缓冲区输入流
缓冲区输入流也和文件输入流差不多,直接看代码:
1 package com.hw.file0221;
2
3 import java.io.BufferedInputStream;
4 import java.io.FileInputStream;
5 import java.io.FileNotFoundException;
6 import java.io.IOException;
7
8 public class Demo02TestBufferedInputStream {
9 public static void main(String[] args) {
10
11 BufferedInputStream input = null;
12 FileInputStream fileinput;
13 try {
14 fileinput = new FileInputStream("F://骚操作//demotest01.txt");
15 input = new BufferedInputStream(fileinput);
16
17 int data = input.read(); //按字节
18 System.out.println((char)data);
19 data = input.read();
20 System.out.println((char)data);
21 data = input.read();
22 System.out.println((char)data);
23
24 byte[] info = new byte[1024]; //按数组
25 int length = input.read(info);
26 String str = new String(info,0,length);
27 System.out.println(str);
28
29 } catch (IOException e) {
30 // TODO Auto-generated catch block
31 e.printStackTrace();
32 }finally{
33 try {
34 if(input != null){
35 input.close();
36 }
37 } catch (IOException e) {
38 // TODO Auto-generated catch block
39 e.printStackTrace();
40 }
41 }
42 }
43 }
读取文件也是可以按字节或者按照字节数组来。
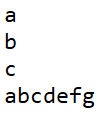
对于第一种方法,表面上看好像只读取了一个字节,但其实读取了很多个字节,根据缓冲区数组的大小把这些数据全部填充,以后每次再调用read方法的时候,其实是从缓冲区里面拿数据,而不需要跟硬盘发生交互,这样是很节约性能的。
第一种方法也是同理,只不过是第一种方法是一次从缓冲区里面取一个数据,而第二种是一次从缓冲区中取1024个数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号