



python——有一种线程池叫做自己写的线程池
python的线程一直被称为鸡肋,所以它也没有亲生的线程池,但是竟然被我发现了野生的线程池,简直不能更幸运~~~于是,我开始啃源码,实在是虐心,在啃源码的过程中,我简略的了解了python线程的相关知识,感觉还是很有趣的,于是写博客困难症患者一夜之间化身写作小能手,完成了一系列线程相关的博客,然后恍然发现,python的多线程是一个鸡肋哎。。。这里换来了同事们的白眼若干→_→。嘻嘻,但是鸡肋归鸡肋,看懂了一篇源码给我带来的收获和成就感还是不能小视,所以还是分享下~~~
别人的线程池
首先介绍别人写的线程池模块,野生threadpool,直接到pypi上去搜,或者pip安装,都可以get到。这里还是先贴上来:


1 # -*- coding: UTF-8 -*- 2 """Easy to use object-oriented thread pool framework. 3 4 A thread pool is an object that maintains a pool of worker threads to perform 5 time consuming operations in parallel. It assigns jobs to the threads 6 by putting them in a work request queue, where they are picked up by the 7 next available thread. This then performs the requested operation in the 8 background and puts the results in another queue. 9 10 The thread pool object can then collect the results from all threads from 11 this queue as soon as they become available or after all threads have 12 finished their work. It's also possible, to define callbacks to handle 13 each result as it comes in. 14 15 The basic concept and some code was taken from the book "Python in a Nutshell, 16 2nd edition" by Alex Martelli, O'Reilly 2006, ISBN 0-596-10046-9, from section 17 14.5 "Threaded Program Architecture". I wrapped the main program logic in the 18 ThreadPool class, added the WorkRequest class and the callback system and 19 tweaked the code here and there. Kudos also to Florent Aide for the exception 20 handling mechanism. 21 22 Basic usage:: 23 24 >>> pool = ThreadPool(poolsize) 25 >>> requests = makeRequests(some_callable, list_of_args, callback) 26 >>> [pool.putRequest(req) for req in requests] 27 >>> pool.wait() 28 29 See the end of the module code for a brief, annotated usage example. 30 31 Website : http://chrisarndt.de/projects/threadpool/ 32 33 """ 34 __docformat__ = "restructuredtext en" 35 36 __all__ = [ 37 'makeRequests', 38 'NoResultsPending', 39 'NoWorkersAvailable', 40 'ThreadPool', 41 'WorkRequest', 42 'WorkerThread' 43 ] 44 45 __author__ = "Christopher Arndt" 46 __version__ = '1.3.2' 47 __license__ = "MIT license" 48 49 50 # standard library modules 51 import sys 52 import threading 53 import traceback 54 55 try: 56 import Queue # Python 2 57 except ImportError: 58 import queue as Queue # Python 3 59 60 61 # exceptions 62 class NoResultsPending(Exception): 63 """All work requests have been processed.""" 64 pass 65 66 class NoWorkersAvailable(Exception): 67 """No worker threads available to process remaining requests.""" 68 pass 69 70 71 # internal module helper functions 72 def _handle_thread_exception(request, exc_info): 73 """Default exception handler callback function. 74 75 This just prints the exception info via ``traceback.print_exception``. 76 77 """ 78 traceback.print_exception(*exc_info) 79 80 81 # utility functions 82 def makeRequests(callable_, args_list, callback=None, 83 exc_callback=_handle_thread_exception): 84 """Create several work requests for same callable with different arguments. 