redis-安装、启动、数据类型、事务、消息队列
1.redis介绍
1.特性:10w ops(每秒10w读写),数据存在内存中,c语言实现,单线程模型
2.持久化:rdb和aof
3.5大数据结构:字符串、列表、哈希、集合、有序集合
基于tcp通信协议,各大编程语言都支持
功能丰富:发布订阅(消息) Lua脚本,事务(pipeline)
3.0版本以后支持分布式
2.安装
1.下载源代码:
wget http://download.redis.io/releases/redis-6.2.9.tar.gz
# 如果没有需要首先执行 yum install wget

2.解压
tar -xzf redis-6.2.9.tar.gz
3.建立软链接
ln -s redis-6.2.9 redis # 这样做是为了做软链接

4.在redis目录下执行:
make&&make install
3.删除
1、查看redis进程;
ps aux|grep redis
2、kill掉进程;
kill 进程id
3、进入到redis目录
cd /usr/local/
4、删除redis对应的文件
rm -f /usr/local/redis/bin/redis*
rm -f /usr/local/bin/redis*
5、删除对应的文件
rm -rf redis
4.redis启动方式
4.1 最简启动
在redis/src目录下执行:
redis-server

再打开一个虚拟机,可以看到redis已经在执行:
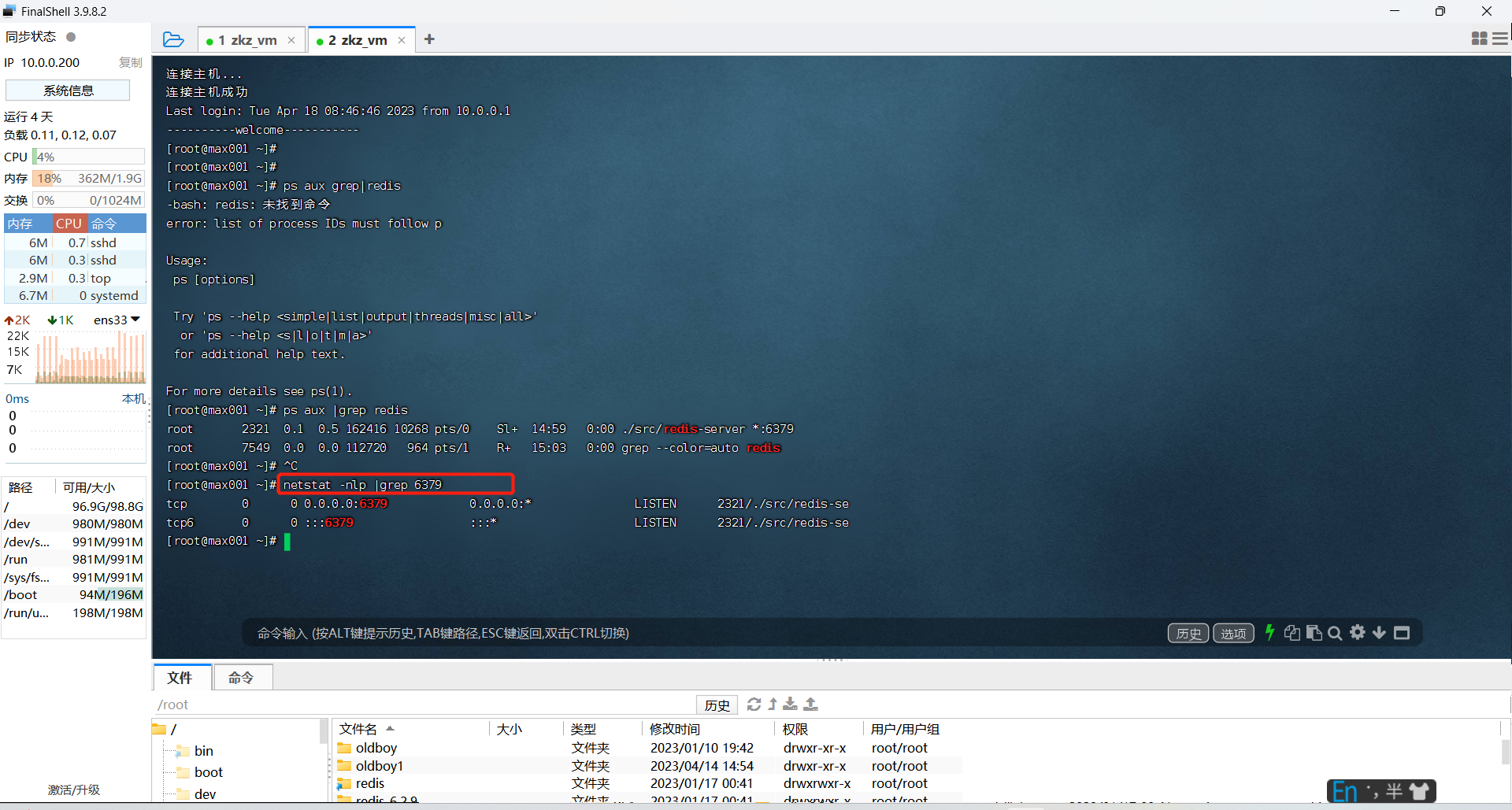
ps aux |grep redis # 查看进程,是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来

netstat -nlp |grep 6379
# 没有netstat需要首先执行:yum install net-tools -y下载
查看端口占用情况:
4.2 动态参数启动
redis-serve --port 6380 #启动,监听6380端口
5.客户端连接命令
# redis-cli -h 地址 -p端口
redis-cli -h 127.0.0.1 -p 6379

