学习日记2.17
学习笔记(2.17)
1.KNN水果分类实践
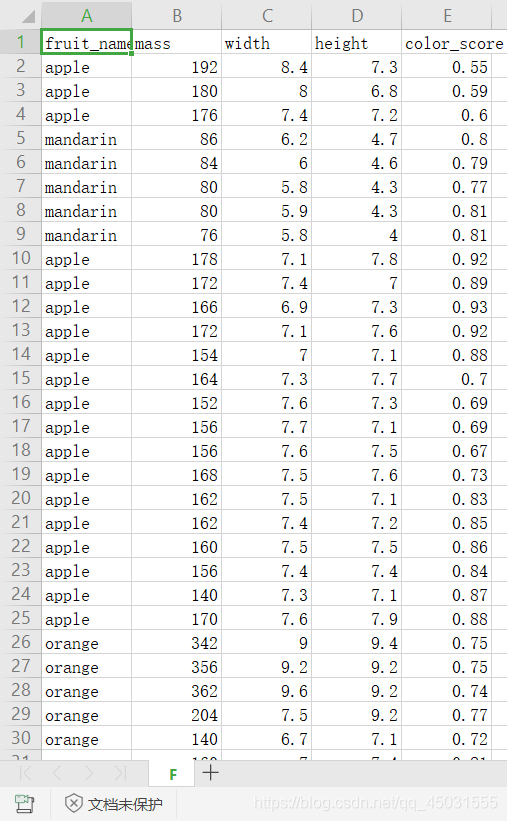
1.data=pd.read_csv('E:\python-ml\F.csv')
import pandas as pd
pd.read_csv可以读取CSV文件
更多的参数可查https://blog.csdn.net/brucewong0516/article/details/79092579
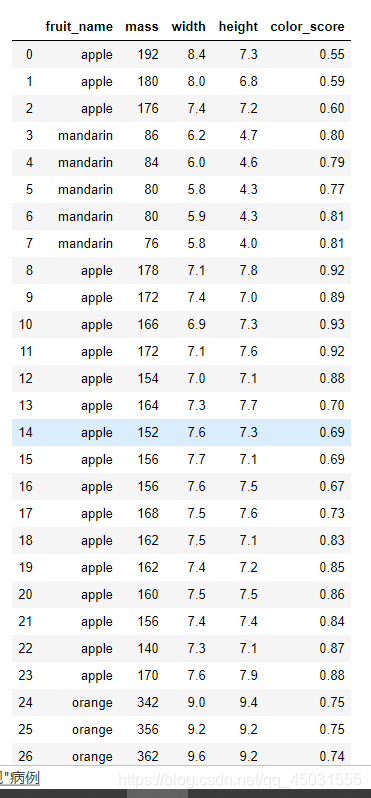
2.labelencoder=LabelEncoder()
data.iloc[:,0]=labelencoder.fit_transform(data.iloc[:,0])
这个是机器学习中的监督学习标签编码,把一些复杂的标签数字化,方便处理
A.data.iloc 是从DataFrame中筛选数据可以根据行和列来进行筛选
B.使用 loc 从DataFrame中筛选数据是根据列头的标签来选择,在坐标轴上挑选不同的列头以获取希望的数据
C.使用 ix 进行选择
现在pandas官方已经不推荐使用 ix 进行选择了,并且将会在 0.20.1版本从Pandas中丢弃
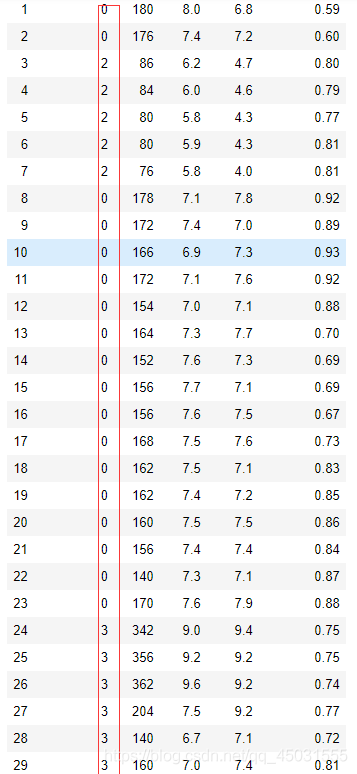
这就是上面标签从小到大对应的数字

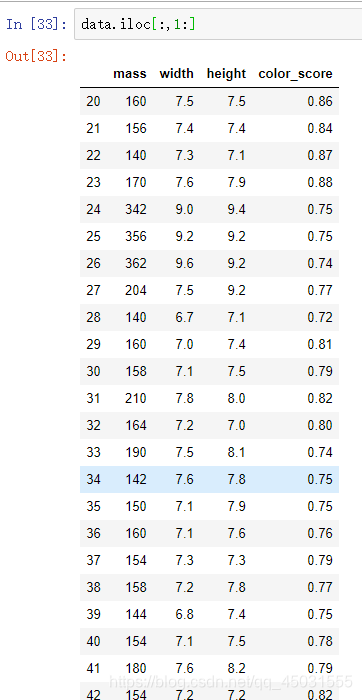
3.data.iloc[:,1:]这个语法再一次困扰着我
从第一行到最后一行提取 从第二行开始的所有列
给我的启发就是下次遇到这样的就去 打印出来data.iloc[:,1:]
4. knn=KNeighborsClassifier(i)
KNeighborsClassifier又称K最近邻,是一种经典的模式识别分类方法。sklearn库中的该分类器有以下参数:
from sklearn.neighbors import KNeighborsClassifier;
model = KNeighborsClassifier(
n_neighbors=5,
weights=’uniform’,
algorithm=’auto’,
leaf_size=30,
p=2,
metric=’minkowski’,
metric_params=None,
