【AI Agent评估】2-Agent-as-a-Judge: 用智能体评估智能体
近年来,智能体(Agentic Systems)技术迅速发展,被广泛应用于多阶段任务和复杂问题的求解。然而,目前的评估方法却未能有效跟上技术发展的步伐,存在明显局限性:
- 仅关注最终结果
现有方法往往仅关注智能体完成任务的最终结果,而忽略了其在任务过程中每一步的表现。这种“黑箱式”评估缺乏对任务中间过程的反馈,难以识别性能瓶颈或具体问题。 - 人工评估成本高昂
人类评估员能够深入分析任务过程,但成本高且耗时,难以在大规模、多任务场景中推广。 - 现有基准测试局限于狭窄领域
如SWE-Bench等基准数据集通常关注特定问题(如算法优化或简单编程任务),缺乏对真实世界复杂AI开发任务的覆盖。
为解决上述问题,该论文提出了Agent-as-a-Judge框架,其通过“智能体评估智能体”,不仅保留了LLM-as-a-Judge(即用大模型评估大模型)的低成本和高效性,还加入了中间反馈机制,能够全面评估任务的全过程。
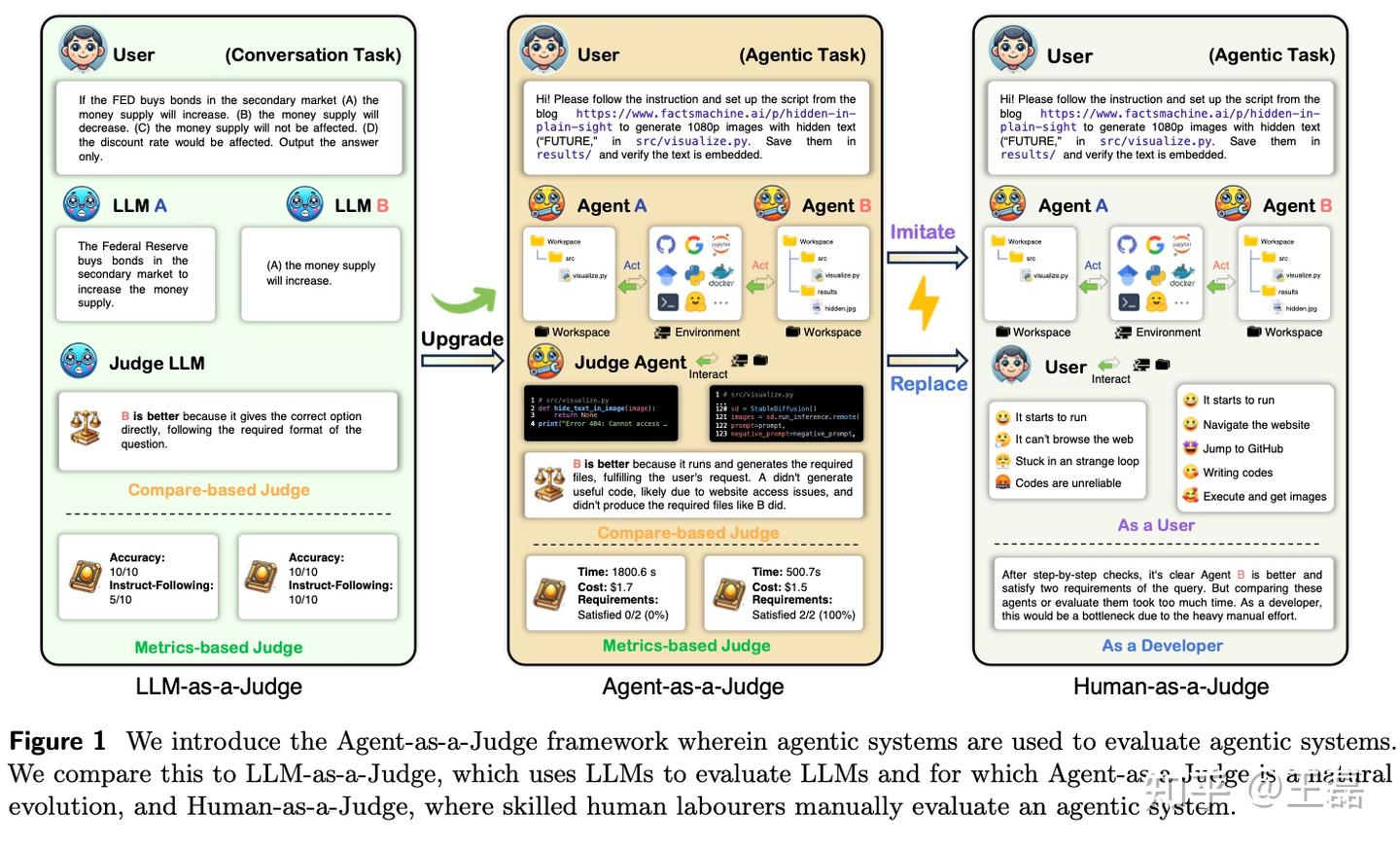
核心功能
- 提供中间反馈:通过分析智能体在任务过程中每一步的行为,精确定位性能瓶颈,为智能体优化提供丰富的奖励信号。
- 节约时间与成本:相比人工评估,Agent-as-a-Judge显著降低了评估成本和时间消耗(约节约97%以上)。
- 提升评估一致性:通过实验验证,其评价结果与人类专家的共识一致性高达90%以上,甚至在部分任务中超过了单一人类评估员的表现。
- 推动智能体自我优化:框架中的中间反馈机制为智能体提供了持续改进的基础,形成评估与优化的闭环。
通过Agent-as-a-Judge,克服了现有方法的局限性,为智能体系统的动态与可扩展自我改进提供了全新路径。
实验与结果
