1.常用内置模块之collections模块
1.具名元组:namedtuole:可以使用第一个元素的名字来修饰元组
from collections import namedtuple
point = namedtuple('位置坐标', ['x', 'y'])
p1 = point(4, 6)
print(p1) # 位置坐标(x=4, y=6)
print(p1.x) # 4
print(p1.y) # 6
card = namedtuple('组合', ['num', 'color'])
c1 = card('J', '黑桃')
c2 = card('k', '红桃')
print(c1.num, c1.color) # J 黑桃
2.队列
队列与堆栈
队列:先进先出
堆栈:先进后出
队列和堆栈都是一边只能进一边只能出
3.deque模块:我们在对元祖首位的文件增删时之前的方法较为麻烦,可以调用deque实现首尾高效增删(适用于队列和栈)
from collections import deque
q = deque(['jason', 'jerry', 'kitty'])
q.append('janny')
q.appendleft('max')
print(q) # deque(['max', 'jason', 'jerry', 'kitty', 'janny'])
q.pop()
q.popleft()
print(q) # deque(['jason', 'jerry', 'kitty'])
4.queue遵循先进先出原则,先进入的先删除。put()是增加,get()是删除
from multiprocessing import Queue
q = Queue(4)
q.put(11) # 插入元素
q.put(22)
q.put(33)
q.put(44)
q.put(55)
print(q.get()) # 增加的元素数量多于限制数量,无法打印
from multiprocessing import Queue
q = Queue(4)
q.put(11) # 插入元素
q.put(22)
q.put(33)
q.put(44)
q.get()
q.put(55)
print(q.get()) # 22 删除一个元素才能继续添加,此时22提到最前面,55加入列表,再删除就是删除22
5.OrderDict:使用是dict是无序的,我们想要使dict变得有顺序可以使用OrderDict,添加顺序越前顺序就越靠前
from collections import OrderedDict
od = OrderedDict()
od['name'] = 'max'
od['hobby'] = 'soccer'
od['base'] = 'Shanghai'
print(od) # OrderedDict([('name', 'max'), ('hobby', 'soccer'), ('base', 'Shanghai')])
6.Counter:Counter是用来跟踪值出现的次数,以字典键值对的形式存储
from collections import Counter
c = Counter('jkadfyhjksdbvsfdfs')
print(c) # Counter({'d': 3, 'f': 3, 's': 3, 'j': 2, 'k': 2, 'a': 1, 'y': 1, 'h': 1, 'b': 1, 'v': 1})