85 86 Convenience function for creating several work requests for the same 87 callable where each invocation of the callable receives different values 88 for its arguments. 89 90 ``args_list`` contains the parameters for each invocation of callable. 91 Each item in ``args_list`` should be either a 2-item tuple of the list of 92 positional arguments and a dictionary of keyword arguments or a single, 93 non-tuple argument. 94 95 See docstring for ``WorkRequest`` for info on ``callback`` and 96 ``exc_callback``. 97 98 """ 99 requests = [] 100 for item in args_list: 101 if isinstance(item, tuple): 102 requests.append( 103 WorkRequest(callable_, item[0], item[1], callback=callback, 104 exc_callback=exc_callback) 105 ) 106 else: 107 requests.append( 108 WorkRequest(callable_, [item], None, callback=callback, 109 exc_callback=exc_callback) 110 ) 111 return requests 112 113 114 # classes 115 class WorkerThread(threading.Thread): 116 """Background thread connected to the requests/results queues. 117 118 A worker thread sits in the background and picks up work requests from 119 one queue and puts the results in another until it is dismissed. 120 121 """ 122 123 def __init__(self, requests_queue, results_queue, poll_timeout=5, **kwds): 124 """Set up thread in daemonic mode and start it immediatedly. 125 126 ``requests_queue`` and ``results_queue`` are instances of 127 ``Queue.Queue`` passed by the ``ThreadPool`` class when it creates a 128 new worker thread. 129 130 """ 131 threading.Thread.__init__(self, **kwds) 132 self.setDaemon(1) 133 self._requests_queue = requests_queue 134 self._results_queue = results_queue 135 self._poll_timeout = poll_timeout 136 self._dismissed = threading.Event() 137 self.start() 138 139 def run(self): 140 """Repeatedly process the job queue until told to exit.""" 141 while True: 142 if self._dismissed.isSet(): 143 # we are dismissed, break out of loop 144 break 145 # get next work request. If we don't get a new request from the 146 # queue after self._poll_timout seconds, we jump to the start of 147 # the while loop again, to give the thread a chance to exit. 148 try: 149 request = self._requests_queue.get(True, self._poll_timeout) 150 except Queue.Empty: 151 continue 152 else: 153 if self._dismissed.isSet(): 154 155 # we are dismissed, put back request in queue and exit loop 156 self._requests_queue.put(request) 157 break 158 try: 159 result = request.callable(*request.args, **request.kwds) 160 self._results_queue.put((request, result)) 161 except: 162 request.exception = True 163 self._results_queue.put((request, sys.exc_info())) 164 165 def dismiss(self): 166 print '**********dismiss***********' 167 """Sets a flag to tell the thread to exit when done with current job. 168 """ 169 self._dismissed.set() 170 171 172 class WorkRequest: 173 """A request to execute a callable for putting in the request queue later. 174 175 See the module function ``makeRequests`` for the common case 176 where you want to build several ``WorkRequest`` objects for the same 177 callable but with different arguments for each call. 178 179 """ 180 181 def __init__(self, callable_, args=None, kwds=None, requestID=None, 182 callback=None, exc_callback=_handle_thread_exception): 183 """Create a work request for a callable and attach callbacks. 