python爬虫 - 反爬之登陆状态二次验证
前言:
偶然发现的一个网站,需要网址的私信,不是说要玩什么套路,而是毕竟不能明目张胆的把别人网址发出来
分析
打开浏览器访问,目前是正常访问:
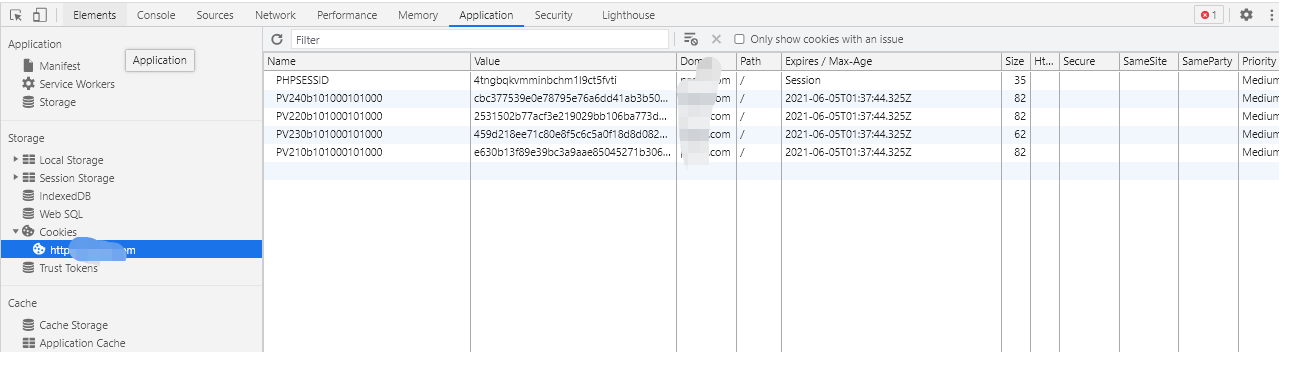
然后它的cookie是这些:
我现在在代码里用一个过期的cookie:
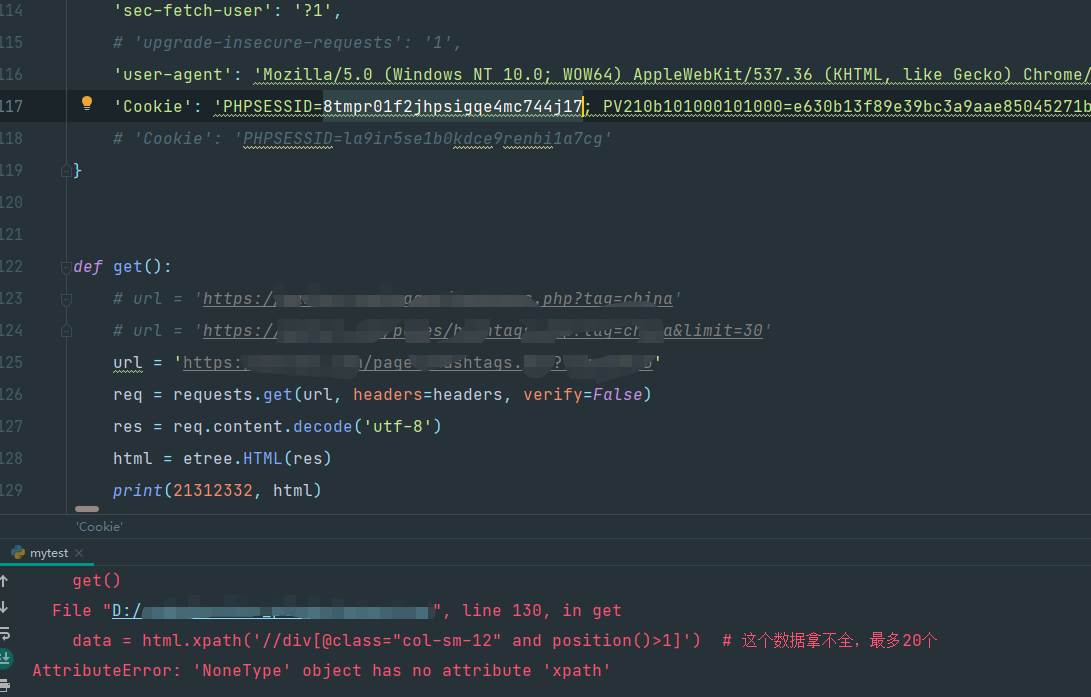
它的请求结果是none
我现在赋值这个过期的cookie到浏览器,回车保存
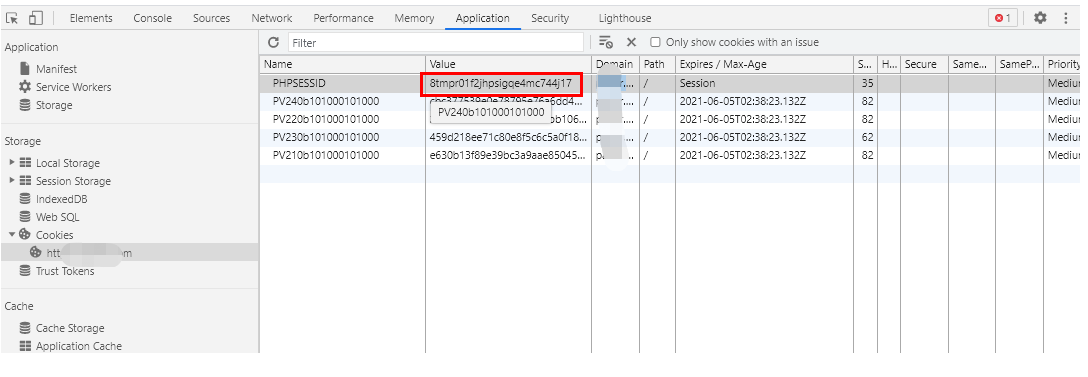
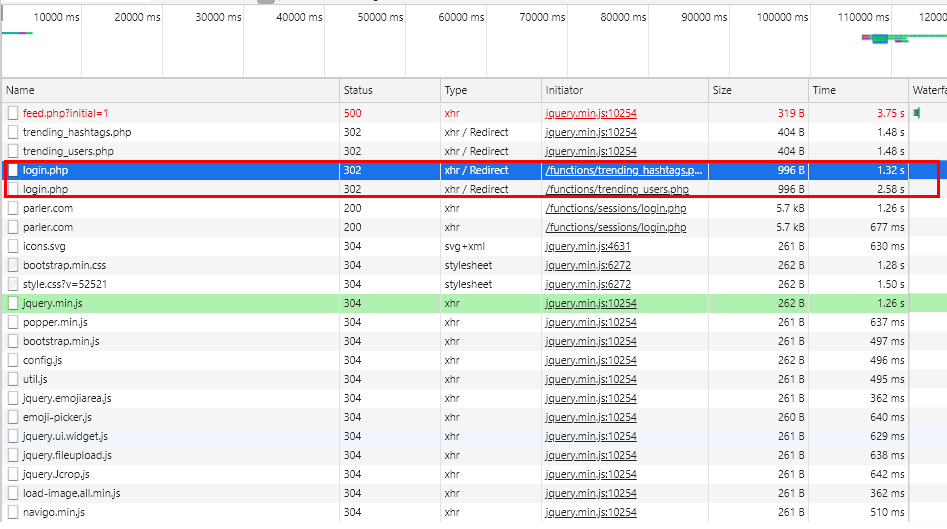