2.常用内置模块之时间模块-import time
1.时间戳:表示的是从1970年1月1日00:00:00开始按秒计算的偏移量,我们运行“type(time.time())”,返回的是float类型
import time
print(time.time()) # 1666171837.1783726
start_time = time.time()
print('看看这个程序执行需要多久')
time.sleep(3)
end_time = time.time()
print('执行时间', end_time - start_time)
import time
print(type(time.time())) # <class 'float'>
2.结构化时间:主要是给计算机看的,其中tm_wday是星期(从0开始计),0代表星期一,6代表星期天。tm_yday代表一年当中的第几天
print(time.localtime()) # time.struct_time(tm_year=2022, tm_mon=10, tm_mday=19, tm_hour=18, tm_min=33, tm_sec=2, tm_wday=2, tm_yday=292, tm_isdst=0)
3.格式化时间:主要是给人看的,类似以格式化输出,连接符可以自定义
import time
print(time.strftime('%Y-%m-%d')) # 2022-10-19
print(time.strftime('%Y/%m/%d')) # 2022/10/19
print(time.strftime('%Y/%m/%m %H:%M:%S')) # 2022/10/10 18:29:14
print(time.strftime('%Y/%m/%d %X')) # 2022/10/19 18:30:30
print(time.strftime('%Y-%m')) # 2022-10
| 索引(Index) |
属性(Attribute) |
值(Values) |
| 0 |
tm_year(年) |
比如2011 |
| 1 |
tm_mon(月) |
1 - 12 |
| 2 |
tm_mday(日) |
1 - 31 |
| 3 |
tm_hour(时) |
0 - 23 |
| 4 |
tm_min(分) |
0 - 59 |
| 5 |
tm_sec(秒) |
0 - 60 |
| 6 |
tm_wday(weekday) |
0 - 6(0表示周一) |
| 7 |
tm_yday(一年中的第几天) |
1 - 366 |
| 8 |
tm_isdst(是否是夏令时) |
默认为0 |
3.常用内置模块之时间模块-import datatime
1.datetime和date的区别在于datetime.now()和datetime.today()都会精确到秒。而date只会精确到日
import datetime
datetime.now():获取当前datetime
print(datetime.datetime.now()) # 2022-10-19 18:47:52.303691
print(datetime.datetime.today()) # 2022-10-19 18:47:52.303692
