不重复数字
题目描述:
小李最近遇到了一个难题,聪明的你帮她解决一下吧。
给出N个数,要求把其中重复的去掉,只保留第一次出现的数。
输入:
输出:
对于每组数据,输出一行,为去重后剩下的数字,数字之间用一个空格隔开。
样例输入:
2
11
1 2 18 3 3 19 2 3 6 5 4
6
1 2 3 4 5 6
样例输出:
1 2 18 3 19 6 5 4
1 2 3 4 5 6
分析:
对于这道题,我们可以这么想:我们首先把这些数据全部存进一个数组里,然后把这个数组的第一个元素拿出来,假设赋给a,再用一个循环,把这个元素依次与它后面的元素作比较,一旦发现有相同元素,假设把这个相同元素赋给b,然后我们再弄一个循环,让b后面的元素依次往前面移一位,这样就完成了去重。当然这整个过程都在一个循环里面完成。代码实现如下:
1 #include <stdio.h>
2 #include <string.h>
3 #define N 100
4 int a[N];
5 int main(void)
6 {
7 int n,t;
8 int i,j,m,x;
9 int T;
10 scanf("%d",&T);
11 while(T--)
12 {
13 scanf("%d",&n);
14 for(i=0;i<n;i++)
15 {
16 scanf("%d",&a[i]);
17 }
18
19 m = n;
20 for(i = 0;i < m;i++)
21 {
22 x = a[i];
23 n = m;
24 for(j = i + 1;j < n;j++)
25 {
26 if(a[j] == x)
27 {
28 for(int k = j;k < n-1;k++)
29 {
30 a[k] = a[k+1];
31 }
32 n--;
33 }
34 }
35 m = n;
36 }
37
38 for(i = 0;i < m;i++)
39 {
40 printf("%d ",a[i]);
41 }
42
43 n = 0;
44 printf("\n");
45 }
46 return 0;
47 }
来看下运行效果:
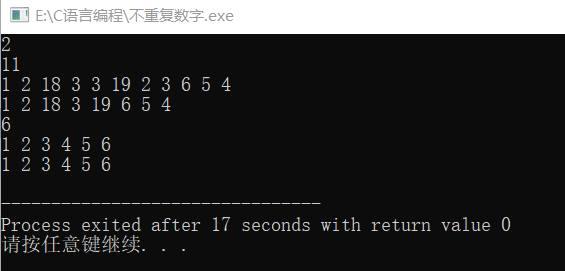
这样子就挺好的。
但是,如果仔细思考这个程序的算法思想,就会发现一个问题,那就是,这个程序里面,先不说输入的循环,光是完成这个去重操作的部分,就有三重循环了,这样一来,它的时间复杂度直接就到了O(n³).数据不多还好,万一去重的数据很多,毫无疑问,这种算法的效率是很低的。因此,我们可以考虑另外一种算法:
我们可以声明两个数组,其中一个用来存放要去重的数据,假设这个数组为a,另外一个数组用来存放去重后的数据,假设为b。我们可以在遍历未去重的数组时,先把第一个数据放进b数组里,然后在遍历a时,每碰到一个数据,我就先判断一下,看是否已经存在于b数组里了,如果已经存在,不管继续看下一个;如果不存在的话,就放进b数组。来看看代码:
1 #include <stdio.h>
2 #include <string.h>
3 #define N 50000
4 int a[N],b[N];
5 int main(void)
6 {
7 int n,t,count;
8 int i,j,m,x,k;
9 int T;
10 scanf("%d",&T);
11 while(T--)
12 {
13 scanf("%d",&n);
14 for(i=0;i<n;i++)
15 {
16 scanf("%d",&a[i]);
17 }
18
19 count = 1;
20 b[0] = a[0]; //先把第一个数据存在b数组里
21 for(i = 1;i < n;i++) //便利a数组
22 {
23 x = a[i]; //把第i个值取出来,便于以后依次与b数组里的数据比较
24 for(k = 0;;k++) //便利已存了数据的b数组,看是否有相同数字
25 {
26 if(x == b[k]) break; //只要有相等的马上跳出循环
27
28 if(k == count - 1) //如果把整个b数组遍历完了都没有相同数字
29 {
30 b[count++] = x; //就先把x赋给b数组,然后count再加加
31 break; //这一步是为了无论如何都要跳出循环,因为k不可能一直自增下去
32 }
33 }
34 }
35
36 for(k = 0;k < count;k++)
37 {
38 printf("%d ",b[k]);
39 }
40 printf("\n");
41
42 }
43 return 0;
44 }
(说明:以上代码中的count就是去重后数组的最终长度。)
这样一来,不考虑输入部分的循环,这种算法的时间复杂度就是O(n²).可以极大地提高效率。来看看运行效果:
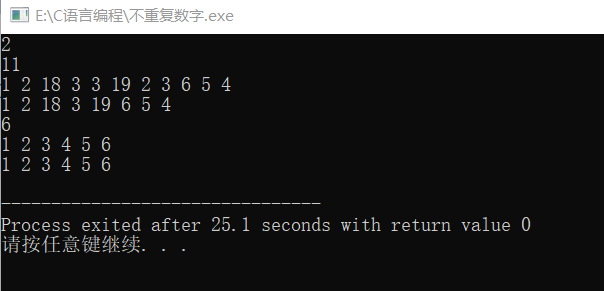

 浙公网安备 33010602011771号
浙公网安备 33010602011771号