启动时直接返回redis运行情况:可以写一个运维管理系统,监控连接redis对的情况
redis-cli -h 127.0.0.1 -p 6379 info
查看客户端能否连接到服务端:
redis-cli -h 127.0.0.1 -p 6379 ping

查看redis配置信息(需要连上服务端才能查看):
CONFIG GET *
# port:端口
# daemonize:是否当做守护进程运行
6.哈希类型
###1---hget,hset,hdel
hget key field #获取hash key对应的field的value 时间复杂度为 o(1)
hset key field value #设置hash key对应的field的value值 时间复杂度为 o(1)
hdel key field #删除hash key对应的field的值 时间复杂度为 o(1)
#测试
hset user:1:info age 23
hget user:1:info ag
hset user:1:info name lqz
hgetall user:1:info
hdel user:1:info age
###2---hexists,hlen
hexists key field #判断hash key 是否存在field 时间复杂度为 o(1)
hlen key #获取hash key field的数量 时间复杂度为 o(1)
hexists user:1:info name
hlen user:1:info #返回数量
###3---hmget,hmset
hmget key field1 field2 ...fieldN #批量获取hash key 的一批field对应的值 时间复杂度是o(n)
hmset key field1 value1 field2 value2 #批量设置hash key的一批field value 时间复杂度是o(n)
###4--hgetall,hvals,hkeys
hgetall key #返回hash key 对应的所有field和value 时间复杂度是o(n)
hvals key #返回hash key 对应的所有field的value 时间复杂度是o(n)
hkeys key #返回hash key对应的所有field 时间复杂度是o(n)
###小心使用hgetall
##1 计算网站每个用户主页的访问量
hincrby user:1:info pageview count
##2 缓存mysql的信息,直接设置hash格式
##其他操作 hsetnx,hincrby,hincrbyfloat
hsetnx key field value #设置hash key对应field的value(如果field已存在,则失败),时间复杂度o(1)
hincrby key field intCounter #hash key 对英的field的value自增intCounter 时间复杂度o(1)
hincrbyfloat key field floatCounter #hincrby 浮点数 时间复杂度o(1)
7.列表类型
有序队列,可以从左侧添加,右侧添加,可以重复,可以从左右两边弹出
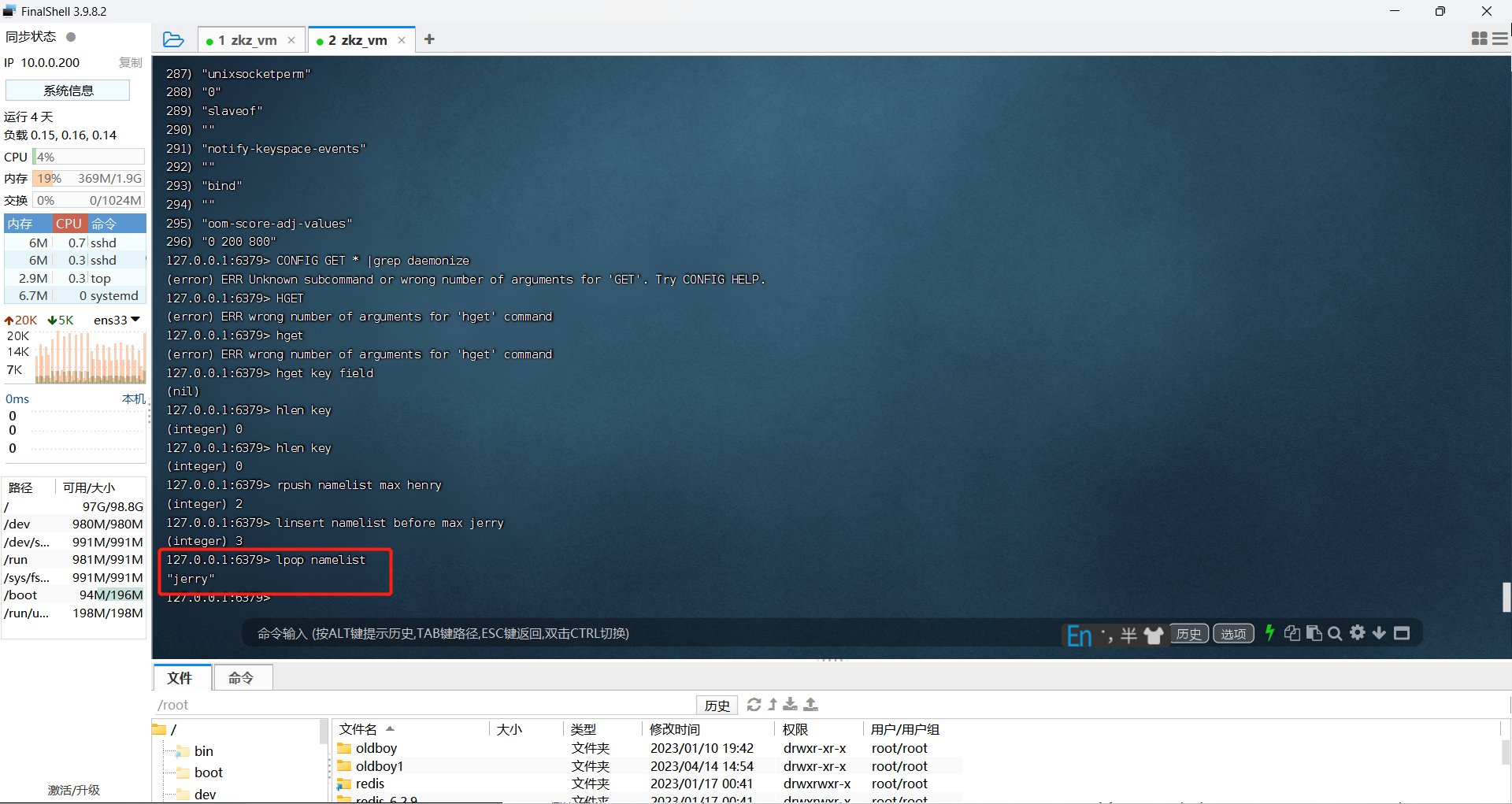
rpush namelist max henry # lpush是从左边插入

