kafka作为消息队列代码模拟
1.日志为什么不能用mysql来存储?
直接使用MySQL等关系型数据库存储日志消息确实可以简化开发流程,尤其是在小规模系统中。然而,随着系统规模的扩大和复杂性的增加,使用Kafka等消息队列作为中间件会带来许多优势
-
直接使用MySQL存储日志的优缺点
优点
开发简单:直接插入日志到MySQL表中,开发工作量较小,适合小规模系统。
查询方便:可以直接使用SQL查询日志,适合简单的日志检索和分析。
事务支持:如果日志需要与业务数据强一致性,MySQL的事务特性可以保证数据一致性。
缺点
性能瓶颈:MySQL是关系型数据库,适合结构化数据的存储和查询,但对于高吞吐量的日志写入(如每秒数千条日志),性能可能成为瓶颈。
扩展性差:MySQL的扩展性有限,难以应对海量日志数据的存储和查询需求。
耦合性高:日志写入和业务逻辑耦合在一起,可能会影响业务系统的性能。
实时性差:如果多个系统需要消费日志,MySQL难以支持高效的实时分发。 -
使用Kafka作为中间件的优缺点
优点
高吞吐量:Kafka是为高吞吐量设计的分布式消息队列,能够轻松处理每秒数百万条消息。
解耦生产者和消费者:日志生产者只需要将日志发送到Kafka,消费者可以独立地从Kafka中读取日志,实现系统解耦。
实时性:Kafka支持实时消息分发,多个消费者可以同时消费日志数据,适合实时分析和处理。
扩展性强:Kafka是分布式系统,可以通过增加节点来扩展存储和吞吐能力。
数据持久化:Kafka支持消息持久化(可配置保留时间),即使消费者暂时不可用,数据也不会丢失。
流处理支持:Kafka可以与流处理框架(如Kafka Streams、Flink)集成,支持实时日志分析和处理。
缺点
复杂性增加:引入Kafka会增加系统的复杂性,需要额外的开发和运维成本。
学习曲线:需要熟悉Kafka的概念(如Topic、Partition、Consumer Group等)和配置。
不适合直接查询:Kafka本身不支持复杂的查询,通常需要将日志数据存储到其他系统(如Elasticsearch)中进行查询和分析。
2.ZooKeeper 和 Kafka 的关系?
Kafka 高度依赖 ZooKeeper 来实现集群的管理和协调。没有 ZooKeeper,Kafka 集群将无法正常工作,因为它无法进行 Broker 管理、主题管理、分区和副本管理以及消费者协调等操作。
3.模拟kafka作为日志消息的中间件
模拟之前保证zookeeper和kafka镜像已经成功拉取,并且没有已经运行或运行过的zookeeper和kafka容器
# 启动zookeeper
docker run -d --name zookeeper -p 2181:2181 zookeeper:3.8.1
# 启动kafka
docker run -d --name kafka --network kafka-network -p 9092:9092 \
--env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \
--env KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
