一、三元表达式
# 针对以下需求:条件成立时,返回一个值;条件不成立时,返回另一个值。=====》用三元表达式,一行代码
def func(x,y):
if x > y:
return x
else:
return y
res=func(1,2)
print(res)
# 三元表达式
语法格式: 条件成立时要返回的值 if 条件 else 条件不成立时要返回的值
# 应用举例:也可放在函数体内
res = x if x > y else y
print(res)
res = 111111 if 'egon' == 'egon' else 2222222222
print(res)
二、生成式
1.列表生成式
# 语法格式: [ 能产生返回值的表达式 for 遍历对象 in 可迭代对象 if条件 ]
l = ['alex_dsb', 'lxx_dsb', 'wxx_dsb', "xxq_dsb", 'egon']
new_l=[]
for name in l:
if name.endswith('dsb'):
new_l.append(name)
new_l=[name for name in l if name.endswith('dsb')]
new_l=[name for name in l] # 就等同于 条件全为真
print(new_l)
# 把所有小写字母全变成大写
new_l=[name.upper() for name in l]
print(new_l)
# 把所有的名字去掉后缀_dsb
new_l=[name.replace('_dsb','') for name in l]
new_l=[name.strip('_dsb') for name in l ]
print(new_l)
2.字典生成式
# 语法格式: { 能产生返回值的表达式 for 遍历对象 in 可迭代对象 if条件 }
keys=['name','age','gender']
dic={key:None for key in keys}
print(dic)
items=[('name','egon'),('age',18),('gender','male')]
res={k:v for k,v in items if k != 'gender'}
print(res)
3.集合生成式
# 语法格式: { 能产生返回值的表达式 for 遍历对象 in 可迭代对象 if条件 }
与字典的区别时,只是单个值,不能加 ':value'
keys=['name','age','gender']
set1={key for key in keys}
print(set1,type(set1))
4.生成器表达式
# 语法格式: ( 能产生返回值的表达式 for 遍历对象 in 可迭代对象 if条件 )
# 没有元祖表达式,因为元祖不可变,没有元祖.append() 方法,故为生成器表达式
# 优点:对比以上三个生成式,节省内存(一次只产生一个值在内存中)
g=(i for i in range(10) if i > 3)
# !!!!!!!!!!!强调!!!!!!!!!!!!!!!
# 此刻g内部一个值也没有
print(g,type(g))
print(g) # 生成器对象
print(next(g))
print(next(g))
print(next(g))
# 计算文件内的字符数
with open('笔记.txt', mode='rt', encoding='utf-8') as f:
# 方式一:初始值累加
# res=0
# for line in f:
# res+=len(line)
# print(res)
# 方式二:sum() +列表表达式
# res=sum([len(line) for line in f])
# print(res)
# 方式三 :sum() +生成器表达式 ------> 效率最高
# res = sum((len(line) for line in f))
# 上述可以简写为如下形式
res = sum(len(line) for line in f)
print(res)
三、函数的递归调用
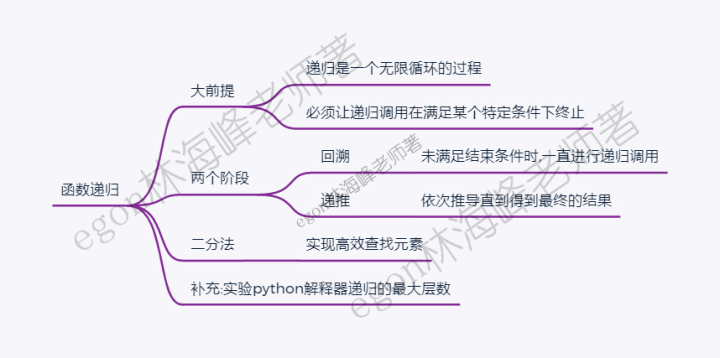
1.递归的定义
# 函数的嵌套:
1.函数不仅可以嵌套定义,还可以嵌套调用,即在调用一个函数的过程中,函数内部又调用另一个函数
# 函数的递归调用
2.函数的递归调用指的是在调用一个函数的过程中又直接或间接地调用该函数本身
# 是函数嵌套调用的一种特殊形式
# 案例:
# 直接调用本身-----》在自己函数体内一直循环调用本身
def f1():
print('是我是我还是我')
f1()
f1()
# 间接调用本身-----》借助其他函数体内一直循环调用本身
def f1():
print('===>f1')
f2()
def f2():
print('===>f2')
f1()
f1()
以上两种递归调用都是一个无限循环的过程,但在python对函数的递归调用的深度做了限制
# 注:
1.python默认递归层级最大:1000 -----》sys.getrecursionlimit() # 查看
2.python不是一门函数式编程语言,无法对递归进行尾递归优化。
3.递归调用不应该无限地调用下去,必须在满足某种条件下结束递归调用
2.回溯与递推
# 递归的两个阶段
# 1.回溯
一层一层调用下去 ----》回归初心,找到递归的源头
# 2.递推
满足某种结束条件,结束递归调用,然后一层一层返回----》根据递归的源头,逐步推导每层调用,返回当前
# 案例:
age(5) = age(4) + 10
age(4) = age(3) + 10
age(3) = age(2) + 10
age(2) = age(1) + 10
age(1) = 18
def age(n):
if n == 1:
return 18
return age(n-1) + 10
res=age(5)
print(res)
# 阶段分析:
回溯阶段:
要求第n个的age,需要回溯得到(n-1)个的age,
以此类推,直到得到第一个的age
此时,age(1)已知,因而不必再向前回溯了。
递推阶段:
从第一个的age可以推算出第二个的age 28
从第二个的age可以推算出第三个的age 38
以此类推,一直推算出第五个的age 58 ,递归结束。
# 需要注意的一点是,递归一定要有一个结束条件,这里n=1就是结束条件。
3.递归的应用
# 递归本质就是在做重复的事情,
故理论上递归可以解决的问题 循环也都可以解决
只不过在某些情况下,使用递归会更容易实现
# eg: 有一个嵌套多层的列表,要求打印出所有的元素
l=[1,2,[3,[4,[5,[6,[7,[8,[9,10,11,[12,[13,]]]]]]]]]]
def f1(list1):
for x in list1:
if isinstance(i,list):
# 如果是列表,应该再循环、再判断,即重新运行本身的代码
f1(x)
else:
print(x, end=' ')
f1(l)
# eg:递归实现二分法
# 对于一个有序列表,查找某个值是否在列表中
nums = [-3, 5, 7, 11, 21, 31, 41, 53, 67, 77, 83, 99, 101]
def search(nums,find_num):
print(nums)
if len(nums) == 0:
print('不存在')
return
mid_index = len(nums) // 2
if find_num > nums[mid_index]:
# 在右半部分
search(nums[mid_index+1:],find_num)
elif find_num < nums[mid_index]:
# 在左半部分
search(nums[:mid_index],find_num)
else:
print('找到了')
search(nums,67)
search(nums,69)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号