将jerry插入到max左边:
linsert namelist before max jerry
删除操作:lpop、rpop删除并且弹出:
lpop namelist
# 将namelist最左边的元素弹出,rpop是从右侧弹出
删除操作:
lrem key count value
key 是列表的键名
value 是列表中的元素名
count=0 删除列表中所有的value元素
count>0 从左到右,删除count个value元素(如果不够有几个就删几个)
count<0 从右到左,删除abs(count)个value元素(如果不够有几个删几个)
lrem namelist 0 max
# 删除namelist中所有的max
lrem namelist -2 max
# 删除namelist中2个max,从右到左,如果不够两个有几个删几个
修剪列表:ltrim key start stop
key 列表名
将列表从start位切到stop位
ltrim namelist 2 5
查询操作:
lrange namelist start stop
查到列表中从start到stop的值(包含首尾)
lrange namelist 2 4

查询列表中所有元素:
lrange namelist 0 -1 # 数字都代表索引

查找列表中指定索引的元素:
lindex namelist 2 # 查找namelist中索引为2的元素

实现timeline功能:例如:列表当中可以存放项目当中例如某个人的任务、某个领导的待审批事项,在缓存中查询的速度要比在mysql中过滤、筛选速度快;关注的人更新了消息,按照时间排序展示在某个人的缓存列表中
利用redis列表也可以实现消息队列的功能:
#要实现栈的功能
lpush+lpop
#实现队列功能
lpush+rpop
#固定大小的列表
lpush+ltrim
#消息队列
lpush+brpop
brpop用法:
brpop 列表key 超时时间
如果能取出值返回的是列表的键名以及弹出的元素。如果取不到值则在此处阻塞超时时间秒,然后报错。如果在阻塞时间消息队列中传入了值,那么会停止阻塞,把消息队列中的值取出
brpop namelist 3