那我浏览器这边刷新看,它就重新访问了下登陆接口,看起来没有什么端倪是吧
不急,接着看,
我换一个cookie继续在浏览器里重改值,在测试代码里复制的之前的过期的cookie
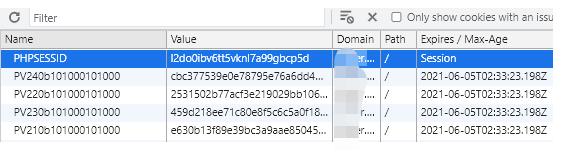
不用代码处理了,直接浏览器刷新看看:
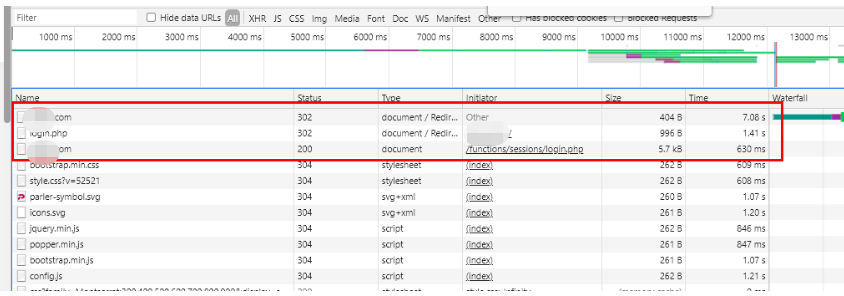
我现在退出下,然后重新登陆看看,退出有点慢,我直接清楚掉cookie重新登陆:
然后通过这次重新登陆,可以肯定的是,cooKie是登陆之前就生成好了,然后去服务器注册的,因为你看这个登陆接口的交互信息里,这个PHPSESSID居然在请求头里就有了,而不是在返回头或者返回结果里
