pyspark教程
Apache Spark是用 Scala编程语言 编写的。为了用Spark支持Python,Apache Spark社区发布了一个工具PySpark。使用PySpark,您也可以使用Python编程语言中的 RDD 。正是由于一个名为 Py4j 的库,他们才能实现这一目标。
它将创建一个目录 spark-2.1.0-bin-hadoop2.7 。在启动PySpark之前,需要设置以下环境来设置Spark路径和 Py4j路径 。
export SPARK_HOME = /home/hadoop/spark-2.1.0-bin-hadoop2.7
export PATH = $PATH:/home/hadoop/spark-2.1.0-bin-hadoop2.7/bin
export PYTHONPATH = $SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH
export PATH = $SPARK_HOME/python:$PATH
或者,要全局设置上述环境,请将它们放在 .bashrc文件中 。然后运行以下命令以使环境正常工作。
# source .bashrc
SparkContext是任何spark功能的入口点。当我们运行任何Spark应用程序时,启动一个驱动程序,它具有main函数,并在此处启动SparkContext。然后,驱动程序在工作节点上的执行程序内运行操作。
SparkContext使用Py4J启动 JVM 并创建 JavaSparkContext。默认情况下,PySpark将SparkContext作为 'sc'提供 ,因此创建新的SparkContext将不起作用。
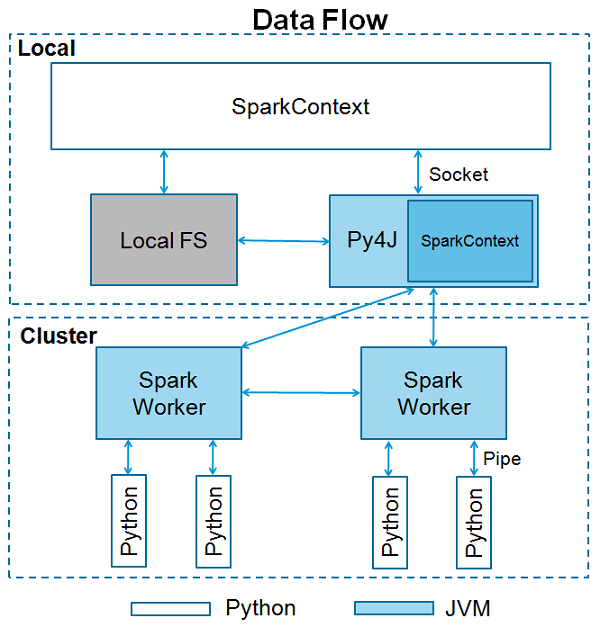
以下代码块包含PySpark类的详细信息以及SparkContext可以采用的参数。
class pyspark.SparkContext (
master = None,
appName = None,
sparkHome = None,
pyFiles = None,
environment = None,
batchSize = 0,
serializer = PickleSerializer(),
conf = None,
gateway = None,
jsc = None,
profiler_cls = <class 'pyspark.profiler.BasicProfiler'>
)
参数
以下是SparkContext的参数。
-
Master - 它是连接到的集群的URL。
-
appName - 您的工作名称。
-
sparkHome - Spark安装目录。
-
pyFiles - 要发送到集群并添加到PYTHONPATH的.zip或.py文件。
-
environment - 工作节点环境变量。
-
batchSize - 表示为单个Java对象的Python对象的数量。 设置1以禁用批处理,设置0以根据对象大小自动选择批处理大小,或设置为-1以使用无限批处理大小。
-
serializer - RDD序列化器。
-
Conf - L {SparkConf}的一个对象,用于设置所有Spark属性。
-
gateway - 使用现有网关和JVM,否则初始化新JVM。
-
JSC - JavaSparkContext实例。
-
profiler_cls - 用于进行性能分析的一类自定义Profiler(默认为pyspark.profiler.BasicProfiler)。
在上述参数中,主要使用 master 和 appname 。任何PySpark程序的前两行如下所示
from pyspark import SparkContext
sc = SparkContext("local", "First App")
SparkContext示例 - PySpark Shell
现在你已经对SparkContext有了足够的了解,让我们在PySpark shell上运行一个简单的例子。在此示例中,我们将计算 README.md 文件中带有字符“a”或“b”的行 数 。那么,让我们说一个文件中有5行,3行有'a'字符,那么输出将是→ Line with a:3 。字符'b'也是如此。
注 - 我们不会在以下示例中创建任何SparkContext对象,因为默认情况下,当PySpark shell启动时,Spark会自动创建名为sc的SparkContext对象。 如果您尝试创建另一个SparkContext对象,您将收到以下错误 “ValueError:无法一次运行多个SparkContexts”。
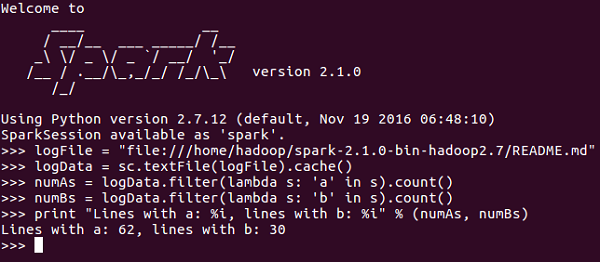
<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
<<< logData = sc.textFile(logFile).cache()
<<< numAs = logData.filter(lambda s: 'a' in s).count()
<<< numBs = logData.filter(lambda s: 'b' in s).count()
<<< print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
Lines with a: 62, lines with b: 30
SparkContext示例 - Python程序
让我们使用Python程序运行相同的示例。创建一个名为 firstapp.py 的Python文件,并在该文件中输入以下代码。
----------------------------------------firstapp.py---------------------------------------
from pyspark import SparkContext
logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
----------------------------------------firstapp.py---------------------------------------