confluentinc/cp-kafka:7.4.0
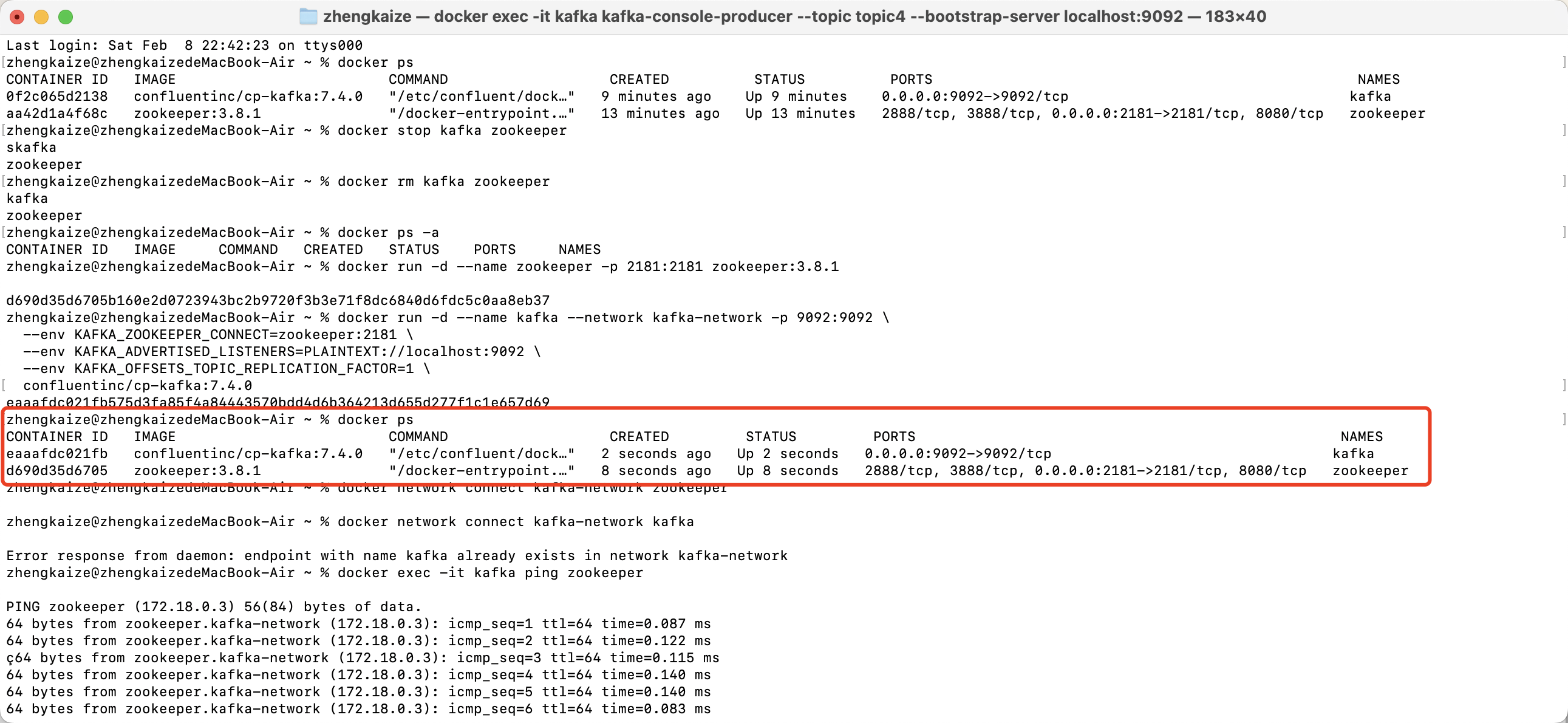
# 将已经 运行中的容器 添加到指定的 Docker 网络
docker network connect kafka-network zookeeper
docker network connect kafka-network kafka
"""
docker network connect 用来将一个已经 运行中的容器 添加到指定的 Docker 网络。这允许容器加入到新网络中,并使得该容器能够与网络中的其他容器通过容器名(DNS方式) 直接通信。如果不执行这一步,容器之间无法通信
"""
# 从kafka中pingzookeeper的网络
docker exec -it kafka ping zookeeper
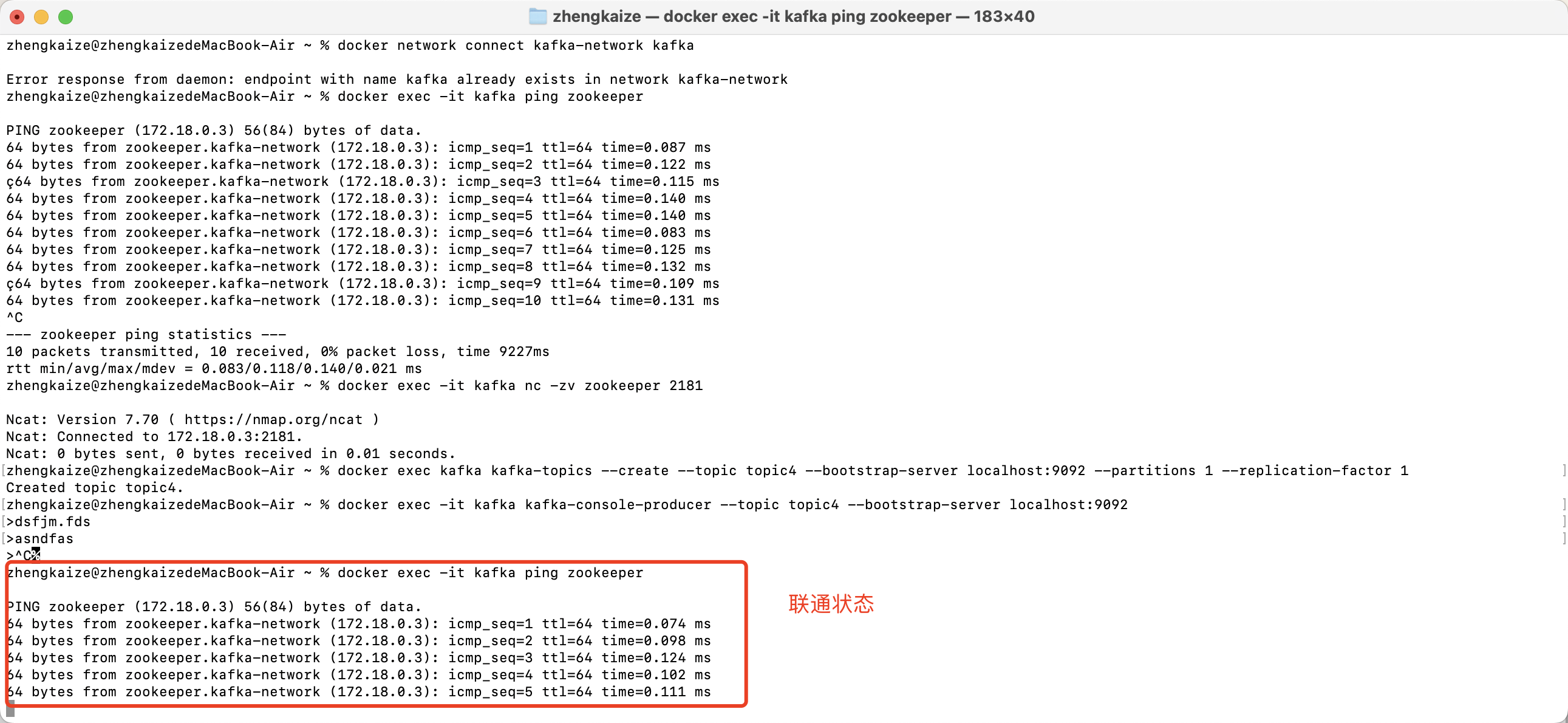
# 查看是否能连接到zookeeper的端口2181
docker exec -it kafka nc -zv zookeeper 2181
# 创建topic
docker exec kafka kafka-topics --create --topic topic名称 --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
# 查看创建的容器
docker exec kafka kafka-topics --list --bootstrap-server localhost:9092
# 进入生产者交互行
docker exec -it kafka kafka-console-producer --topic topic名称 --bootstrap-server localhost:9092
# 在另一个命令行执行,模拟消费者
docker exec -it kafka kafka-console-consumer --topic topic名称 --bootstrap-server localhost:9092 --from-beginning

用python代码向kafka指定容器推送消息:
from kafka import KafkaProducer
import json
# 配置 Kafka 生产者
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
# 定义回调函数
def on_send_success(record_metadata):
print(f"Message sent to {record_metadata.topic} partition {record_metadata.partition} offset {record_metadata.offset}")
def on_send_error(excp):
print(f"Error sending message: {excp}")
# 发送消息到 Kafka
for i in range(20, 31):