n_jobs=None,
**kwargs=object);
这里应该用的只是第一个参数, 那几个最近的就分类为一样的不断的调整,在for循环中不断调整K值再把当前K值对应的模型的精确的存放到一个列表里,我们可以挑选出一个精确度最高的K值
5.x_train,x_test,y_train,y_test=train_test_split(data.iloc[:,1:],data.iloc[:,0],test_size=0.3,stratify=data.iloc[:,0],random_state=20
中的参数 stratifysh 是按照中的比列切分
6.整个过程其实不是很复杂,首先获取数据,把数据的标签和特征分开,把数据集中的数据切分为训练集和测试集,用循环的方式找到一个最优的K值放入KNN模型中得到最好分类精确度。
BP神经网络手写数字识别
1.from sklearn.cross_validation import train_test_split
当我写完这行运行时,出现了报错

经过百度发现:
这个cross_validatio这个包早就不在使用了,划分到了model_selection这个包中。解决方法:
from sklearn.model_selection import train_test_split
2.输入数据归一化
用X减掉最小值然后再除以最大值,X矩阵里所有数据减掉最小值再除以最大值,就可以把X里的所有数据都变成0--1之间的数据。为什么要归一化呢?假如X很大有几个亿,一般权值初始化都是零点几,权值和X相乘,把盛出来的几千万带入激活函数,激活函数是一个S形的曲线,当X很大的时候,X无限趋近与1,在X很大时导数无限趋近于0,是没有梯度的,权值的改变是和梯度有关系的,是没有办法进行学习的。
#输入数据归一化
X-=x.min()
X/=X.max()
3.标签二值化
在手写数字识别中 图片1的标签就是1,4的标签就是4,但是这并不符合神经网络的风格,输出层的神经元都是0和1来取值,
如果说一张图片上是0,那么他的标签也是0,我们应该这样表示
0>1000000000
1>0100000000
2>0010000000
3>0001000000
4>0000100000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号