然后我们将在终端中执行以下命令来运行此Python文件。我们将得到与上面相同的输出。
$SPARK_HOME/bin/spark-submit firstapp.py
Output: Lines with a: 62, lines with b: 30
现在我们已经在我们的系统上安装并配置了PySpark,我们可以在Apache Spark上用Python编程。但在此之前,让我们了解Spark - RDD中的一个基本概念。
RDD代表 Resilient Distributed Dataset,它们是在多个节点上运行和操作以在集群上进行并行处理的元素。RDD是不可变元素,这意味着一旦创建了RDD,就无法对其进行更改。RDD也具有容错能力,因此在发生任何故障时,它们会自动恢复。您可以在这些RDD上应用多个操作来完成某项任务。
要对这些RDD进行操作,有两种方法
- Transformation
- Action
让我们详细了解这两种方式。
转换 - 这些操作应用于RDD以创建新的RDD。 Filter,groupBy和map是转换的例子。
操作 - 这些是应用于RDD的操作,它指示Spark执行计算并将结果发送回驱动程序。
要在PySpark中应用任何操作,我们首先需要创建一个 PySpark RDD 。以下代码块具有PySpark RDD类的详细信息
class pyspark.RDD (
jrdd,
ctx,
jrdd_deserializer = AutoBatchedSerializer(PickleSerializer())
)
让我们看看如何使用PySpark运行一些基本操作。Python文件中的以下代码创建RDD单词,其中存储了一组提到的单词。
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
我们现在将对单词进行一些操作。
count()
返回RDD中的元素数。
----------------------------------------count.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "count app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
counts = words.count()
print "Number of elements in RDD -> %i" % (counts)
----------------------------------------count.py---------------------------------------
命令 - count()的命令是
$SPARK_HOME/bin/spark-submit count.py
输出 - 上述命令的输出是
Number of elements in RDD → 8
搜集()
返回RDD中的所有元素。
----------------------------------------collect.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Collect app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
coll = words.collect()
print "Elements in RDD -> %s" % (coll)
----------------------------------------collect.py---------------------------------------
命令 - collect()的命令是
$SPARK_HOME/bin/spark-submit collect.py
输出 - 上述命令的输出是
Elements in RDD -> [
'scala',
'java',
'hadoop',
'spark',
'akka',
'spark vs hadoop',
'pyspark',
'pyspark and spark'
]
foreach(F)
仅返回满足foreach内函数条件的元素。在下面的示例中,我们在foreach中调用print函数,它打印RDD中的所有元素。
----------------------------------------foreach.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "ForEach app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
def f(x): print(x)
fore = words.foreach(f)
----------------------------------------foreach.py---------------------------------------
命令 - foreach(f)的命令是
$SPARK_HOME/bin/spark-submit foreach.py
输出 - 上述命令的输出是
scala
java
hadoop
spark
akka
spark vs hadoop
pyspark
pyspark and spark
filter(f)
返回一个包含元素的新RDD,它满足过滤器内部的功能。在下面的示例中,我们过滤掉包含''spark'的字符串。
----------------------------------------filter.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Filter app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_filter = words.filter(lambda x: 'spark' in x)
filtered = words_filter.collect()
print "Fitered RDD -> %s" % (filtered)
----------------------------------------filter.py----------------------------------------
命令 - 过滤器(f)的命令是