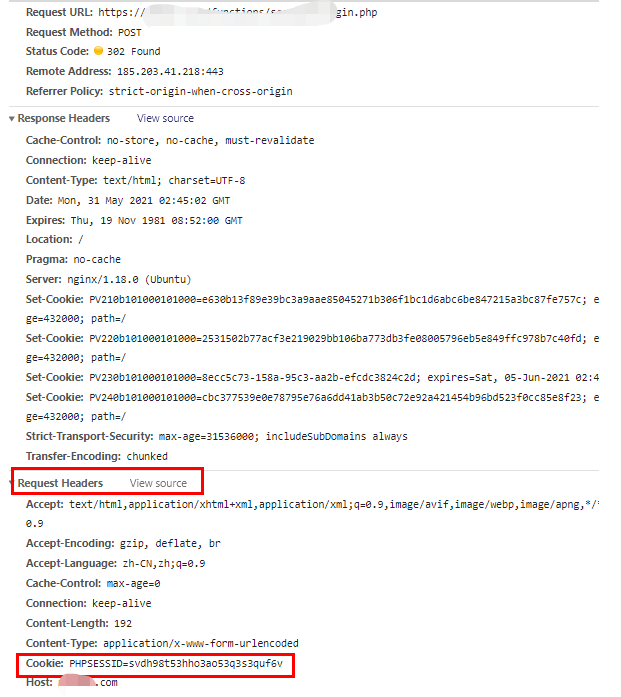
我已经登陆了哈,我刷新下页面:
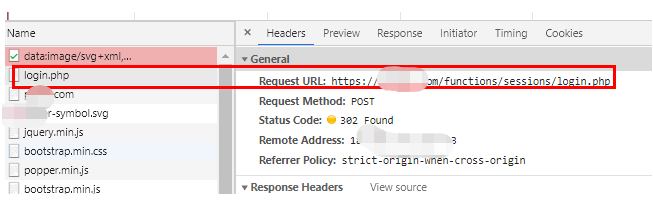
我再刷新下:
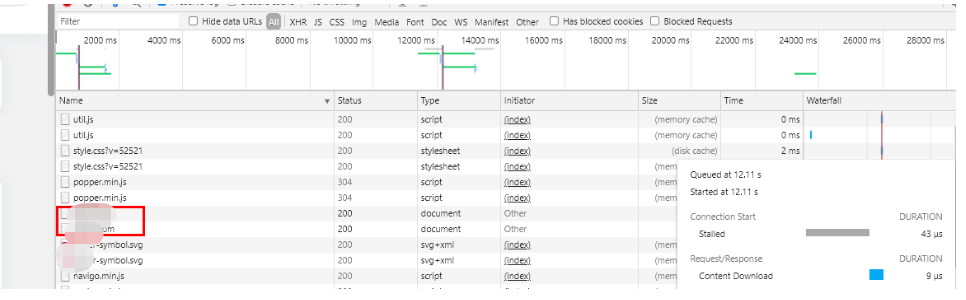
发现关键点
有没有发现问题啊?
好了不浪费时间了,我直接说吧,你看我登陆后第一次刷新,为什么还去访问了下登陆接口?第二次刷新为什么就不用再访问登陆接口呢?
这里就是关键了,我明明已经登陆过了,这个PHPSESSID 也去注册过了,为什么还要再去访问一次登陆接口?不觉得很不符合正常的业务逻辑吗?你是不是觉得这个是多余的?
