1.模型层之前期准备
1.自带的sqlite3数据库对时间字段不敏感,有时候会展示错乱,所以我们习惯切换成常见的数据库比如MySQL,django,orm并不会自动帮你创建库 所以需要提前准备好。
2.单独测试某个django文件:
django默认要求不能单独测试某个文件,需要将整体环境运行起来才可以运行某个py文件。例如我们想测试orm语句中的create,我们需要在views中写一个注册的功能,再在路由层当中匹配对应关系,才可以运行。但是当我们想要运行某个py文件,可以用如下方式:
测试环境1:pycharm提供的python console(但是终端式无法提供保存功能,只适用于临时编写测试代码)
测试环境2:在应用中的tests.py或者在应用中自创一个py文件,并且将manage.py中的前四行代码拷贝到tests.py(或自创的py文件内),再自己加入两行代码:
import os
import sys
def main():
'''注意:这个地方制定的是配置文件的位置,不能出错'''
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'DjangoProject02.settings')
import django
django.setup()
# 以上6行代码写完之后才能导入models模块
2.ORM常用关键字
"""
models.py:
class User(models.Model):
name = models.CharField(max_length=32,verbose_name='姓名')
age = models.IntegerField(verbose_name='年龄')
register_time = models.DateTimeField(verbose_name='注册时间',auto_now_add=True) # auto_now_add=True是自动获取数据生成的时间
def __str__(self):
return f'对象{self.name}'
"""
1.create():创建数据并直接获取当前创建的数据对象:
res = models.User.objects.create(name='max',age=25)
print(res) # 对象max
res1 = models.User.objects.create(name='marry',age=15)
print(res1.age)
'''res拿到的是一个用户对象,该用户对象的命名是按照__str__的返回值来命名,但是该对象也可以通过点的方式拿到用户的信息'''
2.filter():根据相应条件拿到用户对象的列表(query set),如果没有指定条件返回的是所有用户对象的列表:
res2 = models.User.objects.filter()
print(res2)
# <QuerySet [<User: 对象max>, <User: 对象jason>, <User: 对象jerry>, <User: 对象kevin>]
指定筛选条件拿到的还多是一个query set:
res3 = models.User.objects.filter(id=2)
print(res3) # <QuerySet [<User: 对象max>]>
指定筛选条件可以指定多个值,多个条件之间是and关系:
res4 = models.User.objects.filter(name='max',age=25)
print(res4) # <QuerySet [<User: 对象max>]>
6.first(),last():分别指拿到筛选之后的列表中的第一个和最后一个值,和索引取得的结果一样都是一个对象:
res5 = models.User.objects.filter().first()
res6 = models.User.objects.filter().last()
print(res5,res6) # 对象max 对象marry
"""
两者和索引的区别在于索引取不到值会报错,而上述两者会返回一个None。
"""
7.update():对筛选数据进行更新,如果filter()括号内什么都不写默认修改全部。update修改数据的返回值默认是1,不是数据对象。
models.User.objects.filter(name='marry').update(age=19)
8.delete():删除指定对象,如果filter未指定对象默认删除全部。
models.User.objects.filter(name='marry').delete()
"""
update()和delete()不是数据对象方法,而是query set方法,所以它们不需要取到对象(用first()、last()或索引值拿到对象)才能操作。
"""
9.all():和filter方法一样类似,拿到的都是query set,但是all()默认拿到全部对象的列表,filter拿到指定对象的列表。
res8 = models.User.objects.all()
print(res8) # <QuerySet [<User: 对象max>, <User: 对象jason>, <User: 对象jerry>, <User: 对象kevin>]>
10.values():拿到指定字段的值。结果是一个quert set,可以看做列表套字典,字典的键是指定字段。value()也是一个query set方法。
res1 = models.User.objects.values('name')
res2 = models.User.objects.all().values('name')
print('res1',res1) # res1 <QuerySet [{'name': 'max'}, {'name': 'jason'}, {'name': 'jerry'}, {'name': 'kevin'}]>
print('res2',res2) # res1 <QuerySet [{'name': 'max'}, {'name': 'jason'}, {'name': 'jerry'}, {'name': 'kevin'}]>
11.values_list():拿到指定字段的值,返回的结果是一个queryset,里面的元素是元组,每个元组包含了每条数据指定的字段名对应的数据。
res = models.User.objects.all().values_list('name','age')
print(res) # <QuerySet [('max', 25), ('jason', 18), ('jerry', 29), ('kevin', 15), ('lili', 17)]>
