06--基本类型03:集合 和字符编码
1.集合
见https://zhuanlan.zhihu.com/p/108793771
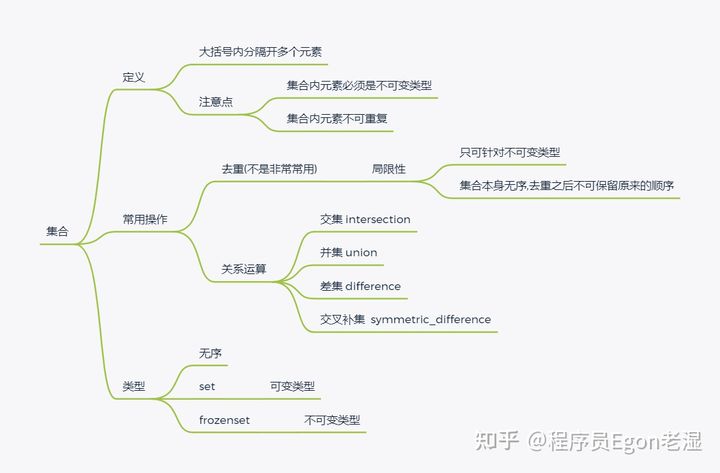
1.1 介绍
# 1.作用
集合、list、tuple、dict一样都可以存放多个值,但是集合主要用于:去重、关系运算
# 2.定义
"""
定义:在{}内用逗号分隔开多个元素,集合具备以下三个特点:
1:每个元素必须是不可变类型
2:集合内没有重复的元素
3:集合内元素无序
"""
s = {1,2,3,4} # 本质 s = set({1,2,3,4})
# 注意
1.列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值,
而集合类型既没有索引也没有key与值对应,所以无法取得单个的值,
而且对于集合来说,主要用于去重与关系元素,根本没有取出单个指定值这种需求。
2.{}既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,
现在我们想定义一个空字典和空集合,该如何准确去定义两者?
d = {} # 默认是空字典
s = set() # 这才是定义空集合
# 3.类型转换
但凡能被for循环的遍历的数据类型(强调:遍历出的每一个值都必须为不可变类型)都可以传给set()转换成集合类型
s = set([1,2,3,4]) # {1, 2, 3, 4}
s1 = set((1,2,3,4)) # {1, 2, 3, 4}
s2 = set({'name':'jason',}) # {'name'}
s3 = set('egon') # {'e', 'o', 'g', 'n'}
1.2 使用
### 关系运算
friends1 = {"zero","kevin","jason","egon"} # 用户1的好友们
friends2 = {"Jy","ricky","jason","egon"} # 用户2的好友们
# 1.合集/并集(|):求两个用户所有的好友(重复好友只留一个)
friends1 | friends2
{'kevin', 'ricky', 'zero', 'jason', 'Jy', 'egon'}
# 2.交集(&):求两个用户的共同好友
friends1 & friends2
{'jason', 'egon'}
# 3.差集(-):
friends1 - friends2 # 求用户1独有的好友
{'kevin', 'zero'}
friends2 - friends1 # 求用户2独有的好友
{'ricky', 'Jy'}
# 4.对称差集(^) # 求两个用户独有的好友们(即去掉共有的好友)
friends1 ^ friends2
{'kevin', 'zero', 'ricky', 'Jy'}
# 5.值是否相等(==)
friends1 == friends2
False
# 6.父集:一个集合是否包含另外一个集合
# 6.1 包含则返回True
{1,2,3} > {1,2}
True
{1,2,3} >= {1,2}
True
# 6.2 不存在包含关系,则返回False
{1,2,3} > {1,3,4,5}
False
{1,2,3} >= {1,3,4,5}
False
# 7.子集
{1,2} < {1,2,3}
True
{1,2} <= {1,2,3}
True
### 去重
# 集合去重复有局限性
1. 只能针对不可变类型
2. 集合本身是无序的,去重之后无法保留原来的顺序
l=['a','b',1,'a','a']
s=set(l) # 将列表转成了集合
{'b', 'a', 1}
l_new=list(s) # 再将集合转回列表
['b', 'a', 1] # 去除了重复,但是打乱了顺序
# 针对不可变类型,并且保证顺序则需要我们自己写代码实现,例如
l=[
{'name':'lili','age':18,'sex':'male'},
{'name':'jack','age':73,'sex':'male'},
{'name':'tom','age':20,'sex':'female'},
{'name':'lili','age':18,'sex':'male'},
{'name':'lili','age':18,'sex':'male'},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
# 结果:既去除了重复,又保证了顺序,而且是针对不可变类型的去重
[
{'age': 18, 'sex': 'male', 'name': 'lili'},
{'age': 73, 'sex': 'male', 'name': 'jack'},
{'age': 20, 'sex': 'female', 'name': 'tom'}
]
1.3 其他方法
# 1.长度
s={'a','b','c'}
