探索检索增强生成(RAG)技术的无限可能:Vector+KG RAG、Self-RAG、多向量检索器多模态RAG集成
探索检索增强生成(RAG)技术的无限可能:Vector+KG RAG、Self-RAG、多向量检索器多模态RAG集成
由于 RAG 的整体思路是首先将文本切分成不同的组块,然后存储到向量数据库中。在实际使用时,将计算用户的问题和文本块的相似度,并召回 top k 的组块,然后将 top k 的组块和问题拼接生成提示词输入到大模型中,最终得到回答。
优化点:
- 优化文本切分的方式,组块大小和重叠的大小都是可以调节的参数
- 多组块召回,可以在检索的时候使用较小长度的组块,然后输入到大模型时使用较大长度的组块获得更充分的上下文信息
- 优化向量模型,使用高性能的向量模型,比如目前我们在使用的 bge,有能力的去微调向量模型能达到更好的效果
- 增加重排序,向量模型召回一个较大数量的组块,然后使用重排序的模型去筛选一个较小数量的组块去生成提示词
- 提示词优化,增加相关的提示词约束可以让大模型输出的结果更稳定,质量更高
RAG 优化分为两个方向:RAG 基础功能优化、RAG 架构优化。我们分别展开讨论。
1.RAG 基础功能优化
对 RAG 的基础功能优化,我们要从 RAG 的流程入手 [1],可以在每个阶段做相应的场景优化。
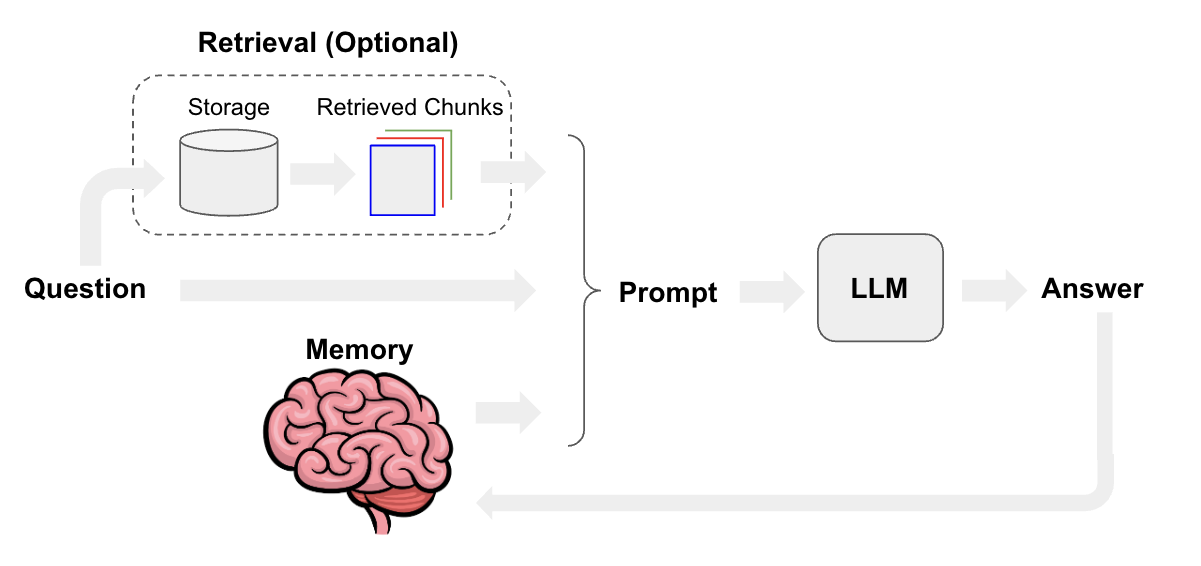
从 RAG 的工作流程看,能优化的模块有:文档块切分、文本嵌入模型、提示工程优化、大模型迭代。下面针对每个模块分别做说明
- 文档块切分:设置适当的块间重叠、多粒度文档块切分、基于语义的文档切分、文档块摘要。
- 文本嵌入模型:基于新语料微调嵌入模型、动态表征。
- 提示工程优化:优化模板增加提示词约束、提示词改写。
- 大模型迭代:基于正反馈微调模型、量化感知训练、提供大 context window 的推理模型。
此外,还可对 query 召回的文档块集合进行处理,比如:元数据过滤 [7]、重排序减少文档块数量 [2]。