message = {'message_id': i, 'content': f'This is message {i}'}
future = producer.send('topic4', value=message)
future.add_callback(on_send_success).add_errback(on_send_error)
# 确保所有消息都被发送
producer.flush()
producer.close()
执行完毕结果:
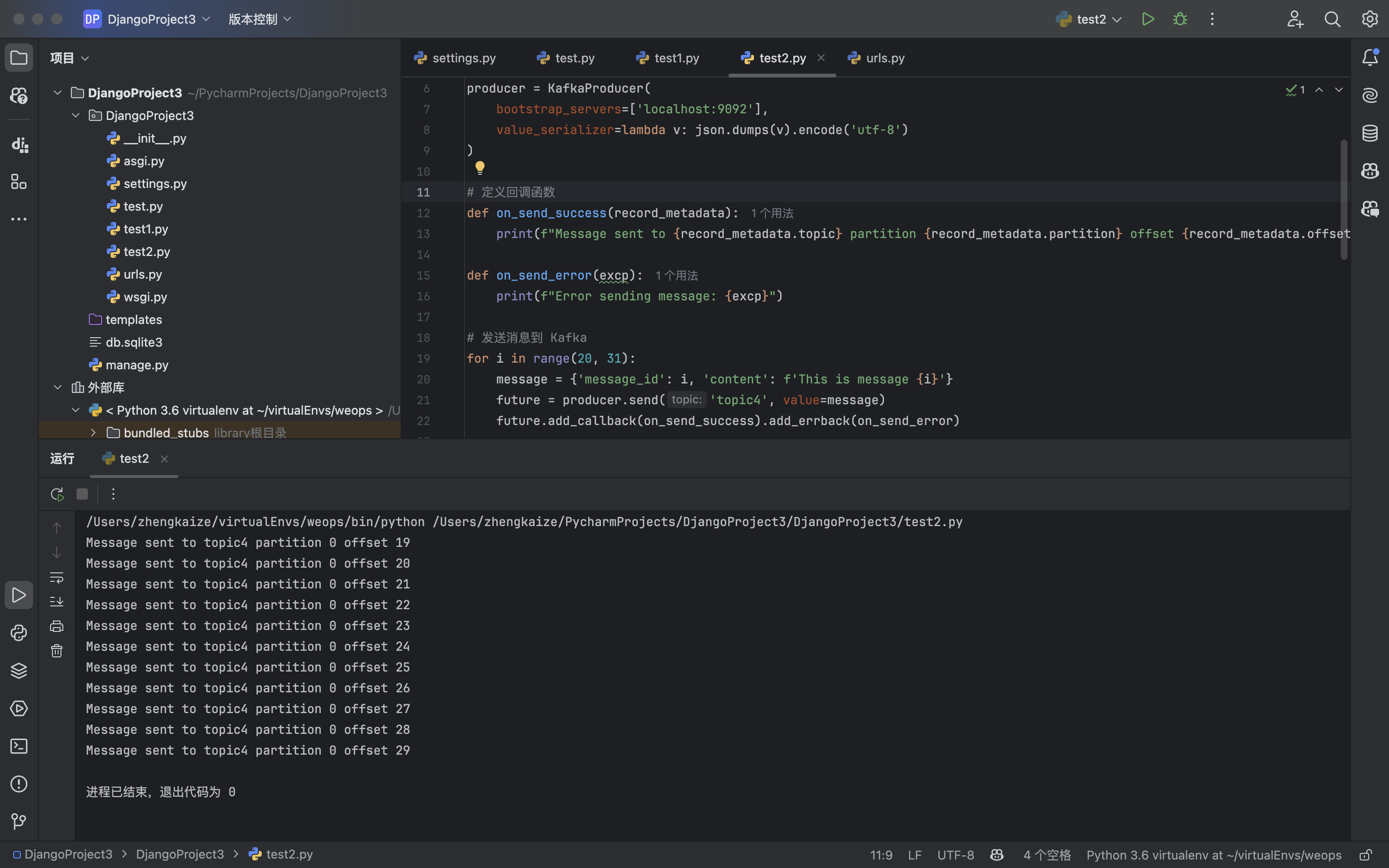
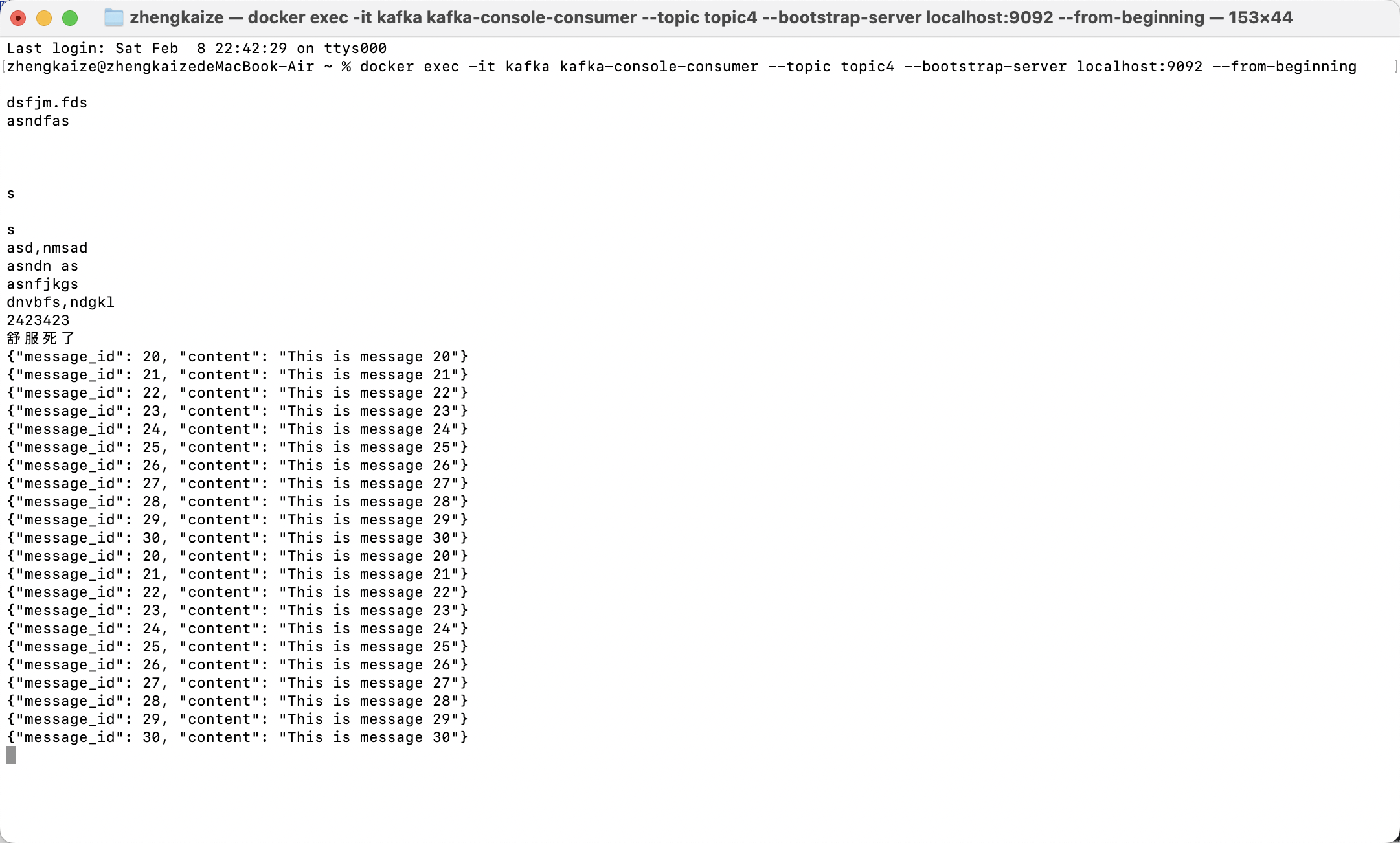
使用python代码模拟消费者接收消息:
from kafka import KafkaConsumer
import json
# 配置 Kafka 消费者
consumer = KafkaConsumer(
'topic4',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest', # 从最早的消息开始消费
value_deserializer=lambda m: m.decode('utf-8'), # 暂时不进行 JSON 反序列化
enable_auto_commit=False
)
# 消费消息
for message in consumer:
# 打印原始消息内容
print(f"Raw Message: {message.value}", type(message.value))
try:
# 尝试进行 JSON 反序列化
data = json.loads(message.value)
print(f"Processed Message: {data}")
except json.JSONDecodeError as e:
# 打印发生错误的消息内容
print(f"Failed to decode JSON: {message.value}. Error: {e}")
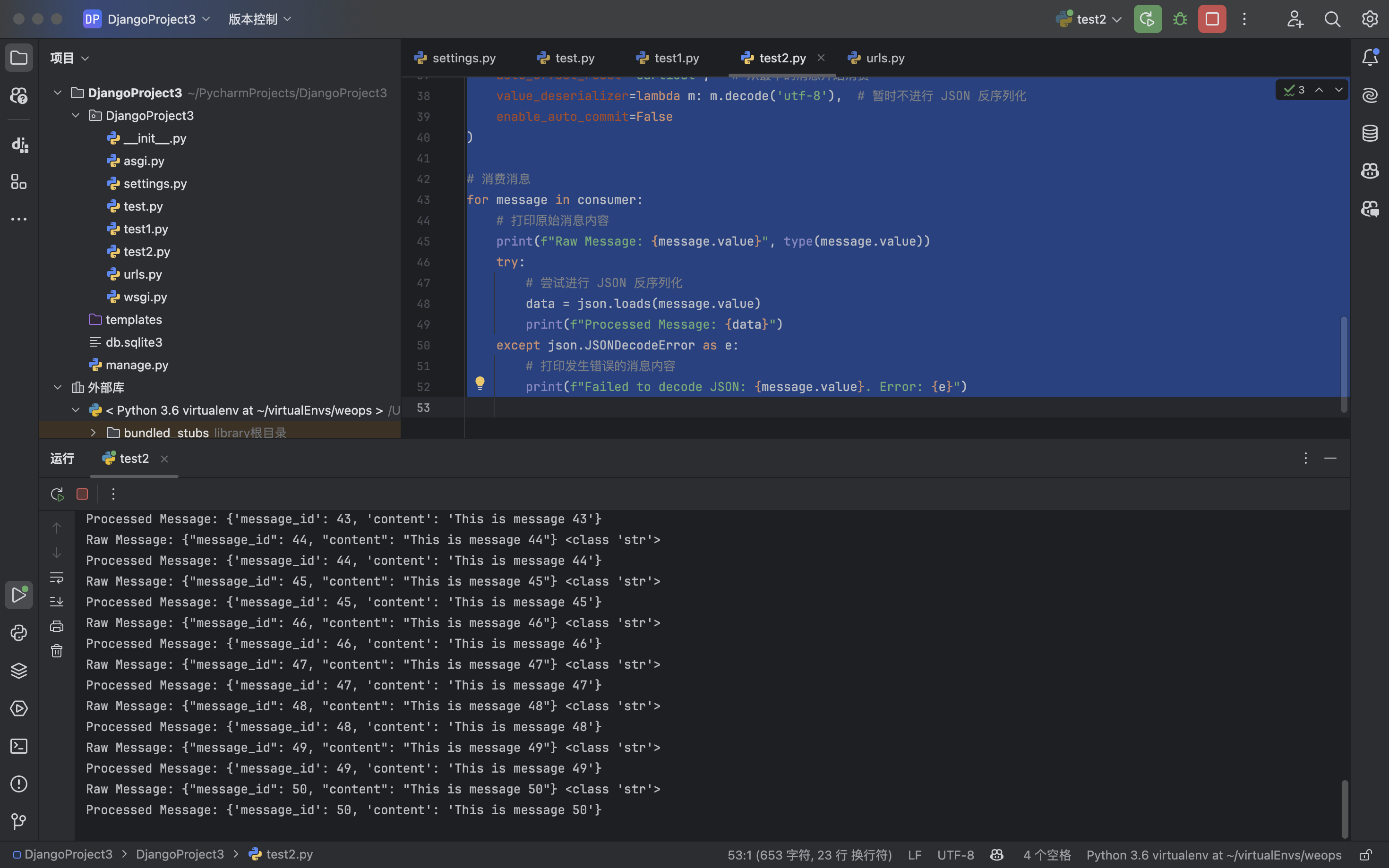
4.怎样发布消息让指定的消费者收到
1.指定一个topic:logss,该topic未做分区处理,一个分区(partition)的消息只能被同一个消费者组内的某一个消费者消费,也就是说:一个分区的消息可以被所有的消费者组接收,但是每个消费者组中只能有一个消费者接收。
消费者组模式
第一种情况:两个消费者组,每个消费者组中各有一个消费者,那么这两个消费者都会接收到来自kafka的消息
log_mgmt/management/commands/consume_parse_logs.py(模拟一个消费者):
import json
from kafka import KafkaConsumer
from django.core.management.base import BaseCommand
class Command(BaseCommand):
help = 'Consume and parse log messages from Kafka'
def handle(self, *args, **kwargs):