"""
values_list()有一个参数flat,默认是False。当values_list()括号内只有一个字段名时,默认是要给查询出来的每一个值加括号。当我们加上flat=True时,括号就可以去掉:
print(Book.objects.all().values_list('name')) # <QuerySet [('三国演义',), ('西游记',), ('红楼梦',)]>
print(Book.objects.all().values_list('name',flat=True)) # <QuerySet ['三国演义', '西游记', '红楼梦']>
"""
12.当我们想查看某个对象的sql语句时,可以用如下方法:
1.用一个queryset对象点query:
res1 = models.User.objects.values('name')
print(res1) # res1 <QuerySet [{'name': 'max'}, {'name': 'jason'}, {'name': 'jerry'}, {'name': 'kevin'}]>
print(res1.query) # SELECT `app01_user`.`name` FROM `app01_user`
2.如果不是queryset对象,我们可以直接在settings加入如下代码,每执行一条操作,都会返回一个sql语句:
"""
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
"""
models.User.objects.create(name='lili',age=17) # INSERT INTO `app01_user` (`name`, `age`, `register_time`) VALUES ('lili', 17, '2022-12-14 13:17:11.321862'); args=['lili', 17, '2022-12-14 13:17:11.321862']
12.distinct():跟在queryset后面,去重。去重时会考虑主键。
res = models.User.objects.filter(name='max').distinct()
print(res) # <QuerySet [<User: 对象max>, <User: 对象max>]> # 考虑主键两个对象不一样
res = models.User.objects.values_list('name','age').distinct()
print(res) # <QuerySet [('max', 25), ('jason', 18), ('jerry', 29), ('kevin', 15), ('lili', 17)]> # 成功去重,因为该queryset不包含主键字段。
13.给queryset通过指定字段排序,默认升序,字段名前面加-是降序。
res = models.User.objects.all().order_by('age')
print(res) # <QuerySet [<User: 对象kevin>, <User: 对象lili>, <User: 对象jason>, <User: 对象max>, <User: 对象max>, <User: 对象jerry>]>
res = models.User.objects.all().order_by('-age')
print(res) # <QuerySet [<User: 对象jerry>, <User: 对象max>, <User: 对象max>, <User: 对象jason>, <User: 对象lili>, <User: 对象kevin>]>
14.get():拿到指定的对象,但是如果没有该对象会直接报错。
res = models.User.objects.get(name='jerry')
print(res) # 对象jerry
15.exclude():拿到条件不满足括号内条件的对象,返回结果是一个queryset。
res = models.User.objects.exclude(name='max')
print(res) # <QuerySet [<User: 对象jason>, <User: 对象jerry>, <User: 对象kevin>, <User: 对象lili>]>
16.reverse():颠倒顺序(被操作的对象必须是已经排过序的才可以)。
res = models.User.objects.all().order_by('age')
res1 = models.User.objects.all().order_by('age').reverse()
print(res, res1)
17.count():统计结果集中数据的个数。
res = models.User.objects.all().count()
print(res) # 6
18..exists():判断结果集中是否含有数据,如果有则返回True,没有则返回False。
res = models.User.objects.all().exists()
print(res) # True
res1 = models.User.objects.filter(pk=100).exists()
print(res1) # False
"""
1.返回QuerySet对象的方法有:all(),filter(),exclude(),order_by(),reverse(),distinct()
2.返回具体对象的:get(),first(),last()
"""
3.ORM执行SQL语句
1.用raw(),在括号内编写sql语句:
res = models.User.objects.raw('select * from app01_user')
print(list(res)) # [<User: User object (1)>, <User: User object (2)>]
2.用django.db模块,产生游标对象(封装了pymsql模块):
from django.db import connection
cursor = connection.cursor()
cursor.execute('select * from app01_user')
print(cursor.fetchall()) # ((1, 'max', 25), (2, 'jerry', 18))
"""
fetchone:一次只拿一个;
fetchmany():一次拿指定个数
"""
4.神奇的双下划线查询
"""
