python爬虫 -- 浏览器的抓包编码可以绝对信任吗
前言
本次也是记录一个偶然发现的小问题,有关js逆向和app逆向的系列文章,放一放,有空再系统的整理成文发布了。
这个问题就很骚了,废话不多说,直接情景再现
目标网站:
aHR0cHM6Ly93d3cubW5kLmdvdi50dy9QdWJsaXNoTVBCb29rLmFzcHg/JnRpdGxlPSVFOCVCQiU4RCVFNCVCQSU4QiVFNSU4OCU4QSVFNyU4OSVBOSZTZWxlY3RTdHlsZT0lRTglQkIlOEQlRTQlQkElOEIlRTYlOUMlOUYlRTUlODglOEE=
复现问题
我们的目标就是要下载这个网站的资源文件
首先这个是一级页面,以下圈出的就是二级页面
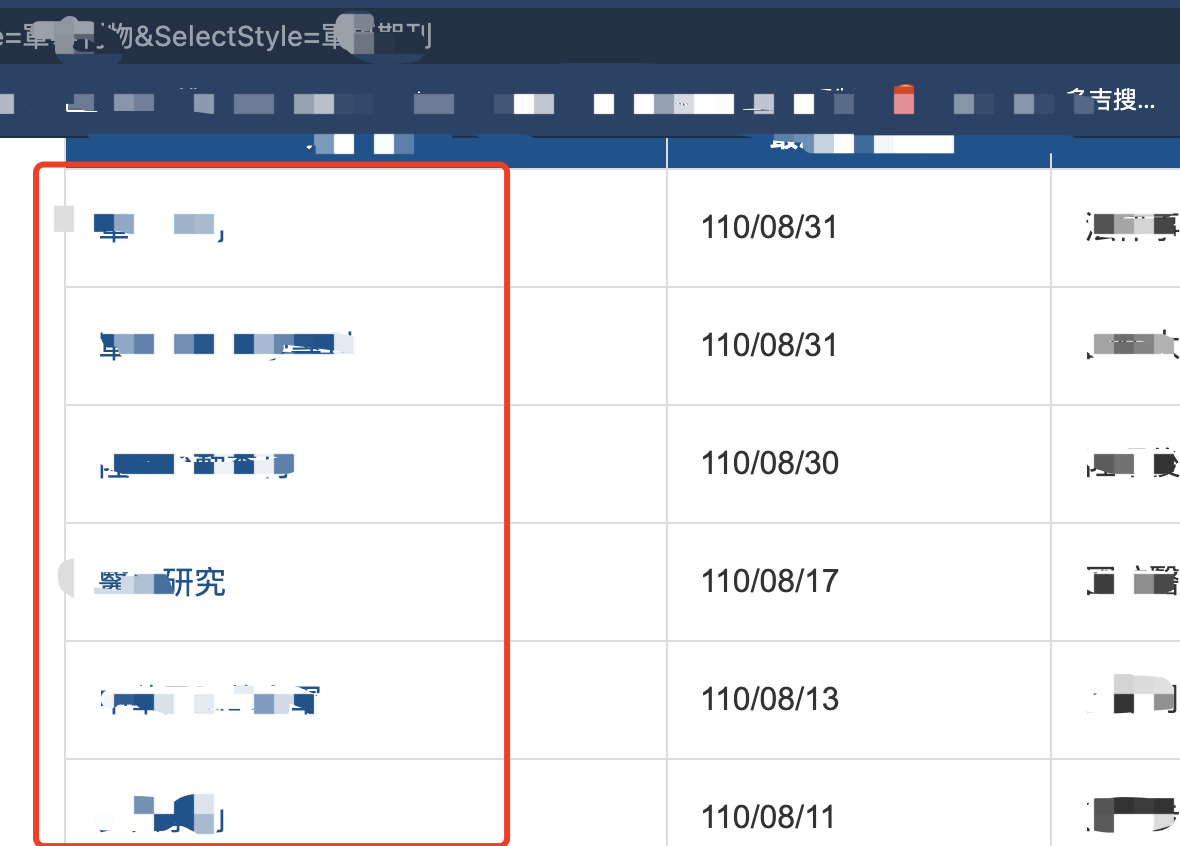
进入二级页面,我下面圈出的地方就是三级页面地址
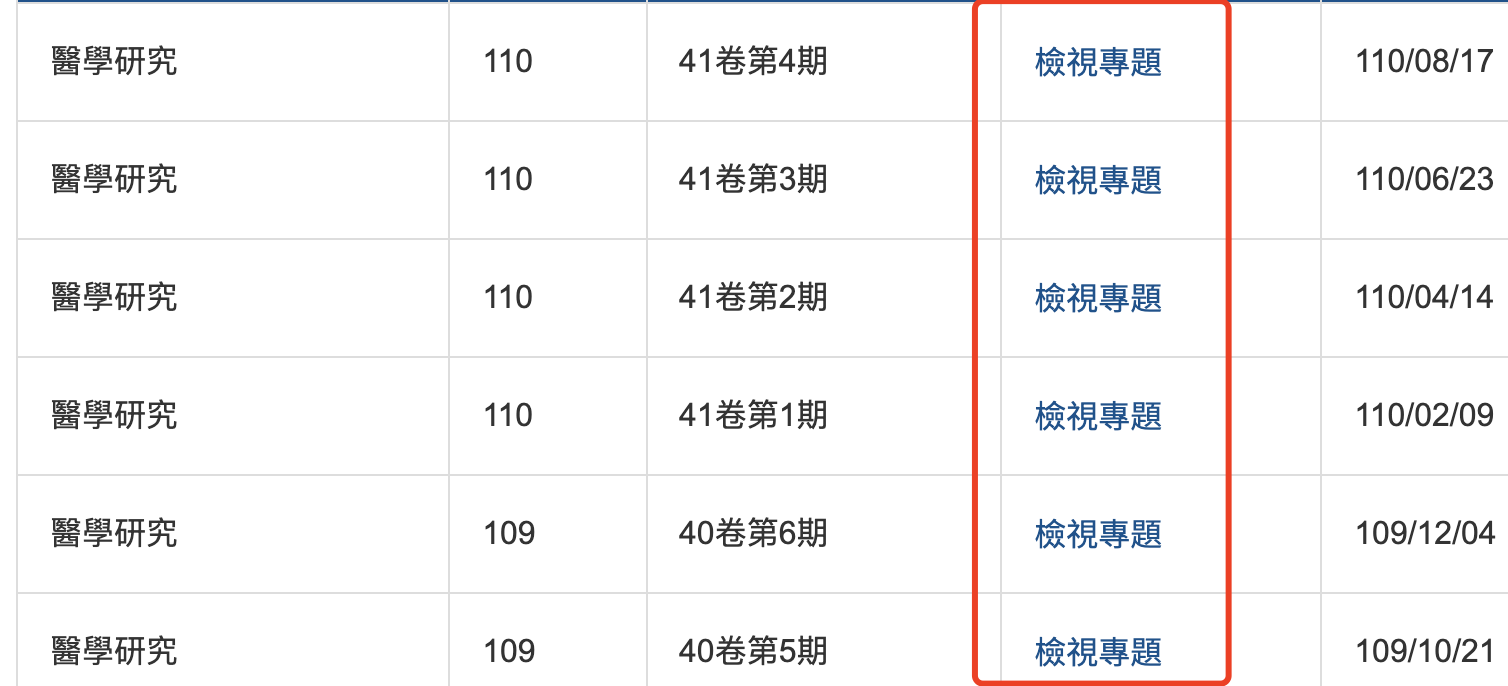
点击三级页面网址,三级页面其实就是在二级底部渲染出来的,下面圈出的什么什么下载的就是我们要的数据了
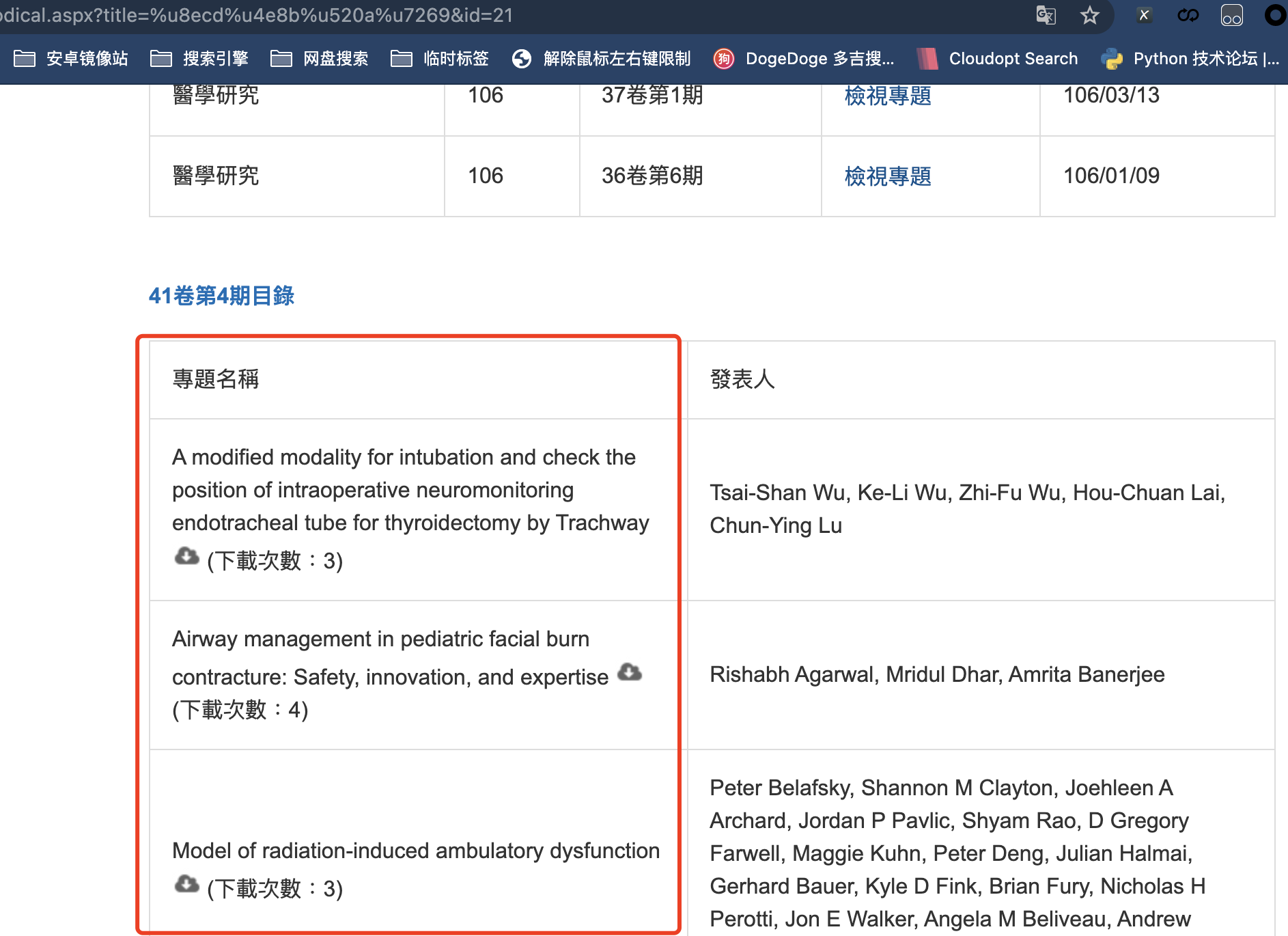
是不是看着很简单
好的,我们直接看他的请求接口:
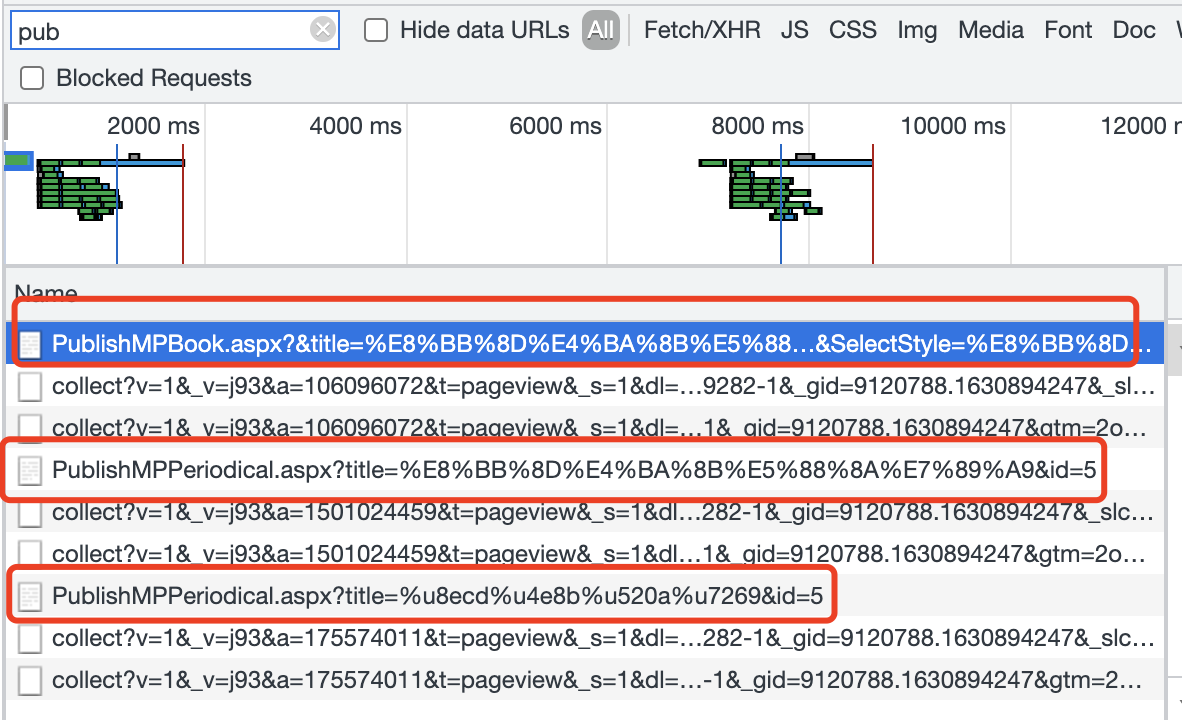
前面两个都是get请求,第三个是post请求,所以我们着重点就在第三个,先看链接:

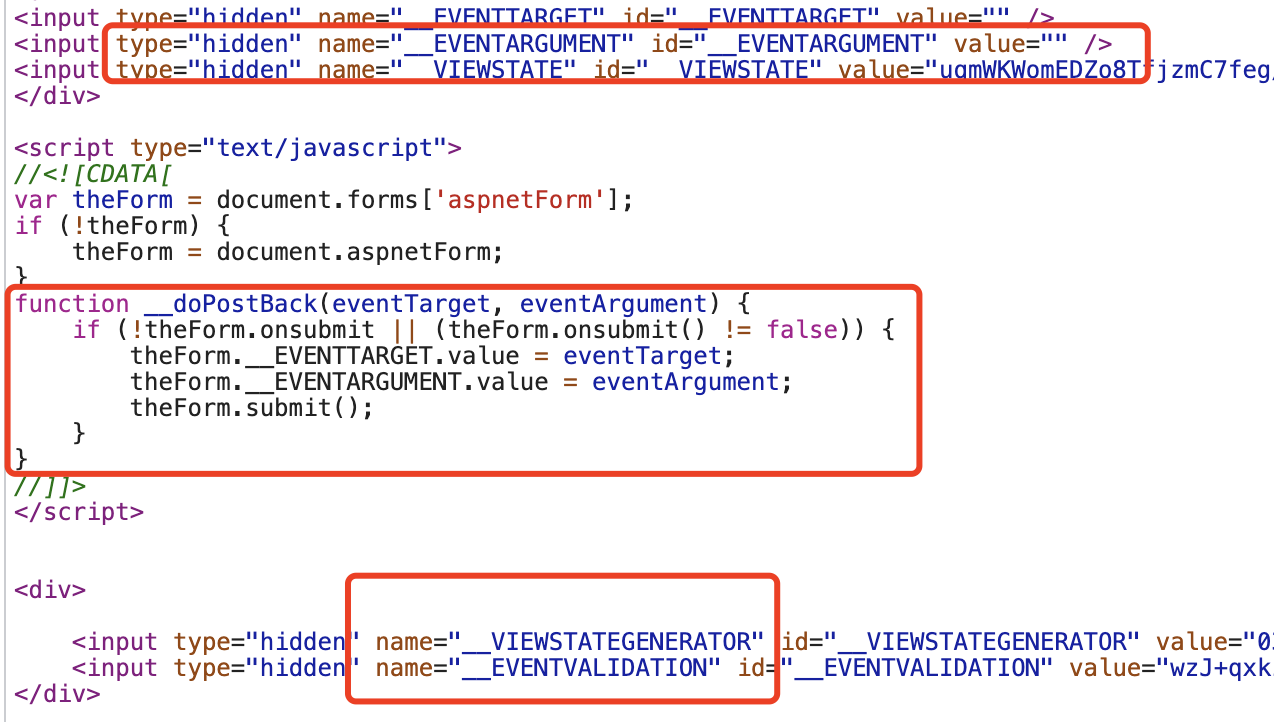
这里看下,有个值没有正常显示:

没事,这个不打紧了,再看请求体:
__EVENTTARGET: ctl00$ContentPlaceHolder1$RtList$ctl01$LkBt
__EVENTARGUMENT:
__VIEWSTATE: i2jc3XTd0XMvdzkJDXcki1wScYnJdfCuOoUlDvgf4ql6TMq8g84WYO1rZ6MyTNjqdoSpUkPNx8VG53Qo2d8+bDEpAlN5bx9At8ApkxRBaAVEthimHSC2wu1pZWg37peXtm+oMKecNXW3cFST4OEGp5rmb3IIcJ4iRnn6v2B6W5VGo3SsBIh5LOA4nAtX0ut87EN
__VIEWSTATEGENERATOR: 0361E37B
__EVENTVALIDATION: 7pEeFbpkgYsGh94FYMVpb/V2HHBATMf46U6yW9OlMx9O55RRM1pySTFubl19vw1ec9F9mBMNS+UZ46T/osr9+s+tOZv4G8ecnT2UsKcl7Vf0vill/V2uqzoLHOiqzkTQIkiUFlK1lwBv89wcIa0zUBdlUZ5/t+YSEEg2GYP7hOL7RpaJM6LOlwKIFrRQY/QiRQ3tL1KPBQ9vEIw3+SUxC905LH8wKjFiCsJpskpThyAR4aySYRF2yZbzNFHWMWiAgZQUd/9O3MXvK6/RZa42d9I8t7xJwAw==
TbSearch2:
TbSearch:
ctl00$ContentPlaceHolder1$txtSearch:
然后,看到这些值,搞过国内某某网站都懂,就是c#的web框架生成出来的值,然后这些值都是在网站源码里面能找到的,其他也不存在什么加密参数,所以,很简单啊,直接拿着代码一顿操作就完了
import requests
from lxml import etree
url = 'https://www.xxxxxxxxx/PublishMPBook.aspx?&title=xxxx%A9&SelectStyle=xxxxx6%xxxxA'
session = requests.session()
headers = {
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
req = session.get(url, headers=headers)
res = req.content.decode('utf-8')
html = etree.HTML(res)
req.close()
data = html.xpath('//div[@class="thisPages"]/table/tr[position()>1]')
for item in data:
curr = dict()
link = item.xpath('./td[1]/a/@href')
link = ''.join(link) if link else ''
kind = item.xpath('./td[1]/a/@title')
kind = ''.join(kind) if kind else ''
pub_date = item.xpath('./td[@headers="LastUpdate"]/text()')
curr['pub_date'] = pub_date
pub_date = ''.join(pub_date) if pub_date else ''
name = item.xpath('./td[@headers="DepartmentName"]/text()')
name = ''.join(name) if name else ''
curr['name'] = name
link = 'https://www.mnd.gov.tw/' + link
sec_req = session.get(link, headers=headers)
sec_res = sec_req.content.decode('utf-8')
sec_req.close()
sec_html = etree.HTML(sec_res)
sec_data = sec_html.xpath('//table[@class="table-bordered"]/tr[position()>1]')