consumer = KafkaConsumer(
'logss',
bootstrap_servers=['localhost:9092'],
# auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='parse_group',
value_deserializer=lambda x: x.decode('utf-8'), # 先不进行JSON解析,只做字符解码
)
self.stdout.write("Parser consumer started...")
for message in consumer:
raw_log = message.value
try:
log = json.loads(raw_log) # 尝试解析JSON
self.stdout.write(f"Parsed log: {log}")
# 解析后执行相关逻辑
except json.JSONDecodeError as e:
self.stdout.write(f"Failed to parse log message as JSON, raw log: {raw_log}")
log_mgmt/management/commands/consume_store_logs.py(模拟另一个消费者):
import json
from kafka import KafkaConsumer
from django.core.management.base import BaseCommand
from log_mgmt.models import RawLog
class Command(BaseCommand):
help = 'Consume and store raw log messages from Kafka'
def handle(self, *args, **kwargs):
consumer = KafkaConsumer(
'logss',
bootstrap_servers=['localhost:9092'],
enable_auto_commit=True,
group_id='store_group',
)
self.stdout.write("Storage consumer started...")
for message in consumer:
try:
data = message.value.decode('utf-8')
# 尝试将消息解析为JSON
try:
parsed_data = json.loads(data)
self.stdout.write(f"JSON data: {parsed_data}")
except json.JSONDecodeError:
self.stdout.write(f"Raw non-JSON data: {data}")
# 如果RawLog需要是一个json里面有data字段
RawLog.objects.create(data=data)
self.stdout.write(f"Stored log: {data}")
except Exception as e:
self.stderr.write(f"Failed to store log message: {e}")
在两个不同的终端分别执行:python manage.py consume_parse_logs、python manage.py consume_store_logs
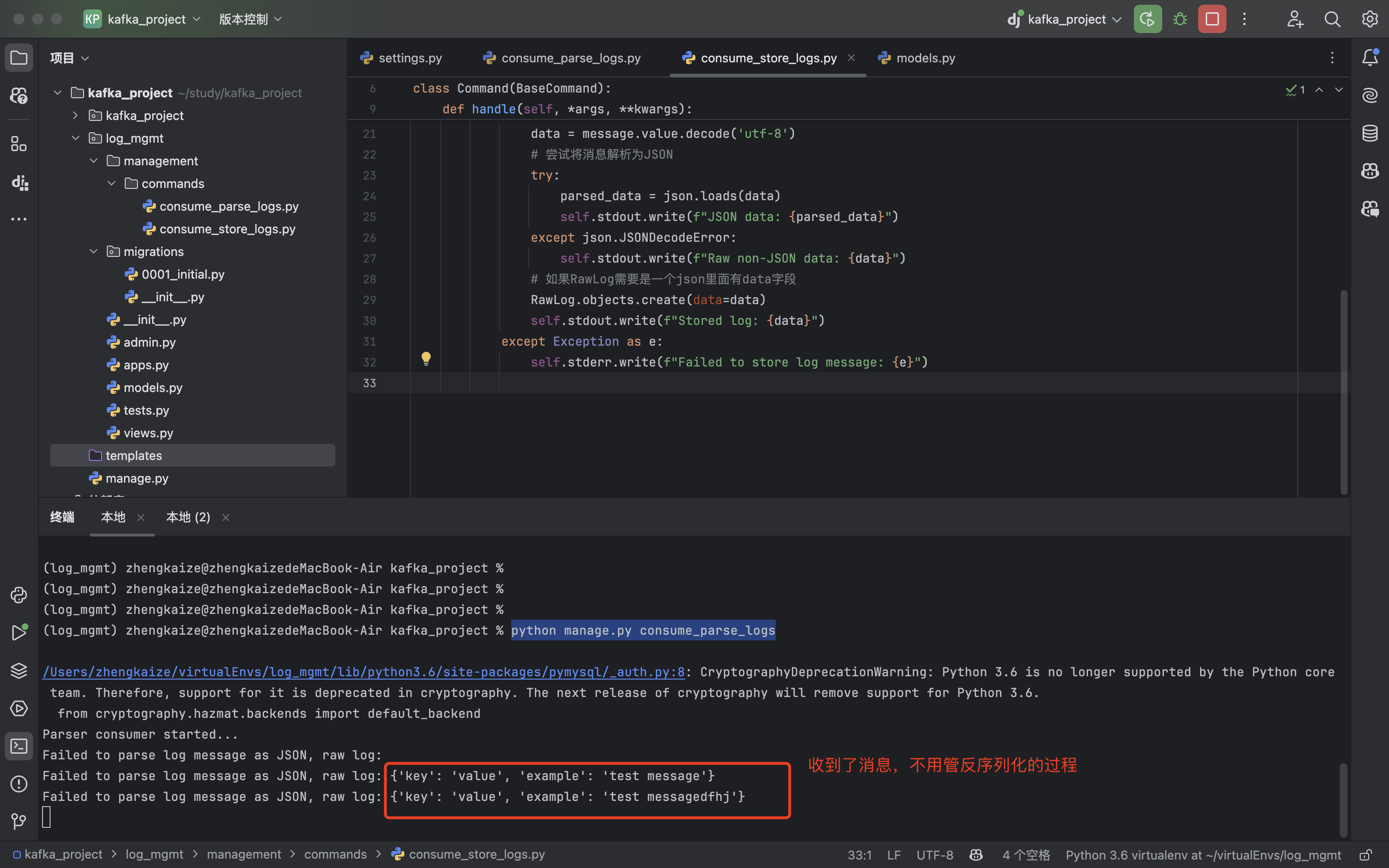
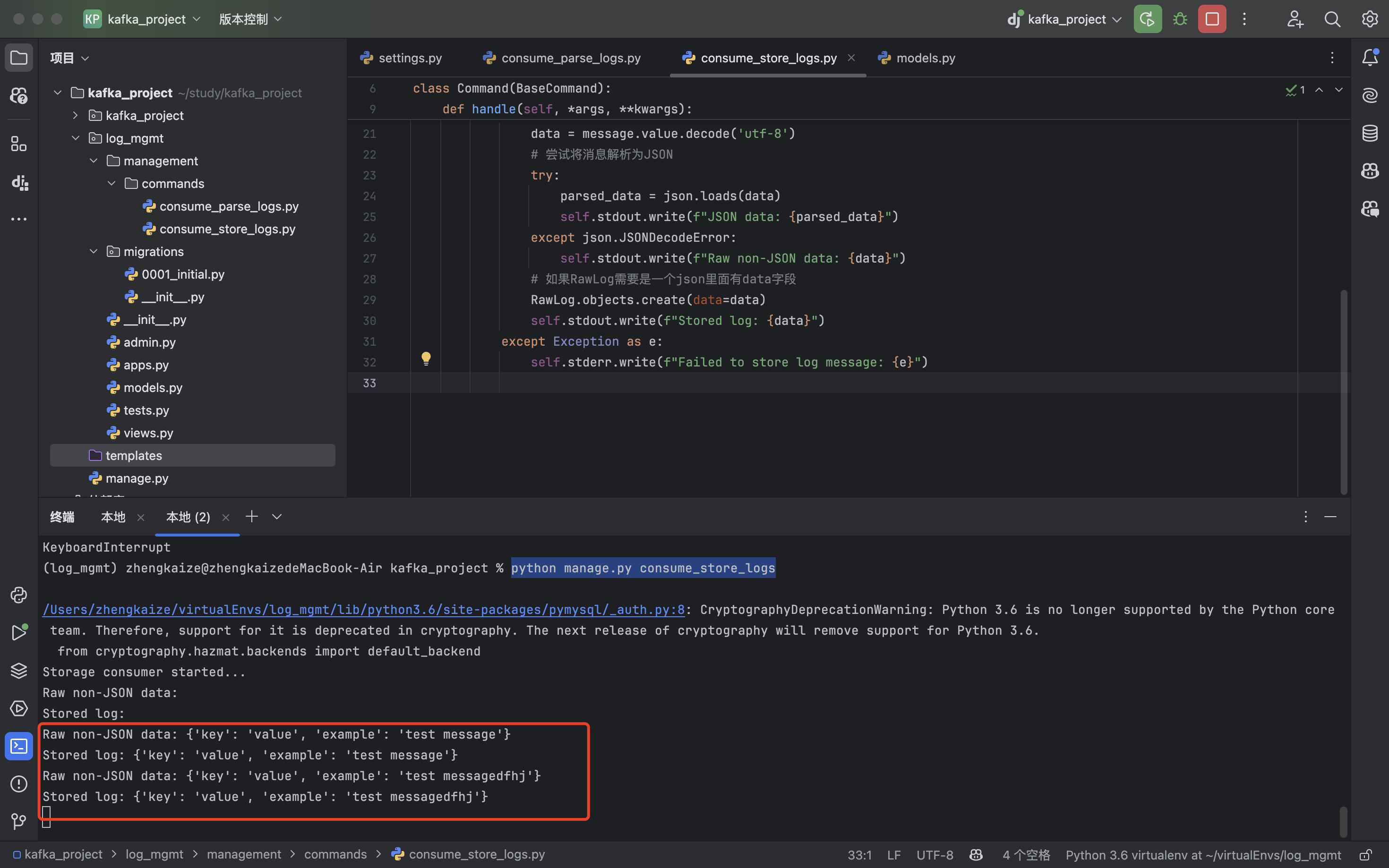
发现两个消费者都收到了信息
第二种情况:两个消费者组,每个消费者组中各有两个消费者,那么每个消费者组中都会只有一个消费者接收到消息:
consume_parse_logs、consume_parse_logs1和上面consume_parse_logs的代码一样
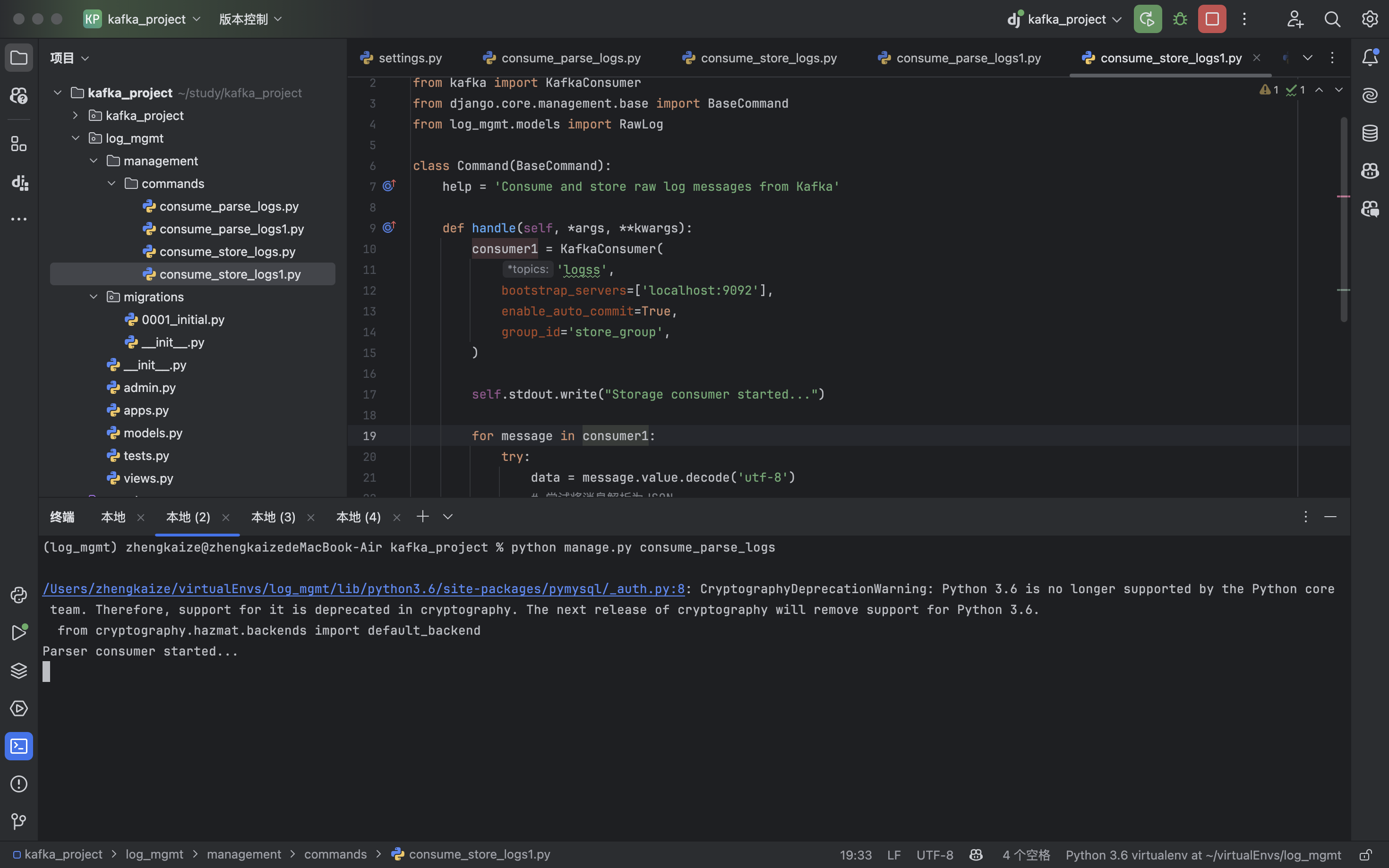
python manage.py consume_parse_logs1:(收到消息了)
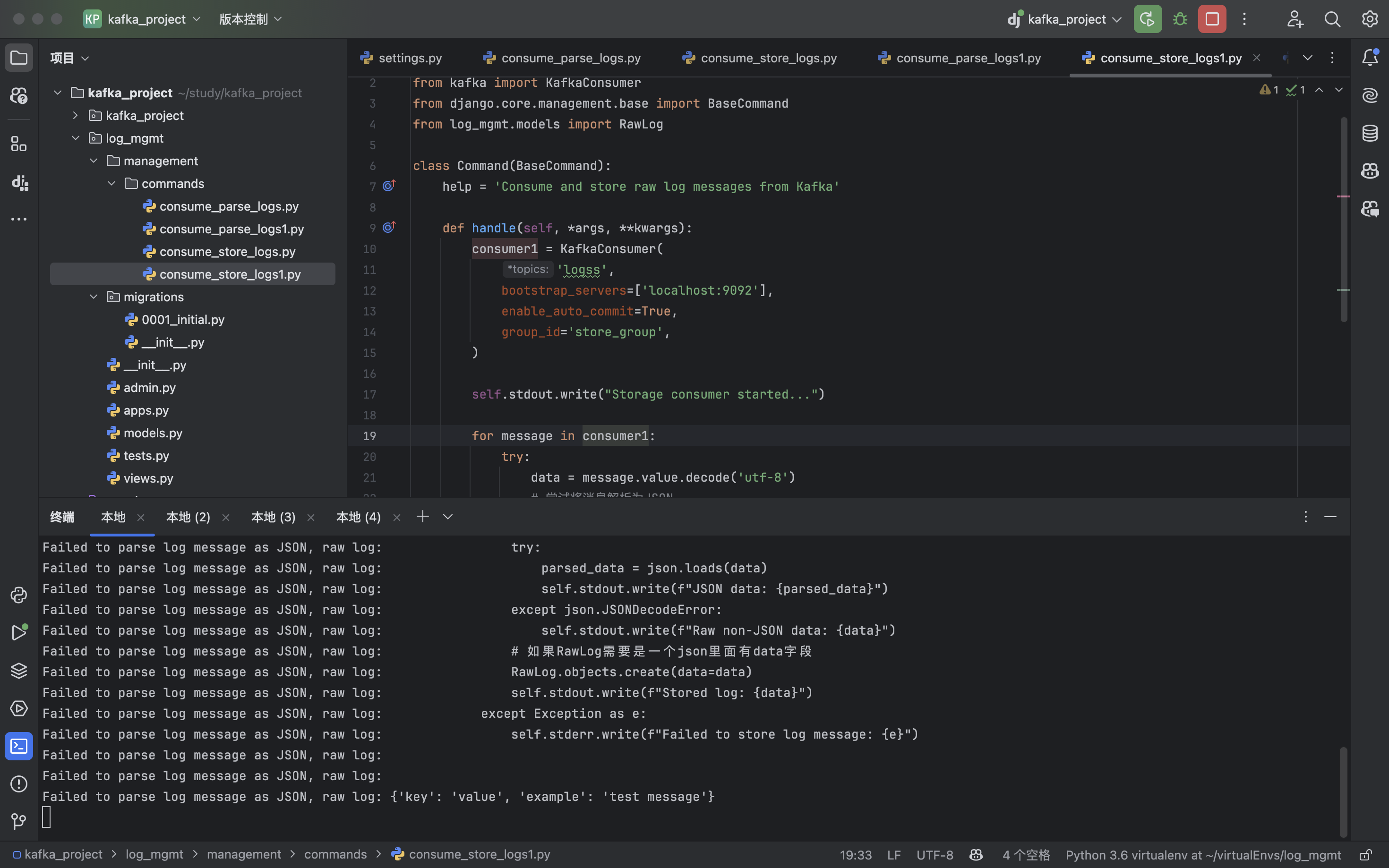
python manage.py consume_parse_logs:(没收到消息)
consume_store_logs、consume_store_logs1和上面consume_store_logs代码一样
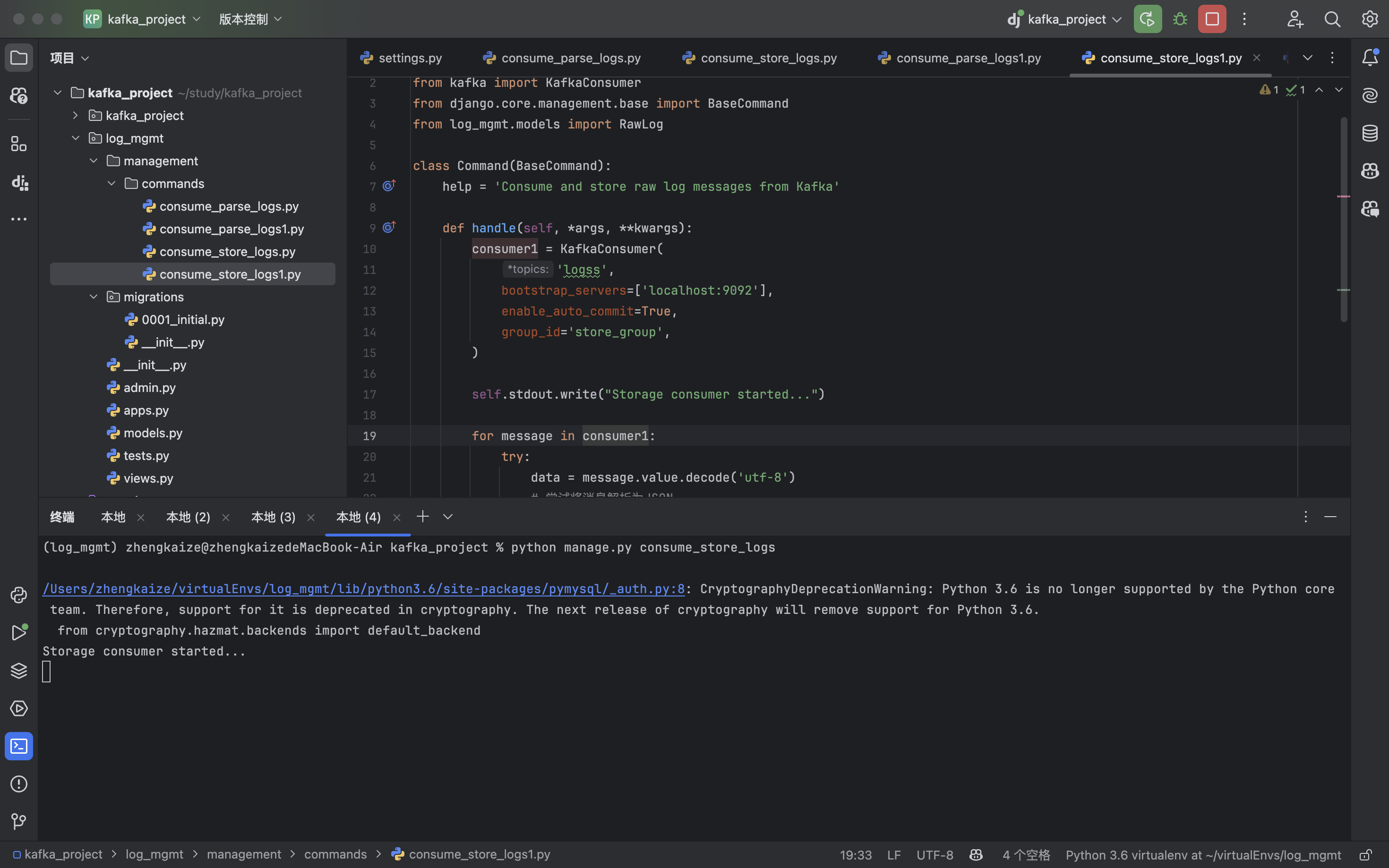
python manage.py consume_store_logs1:(收到消息了)
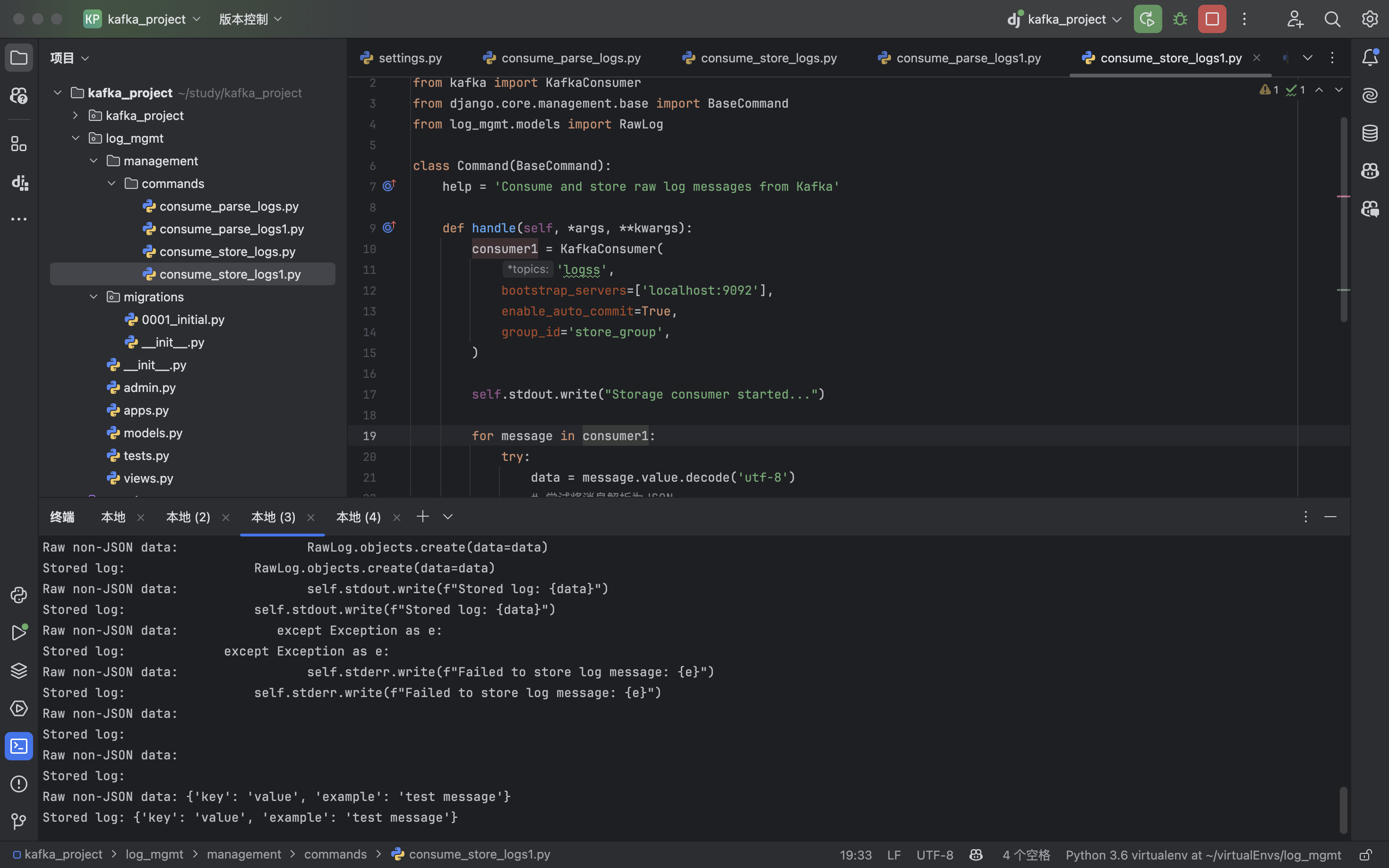
python manage.py consume_store_logs:(没收到消息)
第三种情况:同一个消费者组(group_id一一致),那么只会有其中一个消费者收到消息
如果两个消费者在同一个消费者组中,Kafka 会随机分配消费者负责特定分区的消息。这次只用consume_store_logs和consume_parse_logs来测试:
consume_parse_logs.py:
import json
from kafka import KafkaConsumer
from django.core.management.base import BaseCommand
class Command(BaseCommand):
help = 'Consume and parse log messages from Kafka'
def handle(self, *args, **kwargs):
consumer = KafkaConsumer(
'logss',
bootstrap_servers=['localhost:9092'],
# auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='consumer_group',
value_deserializer=lambda x: x.decode('utf-8'), # 先不进行JSON解析,只做字符解码
)
self.stdout.write("Parser consumer started...")