$SPARK_HOME/bin/spark-submit filter.py
输出 - 上述命令的输出是
Fitered RDD -> [
'spark',
'spark vs hadoop',
'pyspark',
'pyspark and spark'
]
map(f,preservesPartitioning = False)
通过将函数应用于RDD中的每个元素来返回新的RDD。在下面的示例中,我们形成一个键值对,并将每个字符串映射为值1。
----------------------------------------map.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Map app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_map = words.map(lambda x: (x, 1))
mapping = words_map.collect()
print "Key value pair -> %s" % (mapping)
----------------------------------------map.py---------------------------------------
命令 - map命令(f,preservesPartitioning = False)是
$SPARK_HOME/bin/spark-submit map.py
输出 - 上述命令的输出是
Key value pair -> [
('scala', 1),
('java', 1),
('hadoop', 1),
('spark', 1),
('akka', 1),
('spark vs hadoop', 1),
('pyspark', 1),
('pyspark and spark', 1)
]
reduce(F)
执行指定的可交换和关联二进制操作后,将返回RDD中的元素。在下面的示例中,我们从运算符导入add包并将其应用于'num'以执行简单的加法运算。
----------------------------------------reduce.py---------------------------------------
from pyspark import SparkContext
from operator import add
sc = SparkContext("local", "Reduce app")
nums = sc.parallelize([1, 2, 3, 4, 5])
adding = nums.reduce(add)
print "Adding all the elements -> %i" % (adding)
----------------------------------------reduce.py---------------------------------------
命令 - reduce(f)的命令是
$SPARK_HOME/bin/spark-submit reduce.py
输出 - 上述命令的输出是
Adding all the elements -> 15
join(other,numPartitions = None)
它返回RDD,其中包含一对带有匹配键的元素以及该特定键的所有值。在以下示例中,两个不同的RDD中有两对元素。在连接这两个RDD之后,我们得到一个RDD,其元素具有匹配的键及其值。
----------------------------------------join.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Join app")
x = sc.parallelize([("spark", 1), ("hadoop", 4)])
y = sc.parallelize([("spark", 2), ("hadoop", 5)])
joined = x.join(y)
final = joined.collect()
print "Join RDD -> %s" % (final)
----------------------------------------join.py---------------------------------------
命令 - 连接命令(其他,numPartitions =无)是
$SPARK_HOME/bin/spark-submit join.py
输出 - 上述命令的输出是
Join RDD -> [
('spark', (1, 2)),
('hadoop', (4, 5))
]
cache()
使用默认存储级别(MEMORY_ONLY)保留此RDD。您还可以检查RDD是否被缓存。
----------------------------------------cache.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Cache app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words.cache()
caching = words.persist().is_cached
print "Words got chached > %s" % (caching)
----------------------------------------cache.py---------------------------------------
命令 - cache()的命令是
$SPARK_HOME/bin/spark-submit cache.py
输出 - 上述程序的输出是
Words got cached -> True
这些是在PySpark RDD上完成的一些最重要的操作。
对于并行处理,Apache Spark使用共享变量。当驱动程序将任务发送到集群上的执行程序时,共享变量的副本将在集群的每个节点上运行,以便可以将其用于执行任务。
Apache Spark支持两种类型的共享变量
- Broadcast
- Accumulator
让我们详细了解它们。
广播
广播变量用于跨所有节点保存数据副本。此变量缓存在所有计算机上,而不是在具有任务的计算机上发送。以下代码块包含PySpark的Broadcast类的详细信息。