__VIEWSTATE = sec_html.xpath('//input[@id="__VIEWSTATE"]/@value')
__VIEWSTATE = ''.join(__VIEWSTATE) if __VIEWSTATE else ''
__VIEWSTATEGENERATOR = sec_html.xpath('//input[@id="__VIEWSTATEGENERATOR"]/@value')
__VIEWSTATEGENERATOR = ''.join(__VIEWSTATEGENERATOR) if __VIEWSTATEGENERATOR else ''
__EVENTVALIDATION = sec_html.xpath('//input[@id="__EVENTVALIDATION"]/@value')
__EVENTVALIDATION = ''.join(__EVENTVALIDATION) if __EVENTVALIDATION else ''
# print(12312323,__EVENTVALIDATION,__VIEWSTATEGENERATOR,__VIEWSTATE)
# print(123132123,sec_data)
for sec_item in sec_data:
date = sec_item.xpath('./td[@headers="dates"]/text()')
date = ''.join(date) if date else ''
curr['date'] = date
__EVENTTARGET = sec_item.xpath('./td[@headers="MPTable"]/a/@href')
__EVENTTARGET = ''.join(__EVENTTARGET) if __EVENTTARGET else ''
__EVENTTARGET = __EVENTTARGET.replace("javascript:__doPostBack('", '').replace("','')", '')
thr_link = sec_item.xpath('//form[@name="aspnetForm"]/@action')
thr_link = ''.join(thr_link) if thr_link else ''
if thr_link:
thr_link = thr_link.replace('./', '')
thr_link = 'https://www.xxxxxxx/' + thr_link
formdata = {
'__EVENTTARGET': __EVENTTARGET,
'__EVENTARGUMENT': '',
'__VIEWSTATE': __VIEWSTATE,
'__VIEWSTATEGENERATOR': __VIEWSTATEGENERATOR,
'__EVENTVALIDATION': __EVENTVALIDATION,
'TbSearch2': '',