只要还是queryset对象就可以无限制的点queryset对象的方法,除了get(),first(),last(),其余都是queryset方法
"""
1.查询年龄大于18岁的用户:
res = models.User.objects.filter(age__gt=18)
print(res.values_list('name','age')) # <QuerySet [('max', 25), ('henry', 39), ('harry', 58), ('kevin', 28)]>
2.查询年龄大于等于18岁的用户:
res = models.User.objects.filter(age__gte=18)
print(res.values_list('name','age')) # <QuerySet [('max', 25), ('jerry', 18), ('jason', 18), ('henry', 39), ('harry', 58), ('kevin', 28)]>
3.查询年龄小于和小于等于18岁的用户:
res1 = models.User.objects.filter(age__lt=18) # <QuerySet [<User: User object (6)>]>
res2 = models.User.objects.filter(age__lte=18) # <QuerySet [<User: User object (2)>, <User: User object (3)>, <User: User object (6)>]>
print(res1,res2)
4.查询年龄是8,18或38的用户对象:
res = models.User.objects.filter(age__in=(8,18,28))
print(res) # <QuerySet [<User: 对象jerry>, <User: 对象jason>, <User: 对象bob>, <User: 对象kevin>]> # 从这部开始在models中用__str__将对象名改变了
5.查询年龄范围在18到38岁之间的用户对象(age__range默认首尾包含):
res = models.User.objects.filter(age__range=(18,38))
print(res) # <QuerySet [<User: 对象max>, <User: 对象jerry>, <User: 对象jason>, <User: 对象kevin>]>
6.查询名字中含有'j'的用户对象(区分大小写):
res = models.User.objects.filter(name__contains='j')
print(res) # <QuerySet [<User: 对象jerry>, <User: 对象jason>]>
7.查询名字中含有'J'的用户对象(不区分大小写):
res = models.User.objects.filter(name__icontains='J')
print(res) # <QuerySet [<User: 对象jerry>, <User: 对象jason>, <User: 对象Jack>]>
8.查询注册年份是2022的数据:
res = models.User.objects.filter(register_time__year=2022)
print(res)
5.ORM外键字段的创建
"""
mysql中:
一对多:外键字段在多的一方
一对一:建在任何一方都可以,但是建议建在查询频率较高的一方
"""
1.创建基础表:
一对多:ORM与MySQL一致,外键字段建在多的一方
多对多:ORM比MySQL不同,外键字段可以直接建在某张表中(建议放在查询评率较高的表),内部会自动创建第三张表。
一对一:ORM与MySQL一致,外键字段建在查询频率较高的一方。
2.ORM创建:
针对一对一和一对多,外键括号内要加入级联的参数:on_delete=models.CASCADE。
多对多关系表系统会自动创建,并且可以展示在列表中。
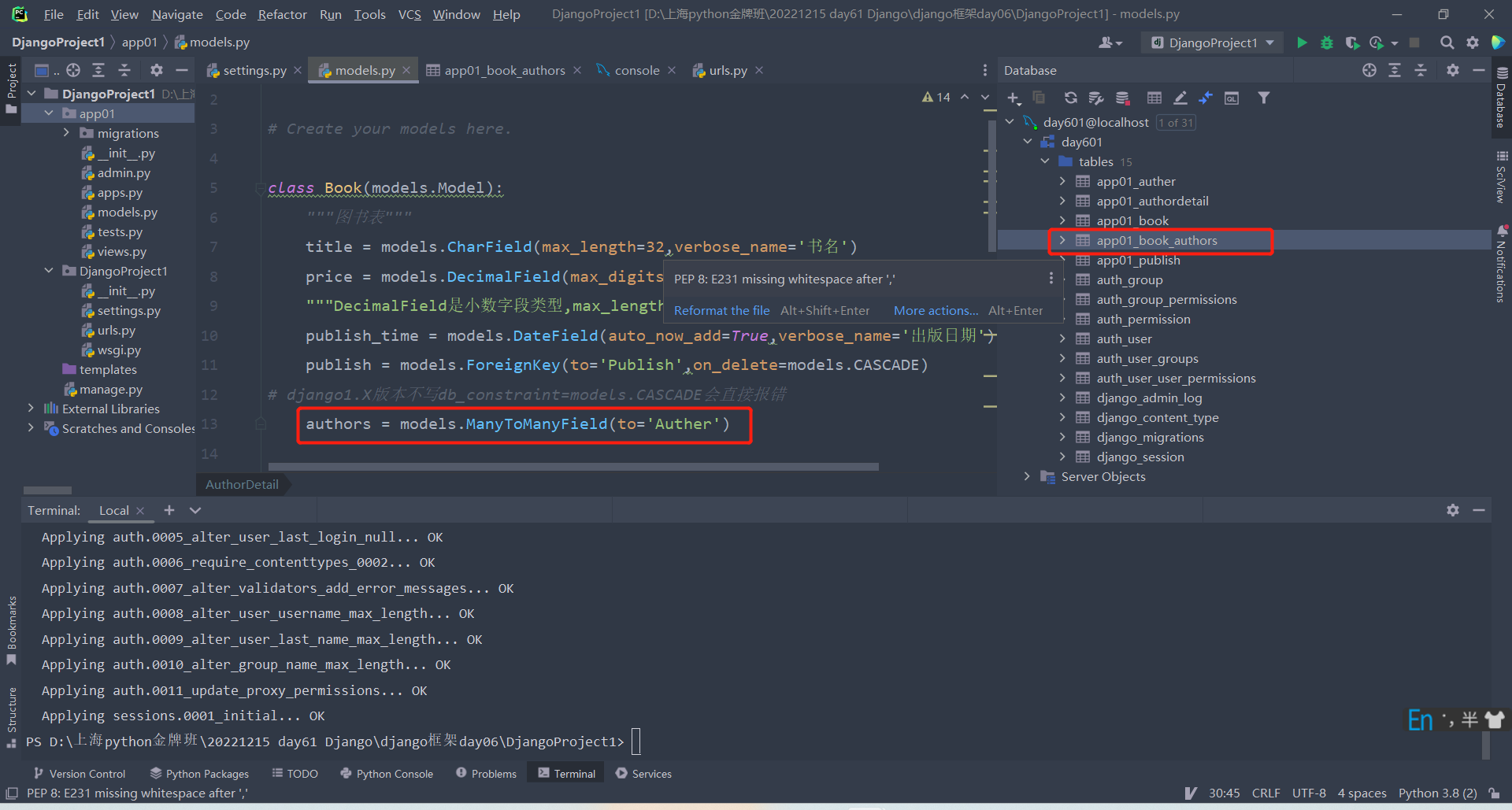
models.py:
class Book(models.Model):
"""图书表"""
title = models.CharField(max_length=32,verbose_name='书名')
price = models.DecimalField(max_digits=8,decimal_places=2,verbose_name='价格')
"""DecimalField是小数字段类型,max_length是数字总长度,decimal_places是小数点后面位数"""
publish_time = models.DateField(auto_now_add=True,verbose_name='出版日期')
publish = models.ForeignKey(to='Publish',on_delete=models.CASCADE)
'''外键中含有其他表中的主键字段在表中会自动加上id(所以自己不需要写id)'''
# django1.X版本不写db_constraint=models.CASCADE会直接报错
authors = models.ManyToManyField(to='Auther')
'''多对多不需要添加级联'''
class Publish(models.Model):
"""出版社表"""
name = models.CharField(max_length=32,verbose_name='名称')
address = models.CharField(max_length=32,verbose_name='地址')
class Auther(models.Model):
"""作者表"""
name = models.CharField(max_length=32,verbose_name='姓名')
age = models.IntegerField(verbose_name='年龄')
author_detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE)
class AuthorDetail(models.Model):
"""作者详情表"""
phone = models.BigIntegerField(verbose_name='手机号')
address = models.CharField(max_length=64,verbose_name='地址')
"""
