
一、time模块
1、几种时间形式的转换
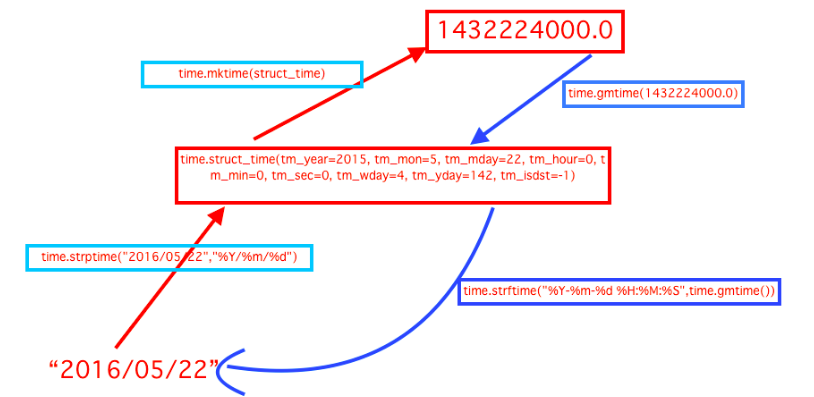
2、struct_time转换成时间戳
#日期字符串 转成 时间戳
string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式
print(string_2_struct)
# time.struct_time(tm_year=2016, tm_mon=5, tm_mday=22, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=143, tm_isdst=-1) #string_2_struct
struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳
print(struct_2_stamp)
# 1463846400.0 #struct_2_stamp
3、时间戳转换成struct_time
#将时间戳转为字符串格式
# print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式
# print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式
4、时间加减
import datetime print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925 print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19 print(datetime.datetime.now() ) print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 c_time = datetime.datetime.now() print(c_time.replace(minute=3,hour=2)) #时间替换
二、random模块


>>> import random >>> random.random() # 0~1 随机浮点数 0.6990063739837862 >>> random.randint(1,7) #随机整数1~7 5 >>> random.randrange(1,7) #随机整数,不包括7 4 >>> random.choice('hello world') #获取一个随机元素 'l' >>> random.choice(['1','2','3',]) '2' >>> random.sample([1,2,3,4,5],3) [1, 2, 4] random.sample的函数原型为:random.sample(sequence, k),从指定 序列中随机获取指定长度的片
应用:随机验证码:
import random def v_code(): code = "" for i in range(4): num = random.randint(0,9) #随机选择0~9 A1Z1 = chr(random.randint(65,90)) #随机选择A~Z a1z1 = chr(random.randint(97,122)) #随机选择a~z add = random.choice([num,A1Z1,a1z1]) #随机选择其中一个 code = "".join([code,str(add)]) #拼接一次选到的元素 return code #返回验证码# print(v_code()) 结果: 5adc
三、OS模块
- 提供对操作系统进行调用的接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
四、SYS模块
1 sys.argv 命令行参数List,第一个元素是程序本身路径 2 sys.exit(n) 退出程序,正常退出时exit(0) 3 sys.version 获取Python解释程序的版本信息 4 sys.maxint 最大的Int值 5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 6 sys.platform 返回操作系统平台名称 7 sys.stdout.write('please:') 8 val = sys.stdin.readline()[:-1]
五、json & pickle模块
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
dump()函数接受一个文件句柄和一个数据对象作为参数,把数据对象以特定的格式保存 到给定的文件中。当我们使用load()函数从文件中取出已保存的对象时,pickle知道如何恢复这些对象到它们本来的格式。
dumps()函数执行和dump() 函数相同的序列化。取代接受流对象并将序列化后的数据保存到磁盘文件,这个函数简单的返回序列化的数据。
loads()函数执行和load() 函数一样的反序列化。取代接受一个流对象并去文件读取序列化后的数据,它接受包含序列化后的数据的str对象, 直接返回的对象。
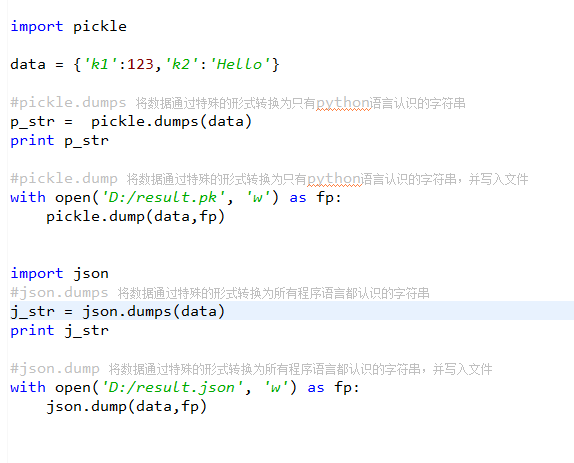
1 import json 2 3 dic={'name':'alvin','age':23,'sex':'male'} 4 print(type(dic))#<class 'dict'> 5 6 j=json.dumps(dic) 7 print(type(j))#<class 'str'> 8 9 10 f=open('序列化对象','w') 11 f.write(j) #-------------------等价于json.dump(dic,f) 12 f.close() 13 #-----------------------------反序列化<br> 14 import json 15 f=open('序列化对象') 16 data=json.loads(f.read())# 等价于data=json.load(f) import json #dct="{'1':111}"#json 不认单引号 #dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1} dct='{"1":"111"}' print(json.loads(dct)) #conclusion: # 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
1 import json 2 3 # 序列化 4 info = {'name':'derek','age':'22'} 5 6 with open('test','w') as f: 7 f.write(json.dumps(info)) 8 9 # 反序列化 10 with open('test','r') as f: 11 info = json.loads(f.read()) 12 print(info)
# pickle序列号只能用于python
1 import pickle 2 3 dic={'name':'alvin','age':23,'sex':'male'} 4 5 print(type(dic))#<class 'dict'> 6 7 j=pickle.dumps(dic) 8 print(type(j))#<class 'bytes'> 9 10 11 f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes' 12 f.write(j) #-------------------等价于pickle.dump(dic,f) 13 14 f.close() 15 #-------------------------反序列化 16 import pickle 17 f=open('序列化对象_pickle','rb') 18 19 data=pickle.loads(f.read())# 等价于data=pickle.load(f) 20 21 22 print(data['age'])
