Spark入门到精通--(第十节)环境搭建(ZooKeeper和kafka搭建)
上一节搭建完了Hive,这一节我们来搭建ZooKeeper,主要是后面的kafka需要运行在上面。
ZooKeeper下载和安装
下载ZooKeeper 3.4.5软件包 ,可以在百度网盘进行下载。链接: http://pan.baidu.com/s/1gePE9O3 密码: unmt。
,可以在百度网盘进行下载。链接: http://pan.baidu.com/s/1gePE9O3 密码: unmt。
下载完用Xftp上传到spark1服务器,我是放在/home/software目录下。
[root@spark1 lib]# cd /home/software/ [root@spark1 software]# tar -zxf zookeeper-3.4.5.tar.gz //解压 [root@spark1 software]# mv zookeeper-3.4.5 /usr/lib/zookeeper //重命名并移到/usr/lib目录下 [root@spark1 software]# cd /usr/lib
设置ZooKeeper环境变量。
[root@spark1 lib]# vi ~/.bashrc //配置环境变量 //添加变量,别忘了Path的变量也要修改 export ZOOKEEPER_HOME=/usr/lib/zookeeper export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin //加上ZooKeeper的路径

保存退出,是文件生效。
[root@spark1 lib]# source ~/.bashrc
完成之后我们开始配置ZooKeeper的配置文件。
- 修改zoo_sample.cfg文件,并且重命名为zoo.cfg。
[root@spark1 lib]# cd zookeeper/conf/ [root@spark1 conf]# mv zoo_sample.cfg zoo.cfg [root@spark1 conf]# vi zoo.cfg //修改dataDir dataDir=/usr/lib/zookeeper/data //添加(最少配置三个节点) server.0=spark1:2888:3888 server.1=spark2:2888:3888 server.2=spark3:2888:3888
修改完成保存退出。
然后我们去/usr/lib/zookeeper目录下创建data文件夹,设置标示。
[root@spark1 conf]# cd .. [root@spark1 zookeeper]# mkdir data [root@spark1 zookeeper]# cd data //创建一个myid文件 [root@spark1 data]# vi myid //添加0 0
修改完成保存退出。
- 将配置文件拷贝到spark2和spark3上,同时myid文件里分别设置1和2.
[root@spark1 data]# cd /usr/lib //拷贝到spark2上 [root@spark1 lib]# scp -r zookeeper root@spark2:/usr/lib/ [root@spark2 lib]# scp ~/.bashrc root@spark2:~/ //拷贝过去别忘了在spark2上执行source ~/.bashrc命令,使生效
完成后同样在spark3上也拷贝一份。(分别将myid文件里设置为1和2)
- 启动ZooKeeper集群
在三台服务器上分别启动,并检查ZooKeeper状态。
[root@spark1 lib]# zookeeper/bin/zkServer.sh start
三台都启动完成后执行查看启动情况。
[root@spark1 lib]# zookeeper/bin/zkServer.sh status JMX enabled by default Using config: /usr/lib/zookeeper/bin/../conf/zoo.cfg Mode: leader //关闭 zookeeper/bin/zkServer.sh stop
//重启 zookeeper/bin/zkServer.sh restart
第一台出现Mode:leader,另外2台是Mode:follower,代表OK,ZooKeeper集群完成!
Scala安装
由于之前在第二节已经讲过Scala安装的过程了,现在只要把spark2和spark3都安装上Scala就好了,就不多说了。
kafka安装
下载kafka 2.9.2软件包 ,可以在百度网盘进行下载。链接: http://pan.baidu.com/s/1gePE9O3 密码: unmt。
,可以在百度网盘进行下载。链接: http://pan.baidu.com/s/1gePE9O3 密码: unmt。
下载完用Xftp上传到spark1服务器,我是放在/home/software目录下。
[root@spark1 lib]# cd /home/software/ [root@spark1 software]# tar -zxf kafka_2.9.2-0.8.1.tgz [root@spark1 software]# mv kafka_2.9.2-0.8.1 /usr/lib/kafka [root@spark1 software]# cd /usr/lib
- 配置kafka
修改配置文件 server.properties文件。
[root@spark1 lib]# vi kafka/config/server.properties //broker.id是唯一的,默认从0开始 broker.id=0 //修改zookeeper.connect zookeeper.connect=spark1:2181,spark2:2181,spark3:2181
slf4j安装
下载slf4j 1.7.6软件包 ,放到/home/software目录下。
,放到/home/software目录下。
[root@spark1 software]# unzip slf4j-1.7.6.zip //解压 //我们把slf4j-1.7.6/slf4j-nop-1.7.6.jar拷贝到kafka的lib下 [root@spark1 software]# cp slf4j-1.7.6/slf4j-nop-1.7.6.jar /usr/lib/kafka/libs/
完成后我们在spark1上的kafka安装完成,然后我们继续把kafka拷贝到spark2和spark3上。(分别将kafka/conf/下的server.properties文件里broker.id设置为1和2)
[root@spark1 lib]# scp -r kafka root@spark2:/usr/lib/
之后可能有些人kafka的集群和JVM不匹配,需要在三台服务器上做个配置。
[root@spark1 kafka]# vi bin/kafka-run-class.sh //在配置文件中把-XX:+UseCompressedOops 给去掉
- 完成之后我们分别在三台服务器上启动kafka集群
[root@spark1 lib]# cd kafka/ //要在kafka目录下 //启动 [root@spark1 kafka]# nohup bin/kafka-server-start.sh config/server.properties &
[root@spark1 kafka]# jps
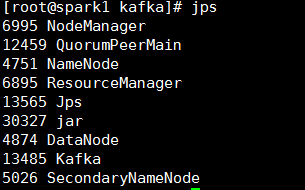
至此kafka配置完成。有问题可以看:http://www.aboutyun.com/thread-12847-1-1.html
kafka测试
//我们创建一个topic [root@spark1 kafka]# bin/kafka-topics.sh --zookeeper spark1:2181,spark2:2181,spark3:2181 --topic TestTopic --replication-factor 1 --partitions 1 --create //创建producer [root@spark1 kafka]# bin/kafka-console-producer.sh --broker-list 10.168.21.169:9092,10.162.59.47:9092,10.168.42.26:9092 --topic TestTopic //创建comsumer [root@spark1 kafka]# bin/kafka-console-consumer.sh --zookeeper 10.168.21.169:2181,10.162.59.47:2181,10.168.42.26:2181 --topic TestTopic --from-beginning


这样我们生产者-消费者的测试hello world没问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号