print(datetime.date.today()) # 2022-10-19
2.date.utcnow():获取获取当前格林威治时间
from datetime import datetime
print(datetime.utcnow()) # 2022-10-19 10:58:23.396622
3.datetime(五个参数):获取指定时间
from datetime import datetime
c = datetime(2019, 6, 15, 20, 58)
print(c) # 2019-06-15 20:58:00
4.将字符串转换成标准格式时间:
from datetime import datetime
d = datetime.strptime('2017/9/30','%Y/%m/%d')
print(d) # 2017-09-30 00:00:00
e = datetime.strptime('2019/5/1', '%Y/%m/%d')
print(e) # 2019-05-01 00:00:00
f = datetime.strptime('2017年9月30日星期六', '%Y年%m月%d日星期六')
print(f) # 2017-09-30 00:00:00
5.计划指定时间任务
import datetime
ctime = datetime.date.today()
print(ctime) # 2022-10-19
del_time = datetime.timedelta(days=3)
print(ctime + del_time) # 2022-10-22
import datetime
ctime = datetime.datetime.today()
print(ctime) # 2022-10-19 19:19:37.132740
del_time = datetime.timedelta(minutes=3)
print(ctime + del_time) # 2022-10-19 19:22:37.132740
4.常用内置模块之随机数模块
1.产生0-1随机的小数
import random
print(random.random()) # 0.7536697184640402
2.随机产生整数(首尾都包含)(摇骰子)
print(random.randint(1,6)) # 4
3.随机产生一个小数(包含首尾)
import random
print(random.uniform(1,10)) # 4.899414993170175
4.随机产生范围中一个数,间隔(步长)为2
print(random.randrange(1,20,2)) # 9
5.随机抽取列表当中一个元素,几率相等
print(random.choice(['一等奖', '二等奖', '三等奖', '谢谢惠顾'])) # 一等奖
print(random.choices(['一等奖', '二等奖', '三等奖', '谢谢惠顾'])) # ['二等奖']
"""
choices会保留数据类型,choice不会
"""
6.choice.sample:
用法一:随机抽取列表当中几个数据值,可以指定数量
print(random.sample(['jason', 'jerry','tony', 'max'], 2)) # ['max', 'tony']
