基于llava-v1.5-7b大模型的图片理解实战
多模态模型:llava-v1.5-7b,主要用于图片理解,本文的使用场景为获取图片标题和图片内容描述。
1、查看服务器配置
nvidia-smiCUDA版本= 12.2,8张24g RTX 3090显卡。
2、环境配置
2.1、克隆此存储库并导航到 LLaVA 文件夹
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA2.2、安装包
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip # enable PEP 660 support
pip install -e .2.3、为培训案例安装附加包
pip install -e ".[train]"
pip install flash-attn --no-build-isolation2.4、升级到最新的代码库
git pull
pip install -e .
# if you see some import errors when you upgrade, please try running the command below (without #)
# pip install flash-attn --no-build-isolation --no-cache-dir3、下载模型
3.1、llava-v1.5-7b下载
liuhaotian/llava-v1.5-7b at main
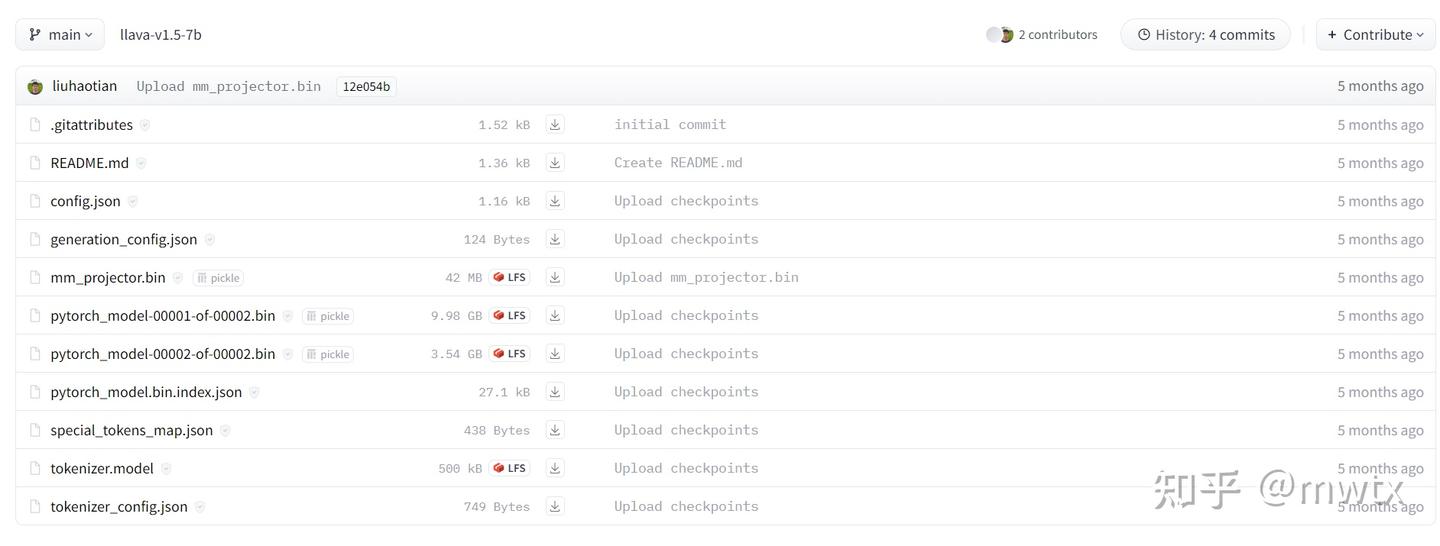
特别注意:LLaVa大模型其中会用到clip-vit-large-patch14-336模型!!!