在书籍表中我们创建了六个字段,但是字段authors并没有显示在书籍表中的字段名当中。Django默认不讲对多对的外键字段显示在表中,而是会单独创建一个表。针对一对多和一对一,同步到表中之后会自动加id的后缀。
"""
6.ORM外键字段的创建和操作
除以下内容,其余的内容直接在表上手动添加:
1.针对一对多,可以直接填写表中的实际字段
models.Book.objects.create(title='三国演义',price=888.88,publish_id=1) # publish_id是外键字段,填写时一定要填已经创建好的
如果一对多中外键字段对应的数据是一个对象,也可以直接添加对象,这种情况下外键字段不用加id(一对多同理):
publish_obj = models.Publish.objects.filter(pk=1).first()
models.Book.objects.create(title='红楼梦',price=666.77,publish=publish_obj)
2.针对多对多,django会自己创建一张表,我们对这张表没有办法直接点名字来添加数据,而是需要通过书籍对象点作者外键名的方式:
book_obj = models.Book.objects.filter(pk=3).first()
book_obj.authors.add(1) # 给pk=3的书籍添加pk=1的作者
一个书籍对象也可以上传多个作者,用逗号隔开(可以多次添加,之前的也会保留):
book_obj = models.Book.objects.filter(pk=4).first()
book_obj.authors.add(1,2)
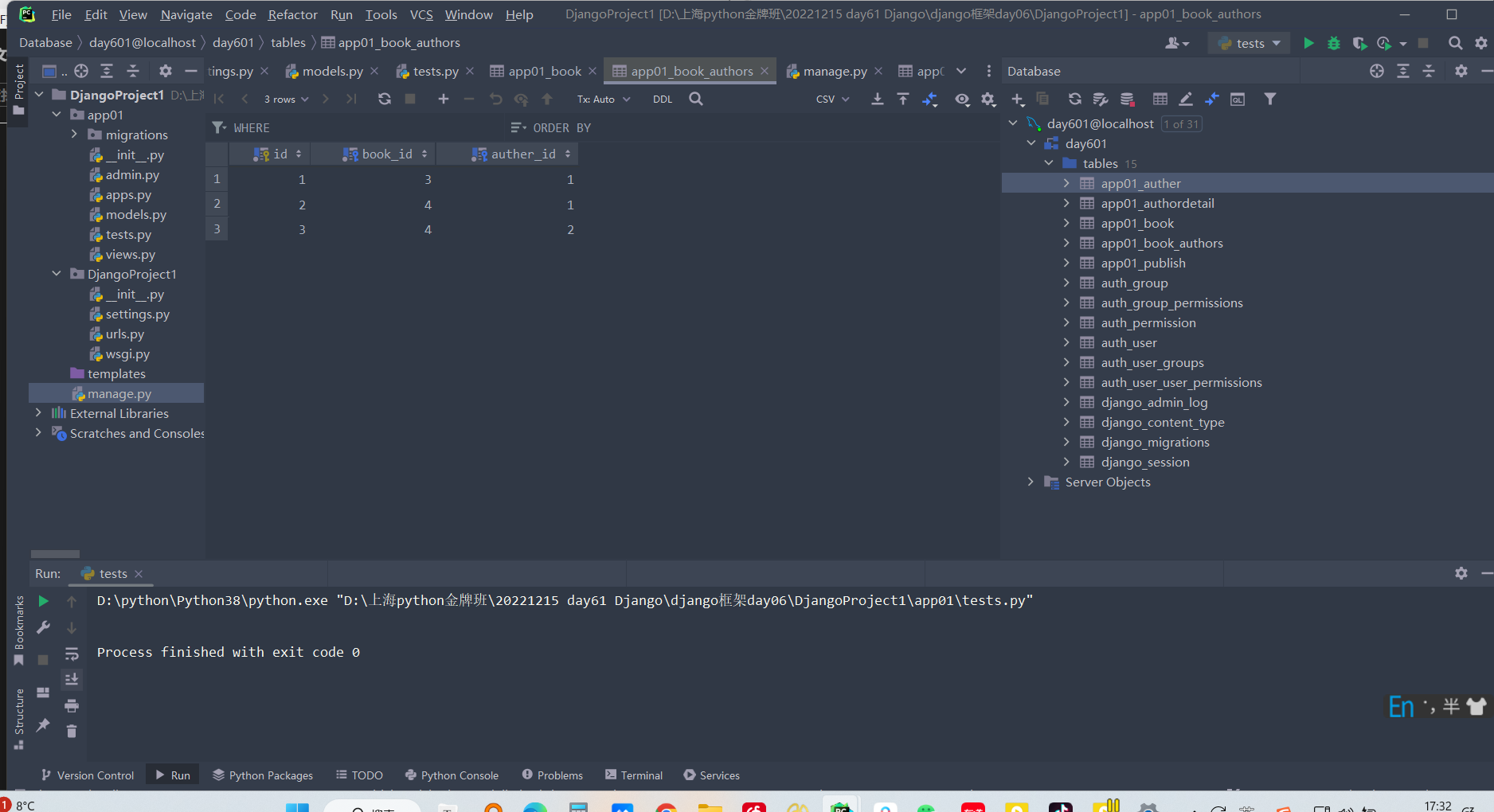
书籍上传作者也可以上传一个(或多个)作者对象:
author_obj = models.Auther.objects.filter(pk=1).first()
book_obj.authors.add(author_obj)
author_obj3 = models.Auther.objects.filter(pk=3).first()
book_obj6.authors.add(author_obj2,author_obj3)
多对多的修改:当我们想要修改多对多表中的对应关系,我们需要按照以下语法:set()括号内需要写一个元组或者列表
book_obj6 = models.Book.objects.filter(pk=6).first()
book_obj6.authors.set((1,2))
修改时也可以传入对象:
book_obj6 = models.Book.objects.filter(pk=6).first()
author_obj2 = models.Auther.objects.filter(pk=1).first()
author_obj3 = models.Auther.objects.filter(pk=3).first()
book_obj6.authors.set((author_obj2,author_obj3))
多对多删除数据:
book_obj.authors.clear() # 删除掉多对多关系创建的第三张表:book_authors表中book_id的数据。
"""
对于没有添加数据的表用set修改会报错,应首先用add添加。
"""
删除:我们可以删除指定书对应的作者,可以删除多个,set和remove括号内一次都可以传入多个值
book_obj = models.Book.objects.filter(pk=6).first()
book_obj.authors.remove(1)
7.ORM跨表查询
"""
复习MySQL跨表查询的思路
1.子查询
分步操作:将一条SQL语句用括号括起来当做另外一条SQL语句的条件
2.连表操作
先整合多张表之后基于单表查询即可
inner join 内连接
left join 左连接
right join 右连接
"""
1.正反向查询的概念:
正向查询:由外键字段所在的表数据查询关联的表数据。比如已知书名查询出版社,外键在书表内,所以是正向查询。
2.反向查询的概念:
反向查询:没有为外键字段的表数据查询关联的表数据。
ps:正反向的核心就看外键字段在不在当前数据所在的表中
ORM跨表查询的口诀(重要):
正向查询按外键字段
反向查询按表名小写
8.基于对象的跨表查询(相当于mysql中的子查询)
正向查询:先拿到已知条件的对象,再通过对象点表中的外键字段名,再点外键对应的表的字段名。如果结果是多个值需要点all(),拿到指定的名字再点values('字段名')。
1.查询主键为1的书籍对应的出版社名称
book_obj = models.Book.objects.filter(pk=1).first()
print(book_obj.publish.name) # 东方出版社
2.查询主键为4的书籍对应的作者姓名:
"""
多对多查询时需要点all(),不然会报错app01.Author.None
"""
book_obj = models.Book.objects.filter(pk=4).first()
print(book_obj.authors.all().values('name')) # <QuerySet [{'name': 'jerry'}]>
3.查询jason的电话号码
author_obj = models.Author.objects.filter(name='jason').first()
print(author_obj.author_detail.phone) # 110
反向查询:先拿到指定数据的对象,再去点该表外键的表名(小写)_set
4.查询北方出版社出版过的书籍
publish_obj = models.Publish.objects.filter(name='北方出版社').first()
print(publish_obj.book_set.all().values('title')) # <QuerySet [{'title': '老人与海'}, {'title': '红楼梦'}]>
5.查询jason写过的书籍
author_obj = models.Author.objects.filter(name='jason').first()
print(author_obj.book_set.all().values('title')) # <QuerySet [{'title': '老人与海'}, {'title': '西游记'}]>
6.查询电话号码是110的作者姓名
auther_detail_obj = models.AuthorDetail.objects.filter(phone=110).first()