2.RAG 架构优化
2.1 Vector+KG RAG
经典的 RAG 架构中,context 增强只用到了向量数据库。这种方法有一些缺点,比如无法获取长程关联知识 [3]、信息密度低。
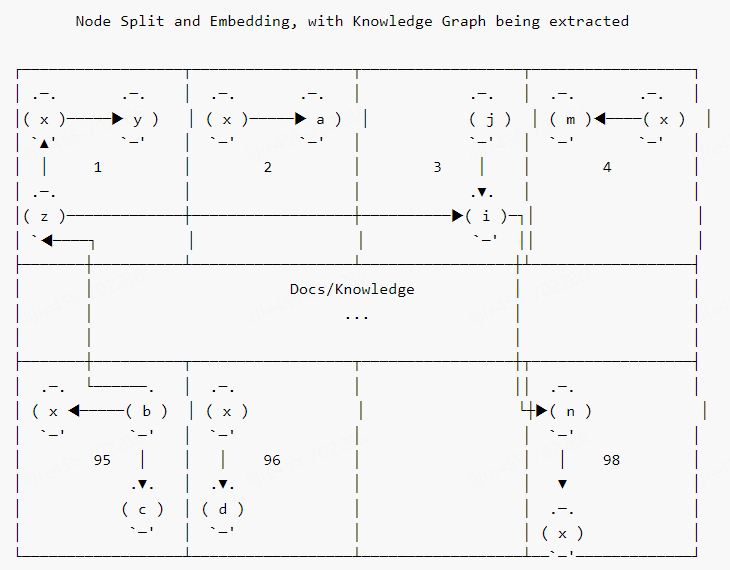
那此题是否可解?答案是肯定的。一个比较好的方案是增加一路与向量库平行的 KG([知识图谱]上下文增强策略。其技术架构图大致如下 [4]:

图 3 中 query 进行 KG 增强是通过 NL2Cypher 模块实现的。根据我的实践,我们可用更简单的[图采样技术]来进行 KG 上下文增强。具体流程是:根据 query 抽取实体,然后把实体作为种子节点对图进行采样(必要时,可把 KG 中节点和 query 中实体先向量化,通过[向量相似度]设置种子节点),然后把获取的子图转换成文本片段,从而达到上下文增强的效果。
LangChain 官网提供了一个通过 Graph 对 RAG 应用进行增强的 DevOps 的例子,感兴趣的读者可以详细研究 [5]。
2.3 多向量检索器多模态 RAG
本小节涉及三种工作模式 [7],具体为:
- 半结构化 RAG(文本 + 表格)
- 多模态 RAG(文本 + 表格 + 图片)
- 私有化多模态 RAG(文本 + 表格 + 图片)
1)半结构化 RAG(文本 + 表格)
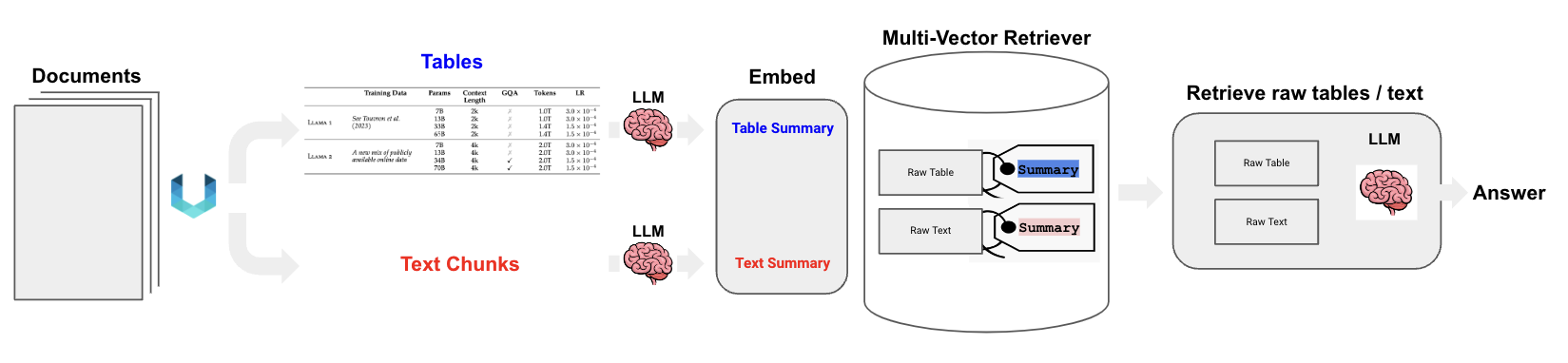
此模式要同时处理文本与表格数据。其核心流程梳理如下 [8]:
- 将原始文档进行版面分析(基于 Unstructured 工具 [9]),生成原始文本 和 原始表格。
- 原始文本和原始表格经 summary LLM 处理,生成文本 summary 和表格 summary。
- 用同一个 embedding 模型把文本 summary 和表格 summary 向量化,并存入多向量检索器。
- 多向量检索器存入文本 / 表格 embedding 的同时,也会存入相应的 summary 和 raw data。