所以还要下载clip-vit-large-patch14-336模型。并修改llava-v1.5-7b中的config.json。
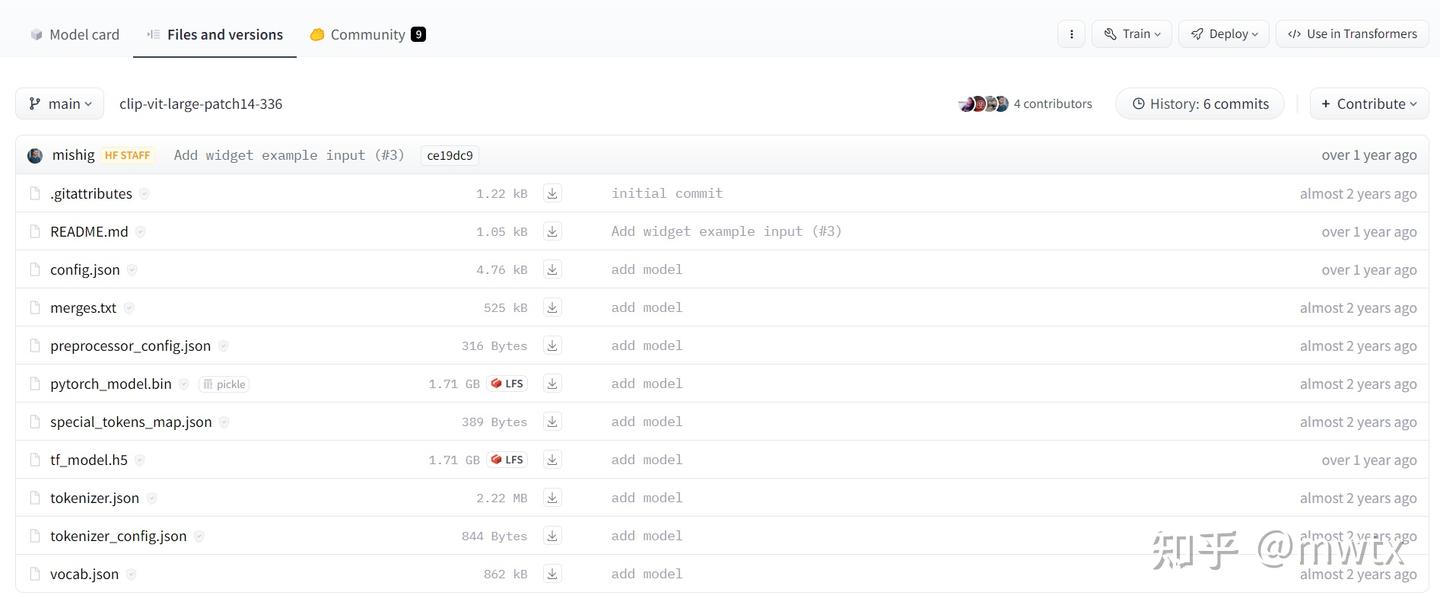
3.2、clip-vit-large-patch14-336下载
openai/clip-vit-large-patch14-336 at main
4、API服务
参考代码:https://github.com/haotian-liu/LLaVA/tree/main/llava/serve/cli.py
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
from llava.conversation import conv_templates, SeparatorStyle
from llava.model.builder import load_pretrained_model
from llava.utils import disable_torch_init
from llava.mm_utils import process_images, tokenizer_image_token, get_model_name_from_path
import torch
from PIL import Image
import requests
from PIL import Image
from io import BytesIO
from transformers import TextStreamer
from pydantic import BaseModel
import uvicorn
from fastapi import FastAPI
# Model
disable_torch_init()
model_path = "/models/llava-v1.6-34b"
model_name = get_model_name_from_path(model_path)
tokenizer, model, image_processor, context_len = load_pretrained_model(
model_path, None, model_name, False, False, device="cuda")
def load_image(image_file):
if image_file.startswith('http://') or image_file.startswith('https://'):
response = requests.get(image_file)
image = Image.open(BytesIO(response.content)).convert('RGB')
else:
image = Image.open(image_file).convert('RGB')
return image
def model_infer(image_file, inp):
"""
模型推断
"""
if "llama-2" in model_name.lower():
conv_mode = "llava_llama_2"
elif "mistral" in model_name.lower():
conv_mode = "mistral_instruct"
elif "v1.6-34b" in model_name.lower():
conv_mode = "chatml_direct"
elif "v1" in model_name.lower():
conv_mode = "llava_v1"
elif "mpt" in model_name.lower():
conv_mode = "mpt"
else:
conv_mode = "llava_v0"
conv = conv_templates[conv_mode].copy()
if "mpt" in model_name.lower():
roles = ('user', 'assistant')
else:
roles = conv.roles
image = load_image(image_file)
image_size = image.size
# Similar operation in model_worker.py
image_tensor = process_images([image], image_processor, model.config)