for message in consumer:
raw_log = message.value
try:
log = json.loads(raw_log) # 尝试解析JSON
self.stdout.write(f"Parsed log: {log}")
# 解析后执行相关逻辑
except json.JSONDecodeError as e:
self.stdout.write(f"Failed to parse log message as JSON, raw log: {raw_log}")
consume_store_logs.py:
import json
from kafka import KafkaConsumer
from django.core.management.base import BaseCommand
from log_mgmt.models import RawLog
class Command(BaseCommand):
help = 'Consume and store raw log messages from Kafka'
def handle(self, *args, **kwargs):
consumer = KafkaConsumer(
'logss',
bootstrap_servers=['localhost:9092'],
enable_auto_commit=True,
group_id='consumer_group',
)
self.stdout.write("Storage consumer started...")
for message in consumer:
try:
data = message.value.decode('utf-8')
# 尝试将消息解析为JSON
try:
parsed_data = json.loads(data)
self.stdout.write(f"JSON data: {parsed_data}")
except json.JSONDecodeError:
self.stdout.write(f"Raw non-JSON data: {data}")
# 如果RawLog需要是一个json里面有data字段
RawLog.objects.create(data=data)
self.stdout.write(f"Stored log: {data}")
except Exception as e:
self.stderr.write(f"Failed to store log message: {e}")
consume_store_logs收到了消息:
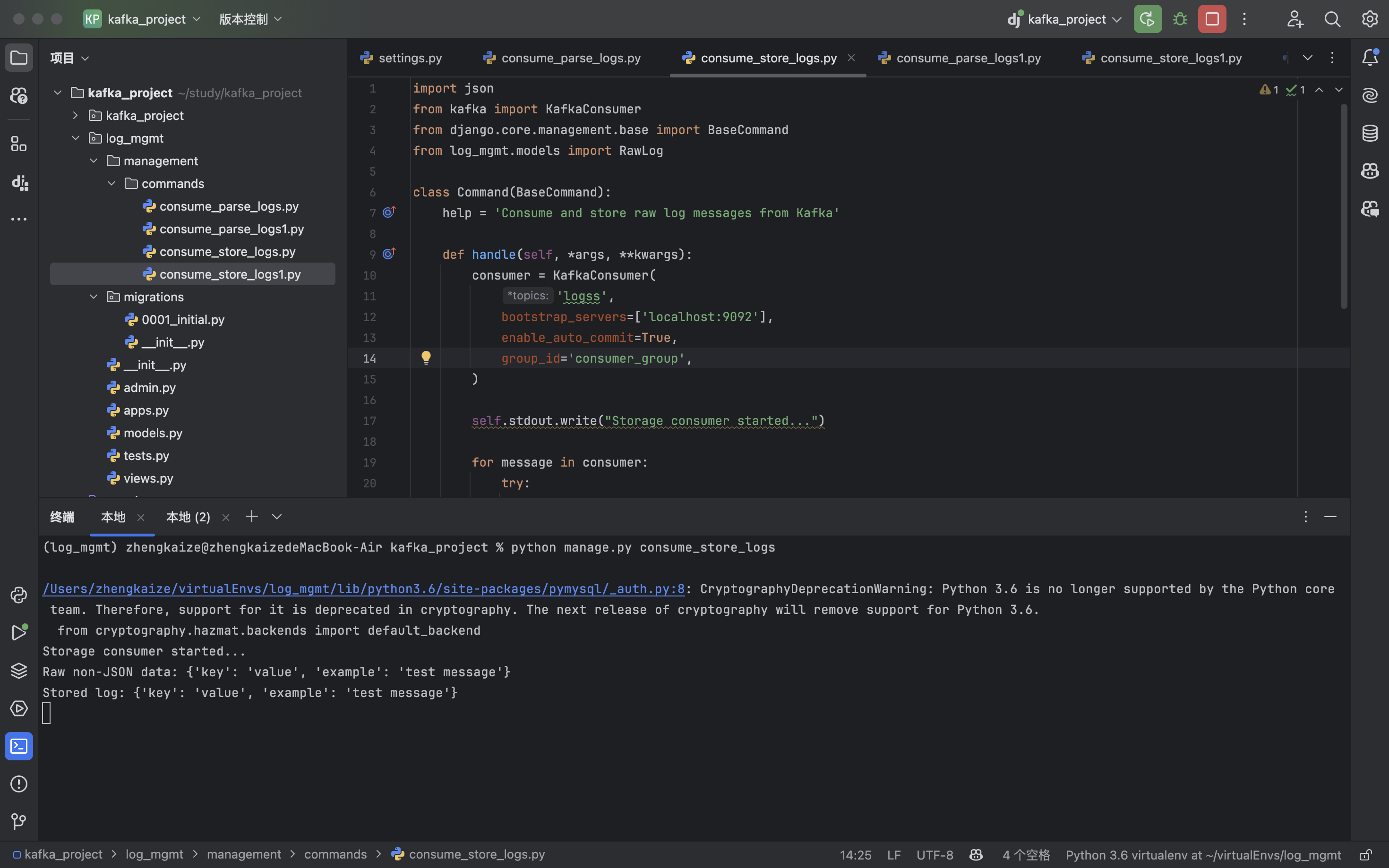
consume_parse_logs.py没收到消息:
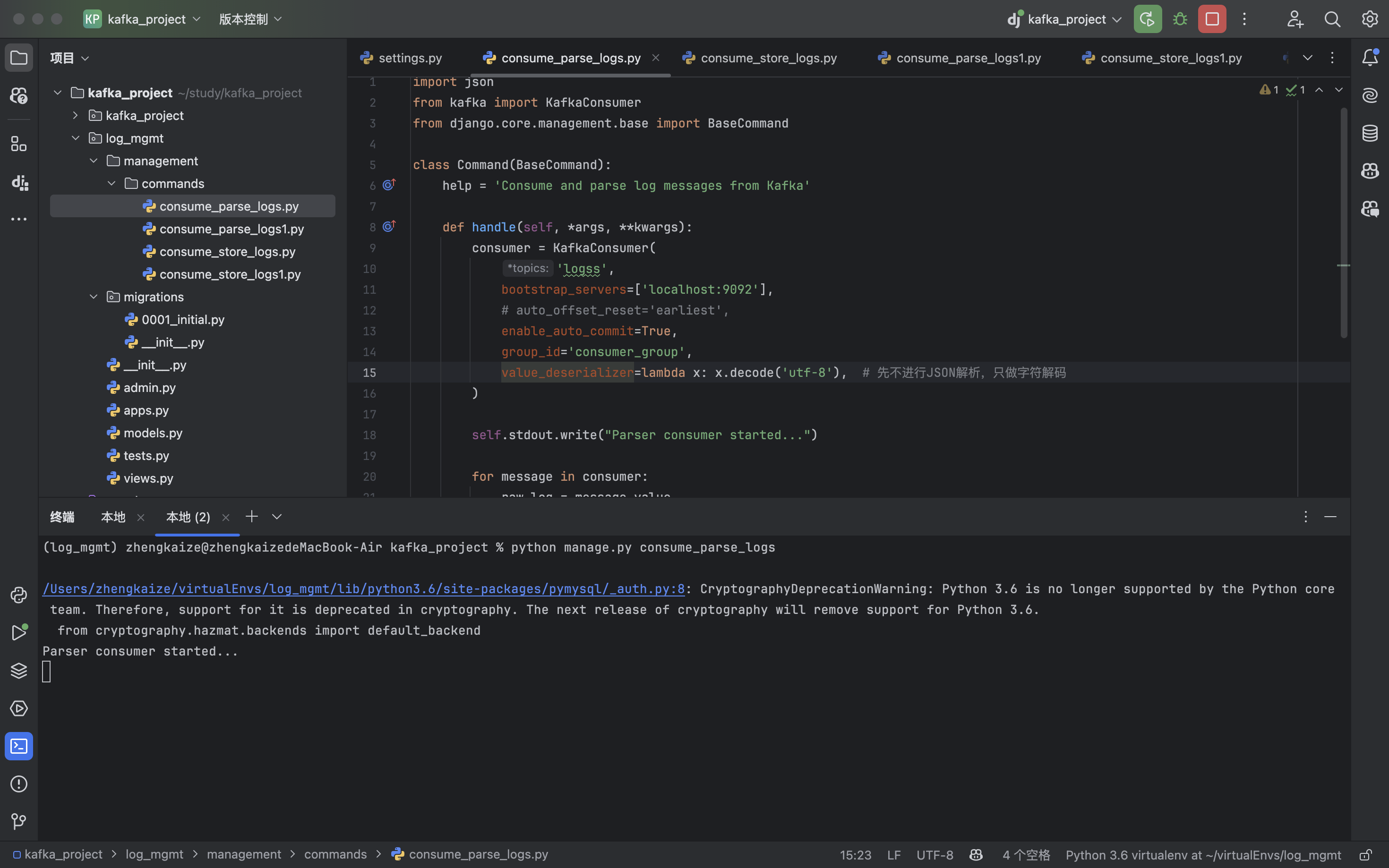
手动分配模式
检查kafka的分区:
终端执行
docker exec -it kafka kafka-topics --describe --topic logss --bootstrap-server localhost:9092