'TbSearch': '',
'ctl00$ContentPlaceHolder1$txtSearch': '',
}
new_headers = headers.copy()
new_headers.update({
'Content-Type': 'application/x-www-form-urlencoded',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
})
thr_req = session.post(thr_link, headers=new_headers, data=formdata)
thr_res = thr_req.content.decode('utf-8')
thr_req.close()
thr_html = etree.HTML(thr_res)
thr_data = thr_html.xpath('//td[@id="Subject"]/../../tr[position()>1]')
for thr_item in thr_data:
file_name = thr_item.xpath('./td[@headers="Subject"]/text()')
file_name = ''.join(file_name) if file_name else ''
curr['file_name'] = file_name
author = thr_item.xpath('./td[@headers="Publisher"]/text()')
author = ''.join(author) if author else ''
curr['author'] = author
file_link = thr_item.xpath('./td[@headers="Subject"]/input/@tile')
file_link = ''.join(file_link) if file_link else ''
curr['file_link'] = file_link
date_year_month = ' '
file_href = f'https://www.xxxxx/NewUpload/{date_year_month}/{file_link}'
curr['file_href'] = file_href
print(123123123213, curr) # 这里就是资源地址了,直接请求存储就行了
反正都不难,这对于很多朋友来说,这????are you kidding me?这么简单的东西值得你大费周章的解析?
嘿嘿嘿,我要不是遇到这个坑,我还真的觉得不至于
先不细说,调试运行看结果:

看着状态码是200,觉得稳得一批对吧,接着看xpath解析部分:

傻眼了吧,为什么会是空,按正常人逻辑,那多半是dom节点没取对是吧,好,看下返回的源码,一看就出问题了,网站平台的结果如下:

在结果里搜,问题大了,根本就没有啊