184 185 A work request consists of the a callable to be executed by a 186 worker thread, a list of positional arguments, a dictionary 187 of keyword arguments. 188 189 A ``callback`` function can be specified, that is called when the 190 results of the request are picked up from the result queue. It must 191 accept two anonymous arguments, the ``WorkRequest`` object and the 192 results of the callable, in that order. If you want to pass additional 193 information to the callback, just stick it on the request object. 194 195 You can also give custom callback for when an exception occurs with 196 the ``exc_callback`` keyword parameter. It should also accept two 197 anonymous arguments, the ``WorkRequest`` and a tuple with the exception 198 details as returned by ``sys.exc_info()``. The default implementation 199 of this callback just prints the exception info via 200 ``traceback.print_exception``. If you want no exception handler 201 callback, just pass in ``None``. 202 203 ``requestID``, if given, must be hashable since it is used by 204 ``ThreadPool`` object to store the results of that work request in a 205 dictionary. It defaults to the return value of ``id(self)``. 206 207 """ 208 #__init__( callable_, args=None, kwds=None, callback=None, exc_callback=_handle_thread_exception) 209 #WorkRequest(callable_, item[0], item[1], callback=callback,exc_callback=exc_callback) 210 if requestID is None: 211 self.requestID = id(self) 212 else: 213 try: 214 self.requestID = hash(requestID) 215 except TypeError: 216 raise TypeError("requestID must be hashable.") 217 self.exception = False 218 self.callback = callback 219 self.exc_callback = exc_callback 220 self.callable = callable_ 221 self.args = args or [] 222 self.kwds = kwds or {} 223 224 def __str__(self): 225 return "<WorkRequest id=%s args=%r kwargs=%r exception=%s>" % \ 226 (self.requestID, self.args, self.kwds, self.exception) 227 228 class ThreadPool: 229 """A thread pool, distributing work requests and collecting results. 230 231 See the module docstring for more information. 232 233 """ 234 235 def __init__(self, num_workers, q_size=0, resq_size=0, poll_timeout=5): 236 """Set up the thread pool and start num_workers worker threads. 237 238 ``num_workers`` is the number of worker threads to start initially. 239 240 If ``q_size > 0`` the size of the work *request queue* is limited and 241 the thread pool blocks when the queue is full and it tries to put 242 more work requests in it (see ``putRequest`` method), unless you also 243 use a positive ``timeout`` value for ``putRequest``. 244 245 If ``resq_size > 0`` the size of the *results queue* is limited and the 246 worker threads will block when the queue is full and they try to put 247 new results in it. 248 249 .. warning: 250 If you set both ``q_size`` and ``resq_size`` to ``!= 0`` there is 251 the possibilty of a deadlock, when the results queue is not pulled 252 regularly and too many jobs are put in the work requests queue. 