消息队列简单实现:
views.py:
# POST访问redis_test1时,会从请求体中拿到content内容
def redis_test1(request):
content = json.loads(request.body).get('content')
from redis import Redis
'''redis设置了密码之后需要上传密码'''
conn = Redis(host='127.0.0.1', port=6379, password='123456')
conn.lpush('content', content)
return HttpResponse('消息发送成功')
def redis_test2(request):
from redis import Redis
conn = Redis(host='127.0.0.1', port=6379, password='123456')
'''brpop第一个参数是redis键,第二个参数是阻塞的秒数'''
content = conn.brpop('content', 10)[1] # brpop是一个拿到的是一个元组,第一个元素是content,第二个元素才是content最右边的值
print(content)
return HttpResponse(content)
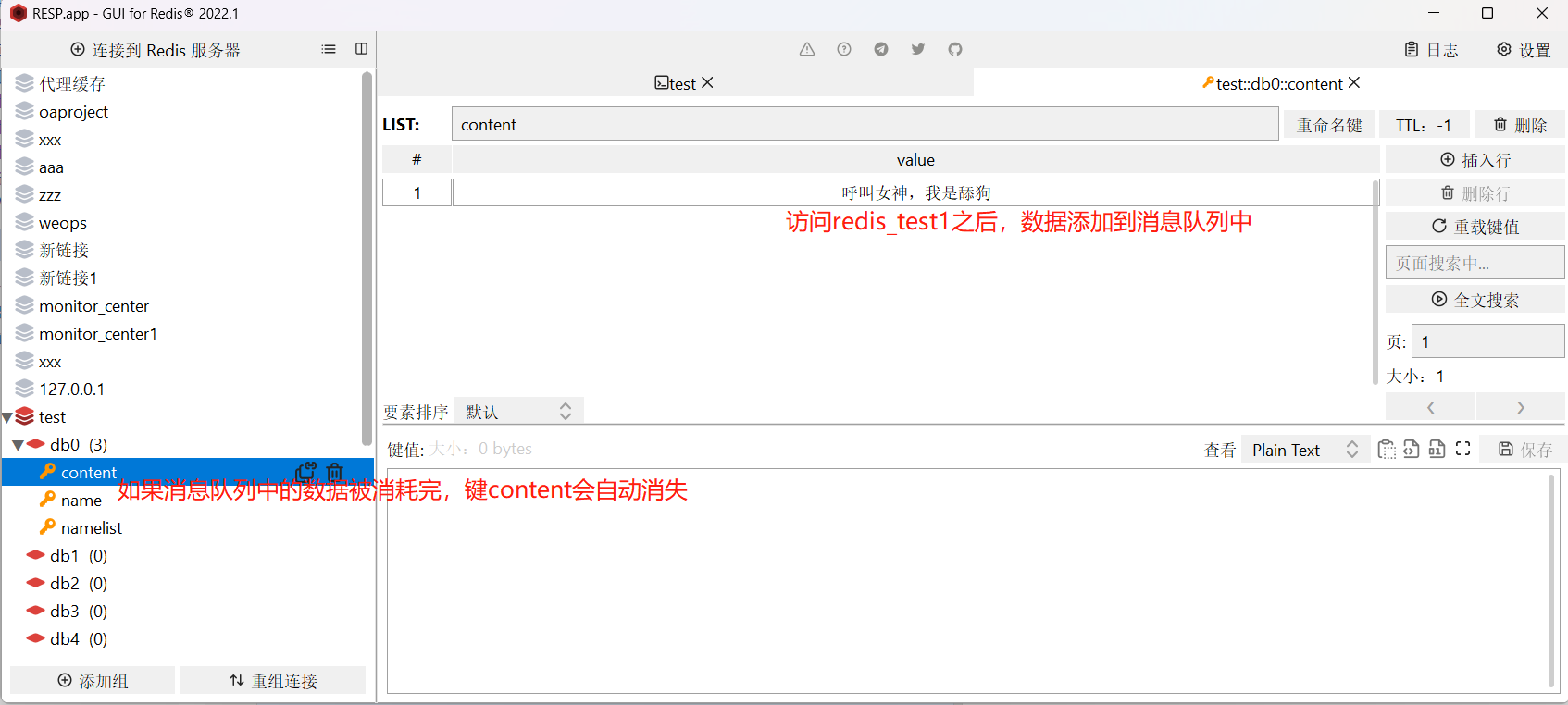
这是就能实现一个神奇的效果:brpop阻塞时间是10秒,如果消息队列中没有数据,当我们在阻塞的若干秒(10秒之前)给消息队列添加了数据,那么阻塞可以立即停止,拿到数据

8.集合类型
特点:无序、无重复、集合间操作
1.集合添加值:
sadd 集合名 元素(可以写一个元素,也可以写多个)
sadd boys max
sadd boys qqq wwww
2.查看集合长度
scard 集合名
scard boys

3.删除元素
srem 集合名 元素名
srem boys max # 返回结果是1
# 删除一个不存在的结果是0
4.判断元素在不在集合内
sismember 集合名 元素名
sismember boys max # 如果不存在返回0,存在返回1
5.随即从集合中取出任意个元素,不会破坏集合中的元素(可以做抽奖效果)
srandmember boys 3
6.随机选择一个元素删除,并且弹出
spop 集合名
spop boys
7.获取集合中所有元素
smembers 集合名
smembers boys
8.集合交并补:
以这两个集合为准做交并补:

sidff A B:求A对B的补集(A中除去A和B的交集)
sdiff boys boyss

求两个集合的交集:sinter A B
sinter boys boyss

求两个集合的并集:
sunion boys boyss

9.有序集合
特点:不能重复、有一个字段分值、来保证顺序,需要上传分值和元素
集合:无重复元素,无序,element
有序集合:无重复元素,有序,element+score
列表:可以有重复元素,有序,element
1.添加元素
zadd 集合名 分值 元素名
zadd girls 90 www