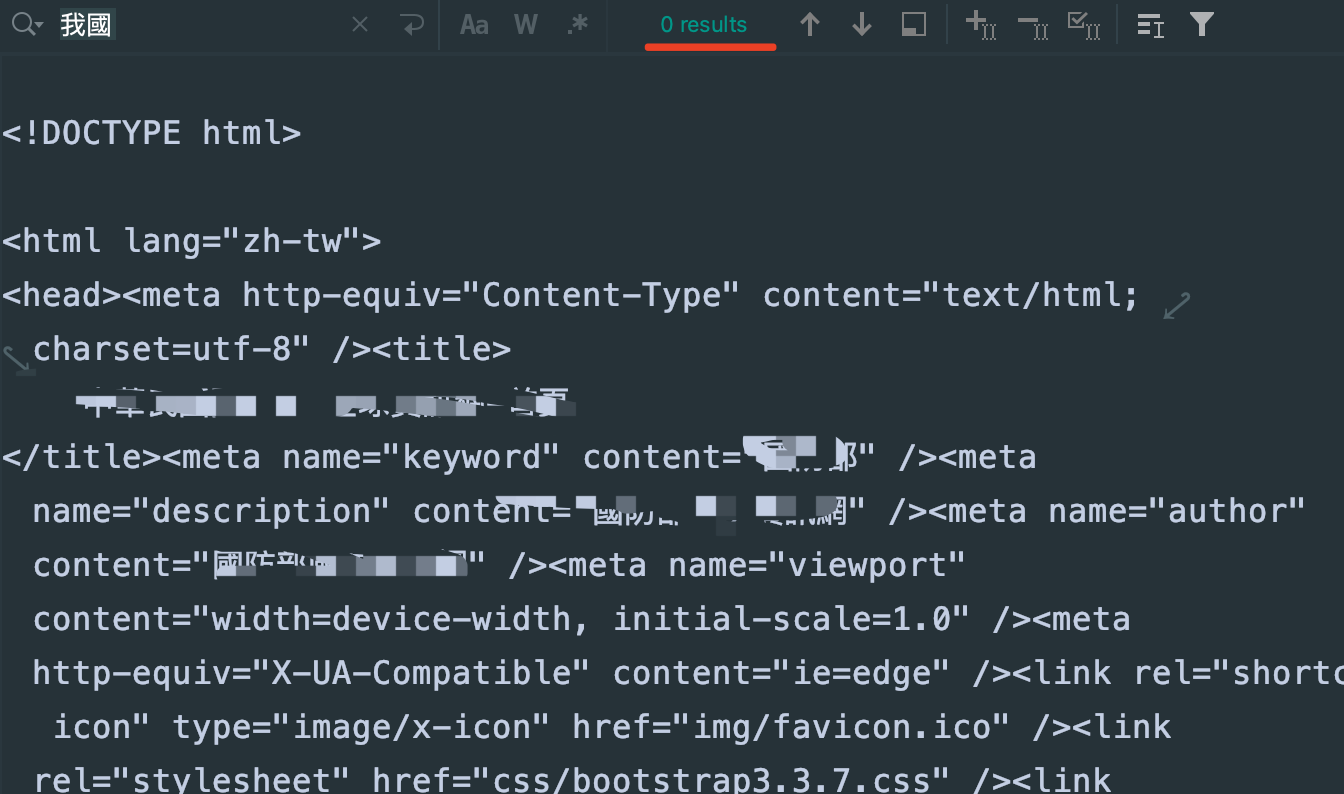
也就是,第三次请求本身就出问题了,根本没有返回正常结果,很奇怪了。
那我第一个想到的就是,估计那几个请求参数出问题了,排查了几个小时,就是没问题啊,我后面用postman单独测试最后一次请求:
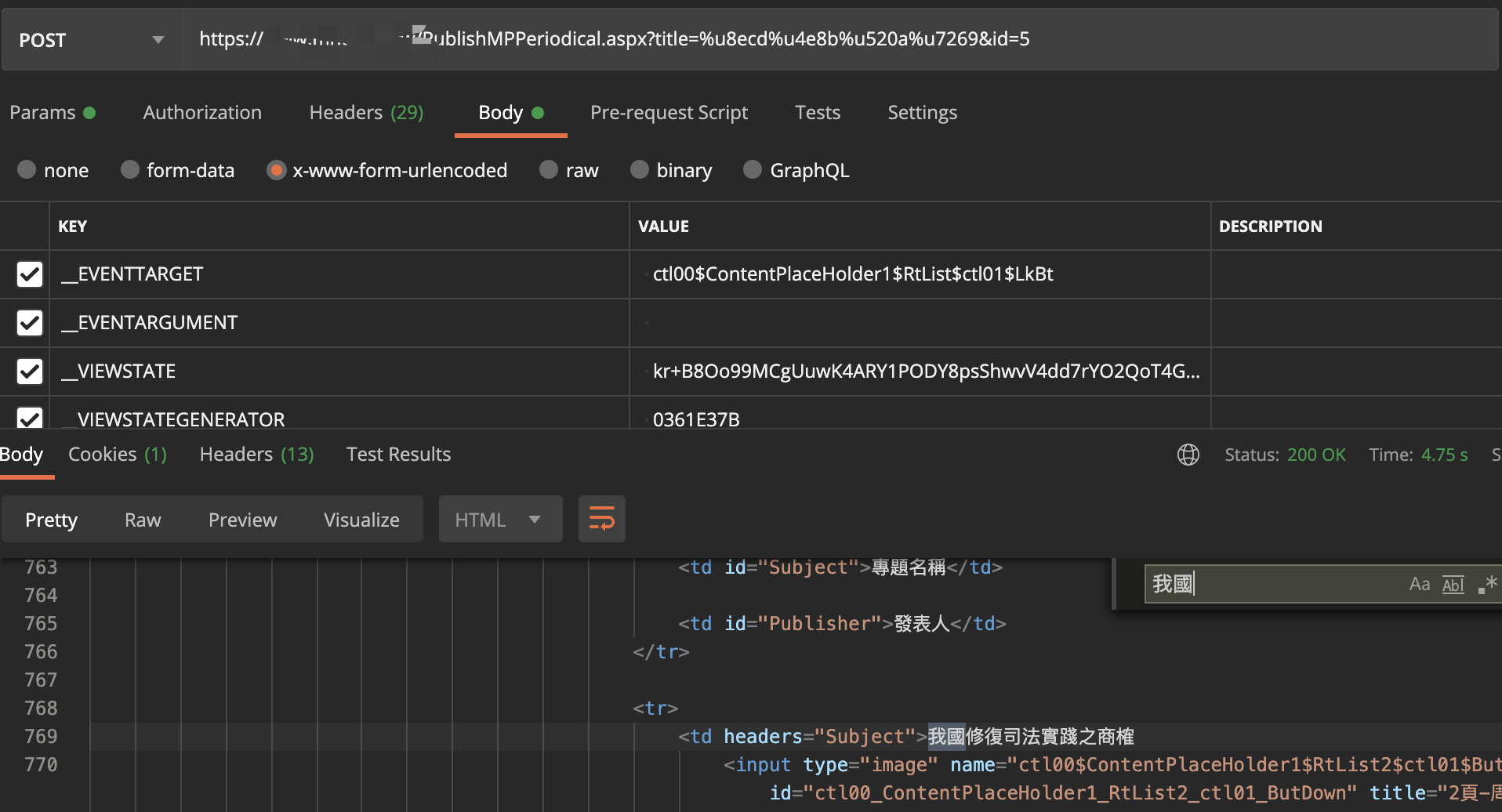
就是有啊,我单独的把第三级的拿出来请求:
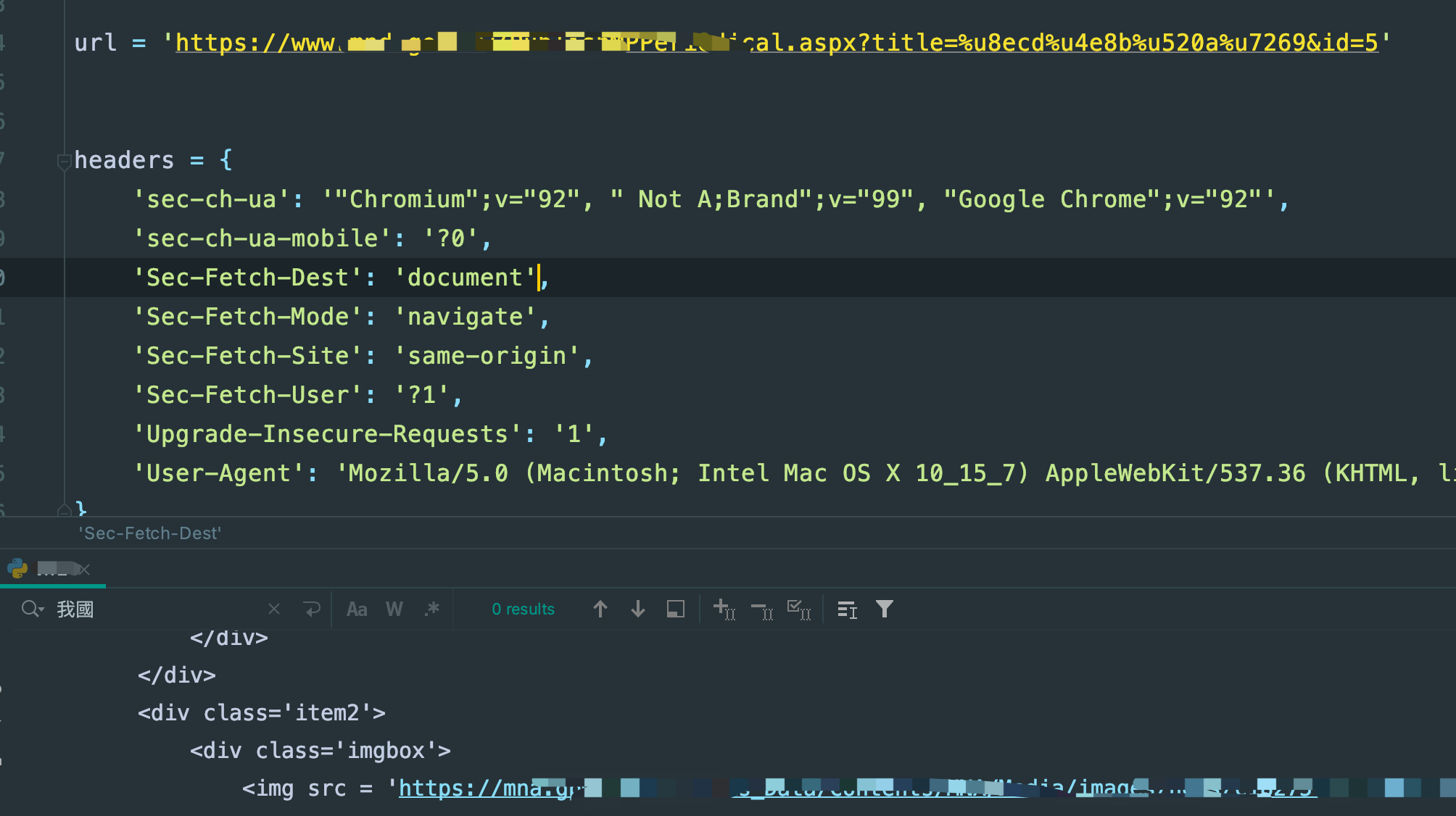
它就是没有正常的获取数据,很骚啊,而且不是一点半点的骚。
最后,我想到一个前端的概念,既然它是submit,看下源码有没有什么猫腻:
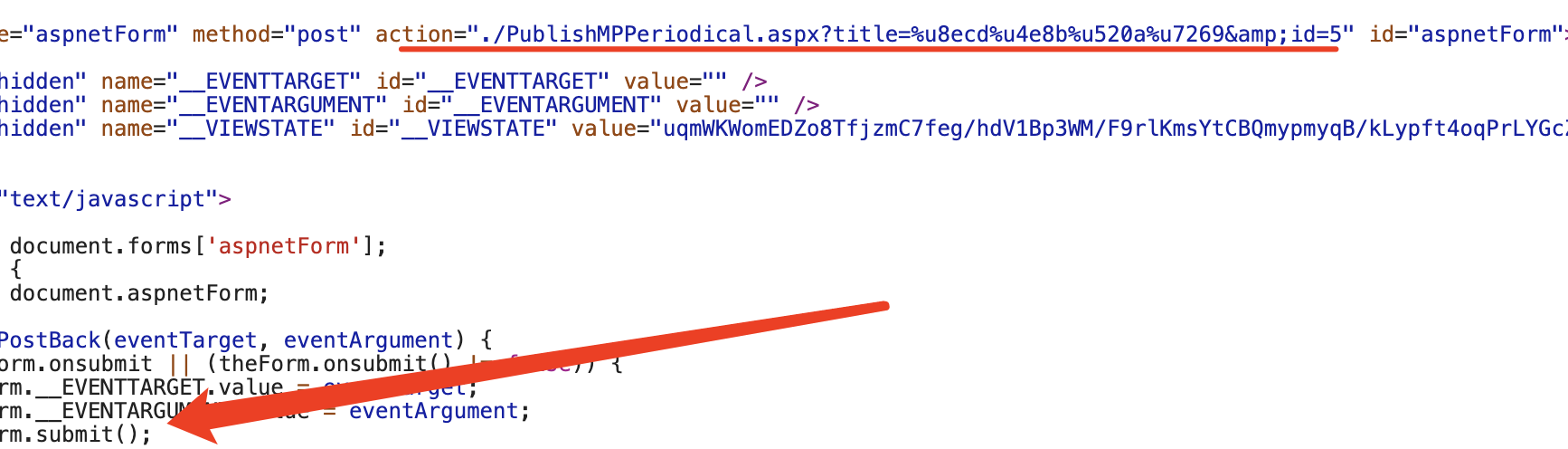
发现确实没有啊,url也就是它这里给的地址,也不存在什么csrf-token之类的,这是为啥啊,一时之间把我整不会了,貌似搞了几年的爬虫跟没搞过一样,这么个问题愣是没整出来,也不涉及js混淆,也不涉及接口加密,所有字段都摆在那,都能拿到,但是就是请求失败,这说实话多多少少有点伤自尊了
找到关键点
那如果真没有解决的话,我也就不会发这篇博客了,跟着分析了一波,既然是所谓的submit,好,那action其实不指定的话就是源地址,而源地址就是第二级链接的,我把第二级和第三级链接复制出来对比:

发现,也就title的值不一样,其他都是一样的,而刚才我特别做了截图,第三级的时候,url的params在浏览器里没有被正常解析:

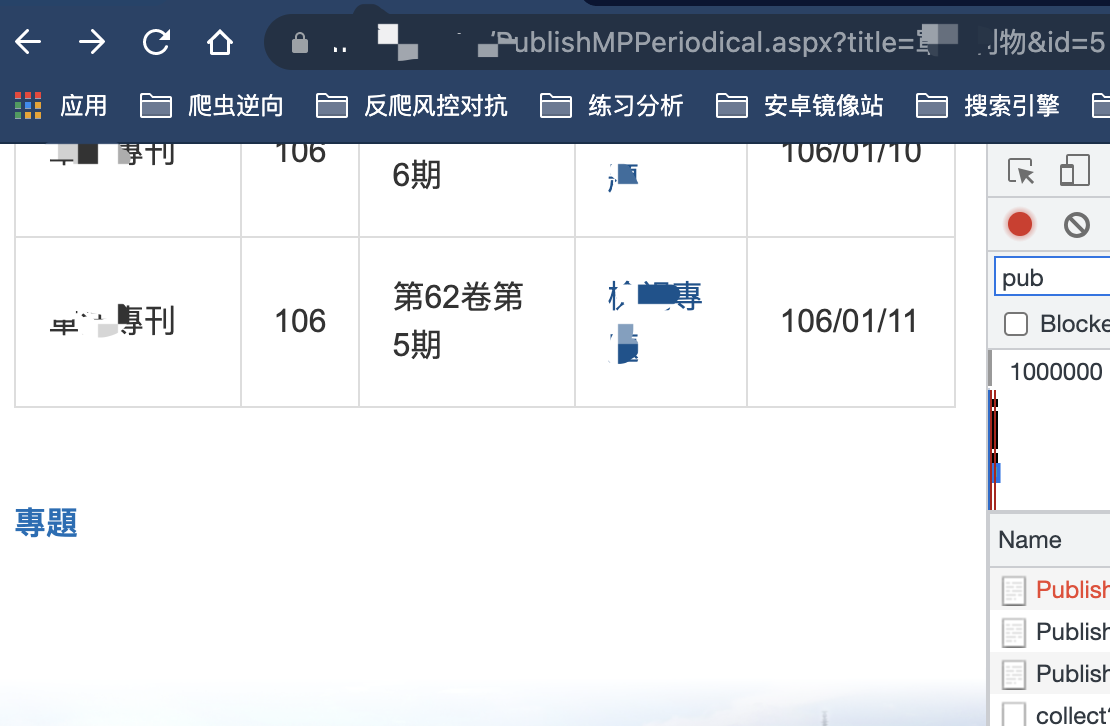
突发奇想,我就用第二级的链接请求呢?有朋友估计有疑惑了,不对啊,你怎么能用第二级的链接作为第三级访问呢?你拿到这个网站分析了就知道了,从二级到三级的时候,其实网站上部分是没有任何变化,变化的是底部突然就多了资源下载列表:
回顾一下,二级页面:
三级页面:
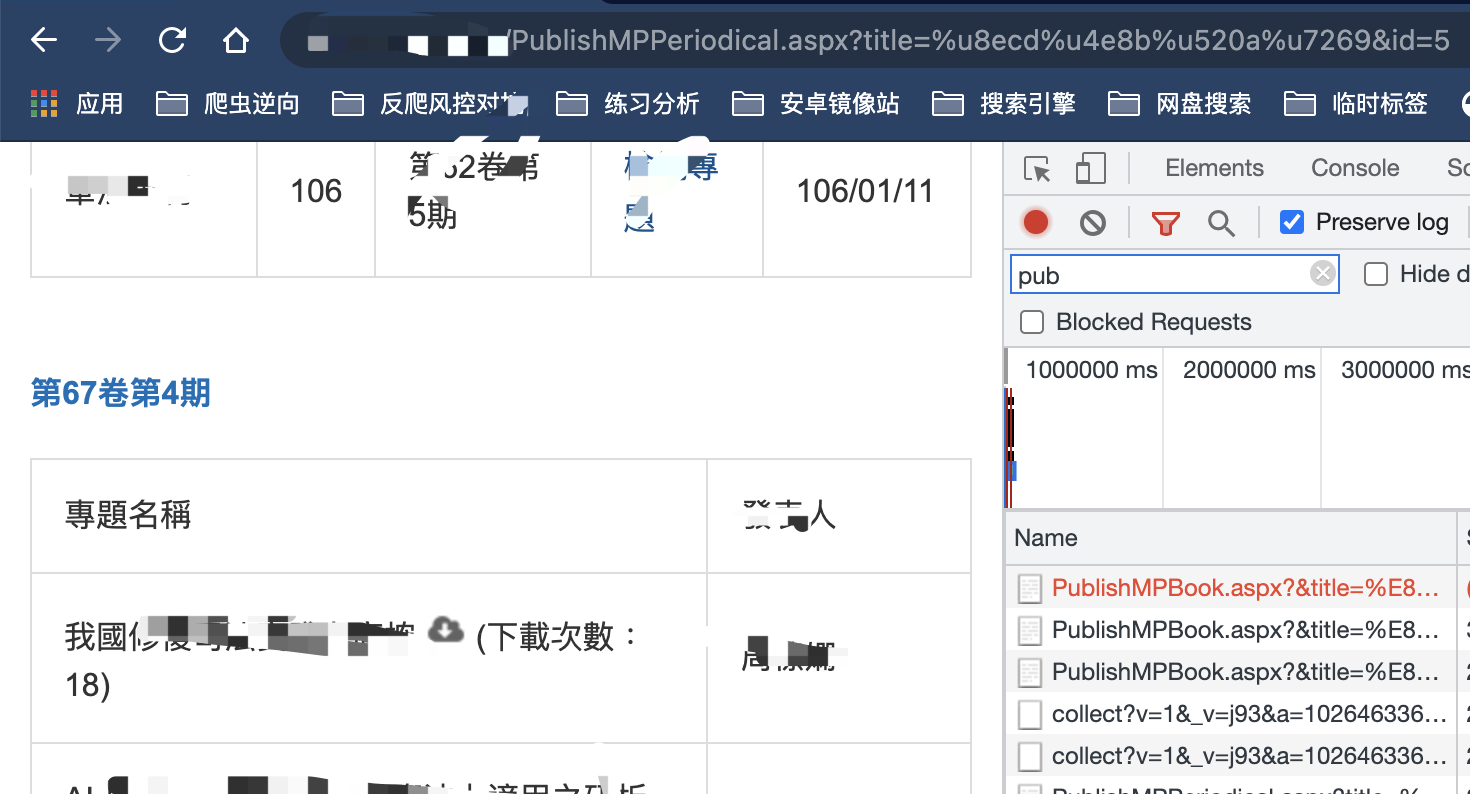
如果您稍微懂一点前端知识的话就大概知道我在说什么了,不太理解的可以查下form表单标签的原理就懂了,好的,继续,这次直接用二级链接请求看看:
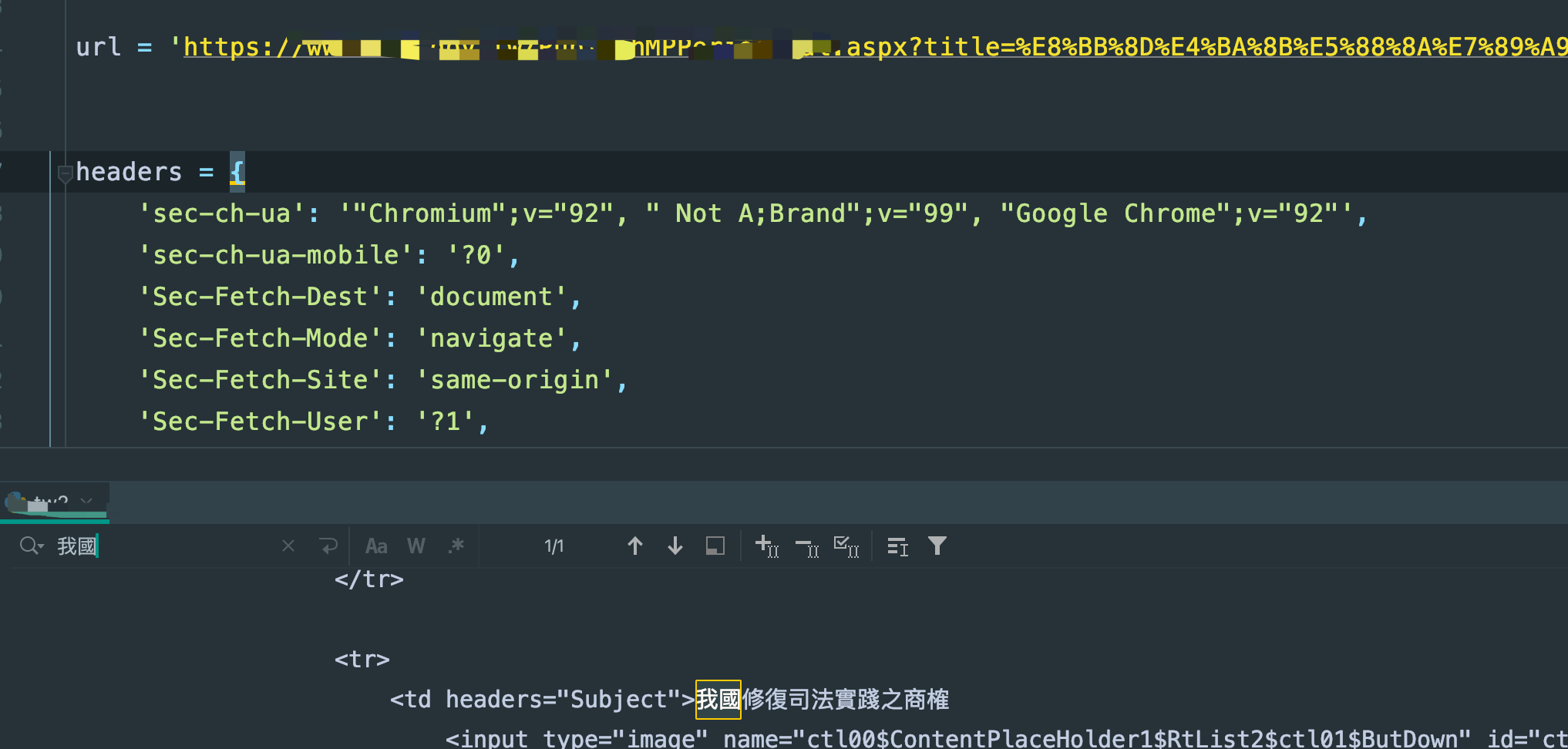
正常拿到结果,果然就是这个问题了
把最后的代码改成如下:
import requests from lxml import etree url = 'https://wxxxxxxStyle=xxxxx%E8%BB%8D%E4%BA%8B%E6%9C%9F%E5%88%8A' session = requests.session() headers = { 'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"', 'sec-ch-ua-mobile': '?0', 'Sec-Fetch-Dest': 'document', 'Sec-Fetch-Mode': 