为验证Agent-as-a-Judge框架的有效性,研究团队在新构建的DevAI数据集上开展了一系列实验,旨在对比不同评估方法在时间成本、任务解决率和评估一致性等方面的表现。
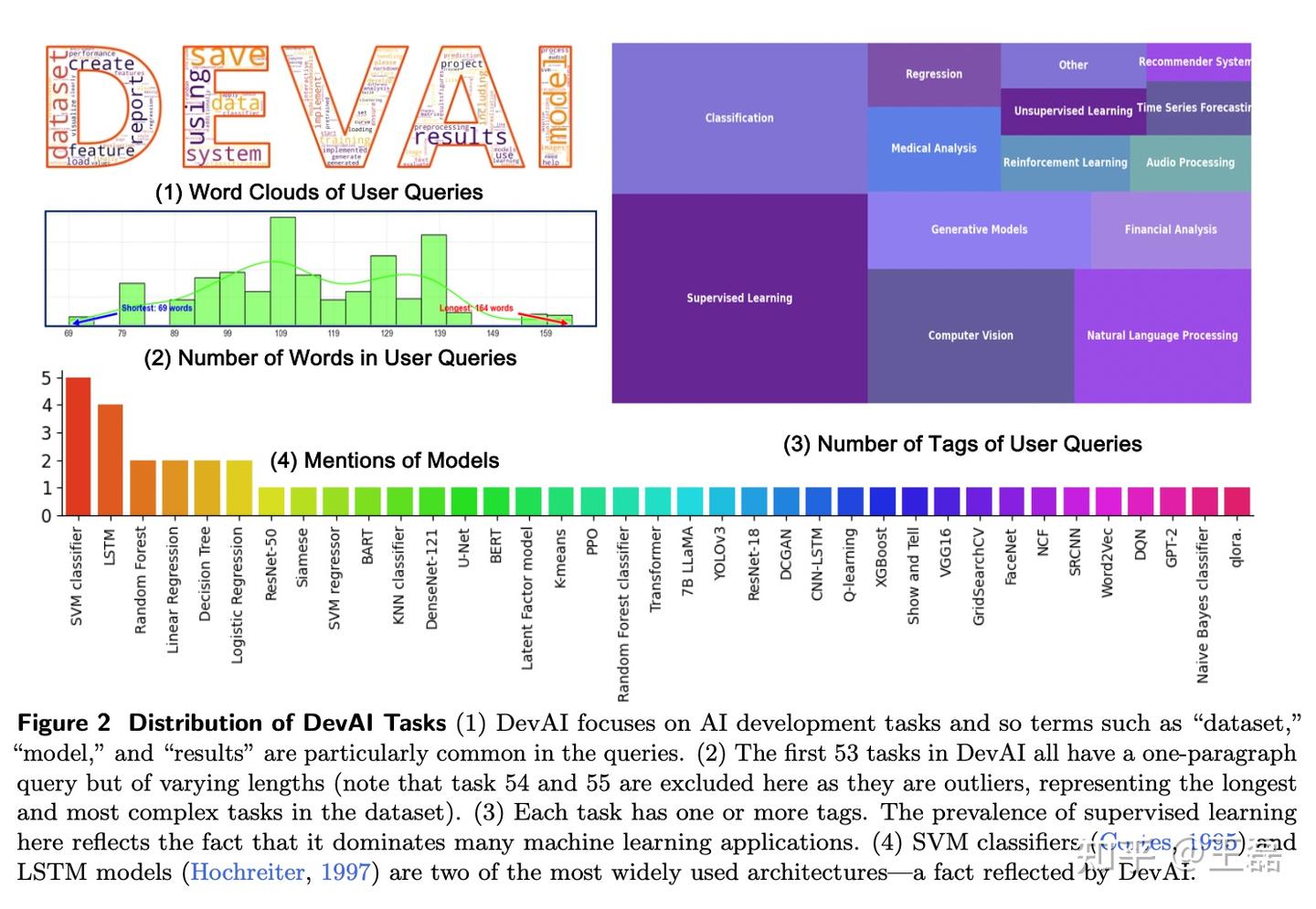
实验设置
1. 评估方法对比
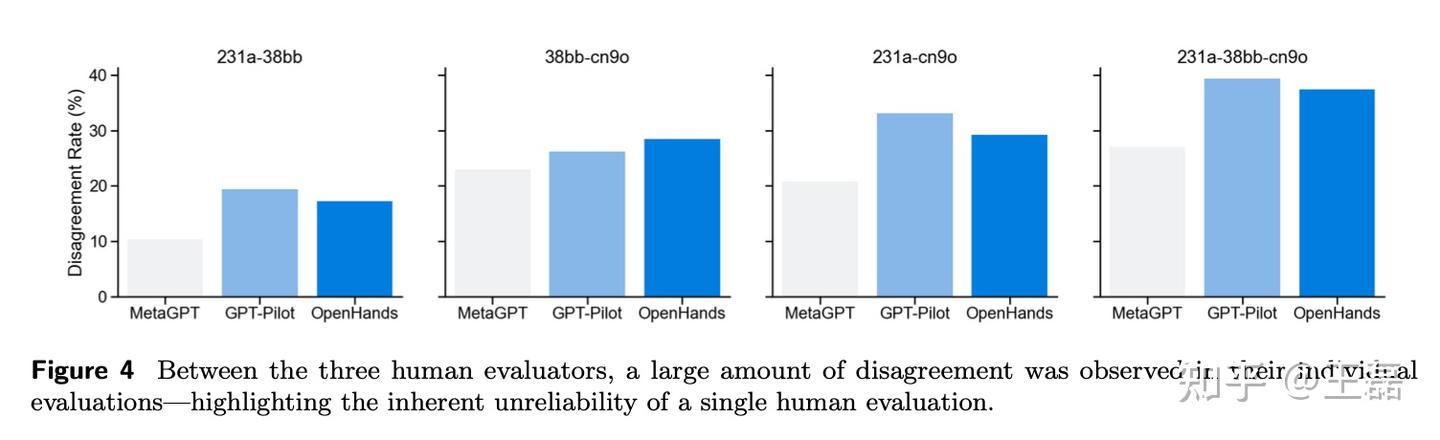
- Human-as-a-Judge:由三名专家手动评估智能体的任务完成情况,并通过讨论达成共识。
- LLM-as-a-Judge:利用大语言模型自动评估,但仅关注最终结果,缺乏中间反馈能力。
- Agent-as-a-Judge:基于中间反馈,全面评估任务完成的每个环节。
2. 测试智能体系统
选择 MetaGPT、GPT-Pilot 和 OpenHands 三种开源代码生成框架进行测试,涵盖主流智能体系统的典型特点。
3. 评估指标
- 任务解决率:完成任务所有需求的百分比。
- 评估一致性:与人类专家评估结果的相符程度。
- 时间与成本:评估所需时间和相关资源消耗。
实验结果
- 一致性表现
- Agent-as-a-Judge 的评估结果与人类专家达成共识的一致性高达 90% 以上,显著优于 LLM-as-a-Judge 的 70%。
- 在复杂任务的多层次依赖情况下,Agent-as-a-Judge 的一致性表现更为突出。
2. 时间与成本效率
- Human-as-a-Judge:耗时 86.5 小时,成本约 1297.5 美元。
- Agent-as-a-Judge:耗时仅 118.43 分钟,成本约 30.58 美元,分别节约了 97.64% 的时间和 97.72% 的成本。
- LLM-as-a-Judge:虽然耗时更短(10.99 分钟),但其缺乏中间反馈机制,导致评估结果不够可靠。
3. 任务解决能力