class pyspark.Broadcast (
sc = None,
value = None,
pickle_registry = None,
path = None
)
以下示例显示如何使用Broadcast变量。Broadcast变量有一个名为value的属性,它存储数据并用于返回广播值。
----------------------------------------broadcast.py--------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Broadcast app")
words_new = sc.broadcast(["scala", "java", "hadoop", "spark", "akka"])
data = words_new.value
print "Stored data -> %s" % (data)
elem = words_new.value[2]
print "Printing a particular element in RDD -> %s" % (elem)
----------------------------------------broadcast.py--------------------------------------
命令 - 广播变量的命令如下
$SPARK_HOME/bin/spark-submit broadcast.py
输出 - 以下命令的输出如下。
Stored data -> [
'scala',
'java',
'hadoop',
'spark',
'akka'
]
Printing a particular element in RDD -> hadoop
累加器
累加器变量用于通过关联和交换操作聚合信息。例如,您可以使用累加器进行求和操作或计数器(在MapReduce中)。以下代码块包含PySpark的Accumulator类的详细信息。
class pyspark.Accumulator(aid, value, accum_param)
以下示例显示如何使用Accumulator变量。Accumulator变量有一个名为value的属性,类似于广播变量。它存储数据并用于返回累加器的值,但仅在驱动程序中可用。
在此示例中,累加器变量由多个工作程序使用并返回累计值。
----------------------------------------accumulator.py------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Accumulator app")
num = sc.accumulator(10)
def f(x):
global num
num+=x
rdd = sc.parallelize([20,30,40,50])
rdd.foreach(f)
final = num.value
print "Accumulated value is -> %i" % (final)
----------------------------------------accumulator.py------------------------------------
命令 - 累加器变量的命令如下
$SPARK_HOME/bin/spark-submit accumulator.py
输出 - 上面命令的输出如下。
Accumulated value is -> 150
要在本地/集群上运行Spark应用程序,您需要设置一些配置和参数,这是SparkConf帮助的。它提供运行Spark应用程序的配置。以下代码块包含PySpark的SparkConf类的详细信息。
class pyspark.SparkConf (
loadDefaults = True,
_jvm = None,
_jconf = None
)
最初,我们将使用SparkConf()创建一个SparkConf对象,它将从 spark。* Java系统属性加载值。现在,您可以使用SparkConf对象设置不同的参数,它们的参数将优先于系统属性。
在SparkConf类中,有一些setter方法,它们支持链接。例如,您可以编写 conf.setAppName(“PySparkApp”)。setMaster(“local”) 。一旦我们将SparkConf对象传递给Apache Spark,任何用户都无法修改它。
以下是SparkConf最常用的一些属性
-
set(key,value) - 设置配置属性。
-
setMaster(value) - 设置主URL。
-
setAppName(value) - 设置应用程序名称。
-
get(key,defaultValue = None) - 获取密钥的配置值。
-
setSparkHome(value) - 在工作节点上设置Spark安装路径。
让我们考虑以下在PySpark程序中使用SparkConf的示例。在此示例中,我们将spark应用程序名称设置为 PySpark App,并将spark应用程序的主URL设置为→ spark:// master:7077 。
以下代码块包含这些行,当它们添加到Python文件中时,它会设置运行PySpark应用程序的基本配置。
---------------------------------------------------------------------------------------
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("PySpark App").setMaster("spark://master:7077")
sc = SparkContext(conf=conf)
---------------------------------------------------------------------------------------
在Apache Spark中,您可以使用 sc.addFile 上传文件(sc是您的默认SparkContext),并使用 SparkFiles.get 获取工作者的路径。因此,SparkFiles解析通过 SparkContext.addFile() 添加的文件的路径。