'navigate', 'Sec-Fetch-Site': 'same-origin', 'Sec-Fetch-User': '?1', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36', } req = session.get(url, headers=headers) res = req.content.decode('utf-8') html = etree.HTML(res) req.close() data = html.xpath('//div[@class="thisPages"]/table/tr[position()>1]') for item in data: curr = dict() link = item.xpath('./td[1]/a/@href') link = ''.join(link) if link else '' kind = item.xpath('./td[1]/a/@title') kind = ''.join(kind) if kind else '' pub_date = item.xpath('./td[@headers="LastUpdate"]/text()') curr['pub_date'] = pub_date pub_date = ''.join(pub_date) if pub_date else '' name = item.xpath('./td[@headers="DepartmentName"]/text()') name = ''.join(name) if name else '' curr['name'] = name link = 'https://wxxxxxxv.tw/' + link sec_req = session.get(link, headers=headers) sec_res = sec_req.content.decode('utf-8') sec_req.close() sec_html = etree.HTML(sec_res) sec_data = sec_html.xpath('//table[@class="table-bordered"]/tr[position()>1]') __VIEWSTATE = sec_html.xpath('//input[@id="__VIEWSTATE"]/@value') __VIEWSTATE = ''.join(__VIEWSTATE) if __VIEWSTATE else '' __VIEWSTATEGENERATOR = sec_html.xpath('//input[@id="__VIEWSTATEGENERATOR"]/@value') __VIEWSTATEGENERATOR = ''.join(__VIEWSTATEGENERATOR) if __VIEWSTATEGENERATOR else '' __EVENTVALIDATION = sec_html.xpath('//input[@id="__EVENTVALIDATION"]/@value') __EVENTVALIDATION = ''.join(__EVENTVALIDATION) if __EVENTVALIDATION else '' # print(12312323,__EVENTVALIDATION,__VIEWSTATEGENERATOR,__VIEWSTATE) # print(123132123,sec_data) for sec_item in sec_data: date = sec_item.xpath('./td[@headers="dates"]/text()') date = ''.join(date) if date else '' curr['date'] = date __EVENTTARGET = sec_item.xpath('./td[@headers="MPTable"]/a/@href') __EVENTTARGET = ''.join(__EVENTTARGET) if __EVENTTARGET else '' __EVENTTARGET = __EVENTTARGET.replace("javascript:__doPostBack('", '').replace("','')", '') thr_link = sec_item.xpath('//form[@name="aspnetForm"]/@action') thr_link = ''.join(thr_link) if thr_link else '' if thr_link: thr_link = thr_link.replace('./', '') thr_link = 'https://wxxxxxw/' + thr_link formdata = { '__EVENTTARGET': __EVENTTARGET, '__EVENTARGUMENT': '', '__VIEWSTATE': __VIEWSTATE, '__VIEWSTATEGENERATOR': __VIEWSTATEGENERATOR, '__EVENTVALIDATION': __EVENTVALIDATION, 'TbSearch2': '', 'TbSearch': '', 'ctl00$ContentPlaceHolder1$txtSearch': '', } new_headers = headers.copy() new_headers.update({ 'Content-Type': 'application/x-www-form-urlencoded', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' }) # thr_req = session.post(thr_link, headers=new_headers, data=formdata) thr_req = session.post(link, headers=new_headers, data=formdata) thr_res = thr_req.content.decode('utf-8') thr_req.close() thr_html = etree.HTML(thr_res) thr_data = thr_html.xpath('//td[@id="Subject"]/../../tr[position()>1]') for thr_item in thr_data: file_name = thr_item.xpath('./td[@headers="Subject"]/text()') file_name = ''.join(file_name) if file_name else '' curr['file_name'] = file_name author = thr_item.xpath('./td[@headers="Publisher"]/text()') author = ''.join(author) if author else '' curr['author'] = author file_link = thr_item.xpath('./td[@headers="Subject"]/input/@tile') file_link = ''.join(file_link) if file_link else '' curr['file_link'] = file_link date_year_month = ' ' file_href = f'https://www.xxxxx/xxxx/{date_year_month}/{file_link}' curr['file_href'] = file_href print(123123123213, curr)
运行结果肯定是有的,就不费篇幅展示了
疑问
那细心的老哥估计要问了,为啥用postman和谷歌浏览器时,用的那个看到的三级链接就可以,在打码里得用二级链接才行?
卧槽,老哥,你问的这个问题,非常的专业,请看如下:

注意,上图右边的是python2环境下的,有没有发现,这可太对应了,也就【\】被替换成了【%】,那果然是这个编码的问题了,右边不难看出,就是unicode编码,而谷歌浏览器能解析的默认是url编码的,所以显示的unable decode,
而为啥python里不行,我想应该是python你给什么url它就是什么,而postman和谷歌会把url做一定编码处理吧,但是具体我没有去仔细研究了,反正就是这个问题了,over
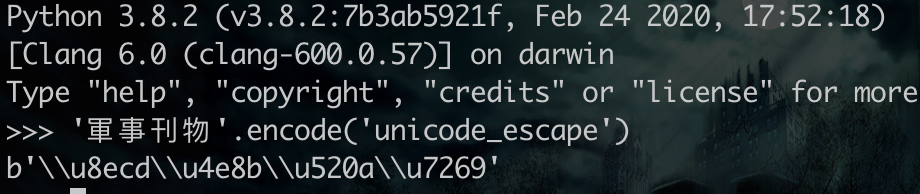
对了,补一个python3里的unicode编码:
结语
所以啊,浏览器的抓包还是不能绝对相信啊,这可是个大坑啊,搞了几个小时搞出来的,心累。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号