用法二:sample第一个参数可以传多个类型,string.ascii_uppercase是字符串的大写字母,string.digits是字符串的数字,string.ascii_lowercase是字符串的小写字母,第二个参数是每个字符串有几位组成:
import random
import string
str_list = ["".join(random.sample(string.ascii_uppercase + string.digits + string.ascii_lowercase, 5)) for i in range(5)]
print(str_list) # ['h2WLe', 'kJA1o', 'LASoD', 'uzY7P', '1F7Uq']
7.打乱列表当中数据值的顺序:random.shuffle()(洗牌)
l1 = [1,2,3,4,5,6,7,8,9,10,'J','Q','K']
random.shuffle(l1) # 不能直接打印,要先修改再打印
print(l1) # [4, 2, 3, 7, 9, 1, 8, 10, 6, 'J', 'K', 5, 'Q']
8.产生随机验证码,每一位都可以是大小写、字母
def get_code(n):
code = ''
for i in range(n):
random_upper = chr(random.randint(65, 90)) # 随机产生大写字母
randon_lower = chr(random.randint(97,112)) # 随机产生小写字母
randon_int = str(random.randint(0,9)) # 随机产生整数
temp = random.choice([random_upper, randon_lower,randon_int]) # 三选一
code += temp # 字符串相加
return code
res = get_code(4)
print(res)
4.OS模块
os模块主要与代码运行所在的操作系统打交道
引入模块:import os
1.创建目录(文件夹):在执行文件所在的路径下创建目录,可以创建单级目录
1.1:os.mkdir()
os.mkdir(r'd1')
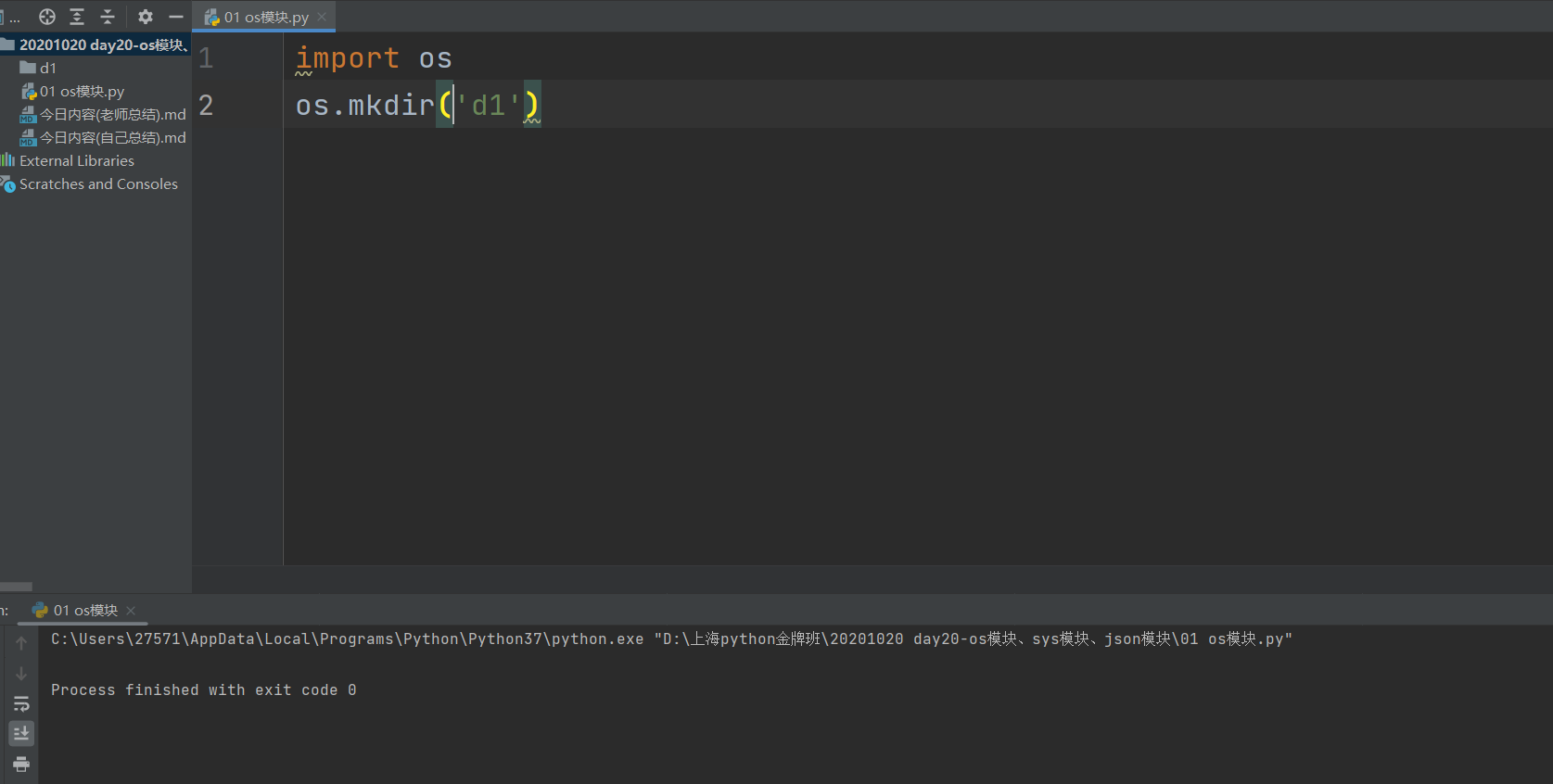
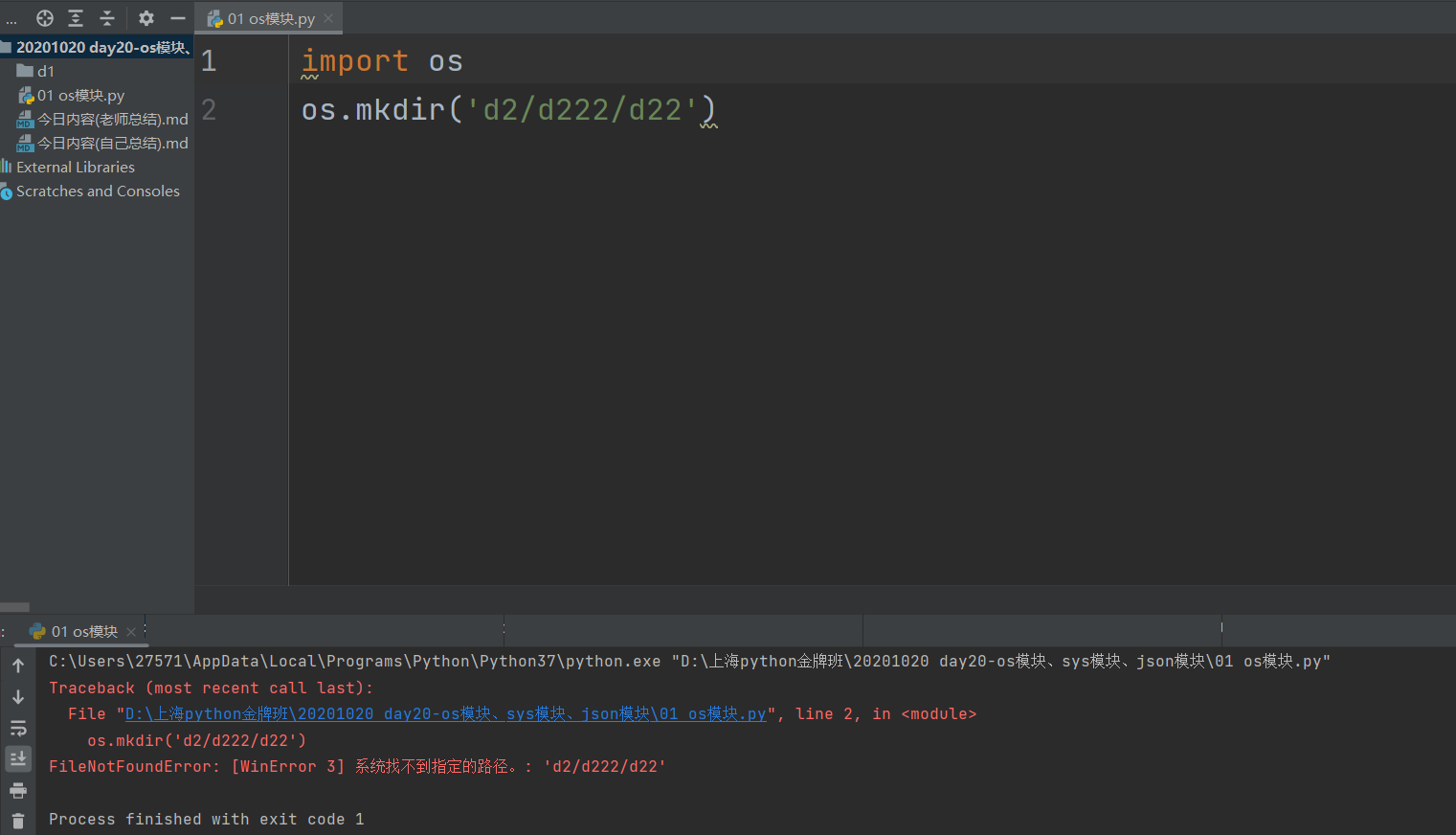
os,mkdir(r'd2\d222\d22'') # mkdir创建多级目录会报错
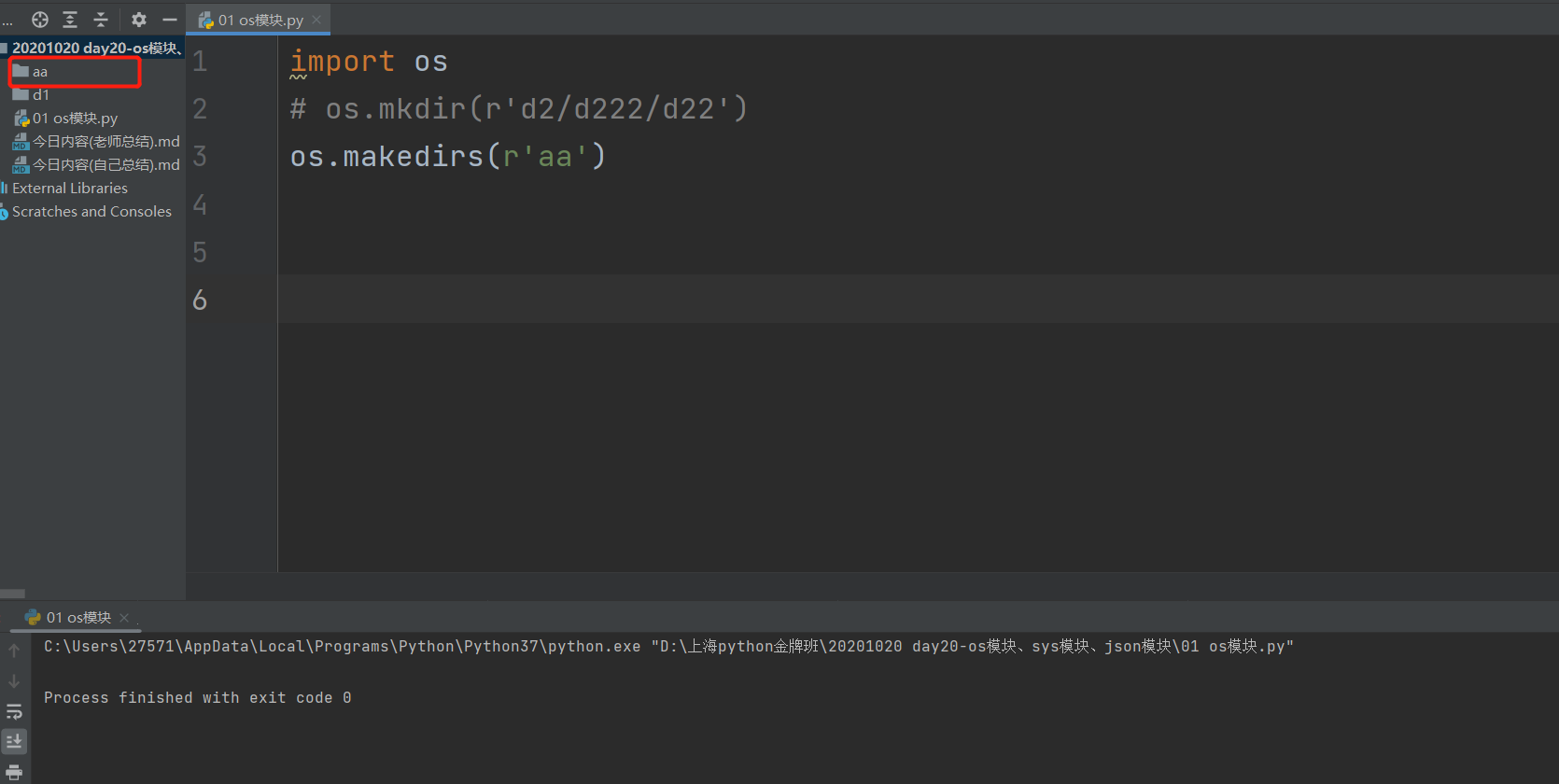
1.2:os.makedirs()
os.makedirs(r'aa')
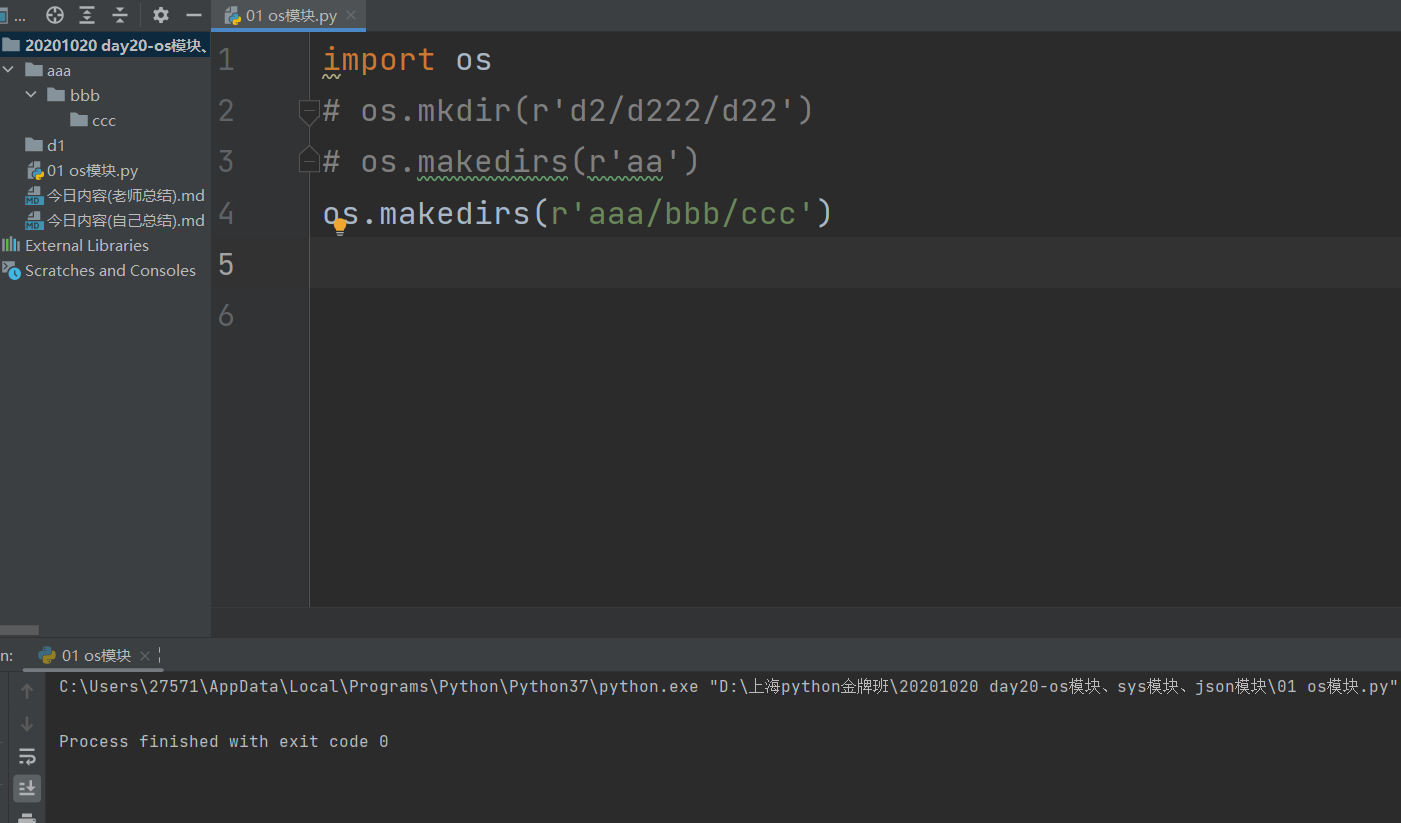
os.makedirs(r'aaa\bbb\ccc') # makedirs可以创建多级目录
2.删除目录
2.1:os.rmdir
os.rmdir(r'a') # 可以删除单级目录
os.rmdir(r'aaa\bbb\ccc') # 不能一次性删除多级目录
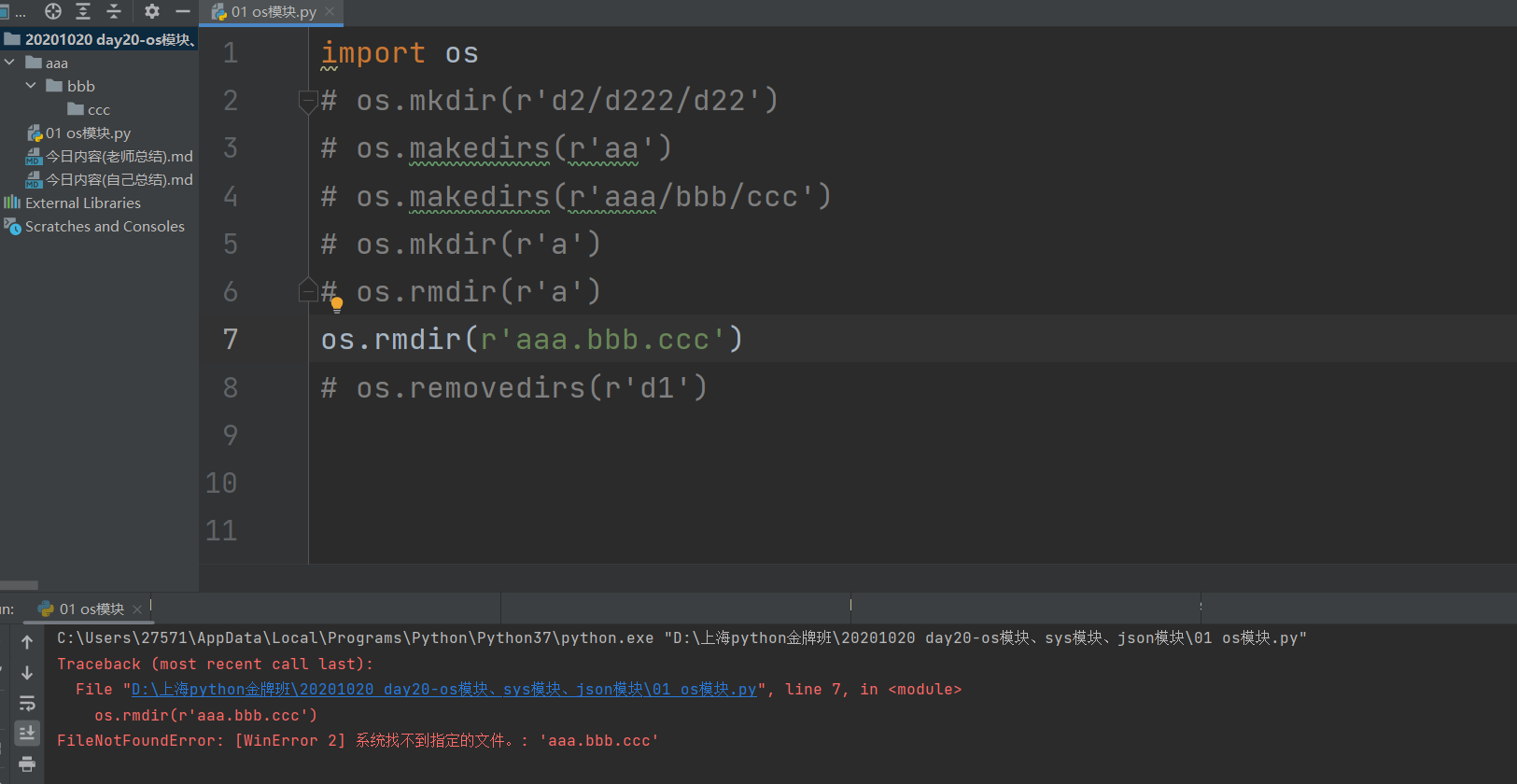
os.removedirs(r'd1') # 可以删除单级目录