len(s) # 3
# 2.成员运算
'c' in s # True
# 3.循环
for item in s:
print(item)
c
a
b
2.字符编码
字符编码表就是一张字符与数字的对应关系的表
2.1 发展史
# 阶段一:一家独大---》ASCII表
1.只支持英文字符串
2.一个英文字符对应1Bytes,1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符
# 阶段二:诸侯割据----》各国各自标准
1.中国人定制了GBK
# GBK表的特点:
1、只有中文字符、英文字符与数字的一一对应关系
2、一个英文字符对应1Bytes; 一个中文字符对应2Bytes
补充说明:
1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符
2Bytes=16bit,16bit最多包含65536个数字,可以对应65536个字符,足够表示所有中文字符
# 阶段三:分久比合----》统一标准 Unicode
内存中统一使用Unicode编码
# 1.存在所有语言中的所有字符与数字的一一对应关系,即兼容万国字符
# 2.与传统的字符编码的二进制数都有对应关系
但是由于历史遗留问题,还有许多其他各自编码组成的文件信息等需要保存。(且保存在硬盘上)
# 此处需要强调:
软件是存放于硬盘的,而运行软件是要将软件加载到内存的,
面对硬盘中存放的各种传统编码的软件,在内存读取硬盘数据时,
该Unicode编码需要与其他编码有相对应的映射/转换关系
# UTF-8(Unicode Transformation Format)
UTF-8是针对Unicode的一种可变长度字符编码
一个英文字符占1Bytes;一个中文字符占3Bytes,生僻字用更多的Bytes存储
为节省内存空间,与IO读取速度,将内存中的unicode二进制写入硬盘
或者基于网络传输时必须将其转换成一种精简的格式,即utf-8
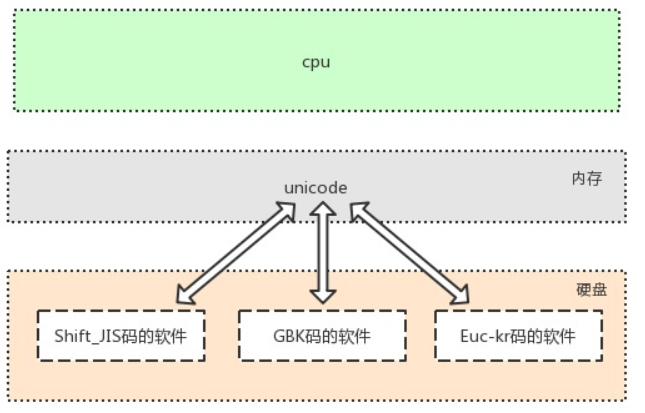
注意:各自老的字符编码都可以转成Unicode,但是不能通过Unicode互转**
# 例:GBK(中文): “哈”------>Unicode------> '00' 二进制
# 二进制:'00'------->Unicode-----> 'かんとう' Shift_JIS(日文)
# 但是转成的日文字符'かんとう',就不一定是中文字符 '哈'的意思了。
因为GBK 和 Shift_JIS 各自和 Unicode 之间的转换关系并不一样,
虽然有对应转换,但是意思就可能不同,就会出现乱码(虽然出现日文或汉字,但是看不懂)
2.2 编码结论
# 1.内存固定使用Unicode,但是我们选择改变的是存入硬盘的编码格式(GBK ,Shift_JIS等)
# 2.文本文件存取乱码问题(内容是什么,就存/取什么格式,最好 'utf-8')
# 3.python解释器默认读文件的编码
python2 默认:ASCII 读文件
python3 默认:utf-8 读文件
2.3 防止出现乱码
# 1.运行python程序(读py文件,并执行)前两个阶段不乱码的核心法则:
执行py文件的前两个阶段就是python解释器读py文件的过程,与文本编辑读文本文件的前两个阶段没人任何区别
"""
若以指定编码存的文件内容,就以同样编码的读文件。
方式:指定文件头修改默认的编码 (主要针对python2,因为解释器默认是ASCII读取)
# coding :编码 (在py文件的首行写)---》但本行内容(英文),是以解释器默认编码读取的。
"""
# 2.运行python程序第三个阶段不乱码的核心法则:
运行第三个阶段时开始识别python语法(经过前两个阶段后py文件的内容都会以unicode格式存放于内存中)
python3 无需操作 -----> 解释器,本身底层就是Unicode在内存中存储str
python2 将字符串前加u:x = u'你好'
解释:表明内存中执行这行代码时,申请内存空间时 强行以Unicode 存储字符串'你好',并指向变量x
# 了解:
python2中,字符串实际是两种类型:
1. 纯字符串类型:'你好'
---->在第三阶段识别语法时,赋值操作会在内存申请空间时,会以文件头中的编码去存储二进制。
---->注:文件头的编码肯定是支持'你好'的编码,不然就和没有文件头一样(解释器默认编码 ASCII)
直接出现了 前两个阶段的 乱码问题,都到不了识别语法的这个阶段(第三阶段)。
2. Unicode类型字符串:u'你好'
---->在第三阶段识别语法时,赋值操作会在内存申请空间时,强制以Unicode编码去存储二进制。
# 总结:
python3 不用管(文件存取都是utf-8,字符串是Unicode)
python2 指定文件头,字符串前加 u

 浙公网安备 33010602011771号
浙公网安备 33010602011771号