if type(image_tensor) is list:
image_tensor = [image.to(model.device, dtype=torch.float16) for image in image_tensor]
else:
image_tensor = image_tensor.to(model.device, dtype=torch.float16)
if image is not None:
# first message
if model.config.mm_use_im_start_end:
inp = DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + inp
else:
inp = DEFAULT_IMAGE_TOKEN + '\n' + inp
conv.append_message(conv.roles[0], inp)
image = None
else:
# later messages
conv.append_message(conv.roles[0], inp)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).to(model.device)
stop_str = conv.sep if conv.sep_style != SeparatorStyle.TWO else conv.sep2
keywords = [stop_str]
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor,
image_sizes=[image_size],
do_sample=True,
temperature=0.1,
max_new_tokens=1024,
streamer=streamer,
use_cache=True)
outputs = tokenizer.decode(output_ids[0, 1:-1]).strip()
conv.messages[-1][-1] = outputs
print("\n", {"prompt": prompt, "outputs": outputs}, "\n")
return outputs
app = FastAPI()
class ImageInput(BaseModel):
url: str
ocr_result: str
@app.get('/')
def home():
return 'hello world'
@app.post('/img_desc')
def image_desc(image_input: ImageInput):
title_string = "请为这张图片生成一个中文标题。" if not image_input.ocr_result else \
f'这张图片中的文字为"{image_input.ocr_result}"。请为这张图片生成一个中文标题。'
title_output = model_infer(image_input.url, title_string)
desc_string = "请详细描述这张图片中的内容。" if not image_input.ocr_result else \
f'这张图片中的文字为"{image_input.ocr_result}"。请详细描述这张图片中的内容。'
desc_output = model_infer(image_input.url, desc_string)
return {"url": image_input.url, "title": title_output, "desc": desc_output}
if __name__ == '__main__':
uvicorn.run(app, host="0.0.0.0", port=50075)5、接口展示
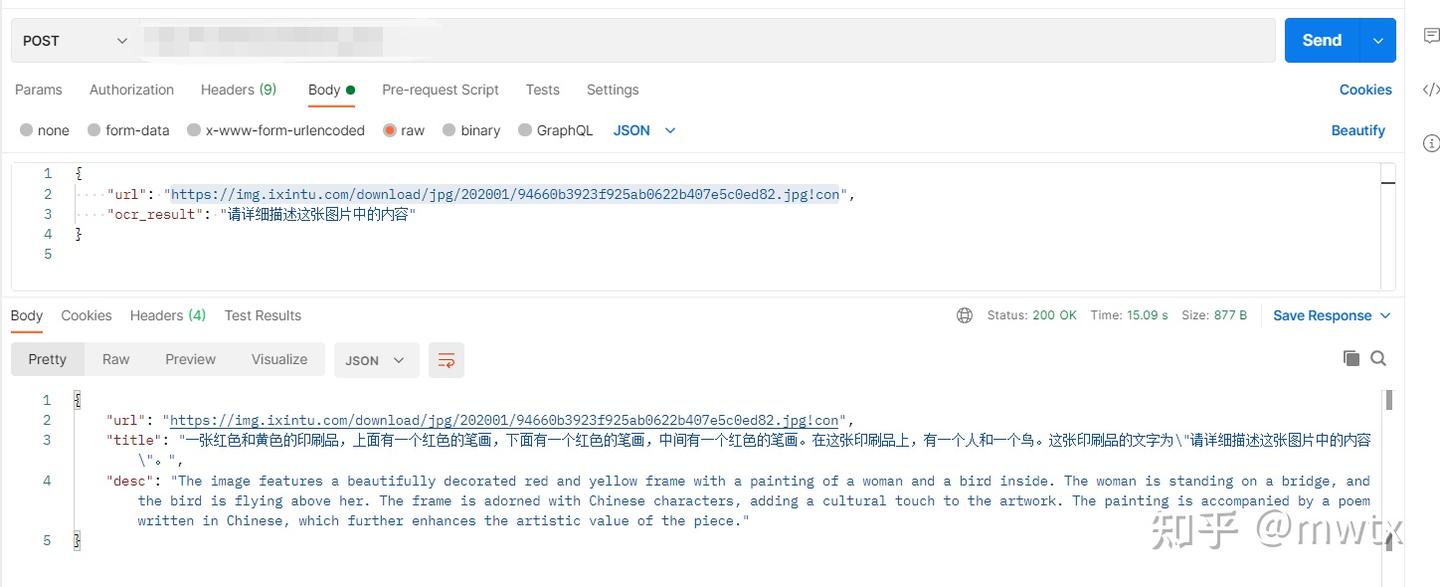
理解能力还是相对差点,后期会结合paddleocr来完善,或者加载llava-v1.6-34b来做测试。
posted on 2025-03-11 16:03 ExplorerMan 阅读(662) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号