print(auther_detail_obj.author.name) # jason
"""
反向查询个有多个结果就需要点all(),并且在字段名后面加_set,_set和all()一起用。一个结果就不用加。
"""
9.基于双下划线的跨表查询(无关正反向)
如果通过已知的条件无法在一张表上面拿到结果,在values()中也是支持跨表查询,直接写表名再用双下划线连接该表明里面的字段名。
1.查询主键为1的书籍对应的出版社名称
res = models.Book.objects.filter(pk=1).values('publish__name')
print(res) # <QuerySet [{'publish__name': '北方出版社'}]>
2.查询主键为4的书籍对应的作者姓名
res = models.Book.objects.filter(pk=4).values('authors__name')
print(res) # <QuerySet [{'authors__name': 'jerry'}]>
3.查询jason的电话号码
res = models.Author.objects.filter(name='jason').values('author_detail__phone')
print(res) # <QuerySet [{'author_detail__phone': 110}]>
4.查询北方出版社出版过的书籍名称和价格
res = models.Publish.objects.filter(name='北方出版社').values('book__title','book__price')
print(res) # <QuerySet [{'book__title': '老人与海', 'book__price': Decimal('444.44')}, {'book__title': '红楼梦', 'book__price': Decimal('888.88')}]>
5.查询jason写过的书籍名称
res = models.Author.objects.filter(name='jason').values('book__title','book__price')
print(res) # <QuerySet [{'book__title': '老人与海', 'book__price': Decimal('444.44')}, {'book__title': '西游记', 'book__price': Decimal('444.44')}]>
6.查询电话号码是110的作者姓名
res = models.AuthorDetail.objects.filter(phone=110).values('author__name')
print(res) # <QuerySet [{'author__name': 'jason'}]>
10.进阶操作
上述操作都是以已知条件为基础表,而下列方法以目标条件作为基础表,filter中同样支持已知的查询条件
1.查询主键为1的书籍对应的出版社名称层
'''以Publish条件查询,筛选条件是Book,所以筛选条件前要加book__'''
res = models.Publish.objects.filter(book__pk=1).values('name')
print(res) # <QuerySet [{'name': '北方出版社'}]>
2.查询主键为4的书籍对应的作者姓名
res = models.Author.objects.filter(book__pk=4).values('name')
print(res) # <QuerySet [{'name': 'jerry'}]>
3.查询jason的电话号码
res = models.AuthorDetail.objects.filter(author__name='jason').values('phone')
print(res) # <QuerySet [{'phone': 110}]>
4.查询北方出版社出版过的书籍名称和价格
res = models.Book.objects.filter(publish__name='北方出版社').values('title','price')
print(res) # <QuerySet [{'title': '老人与海', 'price': Decimal('444.44')}, {'title': '红楼梦', 'price': Decimal('888.88')}]>
5.查询jason写过的书籍名称
res = models.Book.objects.filter(authors__name='jason').values('title')
print(res) # <QuerySet [{'title': '老人与海'}, {'title': '西游记'}]>
6.查询电话号码是110的作者姓名
res = models.Author.objects.filter(author_detail__phone=110).values('name')
print(res) # <QuerySet [{'name': 'jason'}]>
11.聚合查询
在ORM中使用聚合函数首先需要导入模块:from django.db.models import Max,Min,Sum,Count,Avg,使用时需要使用aggregate()将聚合函数包起来
不涉及分组查询,在同一个表内根据聚合函数查询数据,如果取了别名在字典中会按照别名显示:
1.统计每一本书的作者个数:
res = models.Book.objects.aggregate(total_num=Count('pk'),max_price=Max('price'),avg_price=Avg('price'))
print(res) # {'total_num': 5, 'max_price': Decimal('9999.67'), 'avg_price': Decimal('2710.972000')}
12.分组查询
"""
如果我们执行以下分组代码报错,可以尝试在命令行mysql中(游客模式不行)输入以下代码:set global sql_mode='strict_trans_tables',返回OK则完成修改。
"""
models点什么就是按什么分组,聚合函数中也支持正反向查询的原则:
按照表明分组:models.表名.objects.annotate()
1.统计出每个出版社卖的最便宜的书的价格:
res = models.Book.objects.annotate(author_num=Count('authors__pk')).values('title', 'author_num')
print(res)
2.统计出每个出版社卖的最便宜的书的价格:
es = models.Publish.objects.annotate(cheapest_book=Min('book__price')).values('name','book__title','cheapest_book')
print(res) # 同时拿到了出版社名,书名和书的价格
3.统计不止一个作者的图书:
1.首先查出所有图书对应的作者个数:
res = models.Book.objects.annotate(count_author=Count('authors__pk')).values('title','count_author')
2.直接在尾部(values之前)点filter进行筛选:
res = models.Book.objects.annotate(count_author=Count('authors__pk')).filter(count_author__gt=1).values('title','count_author')
print(res) # <QuerySet [{'title': '三国演义', 'count_author': 3}, {'title': '围城', 'count_author': 2}]>
4.查询每个作者出的书的总价格:
res = models.Author.objects.annotate(sum_price=Sum('book__price'),sum_book=Sum('book__pk')).values('name','sum_book','sum_price')
print(res)
"""
annotate前面也可以跟filter(),相当于mysql中的where
"""
5.查询每个作者出的书的总价:
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name','sum_price')
print(res)
按照字段名分组:
models.表名.objects.values('字段名').annotate()
values()在annotate()之前指按照表中某个字段分组,在annotate()之后指拿到某个字段名。
1.拿到每个publish_id初版的书籍个数:
res = models.Book.objects.values('publish_id').annotate(count_pk=Count('pk')).values('publish_id','count_pk')
print(res) # <QuerySet [{'publish_id': 1, 'count_pk': 2}, {'publish_id': 2, 'count_pk': 2}, {'publish_id': 3, 'count_pk': 1}]>
13.F与Q查询
"""
后续添加字段需要指定默认值default=,或者设置允许为空:null=True'''
reper = models.IntegerField(verbose_name='库存数',default=1000)
sale = models.IntegerField(verbose_name='卖出数',null=True)
添加完成之后再执行迁移表的两步操作,新的字段就可以添加到表上
"""
1.当我们需要用同一张表的两个字段名中的数据数据做对比时,我们不能直接用字段名做数据的对比,要是用F('字段名')。
from django.db.models import F
1.1查询库存数大于卖出数的书籍
res = models.Book.objects.filter(reper__gt=F('sale'))
print(res)
1.2将所有书的价格涨800
models.Book.objects.update(price = F('price')+800)
1.3将所有书的名称后面追加爆款
from django.db.models.functions import Concat
from django.db.models import Value
models.Book.objects.update(title=Concat(F('title'), Value('爆款')))
1.4逗号是and关系:
查询所有主键是1并且价格大于200的书籍对象:
res = models.Book.objects.filter(pk=1,price__gt=200)
print(res) # <QuerySet [<Book: 书籍对象:三国演义爆款>]>
2.当我们想要修改不同数据之间的条件时,比如(and或or),我们需要使用Q查询。Q查询两个条件之间|表示或(or),&表示且(and):
2.1查询书籍主键是1或者(or)价格大于200块的书籍对象:
from django.db.models import Q
res = models.Book.objects.filter(Q(pk=1) | Q(price__gt=200))
print(res)
2.2查询书籍主键不是1或者价格大于2000的书籍对象
from django.db.models import Q
res = models.Book.objects.filter(~Q(pk=1) | Q(price__gt=2000))
print(res)
"""
filter()括号内可以跟多个条件,多个条件之间是and关系,也就是,前后的条件需要同时满足。这就相当于Q查询的条件用&连接起来
qs = Book.objects.filter(pk=1,name='西游记').all()
print(qs) # <QuerySet []>
from django.db.models import Q
qs = Book.objects.filter(Q(pk=1) | Q(name='西游记'))
print(qs) # <QuerySet [<Book: Book object (1)>, <Book: Book object (2)>]>
"""
14.Q查询进阶操作
1.Q查询用法1:
from django.db.models import Q
q_obj = Q() # 产生一个Q对象化
q_obj.children.append(('pk',1)) # 给Q对象添加条件,一个对象可以添加多个条件
q_obj.children.append(('price__gt',2000))