os.removedirs(r'aaa\bbb\ccc') # 如果bbb,ccc是单级目录,也就是bbb是aaa下面唯一的文件,ccc是bbb里面唯一的文件,可以删除多级目录
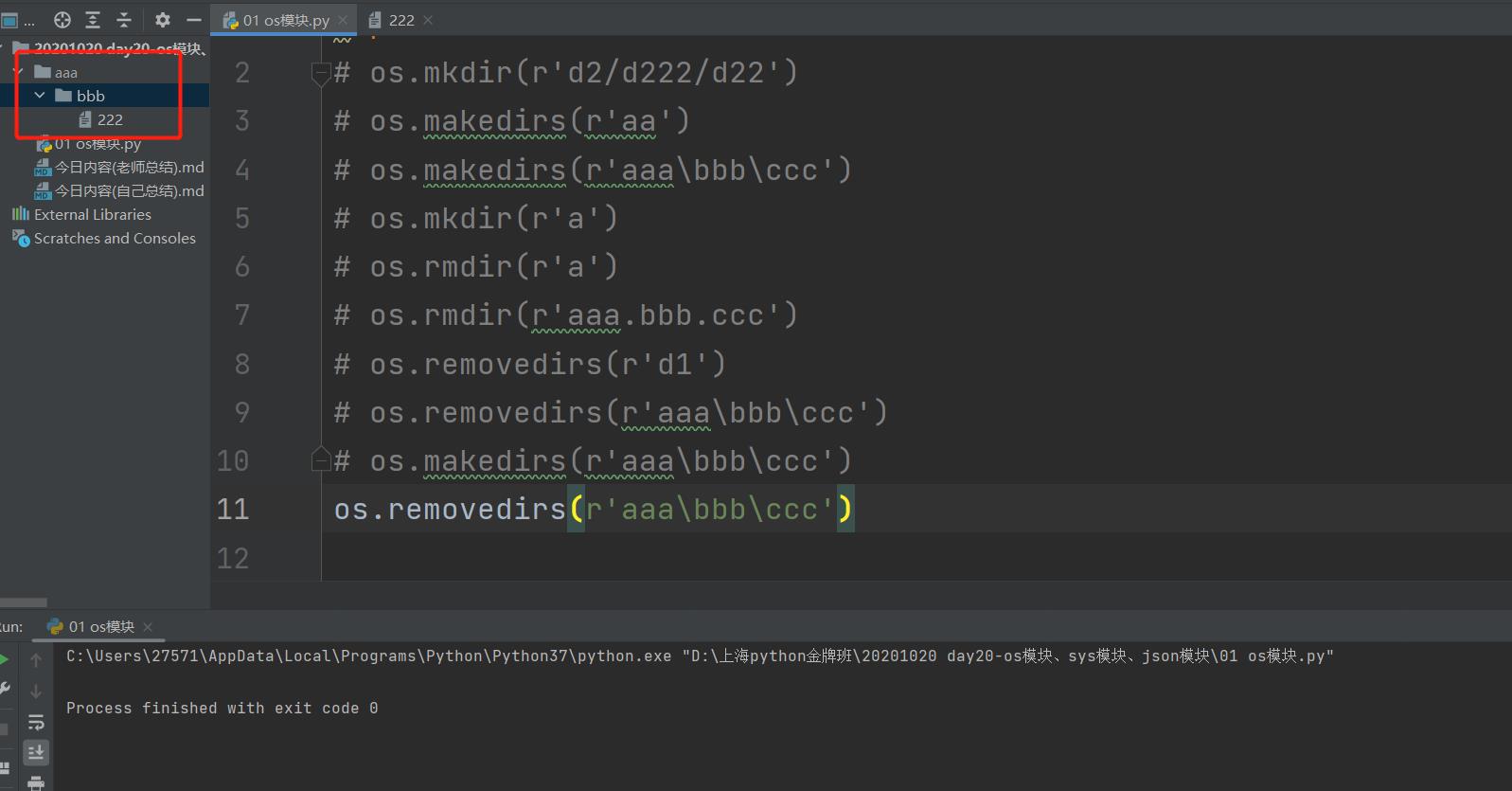
os.removedirs(r'aaa\bbb\ccc') # 但是如果bbb下面有其他文件,ccc是是空目录,那么只能删除ccc
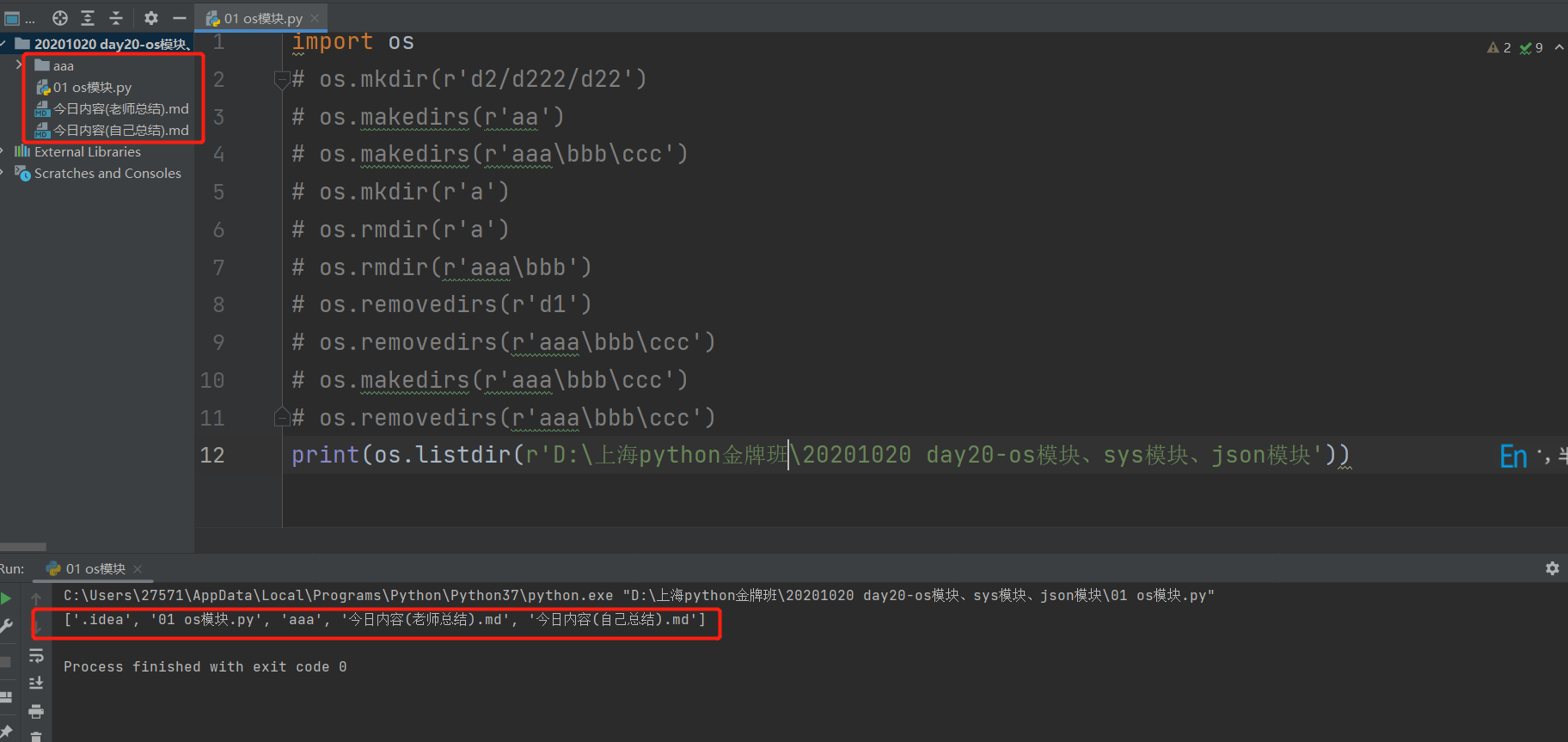
3.列举指定路径下的内容名称:os.listdir() (只能写绝对路径)
print(os.listdir(r'D:\上海python金牌班\20201020 day20-os模块、sys模块、json模块'))
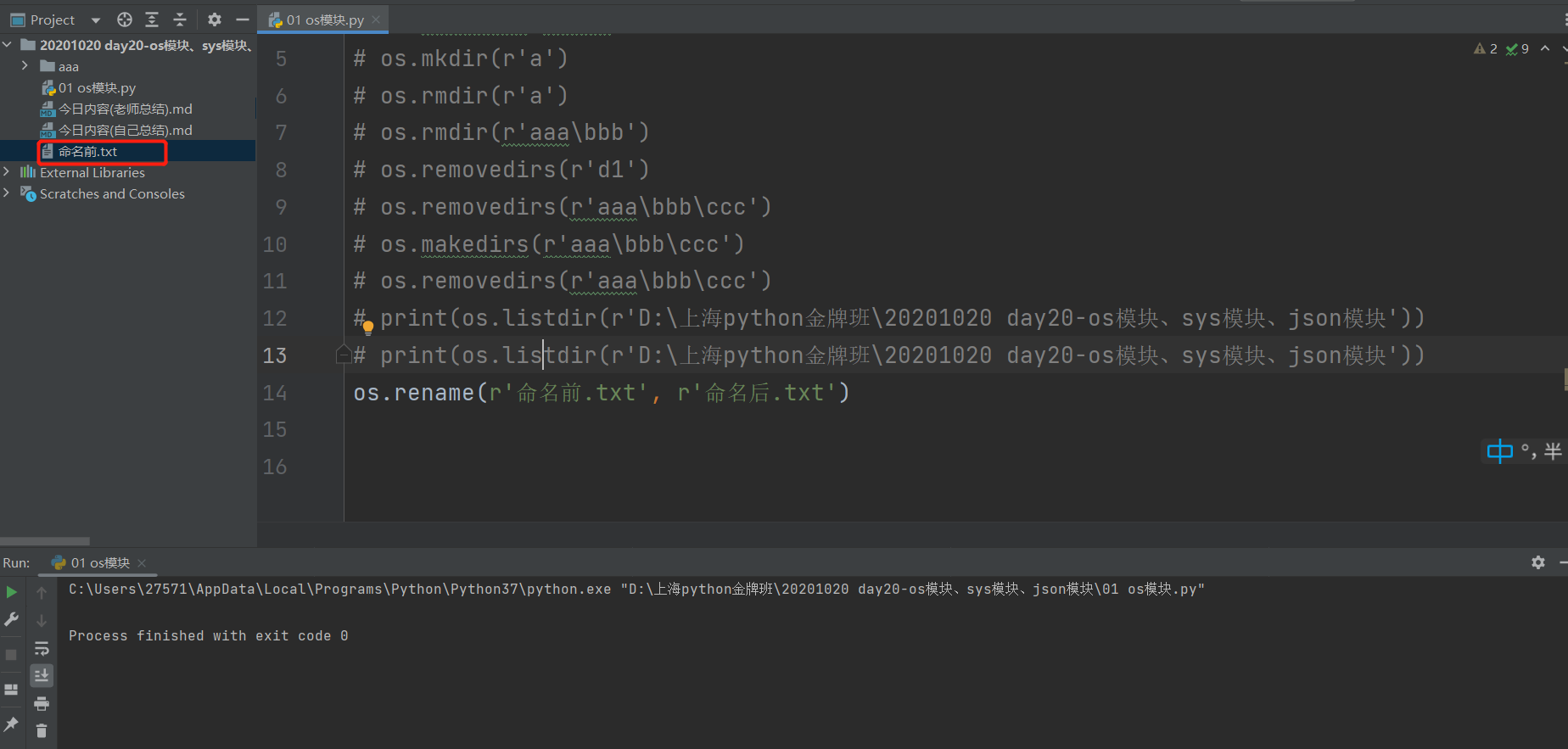
4.删除/重命名文件(文件和目录要区分清楚)
重命名:
os.rename(r'命名前.txt', r'命名后.txt')
os.remove(r'D:\上海python金牌班\20201020 day20-os模块、sys模块、json模块\命名后.txt') # 也可以写相对路径
5.获取当前工作目录(文件夹目录不是文件目录)
print(os.getcwd()) # D:\上海python金牌班\20201020 day20-os模块、sys模块、json模块
6.动态获取项目根路径(非常重要)
6.1获取文件路径:
print(os.path.abspath(__file__)) # D:\上海python金牌班\20201020 day20-os模块、sys模块、json模块\01 os模块.py
6.2获取目录路径
print(os.path.dirname(__file__)) # D:\上海python金牌班\20201020 day20-os模块、sys模块、json模块
7.判断路径是否存在:文件、目录都可以判断
print(os.path.exists(r'01 os模块.py')) # True
print(os.path.exists(r'D:\上海python金牌班\20201020 day20-os模块、sys模块、json模块')) # True
print(os.path.exists(r'D:\上海python金牌班')) # True
8.判断路径是否文件:可以写绝对路径或相对路径
print(os.path.isfile(r'01 os模块.py')) # True
print(os.path.isfile(r'D:\上海python金牌班\20201020 day20-os模块、sys模块、json模块\01 os模块.py')) # True
9.路径拼接(非常重要):不同操作系统的路径分隔符不一样,按照以下方式可以兼容不同系统
s1 = r'01 os模块.py'
s2 = r'D:\上海python金牌班\20201020 day20-os模块、sys模块、json模块\aaa'
print(os.path.join(s1, s2)) # D:\上海python金牌班\20201020 day20-os模块、sys模块、json模块\aaa
10.获取文件大小(字节)
print(os.path.getsize(r'01 os模块.py')) # 1601