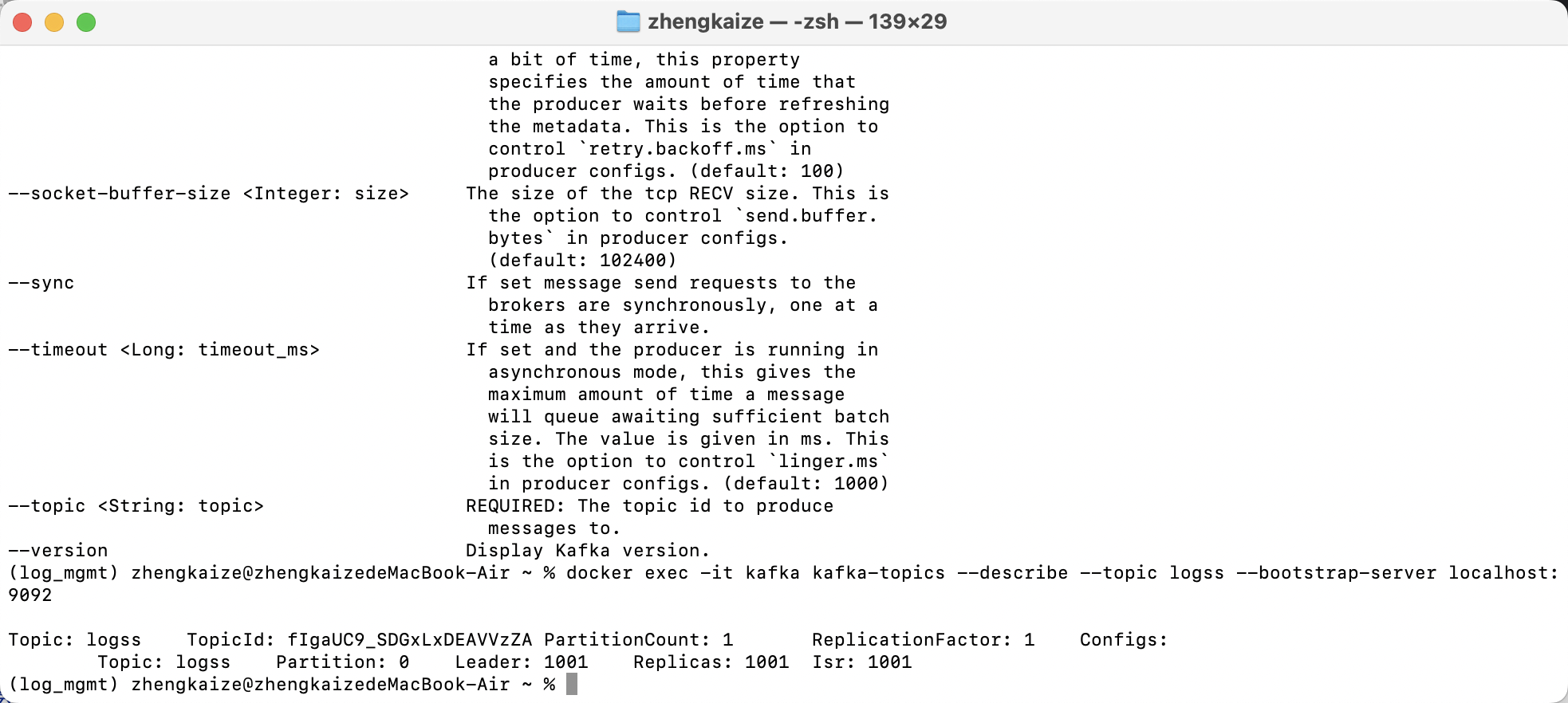
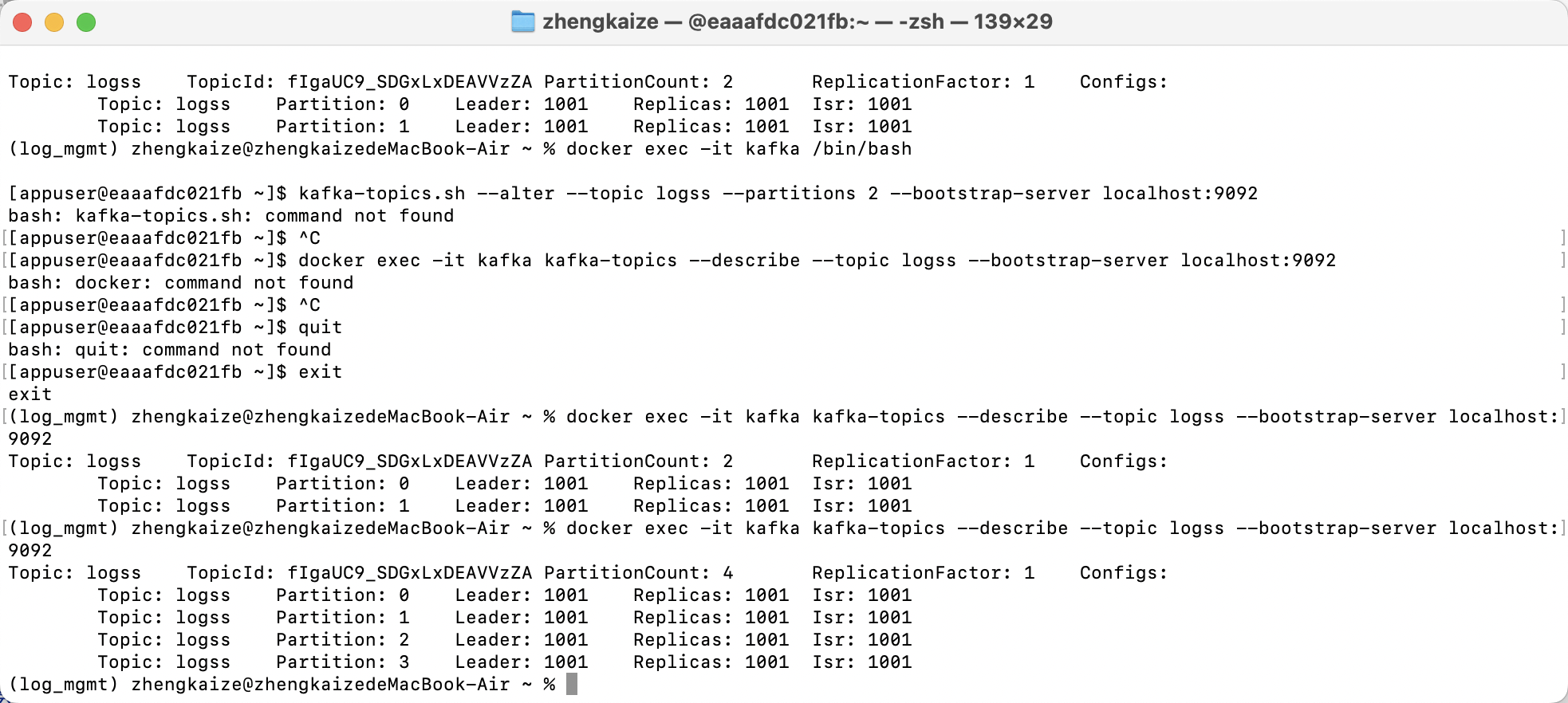
发现只有0这一个分区,现在用python代码创建分区:
from kafka.admin import KafkaAdminClient, NewPartitions
# 创建KafkaAdminClient实例
admin_client = KafkaAdminClient(
bootstrap_servers="localhost:9092",
client_id='test'
)
topic_name = "logss"
new_partition_count = 4 # 新分区总数,必须大于当前分区数,执行之后总共有4个分区
# 构建NewPartitions对象
new_partitions = {topic_name: NewPartitions(total_count=new_partition_count)}
# 增加分区
admin_client.create_partitions(new_partitions)
admin_client.close()
接下来向指定分区推消息:
from kafka import KafkaProducer
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
key_serializer=lambda k: k.encode('utf-8'),
value_serializer=lambda v: v.encode('utf-8')
)
# 直接指定消息发送到分区 0
producer.send(
topic='logss',
key='key-for-partition-1', # 可选:用于分区选择
value='{"name": "maxjsahfkj"}',
partition=1
)
producer.flush()
producer.close()
consume_store_logs.py:(接收分区1的消息:)
import json
from kafka import KafkaConsumer, TopicPartition
from django.core.management.base import BaseCommand
from log_mgmt.models import RawLog
class Command(BaseCommand):
help = 'Consume and store raw log messages from Kafka'
def handle(self, *args, **kwargs):
consumer = KafkaConsumer(
bootstrap_servers=['localhost:9092'],
enable_auto_commit=True,
group_id='consumer_group',
)
# 直接通过 assign 方式订阅指定分区
consumer.assign([TopicPartition('logss', 1)])
self.stdout.write("Storage consumer started...")