253 To prevent this, always set ``timeout > 0`` when calling 254 ``ThreadPool.putRequest()`` and catch ``Queue.Full`` exceptions. 255 256 """ 257 self._requests_queue = Queue.Queue(q_size) 258 self._results_queue = Queue.Queue(resq_size) 259 self.workers = [] 260 self.dismissedWorkers = [] 261 self.workRequests = {} 262 self.createWorkers(num_workers, poll_timeout) 263 264 def createWorkers(self, num_workers, poll_timeout=5): 265 """Add num_workers worker threads to the pool. 266 267 ``poll_timout`` sets the interval in seconds (int or float) for how 268 ofte threads should check whether they are dismissed, while waiting for 269 requests. 270 271 """ 272 for i in range(num_workers): 273 self.workers.append(WorkerThread(self._requests_queue, 274 self._results_queue, poll_timeout=poll_timeout)) 275 276 def dismissWorkers(self, num_workers, do_join=False): 277 """Tell num_workers worker threads to quit after their current task.""" 278 dismiss_list = [] 279 for i in range(min(num_workers, len(self.workers))): 280 worker = self.workers.pop() 281 worker.dismiss() 282 dismiss_list.append(worker) 283 284 if do_join: 285 for worker in dismiss_list: 286 worker.join() 287 else: 288 self.dismissedWorkers.extend(dismiss_list) 289 290 def joinAllDismissedWorkers(self): 291 """Perform Thread.join() on all worker threads that have been dismissed. 292 """ 293 for worker in self.dismissedWorkers: 294 worker.join() 295 self.dismissedWorkers = [] 296 297 def putRequest(self, request, block=True, timeout=None): 298 """Put work request into work queue and save its id for later.""" 299 assert isinstance(request, WorkRequest) 300 # don't reuse old work requests 301 assert not getattr(request, 'exception', None) 302 import time 303 self._requests_queue.put(request, block, timeout) 304 self.workRequests[request.requestID] = request 305 306 def poll(self, block=False): 307 """Process any new results in the queue.""" 308 while True: 309 # still results pending? 310 if not self.workRequests: 311 raise NoResultsPending 312 # are there still workers to process remaining requests? 313 elif block and not self.workers: 314 raise NoWorkersAvailable 315 try: 316 # get back next results 317 318 request, result = self._results_queue.get(block=block) 319 320 # has an exception occured? 321 if request.exception and request.exc_callback: 322 323 request.exc_callback(request, result) 324 325 # hand results to callback, if any 326 if request.callback and not \ 327 (request.exception and request.exc_callback): 328 request.callback(request, result) 329 del self.workRequests[request.requestID] 330 except Queue.Empty: 331 break 332 333 def wait(self): 334 """Wait for results, blocking until all have arrived.""" 