print(os.path.getsize(r'a.txt')) # 12
"""
a.txt中字符:qqq哈哈哈;1个汉字占3个字节,1个字母占1个字节
"""
5.sys模块
引入模块: import sys
sys.path:系统环境变量,里面第一个路径一般是执行文件的路径
1.获取python解释器最大递归深度
print(sys.getrecursionlimit()) # 1000
2.修改解释器最大递归深度,运行会返回None代表已修改
print(sys.setrecursionlimit(2000)) # None
3.获取解释器版本
print(sys.version)
4.获取平台信息
print(sys.platform) # win32
5.sys,argv:打印返回的是一个列表
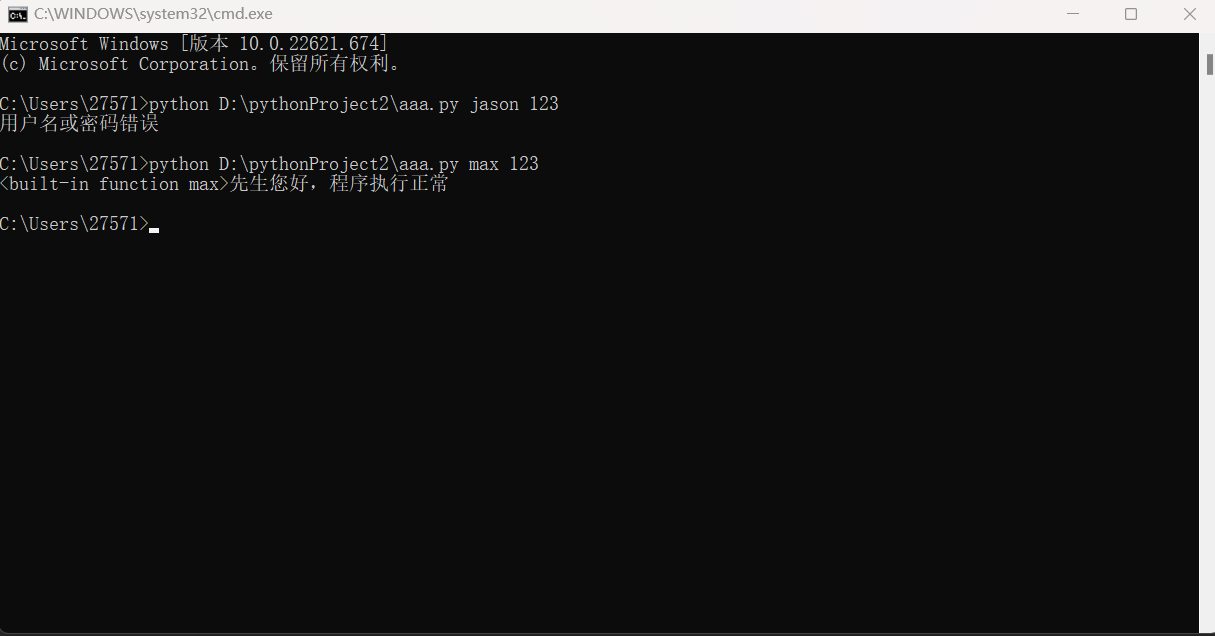
print(sys.argv) # ['D:\\上海python金牌班\\20201020 day20-os模块、sys模块、json模块\\02 sys模块.py']
列表当中的元素是当前执行文件的路径,该列表可以在cmd窗口中添加元素,并且在pycharm中执行代码校验信息并且执行相应功能。在cmd窗口添加元素格式为:python 文件绝对路径 元素1 元素2,元素1和元素2是需要校验的信息
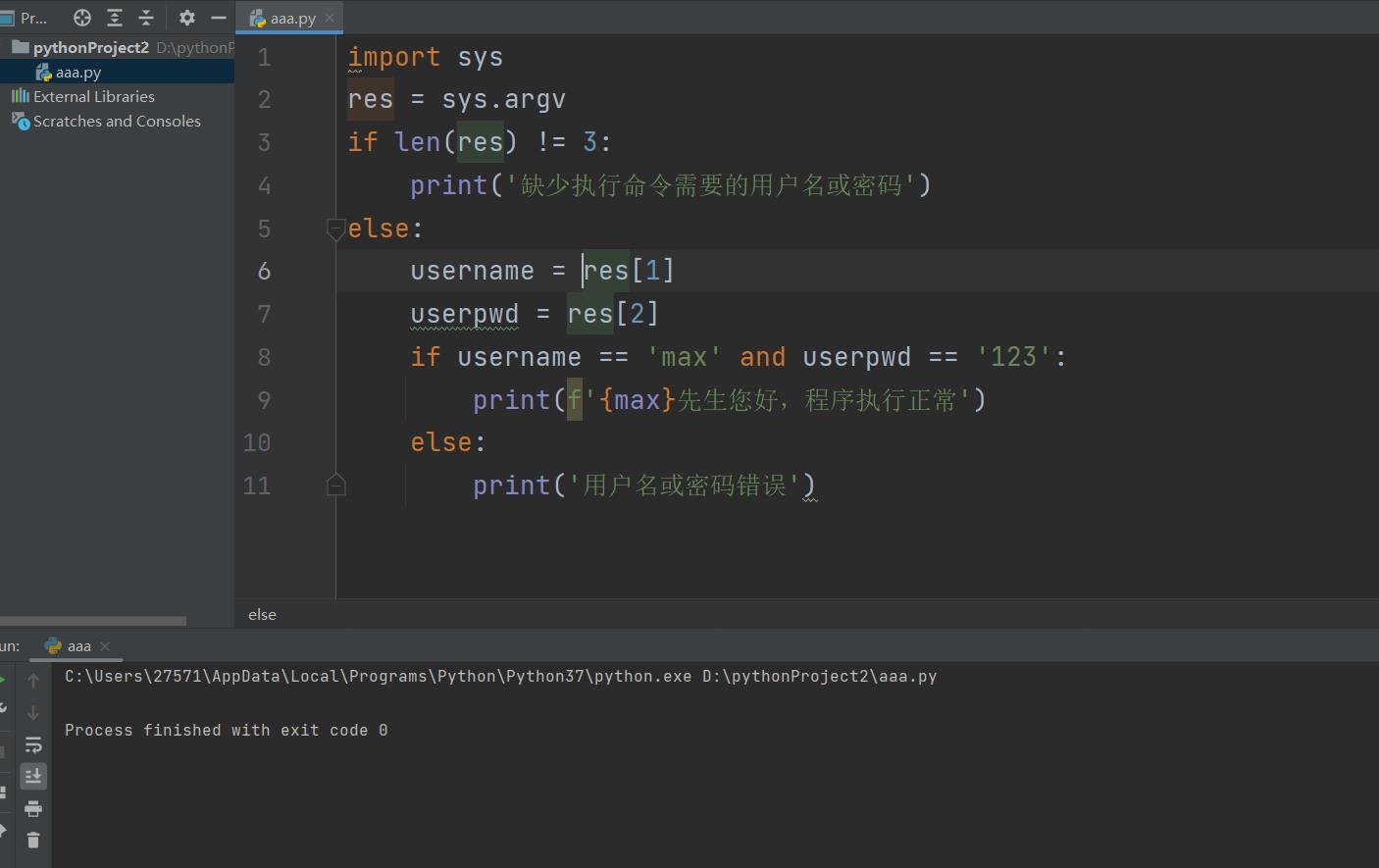
import sys
res = sys.argv
if len(res) != 3:
print('缺少执行命令需要的用户名或密码')
else:
username = res[1]
userpwd = res[2]
if username == 'max' and userpwd == '123':
print(f'{max}先生您好,程序执行正常')
else:
print('用户名或密码错误')
6.json模块
1.json模块也称为序列化模块,序列化可以打破语言限制实现不同编程语言之间数据交互。python数据类型和JS中的自定义对象表现形式相同,但它们属于不同的语言,需要一个媒介来互相转换。将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化,相反的过程叫做反序列化
2.json格式数据的作用:实现不同语言的数据交互
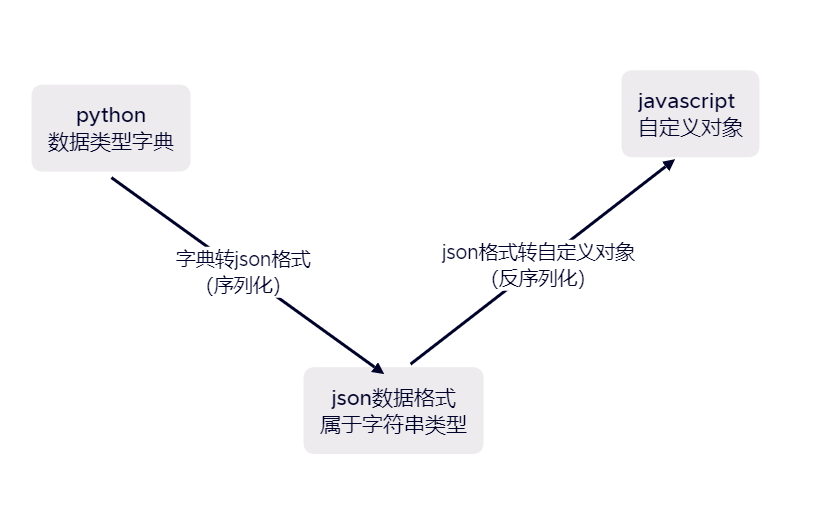
3.json数据类型格式:字符串并且都是双引号
4.json相关操作
针对数据
json.dumps()
json.loads()
针对文件
json.dump()
json.load()
5.如何把字典转成json格式(str)然后再转回字典(dict)
import json
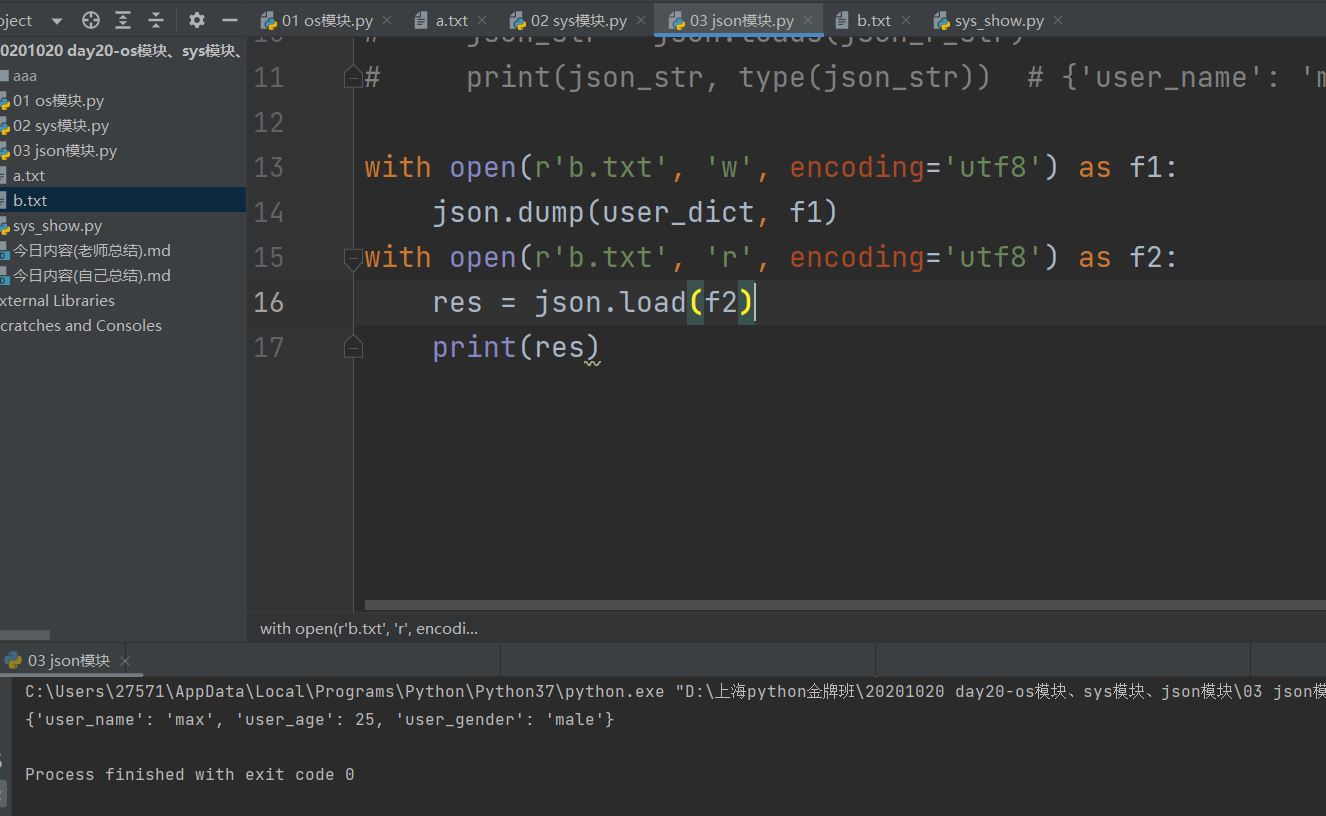
user_dict = {'user_name': 'max', 'user_age': 25, 'user_gender':'male'}
with open(r'b.txt', 'w', encoding='utf8') as f1:
json_w_str = json.dumps(user_dict)
f1.write(json_w_str)
with open(r'b.txt', 'r', encoding='utf8') as f2:
json_r_str = f2.read()
json_str = json.loads(json_r_str)
print(json_str, type(json_str)) # {'user_name': 'max', 'user_age': 25, 'user_gender': 'male'}
"""
当json模块结合文件一起用时,可以将"序列化"、"写入"结合成一行代码:
json.dump(iser_dict. f1)
也可以将"反序列化"、"读"结合携程一行代码:
json.load(f2)
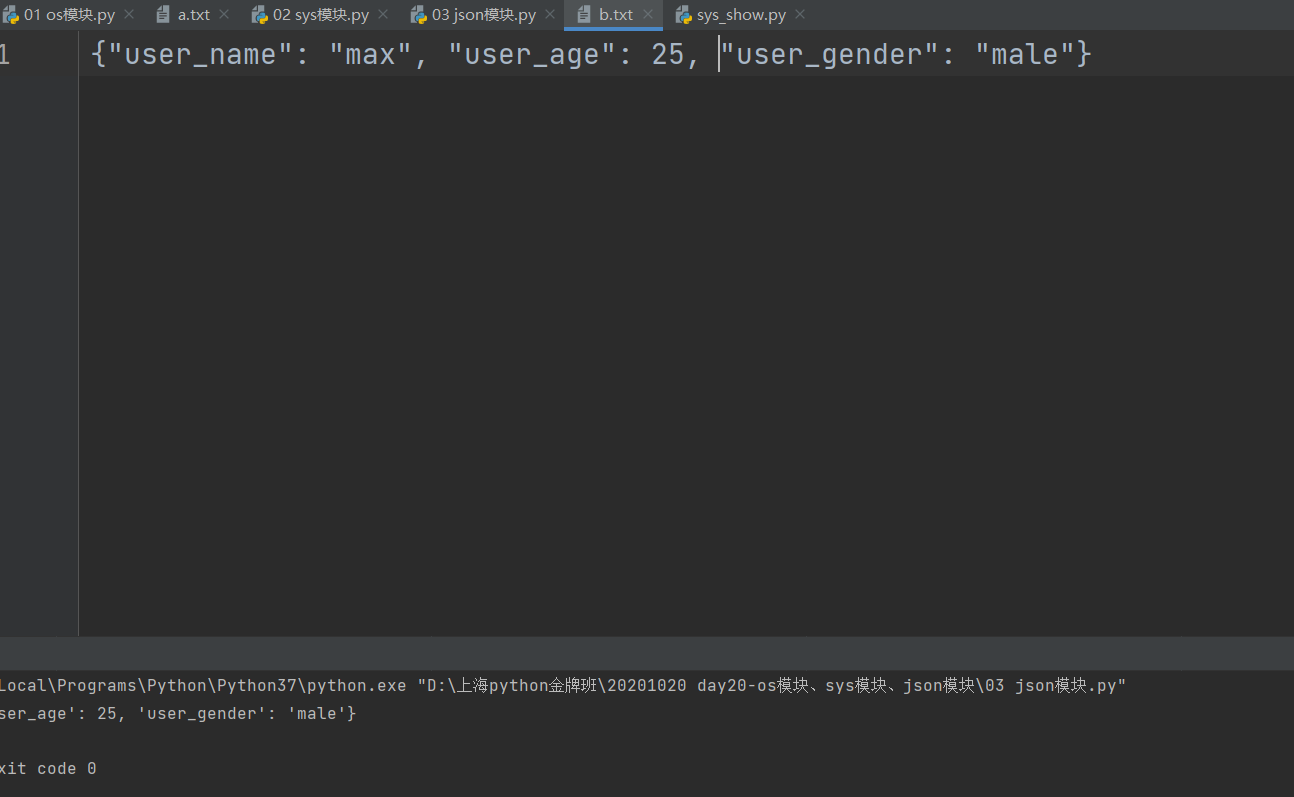
with open(r'b.txt', 'w', encoding='utf8') as f1:
json.dump(user_dict, f1)
with open(r'b.txt', 'r', encoding='utf8') as f2:
res = json.load(f2)
print(res)
"""
7.json实战
import os
import json
while True:
print("""
1.注册
2.登陆
""")
choice = input('请输入您的任务编号>>>:').strip()
if choice == '1':
base_order = os.path.dirname(__file__) # 1.获取当前路径
ds_dir = os.path.join(base_order, 'db') # 2.拼接路径:D:\上海python金牌班\20201020 day20-os模块、sys模块、json模块\db
if not os.path.exists(ds_dir): # 3.判断db文件是否存在
os.mkdir(ds_dir) # 4.若不存在则新增db文件
user_name = input('请输入您的用户名>>>:').strip() # 5.获取用户输入
judge_name = f'{user_name}.json' # 6.拼接字符串,用来判断用户名命名的文件是否存在
if judge_name in os.listdir(ds_dir): # 7.存在则提示已注册
print('您的信息已注册')
else:
user_pwd = input('请输入您的密码>>>:').strip() # 8.不存在则输入密码
user_dict = { # 9.构造用户字典
'username':user_name,
'userpwd':user_pwd
}
user_file_path = os.path.join(ds_dir, f'{user_name}.json') # 10.构造用户数据路径:拼接路径:D:\上海python金牌班\20201020 day20-os模块、sys模块、json模块\db\jason.json
with open (user_file_path, 'w', encoding='utf8') as f1:
json.dump(user_dict, f1)
print(f'用户{user_name}注册成功')
elif choice == '2':
load_name = input('请输入您的用户名>>>:').strip() # 1.获取用户名