2.删除元素
zrem 集合名 元素名
返回1成功删除,返回0删除失败
zrem girls eee
3.查询指定元素的分值
zscore girls www
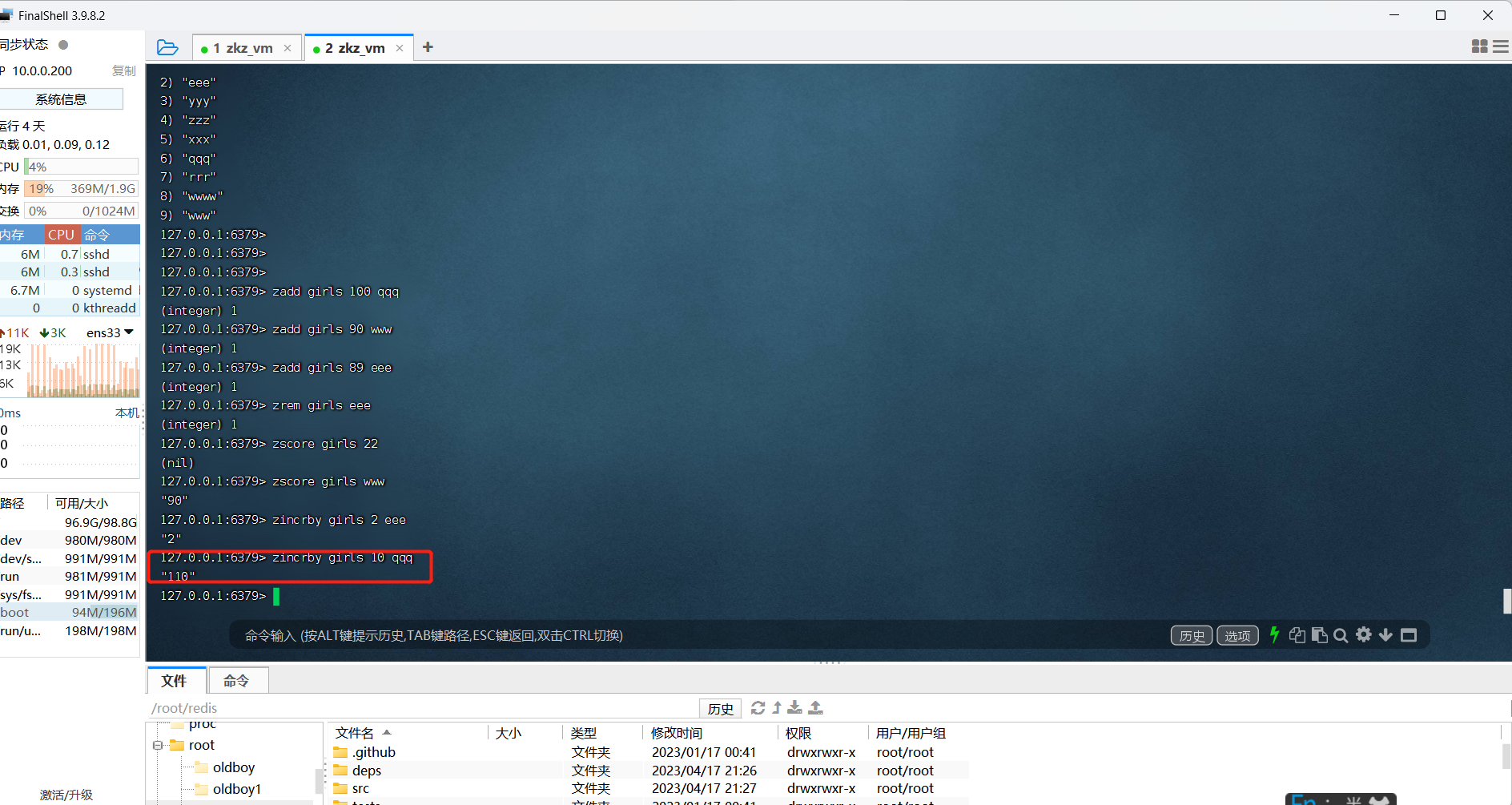
4.给指定的元素分值增加指定的分数
zincrby 集合名 分值 元素名
zincrby girls 10 qqq
5.查找元素排序的位数:元素的分数越低,排名越小,排名从0开始
zrank key element
zrank girls www

6.返回排名,不带分数
zrange girls 0 -1
zrange girls 0 1 # 拿第0位和第1位
zrange girls 0 -1 withscores # 排序并且返回分数


7.返回分数从50到100的元素个数
zcount girls 50 100

8.zremrangebyrank key start end:删除排名从起始到终止的元素
zremrangebyrank girls 0 1 # 第0和第一位都删除
9.其他操作
zrevrank #返回某个元素从高到低排序的顺序
#zrevrank girls dlrb 返回迪丽热巴 按分数降序排的排名
zrevrange #从高到低排序取一定范围
zrevrangebyscore #返回指定分数范围内的降序元素
zinterstore #对两个有序集合交集
zunionstore #对两个有序集合求并集
实战:排行榜、销量榜、
10.慢查询
redis是单线程架构,命令一个个执行,如果有长慢命令,会造成redis的阻塞,redis提供一种方式,可以记录长慢命令,用于后续排查、修改工作
我们可以配置一个时间,如果查询时间超过了我们配置的时间,我们就认为这是一个慢查询
慢查询发生在第三阶段,客户端超时不一定是慢查询,但慢查询是客户端超时的一个可能因素

配置慢查询
slowlog-max-len :慢查询队列的长度
slowly-log-slower-than :超过多少微妙,就算慢命令,就会记录到慢查询队列中
config set slowlog-log-slower-than 0
# 最多记录128条
config set slowlog-max-len 128
# 持久化到本地配置文件,如果不写只是暂时生效,写了会永久生效
config rewrite