还真不是多余的,这个就是该平台的反爬机制,首先我们知道,大部分平台过后,拿到的cooKie直接就可以用了,然后我们写爬虫,是不是也一样,直接就复制下来拿来用了,而这里我试了好多次,登录之后拿到的cooKie就是用不了,它就是因为上面的“多余”的请求动作,再一次对cookie做了注册验证,然后才能正常使用,这也就是刚才我用过期的cookie不能直接用的原因,对了,补充下,我上面用的过期的cookie是之前(非当日)登陆之后在浏览器里复制下来的
这个逻辑不验证下的话,你估计以为我在演你,好,来,用代码说话:
最开始的这个8tm开头的是不能用的对吧
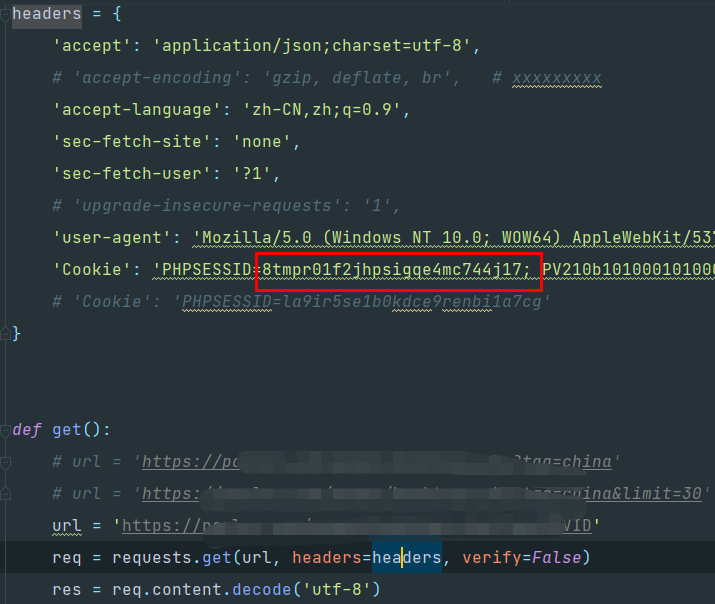
我加一个逻辑,就多请求了一次登陆接口,执行
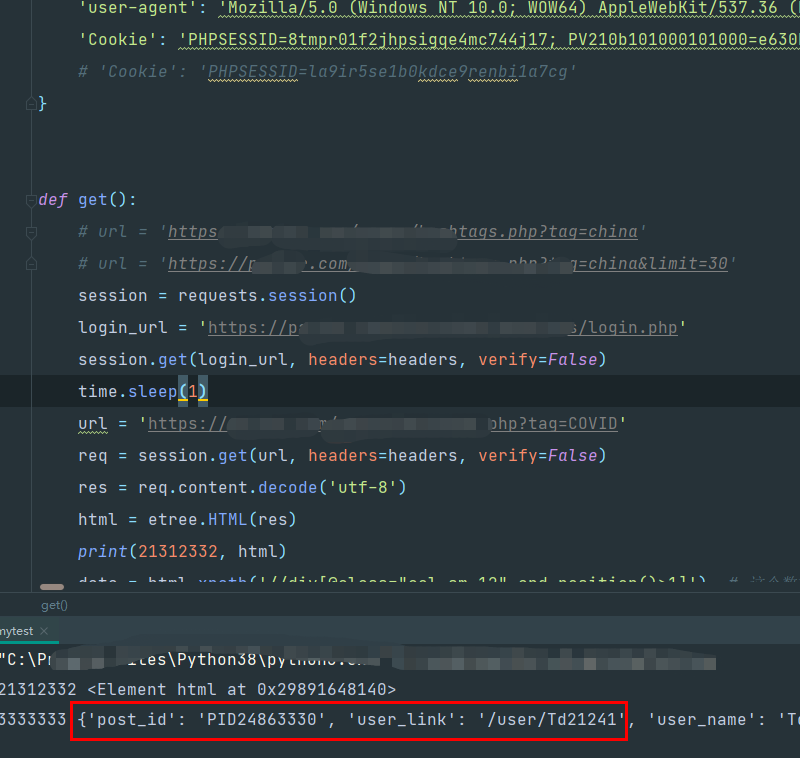
数据已经有了,说明过期的cookie确实需要再去调用下登陆接口注册下就可以用了。
我再改回去,没有调用登陆接口的时候,执行,正常拿结果,这也就是上面的问题,我登陆之后,第一次刷新需要调用登陆接口,而第二次刷新不需要了,因为已经注册过了