res = models.Book.objects.filter(q_obj) # 直接将对象当做筛选的条件
print(res) # <QuerySet [<Book: 书籍对象:三国演义>]>
2.通过查看sql语句得知,上述q_obj中通过append添加的条件是and关系,我们也可以改成or:只需要在生成Q对象后直接将对象.connector = 'or'。
q_obj = Q()
q_obj.connector = 'or'
q_obj.children.append(('pk',1))
q_obj.children.append(('price__gt',2000))
res = models.Book.objects.filter(q_obj)
print(res) # <QuerySet [<Book: 书籍对象:三国演义>, <Book: 书籍对象:月亮和六便士>]>
15.ORM查询优化
1.ORM查询默认都是惰性查询,只要不打印结果,那么就不会执行该sql语句,例如下列语句中并没有执行sql的查询语句:
res = models.Book.objects.filter(pk=1)
print('hahaha') # hahaha
"""
1.只有queryset能实现该效果,如果在上述语句后面加上first()拿到对象,那么即使不打印该结果也会执行sql语句。
2.惰性查询仅针对于查询,增删改已经和数据库进行交互,必然要执行sql语句。
"""
2.ORM自带分页处理:我们在查数据时如果表中的数据过多,我们也可以在sql语句末尾加上LIMIT 来限制每页的数据数。
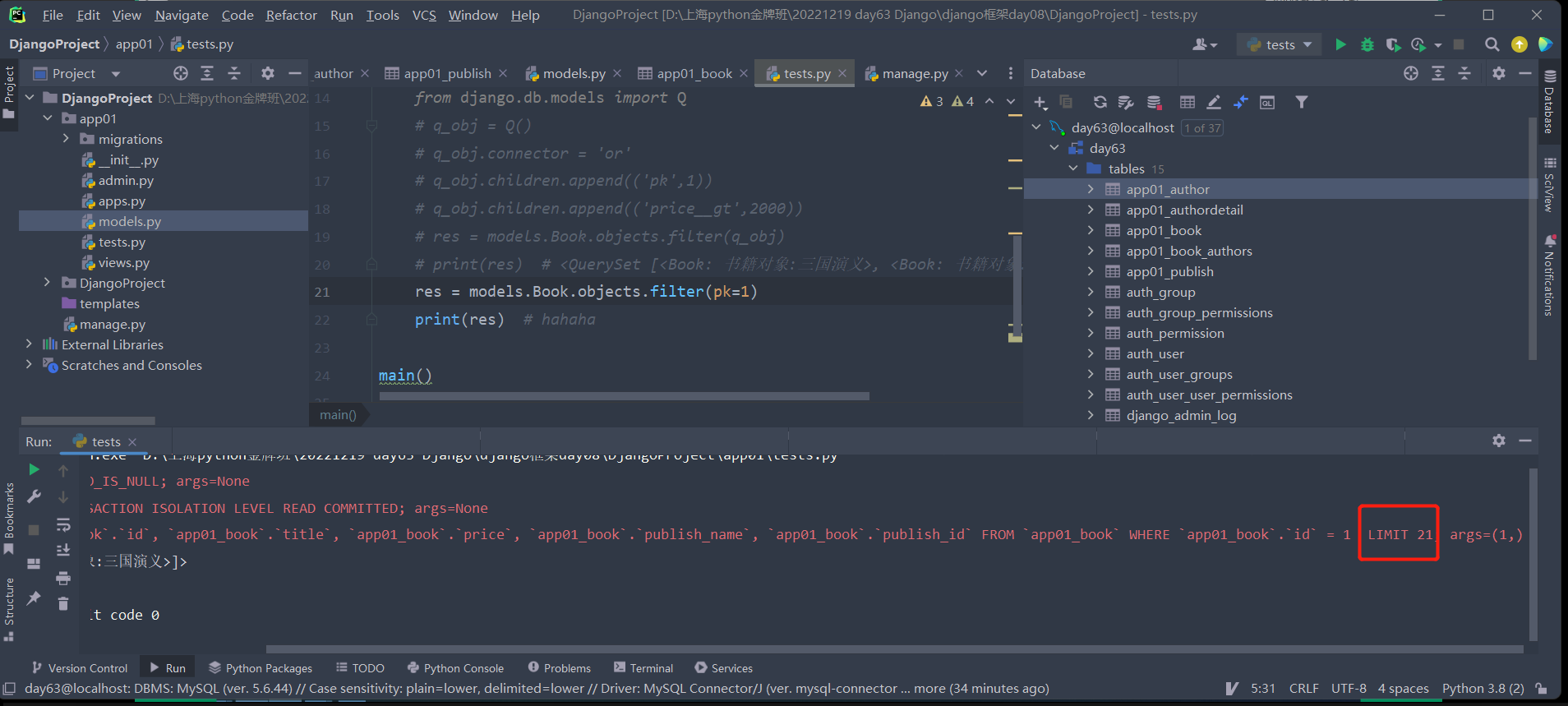
3.only与defer:
"""
res是一个queryset,obj是数据对象,obj具有点所有名字的属性。
res = models.Book.objects.all()
for obj in res:
print(obj.title)
print(obj.price)
如果我们在尾部使用values,我们可以拿到一个queryset,但是里面是字典,无法通过点的方式拿到数据:
res = models.Book.objects.all().values('title','price')
for obj in res:
print(obj) # {'title': '三国演义', 'price': Decimal('2267.98')}
print(obj.get('title')) # 三国演义
print(obj.get('price')) # 2267.98
"""
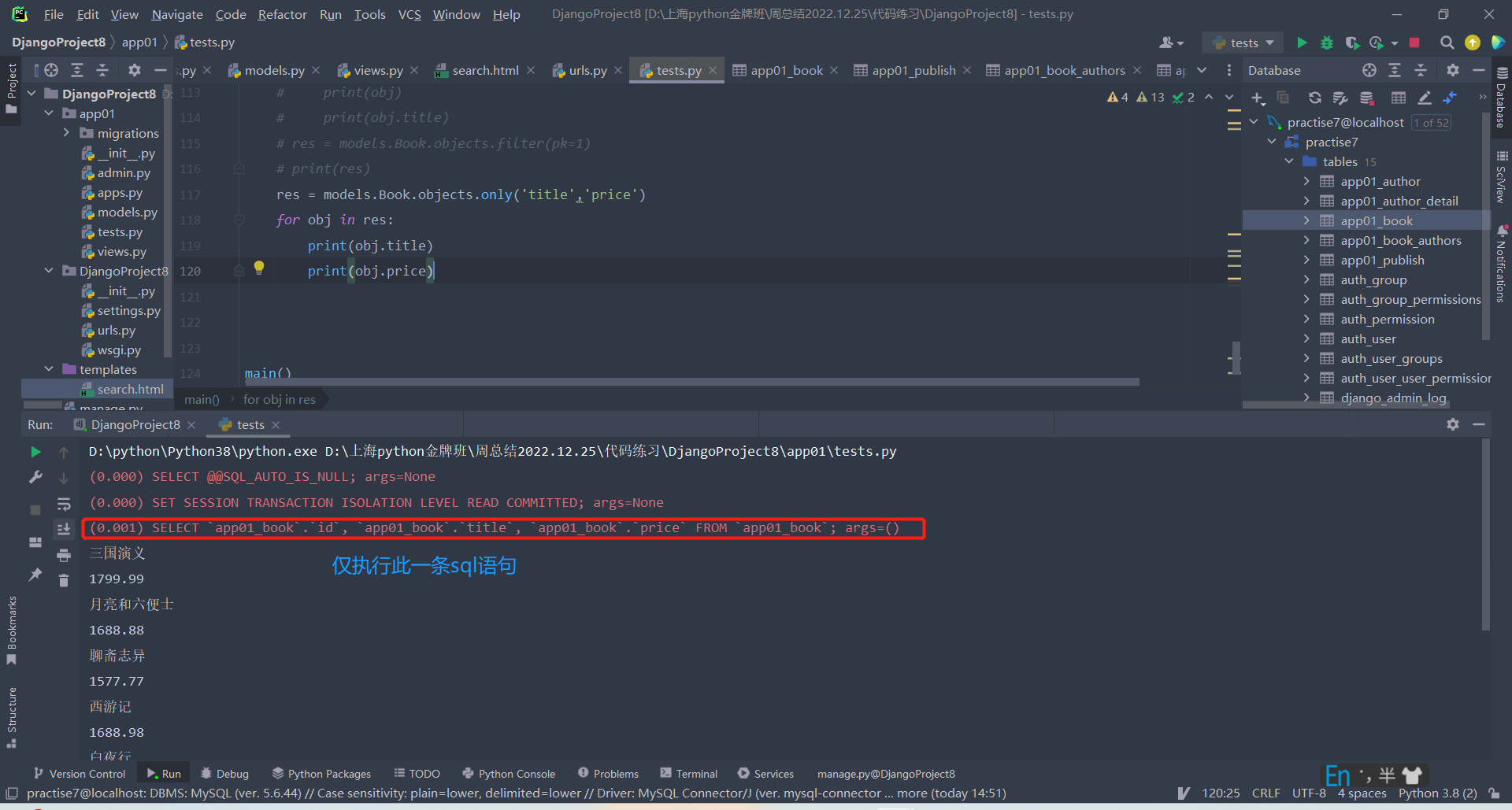
1.only方法可以完美地融合以上两种方法的长处:可以拿到指定的字段名,又可以通过对象名点的方式来拿到对象中的数据(即可以点only括号中有的字段,也可以点括号中没有的字段)。将括号内填写的字段封装到数据对象中,查询括号内填写的字段不需要执行sql语句,查询括号内没有的字段需要执行sql语句:
res = models.Book.objects.only('title','price')
for obj in res: # res是queryset
print(obj) # 书籍对象:三国演义
print(obj.title) # 书籍对象:三国演义
print(obj.price) # 2267.98
运行以上代码只执行了一次sql语句:
如果查找only括号内未声明的字段需要走sql语句:
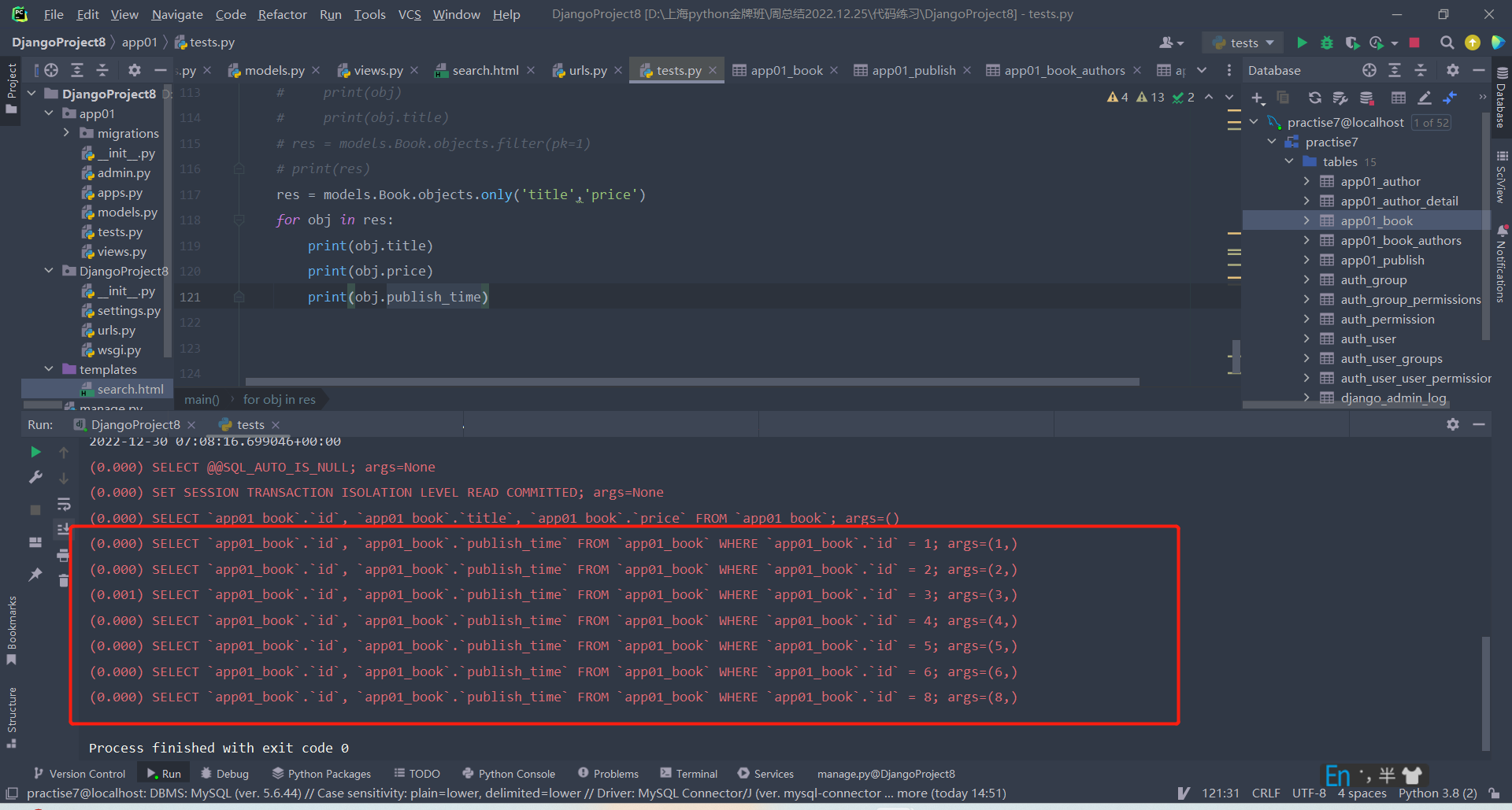
2.defer方法:defer和only相反,defer查找括号内包含的字段时,sql语句会执行,查找括号内不包含的字段时,sql语句不会执行。
res = models.Book.objects.defer('title','price')
for obj in res:
print(obj.title) # 书籍对象:三国演义
print(obj.publish_name)
16.ORM事务操作
"""
1.事务的四大特性(ACID):原子性,一致性,隔离性,持久性
2.相关SQL关键字:
开启事务:start transaction
回滚到上一个状态:rollback
确认事务操作(数据会刷到硬盘):commit
想让事务撤回到指定的点:savepoint
脏读:也叫未提交读。事务中即使修改没有提交,对其他事物都是可见的,事务可以读取未提交的数据:read uncommitted
幻读:所谓幻读指的是当某个事务在读取某个范围内的记录时另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录会产生幻行,InnoDB和XtraDB通过多版本并发控制(MVCC)及间隙锁策略解决该问题。
"""
django中提供了至少三种开启事务的方式:
方式1(全局有效):在settings中的DATABASES中添加以下键值对:'ATOMIC_REQUESTS':True。默认每一次网络请求对应的路由以及ORM操作同属一个事务,如果在一次网络请求中某个位置报错,那么该过程会自动回滚。
例如:我们已经在settings中加入了事物的语句,那么我们执行时只要有一步报错,那么数据就无法添加:
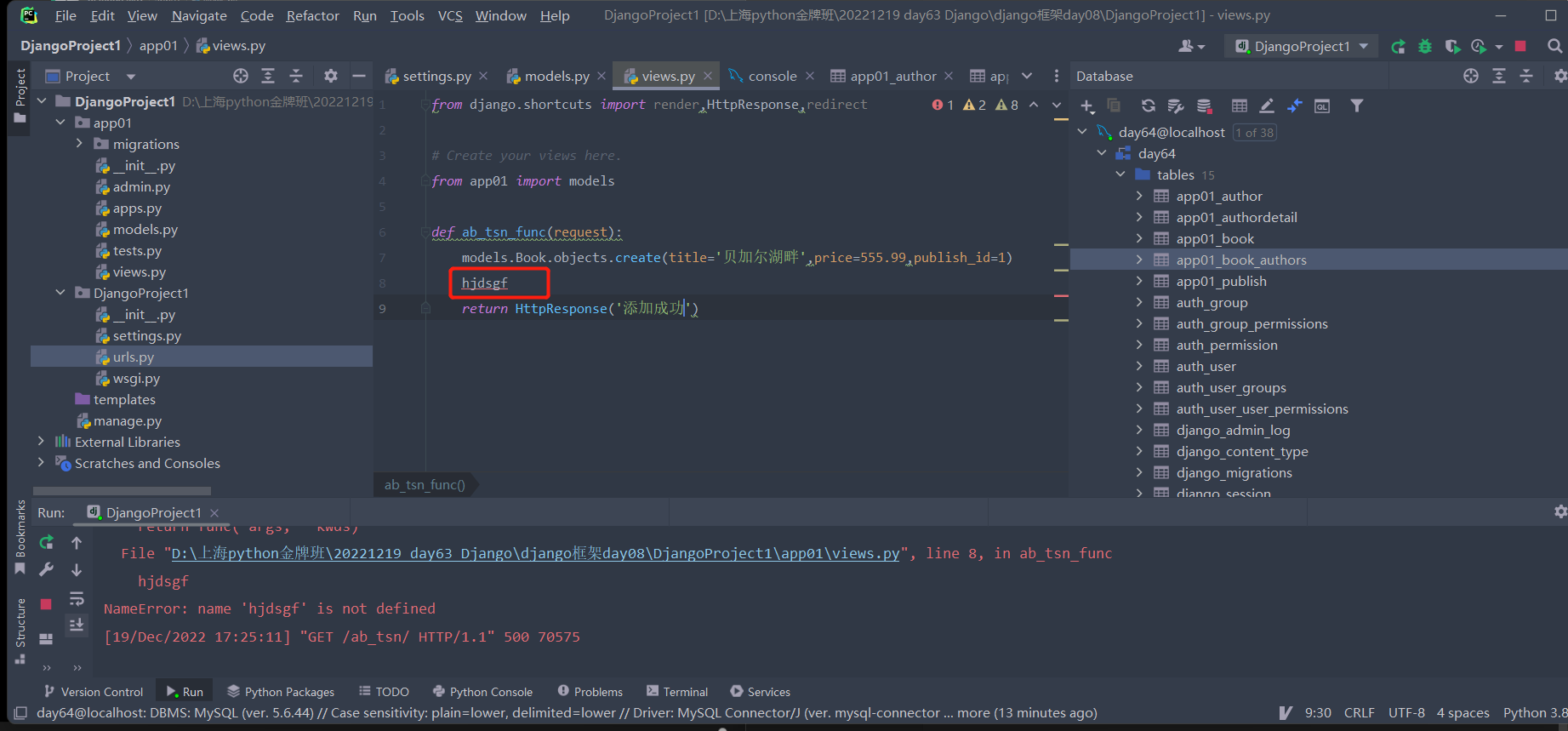
还有一种极限情况:考虑事务的存在,该种情况下并没有返回一个Httpresponce对象,页面上会报错,但是中间并没有打断代码执行的语句,该代码依然会成功添加数据。
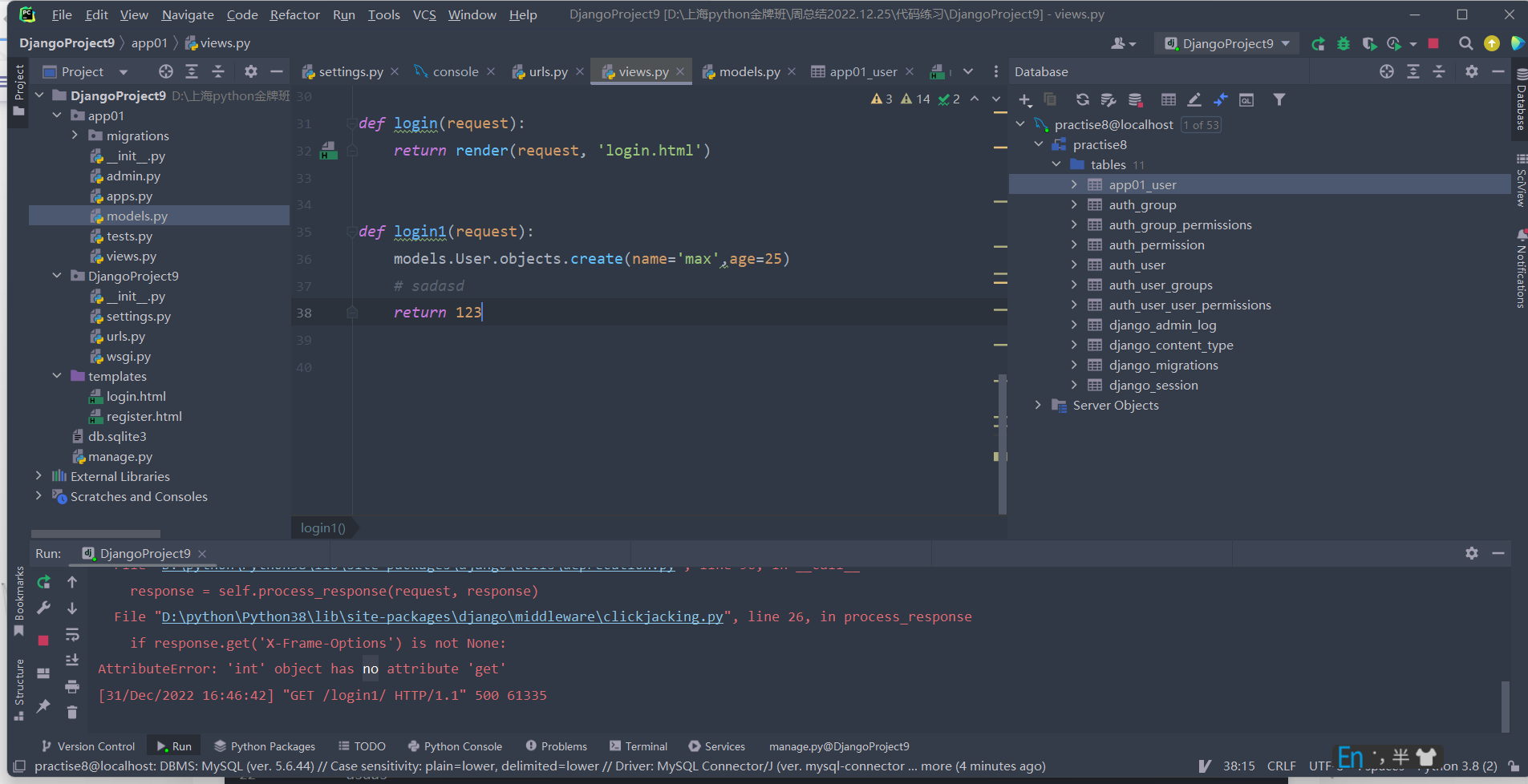
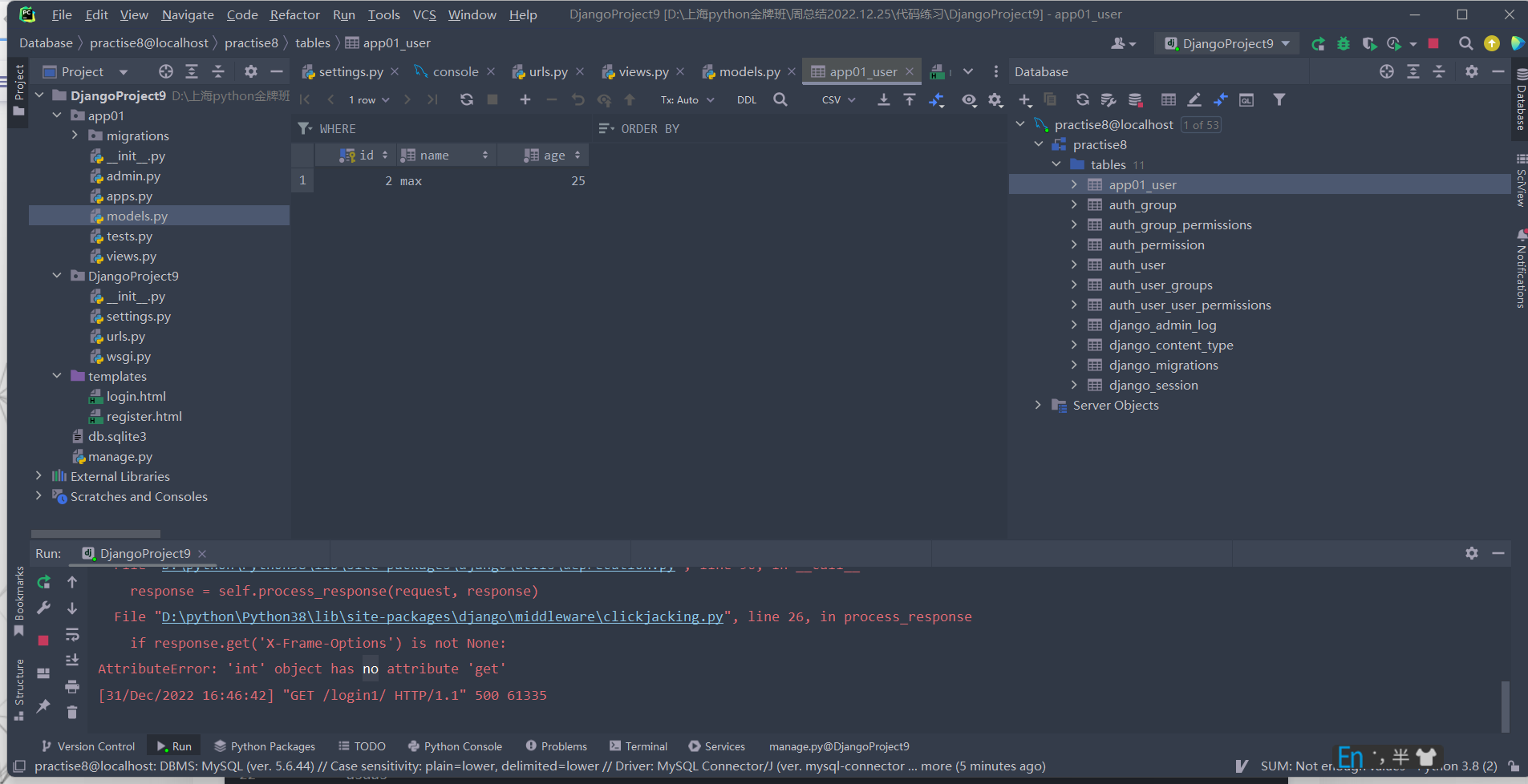
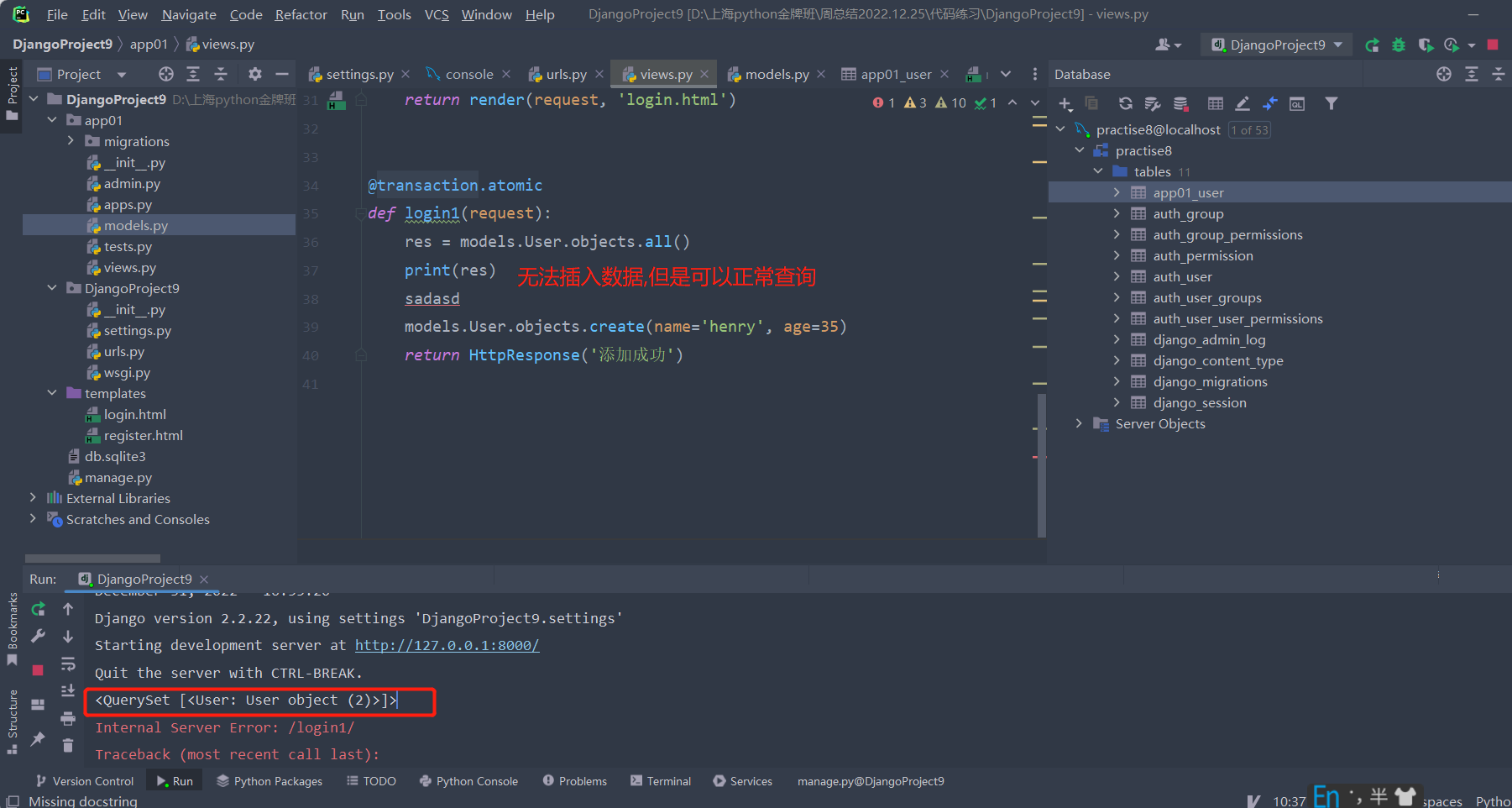
方式2(局部有效):在视图函数上加装饰器,在视图函数分范围内事务有效(事务针对的操作仅限于对ORM的操作,非ORM的操作可以正常执行,视图函数内有一部报错所有ORM操作都回滚,非ORM操作都可以正常执行)。
from django.db import transaction
@transaction.atomic
def index_func(request):
models.Book.objects.create(title='边城',price=555.99,publish_id=2) # 如果改为打印操作可以正常执行
asd
models.Book.objects.create(title='围城',price=555.99,publish_id=2)
return HttpResponse('哈哈哈')