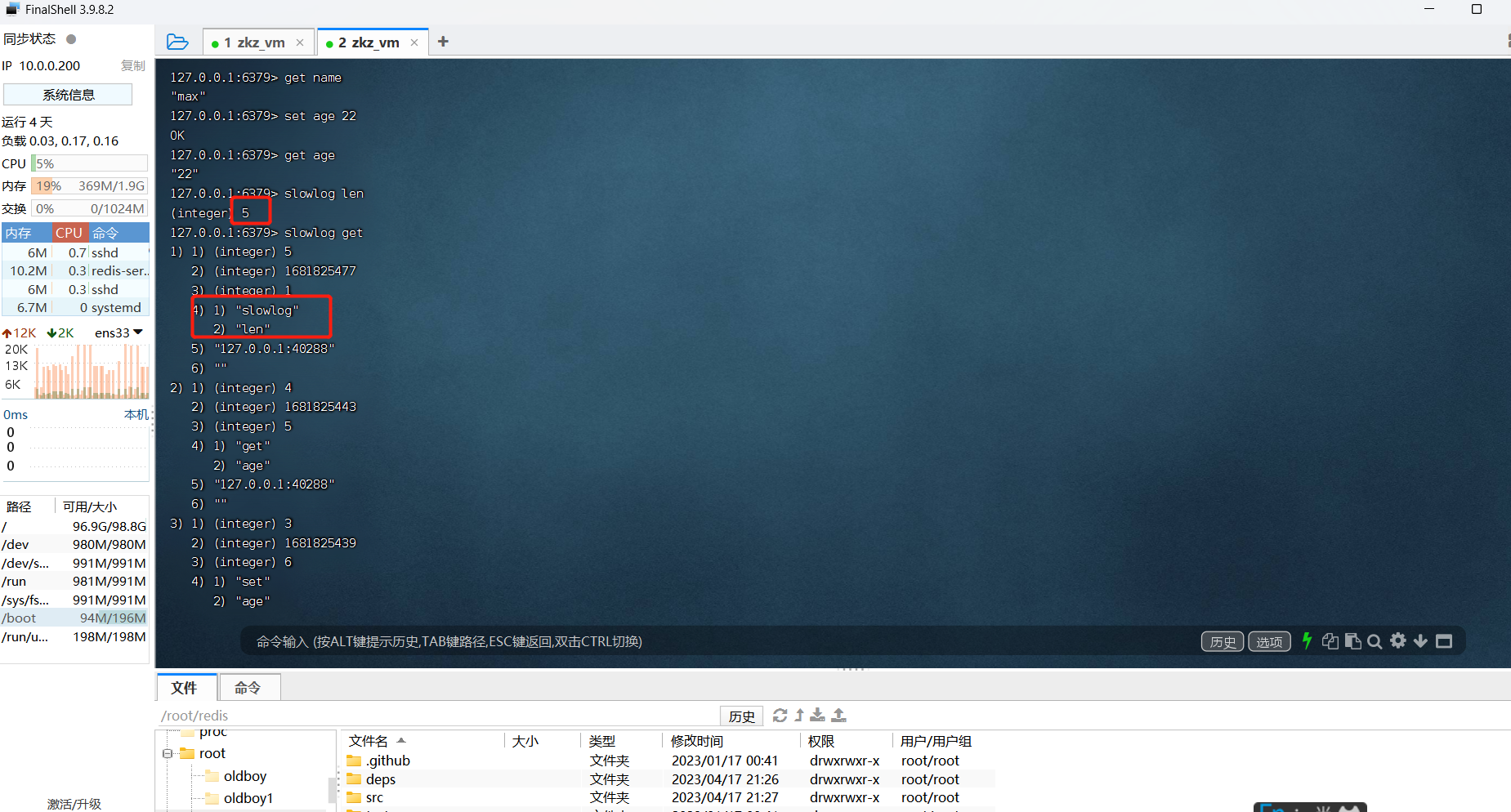
查询慢查询列表长度:
slowlog len
# 取了两次,拿了两次,查询长度也算一次;如果没有执行任何命令,结果是1
查看慢查询列表:
slowlog get
清空慢查询队列:
slowlog reset
11.pipline与事务
Redis的pipeline(管道)功能在命令行中没有,但redis是支持pipeline的,而且在各个语言版的client中都有相应的实现(Redis模块)
将一批命令,批量打包,在redis服务端批量计算(执行),然后把结果批量返回
11.1 python客户端实现事务
1次pipeline(n条命令)=1次网络时间+n次命令时间
没有pipline的命令,但是可以使用python操作实现,python操作实现:
import redis
pool = redis.ConnectionPool(host='127.0.0.1', port=6379)
r = redis.Redis(connection_pool=pool)
#创建pipeline
pipe = r.pipeline(transaction=True)
#开启事务
pipe.multi()
pipe.set('name', 'lqz')