335 while 1: 336 try: 337 self.poll(True) 338 except NoResultsPending: 339 break 340 341 342 ################ 343 # USAGE EXAMPLE 344 ################ 345 346 if __name__ == '__main__': 347 import random 348 import time 349 350 # the work the threads will have to do (rather trivial in our example) 351 def do_something(data): 352 time.sleep(random.randint(1,5)) 353 result = round(random.random() * data, 5) 354 # just to show off, we throw an exception once in a while 355 if result > 5: 356 raise RuntimeError("Something extraordinary happened!") 357 return result 358 359 # this will be called each time a result is available 360 def print_result(request, result): 361 print("**** Result from request #%s: %r" % (request.requestID, result)) 362 363 # this will be called when an exception occurs within a thread 364 # this example exception handler does little more than the default handler 365 def handle_exception(request, exc_info): 366 if not isinstance(exc_info, tuple): 367 # Something is seriously wrong... 368 print(request) 369 print(exc_info) 370 raise SystemExit 371 print("**** Exception occured in request #%s: %s" % \ 372 (request.requestID, exc_info)) 373 374 # assemble the arguments for each job to a list... 375 data = [random.randint(1,10) for i in range(20)] 376 # ... and build a WorkRequest object for each item in data 377 requests = makeRequests(do_something, data, print_result, handle_exception) 378 # to use the default exception handler, uncomment next line and comment out 379 # the preceding one. 380 #requests = makeRequests(do_something, data, print_result) 381 382 # or the other form of args_lists accepted by makeRequests: ((,), {}) 383 data = [((random.randint(1,10),), {}) for i in range(20)] 384 requests.extend( 385 makeRequests(do_something, data, print_result, handle_exception) 386 #makeRequests(do_something, data, print_result) 387 # to use the default exception handler, uncomment next line and comment 388 # out the preceding one. 389 ) 390 391 # we create a pool of 3 worker threads 392 print("Creating thread pool with 3 worker threads.") 393 main = ThreadPool(3) 394 395 # then we put the work requests in the queue... 396 for req in requests: 397 main.putRequest(req) 398 print("Work request #%s added." % req.requestID) 399 # or shorter: 400 # [main.putRequest(req) for req in requests] 401 402 # ...and wait for the results to arrive in the result queue 403 # by using ThreadPool.wait(). This would block until results for 404 # all work requests have arrived: 405 # main.wait() 406 407 # instead we can poll for results while doing something else: 408 i = 0 409 while True: 410 try: 411 time.sleep(0.5) 412 main.poll() 413 print("Main thread working...") 414 print("(active worker threads: %i)" % (threading.activeCount()-1, )) 415 if i == 10: 416 417 main.createWorkers(3) 418 if i == 20: 419 420 main.dismissWorkers(2) 421 i += 1 422 except KeyboardInterrupt: 423 print("**** Interrupted!") 424 break 425 except NoResultsPending: 426 print("**** No pending results.") 427 break 428 if main.dismissedWorkers: 429 print("Joining all dismissed worker threads...") 430 main.joinAllDismissedWorkers()
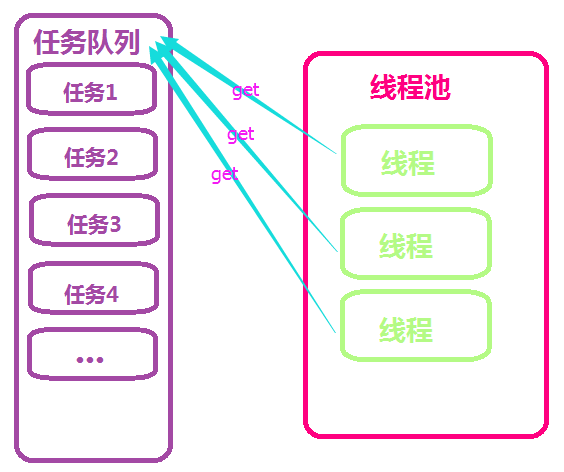