- 用户 query 向量化后,用 ANN 检索召回 raw text 和 raw table。
- 根据 query+raw text+raw table 构造完整 prompt,访问 LLM 生成最终结果。
2)多模态 RAG(文本 + 表格 + 图片)
对多模态 RAG 而言,有三种技术路线 [10],见下图:
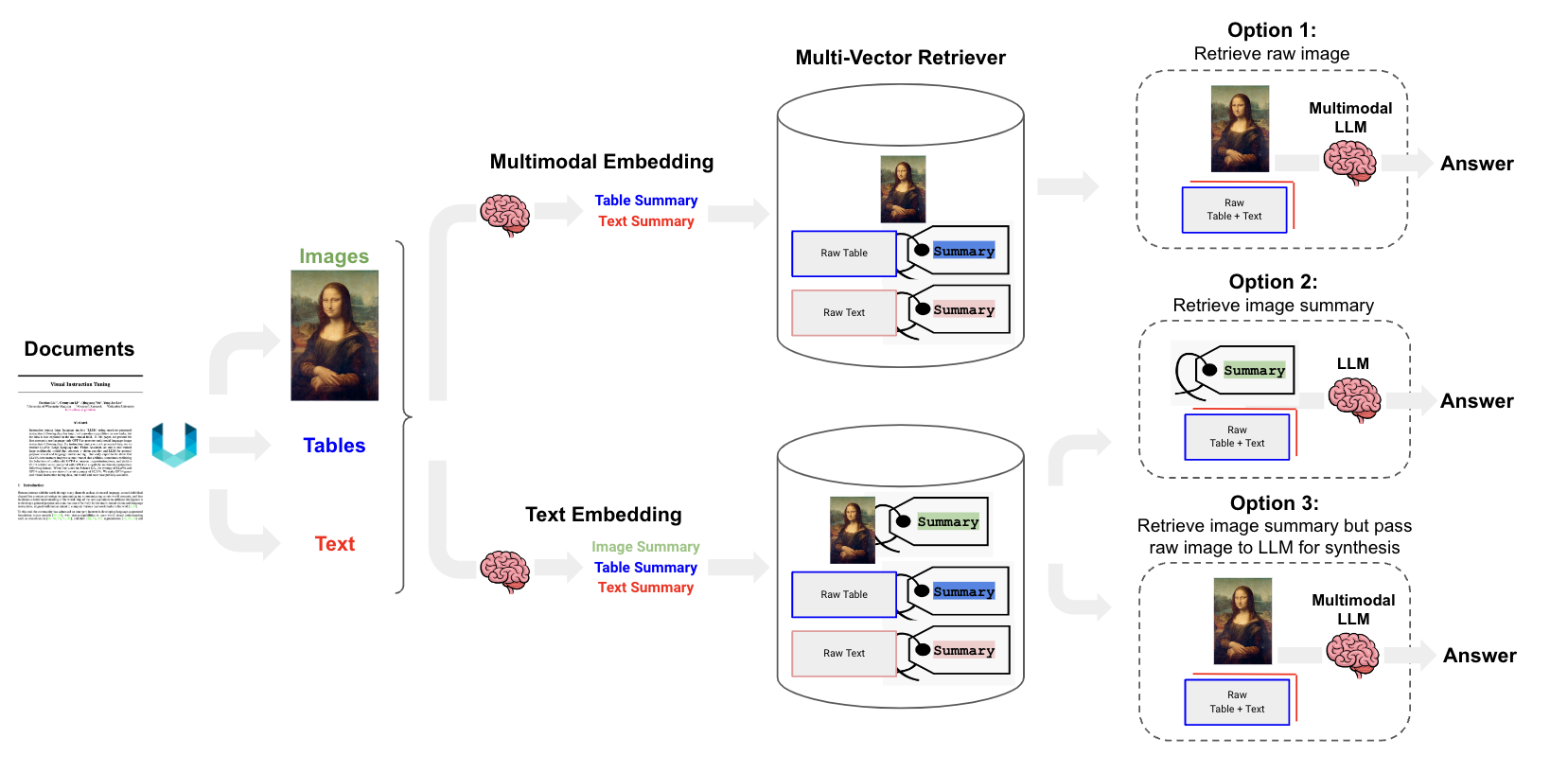
如图 7 所示,对多模态 RAG 而言有三种技术路线,如下我们做个简要说明:
- 选项 1:对文本和表格生成 summary,然后应用多模态 embedding 模型把文本 / 表格 summary、原始图片转化成 embedding 存入多向量检索器。对话时,根据 query 召回原始文本 / 表格 / 图像。然后将其喂给多模态 LLM 生成应答结果。
- 选项 2:首先应用多模态大模型(GPT4-V、LLaVA、FUYU-8b)生成图片 summary。然后对文本 / 表格 / 图片 summary 进行向量化存入多向量检索器中。当生成应答的多模态大模型不具备时,可根据 query 召回原始文本 / 表格 + 图片 summary。
- 选项 3:前置阶段同选项 2 相同。对话时,根据 query 召回原始文本 / 表格 / 图片。构造完整 Prompt,访问多模态大模型生成应答结果。
3)私有化多模态 RAG(文本 + 表格 + 图片)
如果数据安全是重要考量,那就需要把 RAG 流水线进行本地部署。比如可用 LLaVA-7b 生成图片摘要,Chroma 作为向量数据库,Nomic’s GPT4All 作为开源嵌入模型,多向量检索器,Ollama.ai 中的 LLaMA2-13b-chat 用于生成应答 [11]。
posted on 2025-03-11 16:08 ExplorerMan 阅读(429) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号