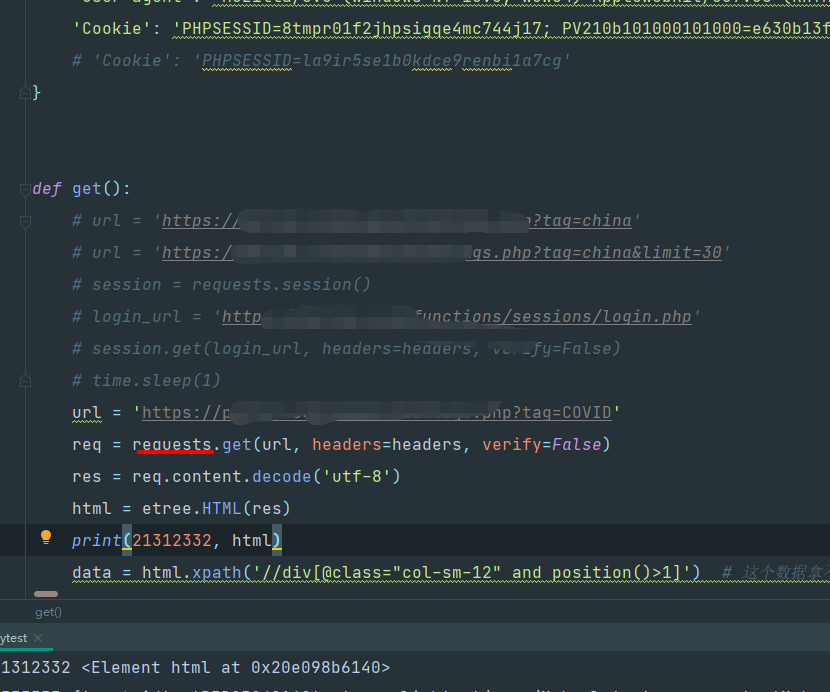
那么也就是时候,这个8tm开头的cookie已经被注册好了对吧。
那么估计你有个疑问,之前用的cooKie是不是就没法用了?验证下,我去浏览器赋值一个cookie放过来看看:
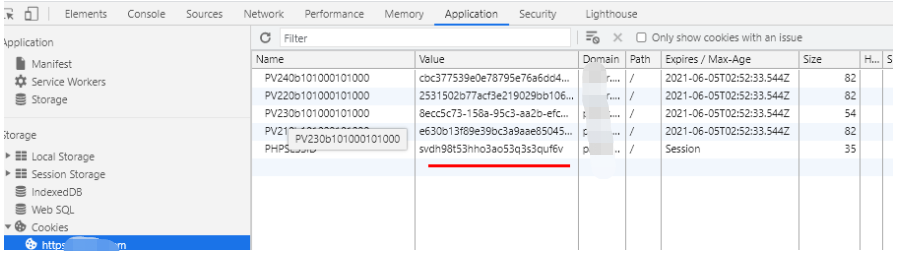
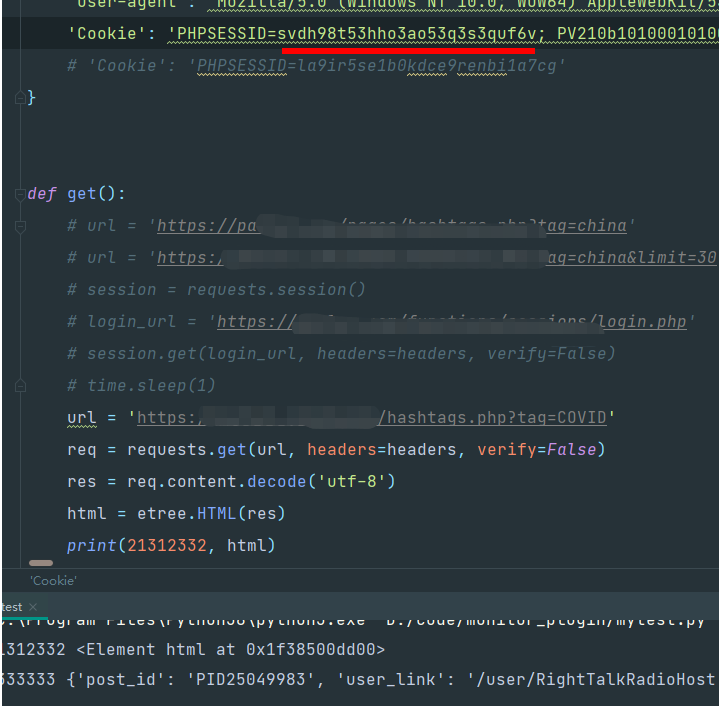
也就是说,它这个cookie并不是常规的那种,用了新的后,旧的自动作废,因为它这个旧的cookie只要再访问一次登陆接口,就可以把旧的cookie重新注册为可用,那么也就是我们可以用一个cookie无限续期了。
完毕!!!!!
结语
总的来说,这种也算是一种反爬机制了,只是针对的反爬等级属于中低级的样子,当然,如果不花点时间研究的话,还真容易被骗过去,然后你就会在代码里一直调试,浏览器一直也看不出问题,接着请求次数过多ip被ban了,但你只要耐心分析,其实还是挺简单的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号