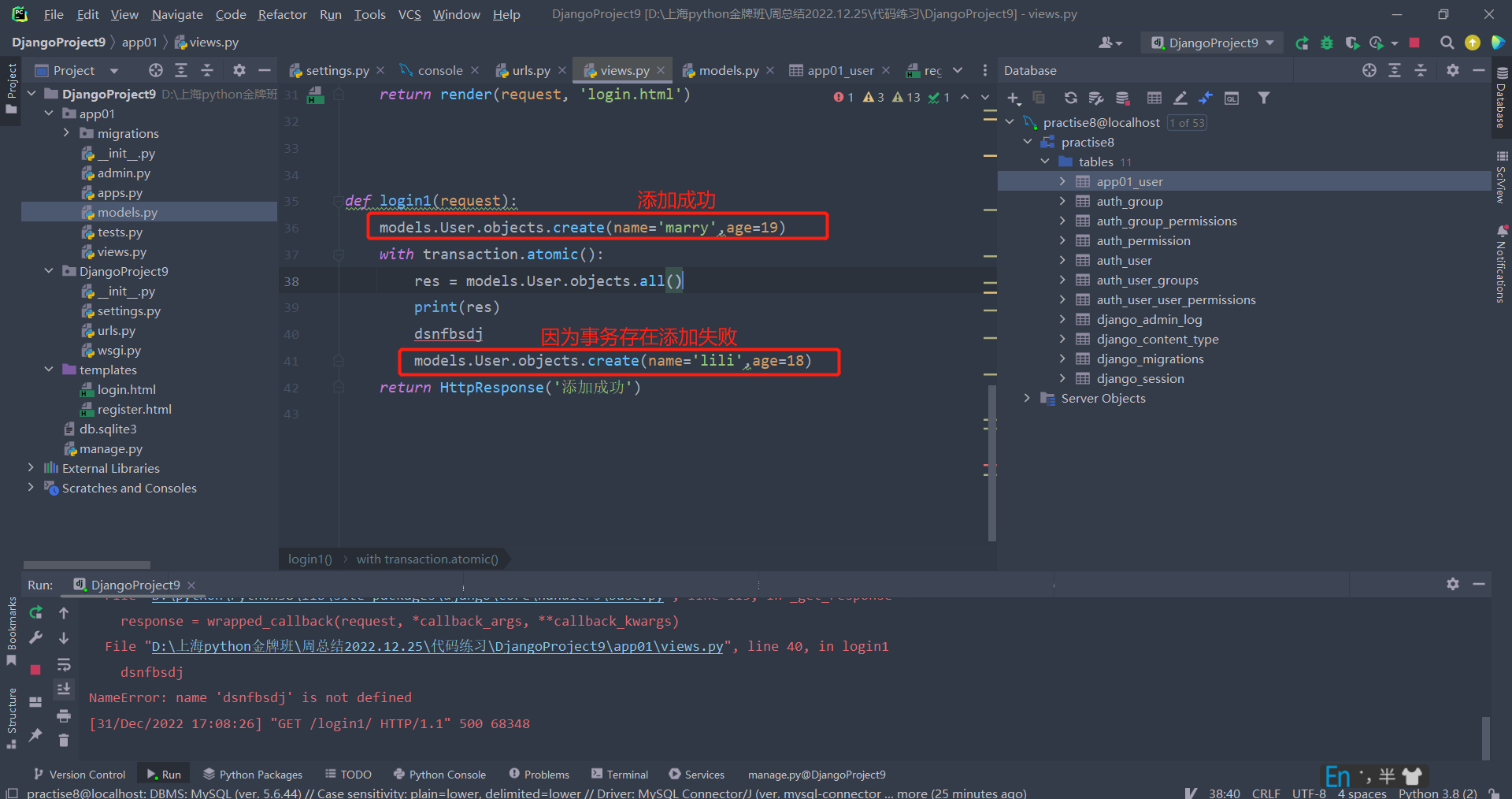
方式3(with上下文管理):将需要添加事务的代码写在with的子代码中,事务操作只会包含with的子代码:
"""
事务特性一致性:一种状态到另一种状态的改变,所以只有删、改、增符合事物的应用范围。
"""
def reg_func(request):
print('111')
models.Book.objects.create(title='边城',price=555.99,publish_id=2) # 可以添加成功
with transaction.atomic():
res = models.Book.objects.filter(pk=1)
print(res)
models.Book.objects.create(title='围城',price=555.99,publish_id=2) # 无法添加成功
asdas
return HttpResponse('哈哈哈')
17.ORM常用字段类型
1.常用字段:
AutoField:自增,必须配合primary_key=True一起使用
CharField:对应mysql中的Varchar,括号内需要指定max_length(一般都不长)
IntegerField:整形(4个字节,32位0或1),表示数字个数:2**32,表示范:-2**31-2**31-1
BigIntegerField:整形(8个字节,64位0或1),表示数字个数:2**64,表示范围:-2**63-2**63-1
SmallIntegerField:整形(2个字节,16位0或1),表示数字个数:2**16,表示范围:-2**15-2**15-1
DecimalField:小数类型,有max_digits和decimal_places两个参数
DateField:日期字段
auto_now:只要是修改就记录时间
auto_now_add:只记录创建时间
DataTimeField:时间字段(同样有auto_now和auto_now_add)
BooleanField:传布尔值(True或False)自动存1或0
TextField:存储大段文本()
EmailField:存储邮箱格式数据
FileField:传文件对象,会自动保存到配置好的路径下
2.ORM还支持用户自定义字段:
class MyCharField(models.Field):
def __init__(self, max_length, *args, **kwargs):
self.max_length = max_length
super().__init__(max_length=max_length, *args, **kwargs)
"""
如果super()括号内有参数,是为了在多继承的情况下查找目标方法。
例如:
super(A,self).create是指去A类的父类中查找create方法。
"""
def db_type(self, connection):
return 'char(%s)' % self.max_length
class User(models.Model):
name = models.CharField(max_length=32)
info = MyCharField(max_length=64)
"""
ORM和MySql数据类型对应关系:
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
"""
18.ORM常用字段参数
primary_key:主键
verbose_name:主键
max_length:字段长度
max_digits:小数总共多少位
decimal_places:小数点后面的位数
auto_now 每次操作数据自动更新事件
auto_now_add 首次创建自动更新事件后续不自动更新
null 允许字段为空
default 字段默认值
unique 唯一值
db_index db_index=True代表给字段添加索引,加快数据查询
choices 当某个字段可能性被列举完全的情况下使用(性别,学历)
"""
models.py:
class User(models.Model):
name = models.CharField(max_length=32)
info = models.TextField(max_length=1024)
gender_choice = (
(1,'男性'),
(2,'女性'),
(3,'其他')
)
gender = models.IntegerField(choices=gender_choice,null=True)
test.py:2023-04-10 21:15:34 星期一
user_obj = models.User.objects.filter(pk=1).first()
print(user_obj.gender) # 1
print(user_obj.get_gender_display()) # 男性
user_obj1 = models.User.objects.filter(pk=4).first()
print(user_obj1.get_gender_display()) # 4 找不到对应关系就还写正常的数字,数字只要符合数据类型都可以添加到表上
"""
to 关联表
to_field 关联字段,不写默认关联主键
on_delete 当删除关联表中的数据时,当前表与其关联的数据同时被删除
1、models.CASCADE
级联操作,当主表中被连接的一条数据删除时,从表中所有与之关联的数据同时被删除
2、models.SET_NULL
当主表中的一行数据删除时,从表中所有与之关联的数据的相关字段设置为null,此时注意定义外键时,这个字段必须可以允许为空
3、models.PROTECT
当主表中的一行数据删除时,由于从表中相关字段是受保护的外键,所以都不允许删除
4、models.SET_DEFAULT
当主表中的一行数据删除时,从表中所有相关的数据的关联字段设置为默认值,此时注意定义外键时,这个外键字段应该有一个默认值
5、models.SET()
当主表中的一条数据删除时,从表中所有的关联数据字段设置为SET()中设置的值,与models.SET_DEFAULT相似,只不过此时从表中的相关字段不需要设置default参数
6、models.DO_NOTHING
什么都不做,一切都看数据库级别的约束,注数据库级别的默认约束为RESTRICT,这个约束与django中的models.PROTECT相似

 浙公网安备 33010602011771号
浙公网安备 33010602011771号