首先我们来看这个线程池的大致原理。在初始化中,它会根据我们的需求,启动相应数量的线程,这些线程是初始化好的,一直到程序结束,不会停止,它们从任务队列中获取任务,在没有任务的时候就阻塞,他们当我们有任务的时候,对任务进行初始化,放入任务队列,拿到任务的线程结束了自己的阻塞人生,欢欢喜喜的拿回去执行,并在执行完毕之后,将结果放入结果队列,继续到任务队列中取任务,如果没有任务就进入阻塞状态。看了一整天的源码竟让我三两句话解释清楚了,我到底是表达能力强还是理解能力差!!!我想静静~~~附上类图如下: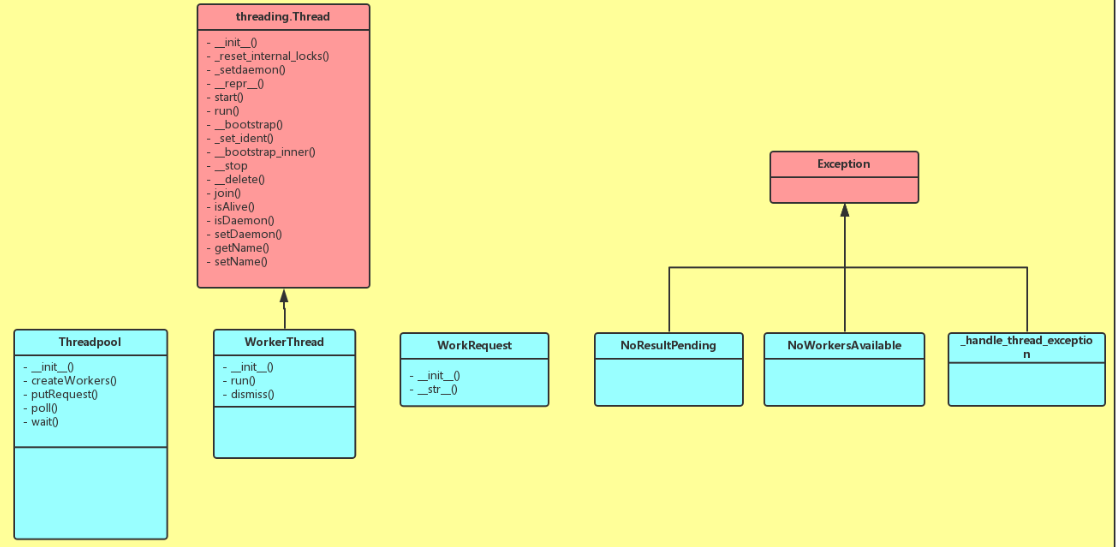
我的线程池
下面就来介绍我写的线程池了,上面的线程池有一个问题,那就是一开始创建了多少个线程,这些线程就一直存在内存中,即使没有工作,也不会销毁。于是我有了一个想法,就像其他语言中的线程池一样,写一个拥有最大线程数和最小线程数限制的线程池。
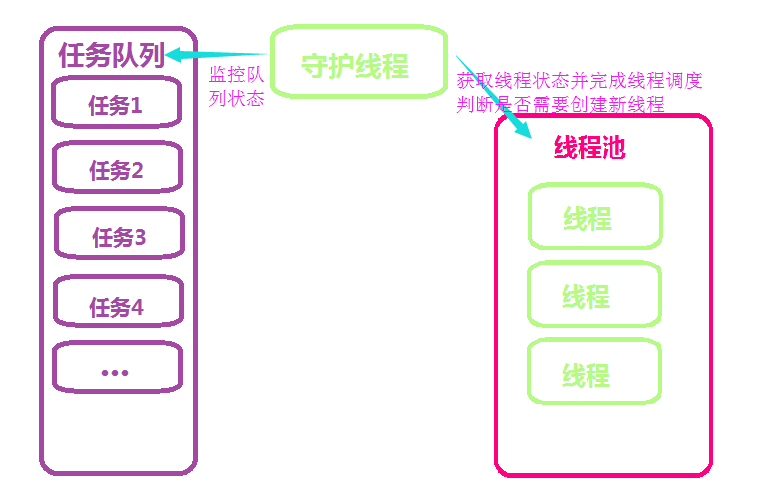
程序启动之初只将最小线程数的线程放在池中,并将线程设置为阻塞状态,用守护线程来查看任务队列,当任务队列中有任务时,则停止线程的阻塞状态,让它们到队列中去获取任务,执行,如果需要返回结果,则将结果返回结果队列。当任务很多,线程池中没有闲置的线程且当前线程数小于线程池最大线程数时,将创建新的线程(这里使用了yield)来接收新的任务,线程执行完毕后,则回到阻塞状态,长期闲置的线程会自动销毁,但池中线程永远不小于在最小线程数。当最小线程数和最大线程数相等的时候,内部就基本和野生线程相同啦~~~
在参考了野生threadpool模块之后,我也学着继承原生的threading.Thread类,并重写了run方法,了解了给一个线程注入新方法的过程。并用到了Event方法和yield。如果不要返回值的话,我想效率还是很高的。尽管我在返回值方面还做了优化,哎~~~
银角大王的线程池:
1 from Queue import Queue 2 import contextlib 3 import threading 4 5 WorkerStop = object() 6 7 8 class ThreadPool: 9 10 workers = 0 11 12 threadFactory = threading.Thread 13 currentThread = staticmethod(threading.currentThread) 14 15 def __init__(self, maxthreads=20, name=None): 16 17 self.q = Queue(0) 18 self.max = maxthreads 19 self.name = name 20 self.waiters = [] 21 self.working = [] 22 23 def start(self): 24 needsiZe = self.q.qsize() 25 while self.workers < min(self.max, needSize): 26 self.startAWorker() 27 28 def startAWorker(self): 29 self.workers += 1 30 name = "PoolThread-%s-%s" % (self.name or id(self), self.workers) 31 newThread = self.threadFactory(target=self._worker, name=name) 32 newThread.start() 33 34 def callInThread(self, func, *args, **kw): 35 self.callInThreadWithCallback(None, func, *args, **kw) 36 37 def callInThreadWithCallback(self, onResult, func, *args, **kw): 38 o = (func, args, kw, onResult) 39 self.q.put(o) 40 41 42 @contextlib.contextmanager 43 def _workerState(self, stateList, workerThread): 44 stateList.append(workerThread) 45 try: 46 yield 47 finally: 48 stateList.remove(workerThread) 49 50 def _worker(self): 51 ct = self.currentThread() 52 o = self.q.get() 53 while o is not WorkerStop: 54 with self._workerState(self.working, ct): 55 function, args, kwargs, onResult = o 56 del o 57 try: 58 result = function(*args, **kwargs) 59 success = True 60 except: 61 success = False 62 if onResult is None: 63 pass 64 65 else: 66 pass 67 68 del function, args, kwargs 69 70 if onResult is not None: 71 try: 72 onResult(success, result) 73 except: 74 #context.call(ctx, log.err) 75 pass 76 77 del onResult, result 78 79 with self._workerState(self.waiters, ct): 80 o = self.q.get() 81 82 def stop(self): 83 while self.workers: 84 self.q.put(WorkerStop) 85 self.workers -= 1 86
1 def show(arg): 2 import time 3 time.sleep(1) 4 print arg 5 6 7 pool = ThreadPool(20) 8 9 for i in range(500): 10 pool.callInThread(show, i) 11 12 pool.start() 13 pool.stop()
这里安利下我男神,哈哈哈~武sir的方法和上面的例子中不同的是,自定义了线程的start方法,当启动线程的时候才初始化线程池,并根据线程池定义的数量和任务数量取min,而不是先开启定义的线程数等待命令,在一定程度上避免了空线程对内存的消耗。
with知识点
这里要介绍一个知识点。我们在做上下文管理的时候,用到过with。
我们如何自定义一个with方法呢?
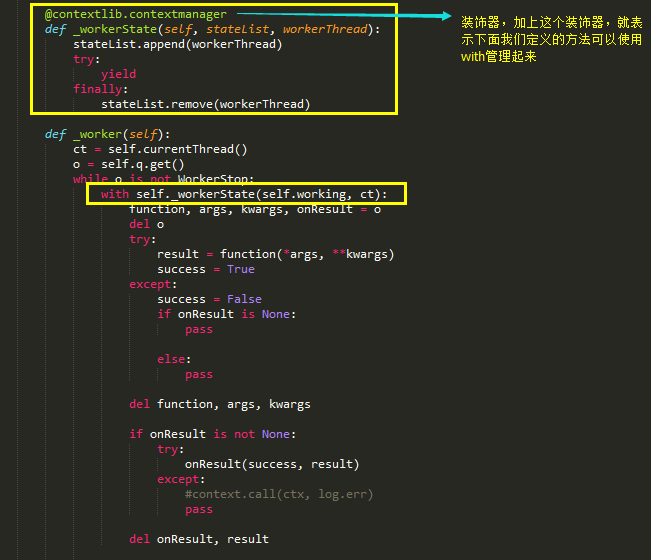
如此一来,我们便可以实现对线程状态的监控和管理了。将正在运行中的线程,加入到一个列表中,并使用yield返回,当线程执行完之后,再从这个列表中移除,就可以知道哪些线程是正在运行的啦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号