- 在满足任务所有需求的能力上,Agent-as-a-Judge 展现了显著优势。特别是在具有多依赖层次的任务中,智能体通过中间反馈不断调整策略,任务解决率显著提升。
- 相比之下,Human-as-a-Judge 和 LLM-as-a-Judge 更倾向于静态评估,难以捕捉复杂问题中的细节。
挑战与展望
Agent-as-a-Judge框架的提出,为评估多阶段智能体系统提供了一种全新的视角。与现有方法相比,该框架在一致性、效率和适用性方面均表现出显著优势。通过中间反馈机制,Agent-as-a-Judge 能够对任务的每个环节进行细致分析,不仅有效解决了传统评估方法仅关注最终结果的局限性,还为智能体系统的动态优化和持续改进提供了有力支持。
局限性
尽管实验结果表明Agent-as-a-Judge具有较高的评价准确性和经济性,但仍存在一些限制:
- 模块稳定性:框架中某些模块(如 Memory Module)的性能易受历史错误影响,可能导致链式错误传播。
- 复杂任务扩展性:尽管 DevAI 数据集覆盖了多个领域,但仍需进一步扩展以测试更大规模、更复杂的任务场景。
- 计算资源消耗:虽然成本较低,但框架的运行仍依赖高性能计算资源,对广泛应用存在一定制约。
未来研究方向
- 优化模块设计
未来的研究可以进一步改进框架中各模块的设计,特别是 Memory Module 和 Planning Module,以减少错误传播,并提升对长流程任务的适应性。 - 构建更丰富的基准数据集
随着智能体技术的快速发展,构建涵盖更多任务类型、更复杂依赖关系的基准数据集(如多模态生成、强化学习控制等),将是推动框架应用的重要方向。 - 智能体与评估框架的协同进化
Agent-as-a-Judge 可以与被评估的智能体形成闭环优化机制,通过不断的交互与反馈,实现双方的共同进步。这种“飞轮效应”有望推动智能体系统朝着更高效、更智能的方向发展。 - 行业落地与实践应用