SparkFiles包含以下类方法
- get(filename)
- getrootdirectory()
让我们详细了解它们。
get(filename)
它指定通过SparkContext.addFile()添加的文件的路径。
getrootdirectory()
它指定根目录的路径,该目录包含通过SparkContext.addFile()添加的文件。
----------------------------------------sparkfile.py------------------------------------
from pyspark import SparkContext
from pyspark import SparkFiles
finddistance = "/home/hadoop/examples_pyspark/finddistance.R"
finddistancename = "finddistance.R"
sc = SparkContext("local", "SparkFile App")
sc.addFile(finddistance)
print "Absolute Path -> %s" % SparkFiles.get(finddistancename)
----------------------------------------sparkfile.py------------------------------------
命令 - 命令如下
$SPARK_HOME/bin/spark-submit sparkfiles.py
输出 - 上述命令的输出是
Absolute Path ->
/tmp/spark-f1170149-af01-4620-9805-f61c85fecee4/userFiles-641dfd0f-240b-4264-a650-4e06e7a57839/finddistance.R
StorageLevel决定如何存储RDD。在Apache Spark中,StorageLevel决定RDD是应该存储在内存中还是存储在磁盘上,或两者都存储。它还决定是否序列化RDD以及是否复制RDD分区。
以下代码块具有StorageLevel的类定义
class pyspark.StorageLevel(useDisk, useMemory, useOffHeap, deserialized, replication = 1)
现在,为了确定RDD的存储,有不同的存储级别,如下所示 -
-
DISK_ONLY = StorageLevel(True,False,False,False,1)
-
DISK_ONLY_2 = StorageLevel(True,False,False,False,2)
-
MEMORY_AND_DISK = StorageLevel(True,True,False,False,1)
-
MEMORY_AND_DISK_2 = StorageLevel(True,True,False,False,2)
-
MEMORY_AND_DISK_SER = StorageLevel(True,True,False,False,1)
-
MEMORY_AND_DISK_SER_2 = StorageLevel(True,True,False,False,2)
-
MEMORY_ONLY = StorageLevel(False,True,False,False,1)
-
MEMORY_ONLY_2 = StorageLevel(False,True,False,False,2)
-
MEMORY_ONLY_SER = StorageLevel(False,True,False,False,1)
-
MEMORY_ONLY_SER_2 = StorageLevel(False,True,False,False,2)
-
OFF_HEAP = StorageLevel(True,True,True,False,1)
让我们考虑以下StorageLevel示例,其中我们使用存储级别 MEMORY_AND_DISK_2, 这意味着RDD分区将具有2的复制。
------------------------------------storagelevel.py-------------------------------------
from pyspark import SparkContext
import pyspark
sc = SparkContext (
"local",
"storagelevel app"
)
rdd1 = sc.parallelize([1,2])
rdd1.persist( pyspark.StorageLevel.MEMORY_AND_DISK_2 )
rdd1.getStorageLevel()
print(rdd1.getStorageLevel())
------------------------------------storagelevel.py-------------------------------------
命令 - 命令如下
$SPARK_HOME/bin/spark-submit storagelevel.py
输出 - 上述命令的输出如下
Disk Memory Serialized 2x Replicated
Apache Spark提供了一个名为 MLlib 的机器学习API。PySpark也在Python中使用这个机器学习API。它支持不同类型的算法,如下所述
-
mllib.classification - spark.mllib 包支持二进制分类,多类分类和回归分析的各种方法。分类中一些最流行的算法是 随机森林,朴素贝叶斯,决策树 等。
-
mllib.clustering - 聚类是一种无监督的学习问题,您可以根据某些相似概念将实体的子集彼此分组。
-
mllib.fpm - 频繁模式匹配是挖掘频繁项,项集,子序列或其他子结构,这些通常是分析大规模数据集的第一步。 多年来,这一直是数据挖掘领域的一个活跃的研究课题。
-
mllib.linalg - 线性代数的MLlib实用程序。
-
mllib.recommendation - 协同过滤通常用于推荐系统。 这些技术旨在填写用户项关联矩阵的缺失条目。
-