六、hashlib模块
hash:一种算法 ,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法 三个特点: 1.内容相同则hash运算结果相同,内容稍微改变则hash值则变 2.不可逆推 3.相同算法:无论校验多长的数据,得到的哈希值长度固定。
注意:把一段很长的数据update多次,与一次update这段长数据,得到的结果一样。但是update多次为校验大文件提供了可能。
import hashlib m=hashlib.md5() # m=hashlib.sha256() m.update('hello'.encode('utf8')) print(m.hexdigest()) #5d41402abc4b2a76b9719d911017c592 m.update('alvin'.encode('utf8')) print(m.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af m2=hashlib.md5() m2.update('helloalvin'.encode('utf8'))
print(m2.digest) #2进制格式hash print(m2.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af #16进制格式hash
1 import hashlib 2 3 # ######## md5 ######## 4 5 hash = hashlib.md5() 6 hash.update('admin') 7 print(hash.hexdigest()) 8 9 # ######## sha1 ######## 10 11 hash = hashlib.sha1() 12 hash.update('admin') 13 print(hash.hexdigest()) 14 15 # ######## sha256 ######## 16 17 hash = hashlib.sha256() 18 hash.update('admin') 19 print(hash.hexdigest()) 20 21 22 # ######## sha384 ######## 23 24 hash = hashlib.sha384() 25 hash.update('admin') 26 print(hash.hexdigest()) 27 28 # ######## sha512 ######## 29 30 hash = hashlib.sha512() 31 hash.update('admin') 32 print(hash.hexdigest())
--python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
散列消息鉴别码,简称HMAC,是一种基于消息鉴别码MAC(Message Authentication Code)的鉴别机制。使用HMAC时,消息通讯的双方,通过验证消息中加入的鉴别 密钥K来鉴别消息的真伪;
一般用于网络通信中消息加密,前提是双方先要约定好key,就像接头暗号一样,然后消息发送把用key把消息加密,接收方用key + 消息明文再加密,拿加密后的值 跟 发送者的相对比是否相等,这样就能验证消息的真实性,及发送者的合法性了。
1 import hmac 2 h = hmac.new(b'天王盖地虎', b'宝塔镇河妖') 3 print h.hexdigest()
七、re模块
1 '.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 2 '^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE) 3 '$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以 4 '*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a'] 5 '+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb'] 6 '?' 匹配前一个字符1次或0次 7 '{m}' 匹配前一个字符m次 8 '{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb'] 9 '|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC' 10 '(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c 11 12 13 '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的 14 '\Z' 匹配字符结尾,同$ 15 '\d' 匹配数字0-9 16 '\D' 匹配非数字 17 '\w' 匹配[A-Za-z0-9] 18 '\W' 匹配非[A-Za-z0-9] 19 's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' 20 21 '(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}
# ===========================re模块提供的方法介绍=========================== import re #1 print(re.findall('e','alex make love') ) #['e', 'e', 'e'],返回所有满足匹配条件的结果,放在列表里 #2 print(re.search('e','alex make love').group()) #e,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 #3 print(re.match('e','alex make love')) #None,同search,不过在字符串开始处进行匹配,完全可以用search+^代替match #4 print(re.split('[ab]','abcd')) #['', '', 'cd'],先按'a'分割得到''和'bcd',再对''和'bcd'分别按'b'分割 #5 print('===>',re.sub('a','A','alex make love')) #===> Alex mAke love,不指定n,默认替换所有 print('===>',re.sub('a','A','alex make love',1)) #===> Alex make love print('===>',re.sub('a','A','alex make love',2)) #===> Alex mAke love print('===>',re.sub('^(\w+)(.*?\s)(\w+)(.*?\s)(\w+)(.*?)$',r'\5\2\3\4\1','alex make love')) #===> love make alex print('===>',re.subn('a','A','alex make love')) #===> ('Alex mAke love', 2),结果带有总共替换的个数 #6 obj=re.compile('\d{2}') print(obj.search('abc123eeee').group()) #12 print(obj.findall('abc123eeee')) #['12'],重用了obj
# 最常用的匹配语法 re.match 从头开始匹配 re.search 匹配包含 re.findall 把所有匹配到的字符放到以列表中的元素返回 re.splitall 以匹配到的字符当做列表分隔符 re.sub 匹配字符并替换
未来的你,会感谢现在努力的你!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号