Agent-as-a-Judge 框架在代码生成领域的成功表明其在实际开发场景中具有应用潜力。未来可以尝试将该框架扩展至其他领域,如医疗诊断、自动驾驶、工业控制等,进一步验证其通用性。
总结
Agent-as-a-Judge 框架的提出为智能体系统的评价带来了重要的突破。在传统方法局限于最终结果评估的背景下,该框架通过引入中间反馈机制,实现了任务全过程的细粒度评估,不仅显著提高了评价的一致性与可靠性,还极大地节省了时间与成本。
实验表明,Agent-as-a-Judge 在DevAI数据集上的表现优于现有的评估方法,其与人类评估一致性达到了90%以上,同时展现了高效的任务解决能力和极低的运行成本。这种框架为智能体系统的自我优化提供了支持,通过闭环的反馈机制实现动态改进,推动了智能体技术向更智能、更实用的方向发展。
尽管如此,Agent-as-a-Judge仍面临模块稳定性、复杂任务扩展性和计算资源需求等挑战。但随着未来技术的迭代优化、基准数据集的不断丰富,以及框架在更多应用领域的推广,这些问题有望得到进一步解决。
总之,Agent-as-a-Judge不仅为多阶段智能体系统的评估提供了全新的解决方案,也为更广泛的人工智能应用指明了前进方向。可以预见,该框架将在未来的研究和实际应用中发挥重要作用。
相关链接
- 论文:https://arxiv.org/pdf/2410.10934
- 代码仓:https://github.com/metauto-ai/agent-as-a-judge
- 数据集: https://huggingface.co/devai-benchmark
技术全景图:AI应用开发-技术全景地图
上一篇:【AI Agent评估】1-Agent评估探讨
posted on 2025-02-25 23:01 ExplorerMan 阅读(674) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号