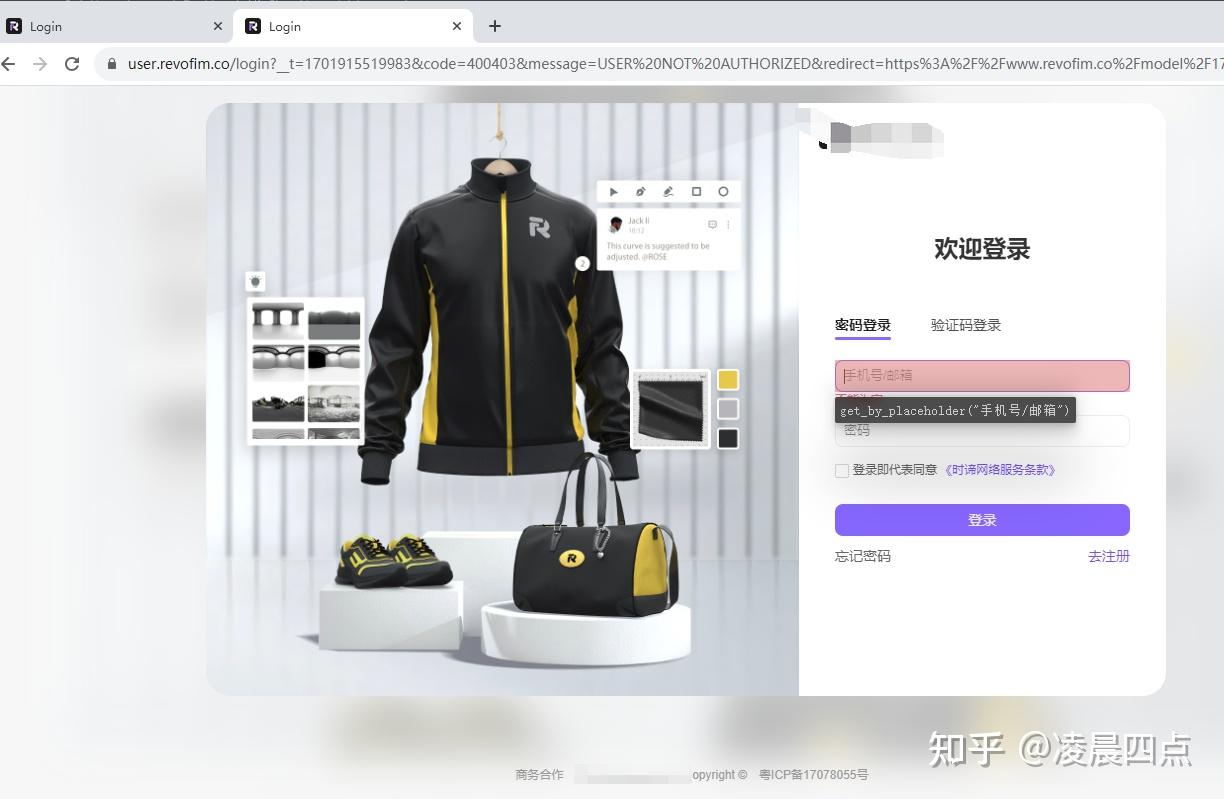
<h1 data-v-4a3b3bb4="" class="form-title">欢迎登录</h1>
<div data-v-4a3b3bb4="" class="login-form-tab el-tabs el-tabs--top">
<div class="el-tabs__header is-top">
<div class="el-tabs__nav-wrap is-top">
<div class="el-tabs__nav-scroll">
<div role="tablist" class="el-tabs__nav is-top" style="transform: translateX(0px);">
<div class="el-tabs__active-bar is-top" style="width: 56px; transform: translateX(0px);"></div>
<div id="tab-by-password" aria-controls="pane-by-password" role="tab" aria-selected="true" tabindex="0" class="el-tabs__item is-top is-active">密码登录</div>
<div id="tab-by-code" aria-controls="pane-by-code" role="tab" tabindex="-1" class="el-tabs__item is-top">验证码登录</div>
</div>
</div>
</div>
</div>
<div class="el-tabs__content">
<div data-v-4a3b3bb4="" role="tabpanel" id="pane-by-password" aria-labelledby="tab-by-password" class="el-tab-pane"></div>
<div data-v-4a3b3bb4="" role="tabpanel" aria-hidden="true" id="pane-by-code" aria-labelledby="tab-by-code" class="el-tab-pane" style="display: none;"></div>页面跳转
常用于模拟操作的第一步,去到目标网站
page.goto(url) # 你想去到的页面地址页面点击
进入某个网站后,模拟用户的点击行为,点击某个元素
# 页面点击
page.click(selector) # selector 为页面元素选择器相当于告诉程序,你点击的地方在哪里,playwright提供了多种选择的方法,有CSS选择法,文本选择,xpath。作为爬虫演示,主要使用文本选择和xpath
# 文本选择
page.click("text=保存")
# xpath
page.click("xpath=//div[@class='nav-items']/ul/li[4]/a")比如要点击上面页面中的**【登录】**
# xpath 方式
page.click('xpath=//button[@class="el-button btn-submit el-button--primary el-button--small"]')输入字符
page.fill(selector,value) # value 为填入的值,前者为输入框元素
page.fill("xpath=//input[@id='inp-query']",'你好')比如要在上面输入手机号
<input type="text" autocomplete="email" autofocus="autofocus" placeholder="手机号/邮箱" class="el-input__inner">
page.fill("xpath=//input[@placeholder='手机号/邮箱']",'183xxxx2345')获取当前页面的url
page.url获取当前页面title
page.title获取页面全文
# 获取页面全文
page.content()获取某个数据
page.text_content(selector)
page.text_content("xpath=//div[@class='nav-logo']/a")比如要获取上面截图中的【欢迎登录】四个字
# <h1 data-v-4a3b3bb4="" class="form-title">欢迎登录</h1>
page.text_content('xpath=//h1[@class="form-title"]')获取属性值
page.get_attribute(selector,attr)
page.get_attribute("xpath=//div[@class='nav-logo']/a",'href')比如要获取截图中左边的大图
# <img data-v-3aa1f3cd="" src="//static.revobit.cn/user-center%402.0.0%2Bbe1fa77/img/login-holder.d395120d.jpg" alt="网站展示图片" class="login-holder">
page.get_attribute("xpath=//img[@alt='网站展示图片']",'src')
# 输出大图的url获取元素节点
# 获取单个
page.query_selector("//a")
# 获取多个节点
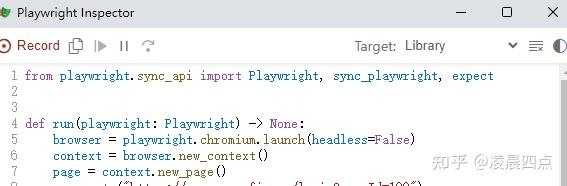
page.query_selector_all("//a")六、代码录制功能
也叫做自动生成代码功能,使用场景是,你不会或者懒的写代码时,可以在命令行输入下面代码,会自动弹出一个浏览器和一个代码编辑器,我们输入需要模拟的网站地址,人为操作就好,每一步的代码会自动生成到代码编辑器上,可复制使用
playwright codegen -o script.py
此篇就简单介绍一下 Playwright 的入门级功能,如果觉得有用,麻烦点个赞或者喜欢,也是我继续更新的动力,后续会结合真实的爬虫场景来演示。
posted on 2025-04-21 16:44 ExplorerMan 阅读(1720) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号