spark.mllib - 它目前支持基于模型的协同过滤,其中用户和产品由一小组可用于预测缺失条目的潜在因素描述。 spark.mllib使用交替最小二乘(ALS)算法来学习这些潜在因素。
-
mllib.regression - 线性回归属于回归算法族。 回归的目标是找到变量之间的关系和依赖关系。使用线性回归模型和模型摘要的界面类似于逻辑回归案例。
还有其他算法,类和函数也作为mllib包的一部分。截至目前,让我们了解一下 pyspark.mllib 的演示。
以下示例是使用ALS算法进行协同过滤以构建推荐模型并在训练数据上进行评估。
使用数据集 - test.data
1,1,5.0
1,2,1.0
1,3,5.0
1,4,1.0
2,1,5.0
2,2,1.0
2,3,5.0
2,4,1.0
3,1,1.0
3,2,5.0
3,3,1.0
3,4,5.0
4,1,1.0
4,2,5.0
4,3,1.0
4,4,5.0
--------------------------------------recommend.py----------------------------------------
from __future__ import print_function
from pyspark import SparkContext
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating
if __name__ == "__main__":
sc = SparkContext(appName="Pspark mllib Example")
data = sc.textFile("test.data")
ratings = data.map(lambda l: l.split(','))\
.map(lambda l: Rating(int(l[0]), int(l[1]), float(l[2])))
# Build the recommendation model using Alternating Least Squares
rank = 10
numIterations = 10
model = ALS.train(ratings, rank, numIterations)
# Evaluate the model on training data
testdata = ratings.map(lambda p: (p[0], p[1]))
predictions = model.predictAll(testdata).map(lambda r: ((r[0], r[1]), r[2]))
ratesAndPreds = ratings.map(lambda r: ((r[0], r[1]), r[2])).join(predictions)
MSE = ratesAndPreds.map(lambda r: (r[1][0] - r[1][1])**2).mean()
print("Mean Squared Error = " + str(MSE))
# Save and load model
model.save(sc, "target/tmp/myCollaborativeFilter")
sameModel = MatrixFactorizationModel.load(sc, "target/tmp/myCollaborativeFilter")
--------------------------------------recommend.py----------------------------------------
命令 - 命令如下
$SPARK_HOME/bin/spark-submit recommend.py
输出 - 上述命令的输出将为
Mean Squared Error = 1.20536041839e-05
序列化用于Apache Spark的性能调优。通过网络发送或写入磁盘或持久存储在内存中的所有数据都应序列化。序列化在昂贵的操作中起着重要作用。
PySpark支持用于性能调优的自定义序列化程序。PySpark支持以下两个序列化程序
MarshalSerializer
使用Python的Marshal Serializer序列化对象。此序列化程序比PickleSerializer更快,但支持更少的数据类型。
class pyspark.MarshalSerializer
PickleSerializer
使用Python的Pickle Serializer序列化对象。此序列化程序几乎支持任何Python对象,但可能不如更专业的序列化程序快。
class pyspark.PickleSerializer
让我们看一下PySpark序列化的例子。在这里,我们使用MarshalSerializer序列化数据。
--------------------------------------serializing.py-------------------------------------
from pyspark.context import SparkContext
from pyspark.serializers import MarshalSerializer
sc = SparkContext("local", "serialization app", serializer = MarshalSerializer())
print(sc.parallelize(list(range(1000))).map(lambda x: 2 * x).take(10))
sc.stop()
--------------------------------------serializing.py-------------------------------------
Command - 命令如下
$SPARK_HOME/bin/spark-submit serializing.py
输出 - 上述命令的输出是
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
posted on 2021-02-01 15:22 ExplorerMan 阅读(1487) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号