#其他代码,可能出异常
pipe.set('role', 'nb')
pipe.execute()
11.2 redis原生实现事务
# 以下代码依次执行
multi
set name qwe
set age 23 # 执行之后返回一个QUEUE,只是加入到了队列里,还没有真正执行
exec # 提交之后值才能改变
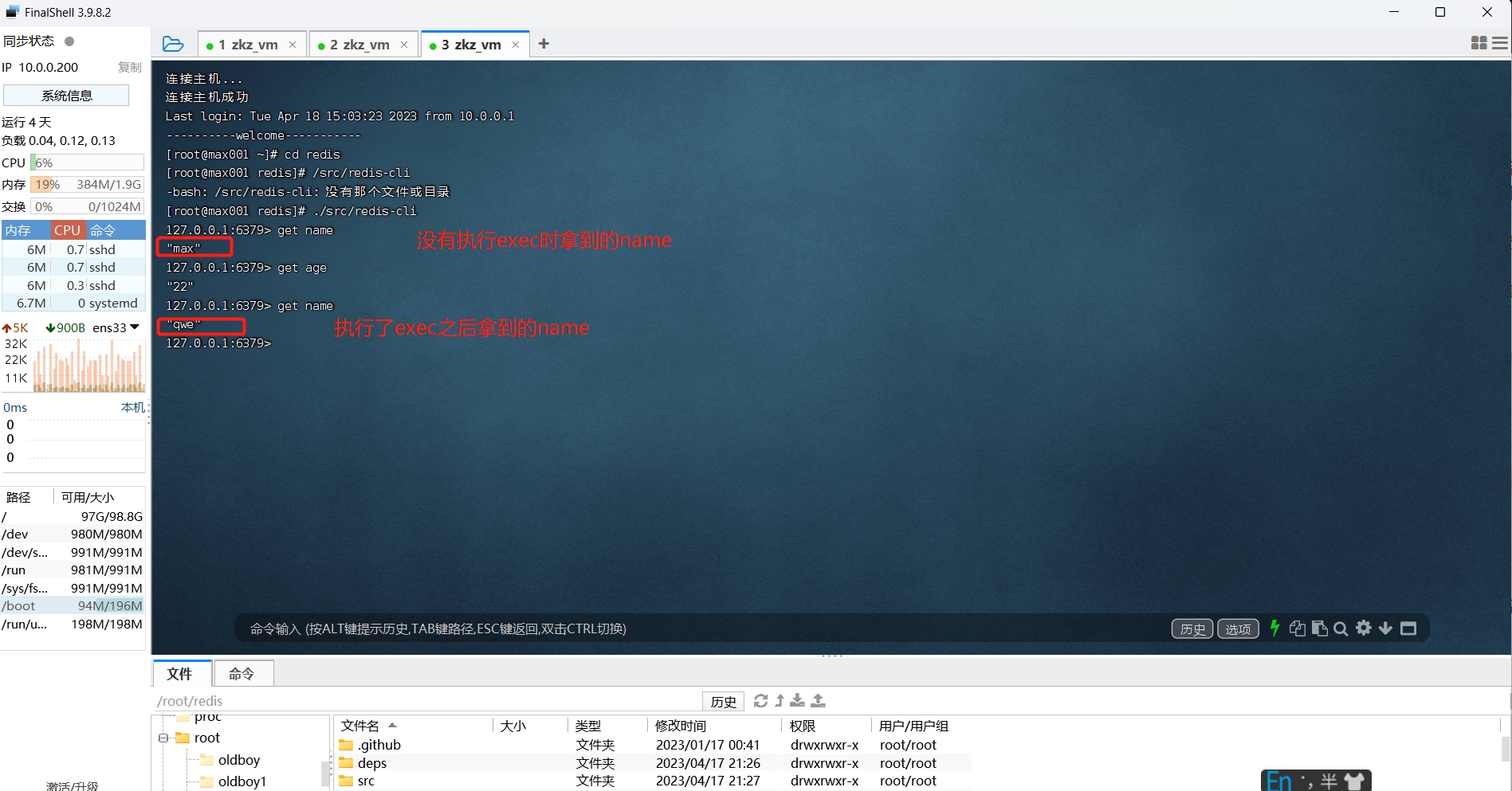
提交了之后才能在另一个服务端才能看到,所以隔离级别是提交读。
11.3 通过watch和multi实现乐观锁
目前age是22
首先我们在第一个服务端开启事务,执行decr age,但不执行exec。然后去另一个客户端,执行decr age,执行exec,返回age是21。我们返回到第一个客户端,执行exec,返回结果20,符合我们常规的逻辑。
再考虑一种极端情况:此时watch是20。在第一个客户端先执行 watch age,再执行multi,在执行decr age,但是不执行exec。在第二个服务端执行multi,decr,exec,此时age成功的改为了19。然后我们再回到第一个客户端,执行exec,但是这时报错了,因为当我们执行watch之后,我们在提交事务时(exec)的age和watch监听创建时的age不一样了,就无法修改:

这就是乐观锁机制。乐观锁乐观地认为我在修改数据的时候别人不会修改,我在修改之前先记录数据的初始值(在redis中是watch),修改的时候将此时的数据和开始监听时的版本做对比,如果不一样,就无法修改。
悲观锁是悲观地认为其他线程都会修改锁,所以修改之前会加锁,不允许其他线程进行修改。
12.发布订阅
发布订阅模式就是观察者模式,只要订阅了某个东西,这个东西发送变化,我们就能收到。发布者发布了消息,所有的订阅者都可以收到,就是生产者消费者模型(后订阅了,无法获取历史消息)
发布订阅模式和生产者消费者模型区别:发布订阅模式信息发布后,监听的用户都会收到,并且不会消失,每个人都有自己的队列,发布者发布之后该信息会存入到所有订阅者的队列中。而生产者消费者模型当消费者消费之后资源就不存在了,并且生产者生产的资源都会放在一个指定的队列中,所有消费者都来这个队列拿。
代码实现:
客户端2:
subscribe channer2 # 订阅channel2
客户端1:
publish channer2 bbb # 在channel2频道发信息bbb
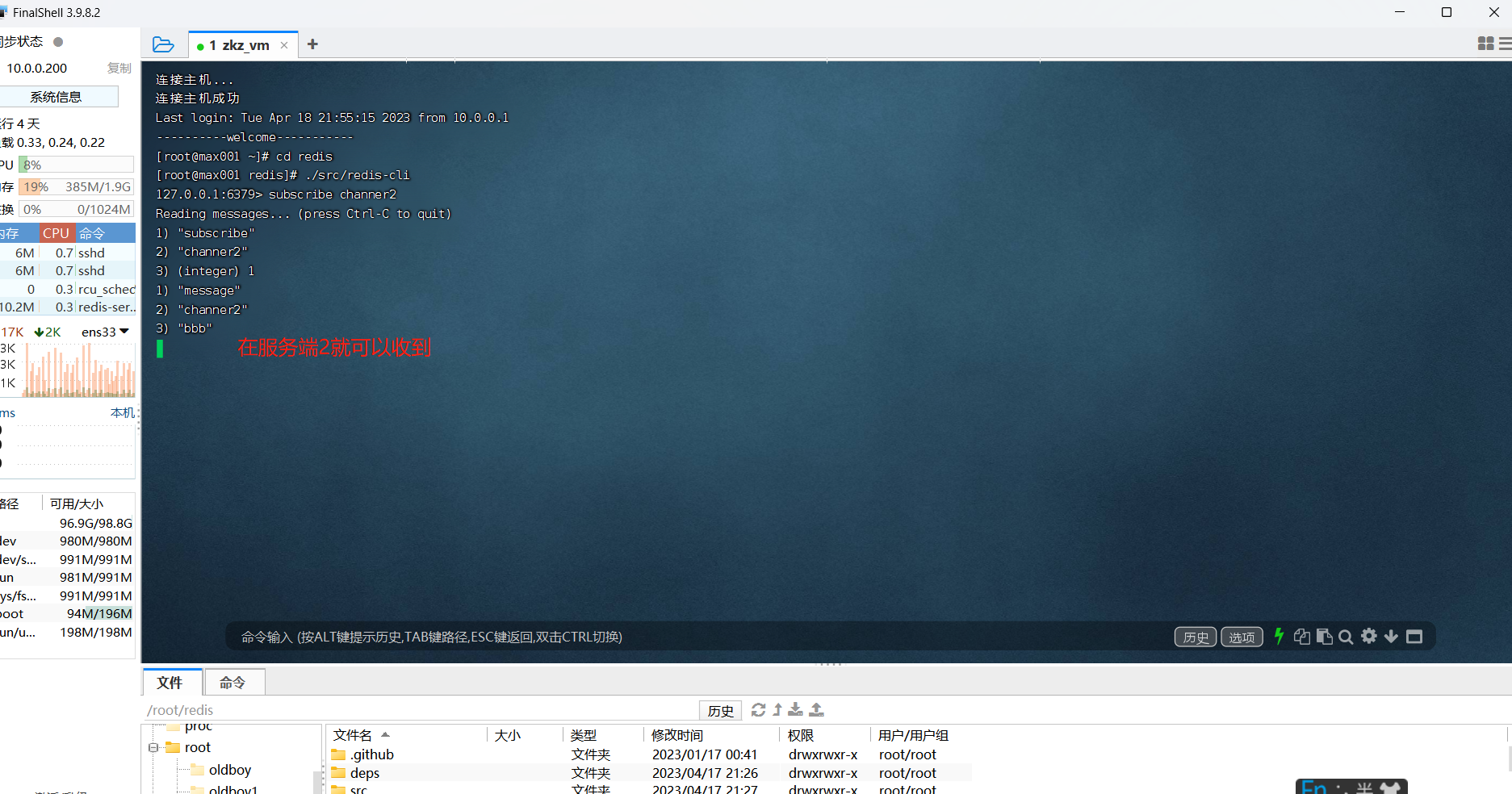
其他操作:
# 查看某个频道有几个订阅者
pubsub numsub lqz
# 列出活跃的频道
pubsub channels
13.用python操作redis实现消息队列
product.py:
'''生产者代码'''
import time
import redis
conn = redis.Redis(host='127.0.0.1',port=6379,password='123456')
def publish():
for i in range(30,40):
'''redis对象.publish是发布消息,第一个参数是频道,第二个参数是发布的信息'''
conn.publish('int_channel', i)
time.sleep(1)
if __name__ == '__main__':
publish()
consumer.py:
'''消费者代码'''
from redis.client import Redis
r = Redis(host='127.0.0.1', port=6379, password='123456', db=0)
def sub():
pub = r.pubsub()
'''订阅频道'''
pub.subscribe('int_channel')
'''监听频道'''
msg_stream = pub.listen()
for msg in msg_stream:
print(msg)
if msg["type"] == "message":
print(str(msg["channel"], encoding="utf-8") + ":" + str(msg["data"], encoding="utf-8"))
elif msg["type"] == "subscribe":
print(str(msg["channel"], encoding="utf-8"), '订阅成功')
if __name__ == '__main__':
sub()
此时就会实现一个效果:生产者随机生产若干条消息加入到消息队列,消费者在已经监听的情况下随时可以收到队列当中的消息。当生产者再次发布消息时,消息队列中之前发布的消息并不会消失,这是我们看到的是累计总共发布的消息


 浙公网安备 33010602011771号
浙公网安备 33010602011771号