for message in consumer:
try:
data = message.value.decode('utf-8')
# 尝试将消息解析为JSON
try:
parsed_data = json.loads(data)
self.stdout.write(f"JSON data: {parsed_data}")
except json.JSONDecodeError:
self.stdout.write(f"Raw non-JSON data: {data}")
# 如果RawLog需要是一个json里面有data字段
RawLog.objects.create(data=data)
self.stdout.write(f"Stored log: {data}")
except Exception as e:
self.stderr.write(f"Failed to store log message: {e}")
consume_parse_logs.py:(接收分区0的消息)
import json
from kafka import KafkaConsumer, TopicPartition
from django.core.management.base import BaseCommand
class Command(BaseCommand):
help = 'Consume and parse log messages from Kafka'
def handle(self, *args, **kwargs):
consumer = KafkaConsumer(
bootstrap_servers=['localhost:9092'],
# auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='consumer_group',
value_deserializer=lambda x: x.decode('utf-8'), # 先不进行JSON解析,只做字符解码
)
# 直接通过 assign 方式订阅指定分区
consumer.assign([TopicPartition('logss', 0)])
self.stdout.write("Parser consumer started...")
for message in consumer:
raw_log = message.value
try:
log = json.loads(raw_log) # 尝试解析JSON
self.stdout.write(f"Parsed log: {log}")
# 解析后执行相关逻辑
except json.JSONDecodeError as e:
self.stdout.write(f"Failed to parse log message as JSON, raw log: {raw_log}")
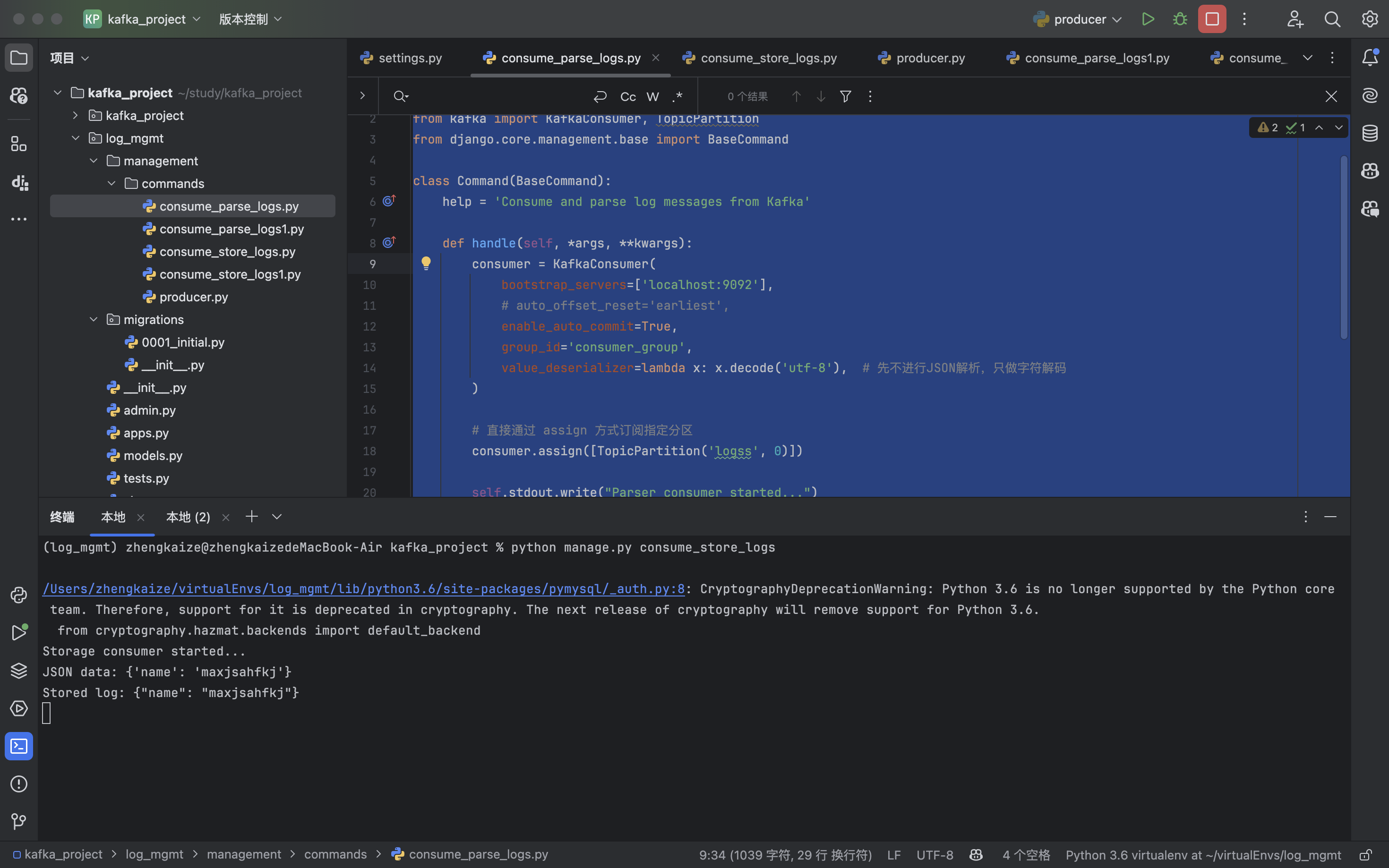
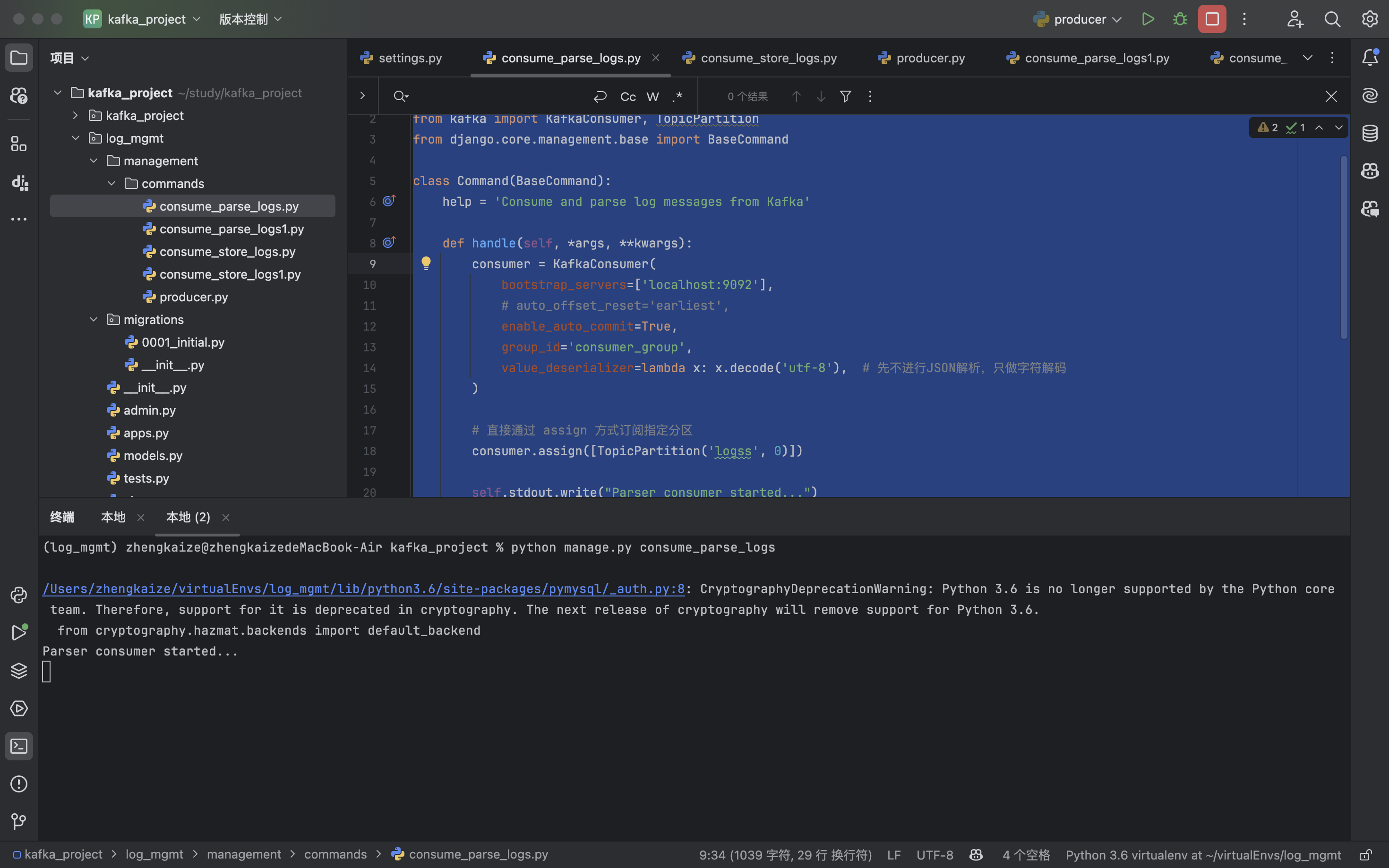
这样就可以实现指定消费者接收消息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号