base_order = os.path.dirname(__file__) # 2.获取当前路径
ds_dir = os.path.join(base_order, 'db') # 3.路径加\db
load_user_path = os.path.join(ds_dir, f'{load_name}.json') # 4.拼接字符串,用来判断用户名命名的文件是否存在
if not os.path.isfile(load_user_path): # 5.如果不存在提示用户
print('该用户未注册')
else:
load_pwd = input('请输入您的密码>>>:').strip() # 6.如果存在输入密码
with open(load_user_path, 'r', encoding='utf8') as f2:
real_dict = json.load(f2) # 7.把字符串信息文件转成字典,对比
if load_name == real_dict.get('username') and load_pwd == real_dict.get('userpwd'):
print('登陆成功')
else:
print('密码错误')
8.作业
"""
1.编程小练习
有一个目录文件下面有一堆文本文件
eg:
db目录
J老师视频合集
R老师视频合集
C老师视频合集
B老师视频合集
文件内容自定义即可 要求循环打印出db目录下所有的文件名称让用户选择
用户选择哪个文件就自动打开该文件并展示内容
涉及到文件路径全部使用代码自动生成 不准直接拷贝当前计算机固定路径
"""
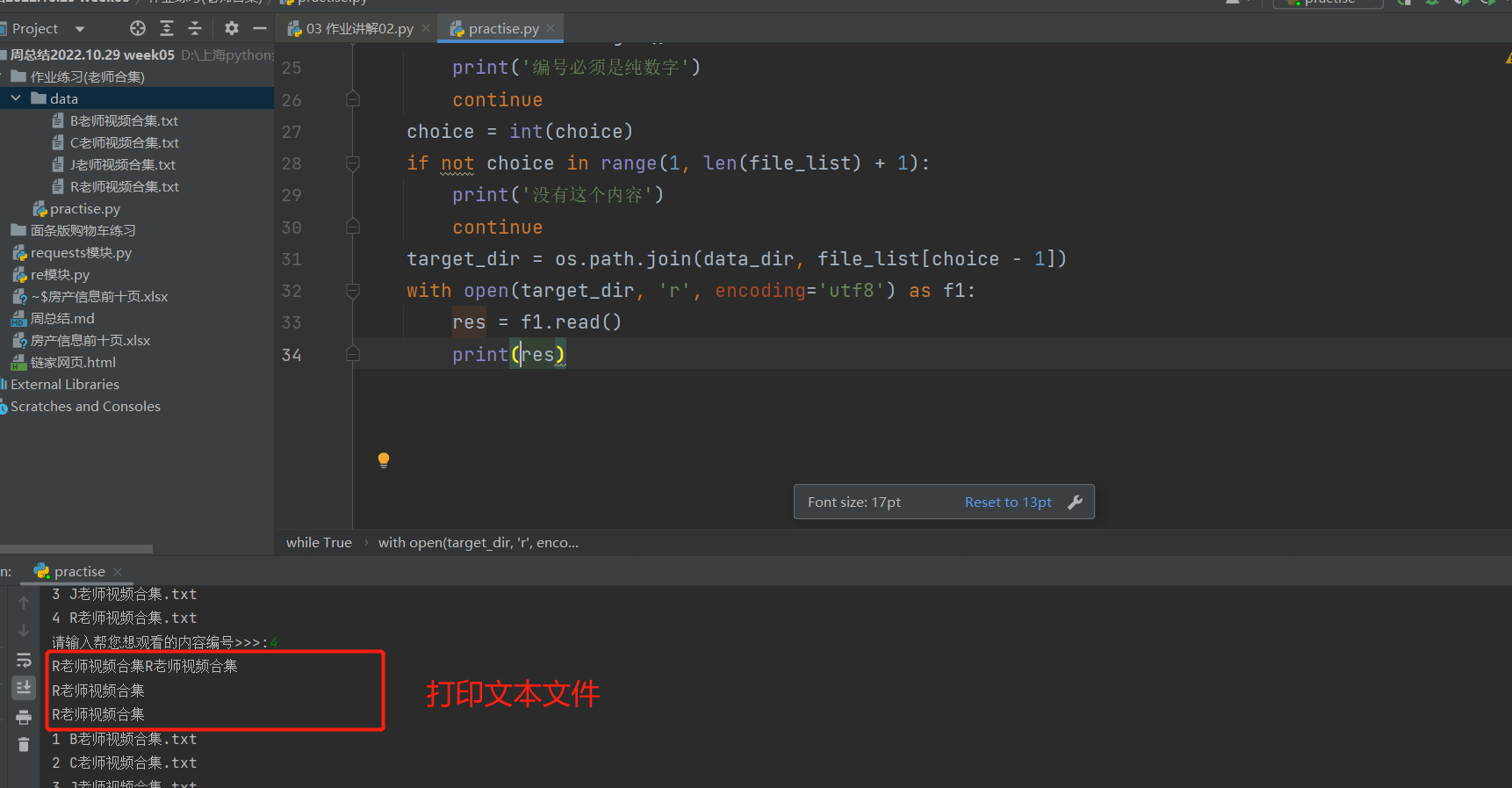
import os
while True:
file_dir = os.path.dirname(__file__) # 获取作业练习(老师合集目录路径)
data_dir = os.path.join(file_dir, 'data')
file_list = os.listdir(data_dir)
# file_list:['B老师视频合集.txt', 'C老师视频合集.txt', 'J老师视频合集.txt', 'R老师视频合集.txt']
for i, j in enumerate(file_list,start=1): # i:1, j:B老师视频合集.txt
print(f'{i} {j}')
choice = input('请输入帮您想观看的内容编号>>>:').strip()
if not choice.isdigit():
print('编号必须是纯数字')
continue
choice = int(choice)
if not choice in range(1, len(file_list) + 1):
print('没有这个内容')
continue
target_dir = os.path.join(data_dir, file_list[choice - 1])
with open(target_dir, 'r', encoding='utf8') as f1:
res = f1.read()
print(res)
"""
2.编写一个统计指定文件类型的脚本工具
输入指定类型的文件后缀
eg:.txt
并给出一个具体路径 之后统计该类型文件在该文件下的个数
ps:简单实现即可 无需优化
"""
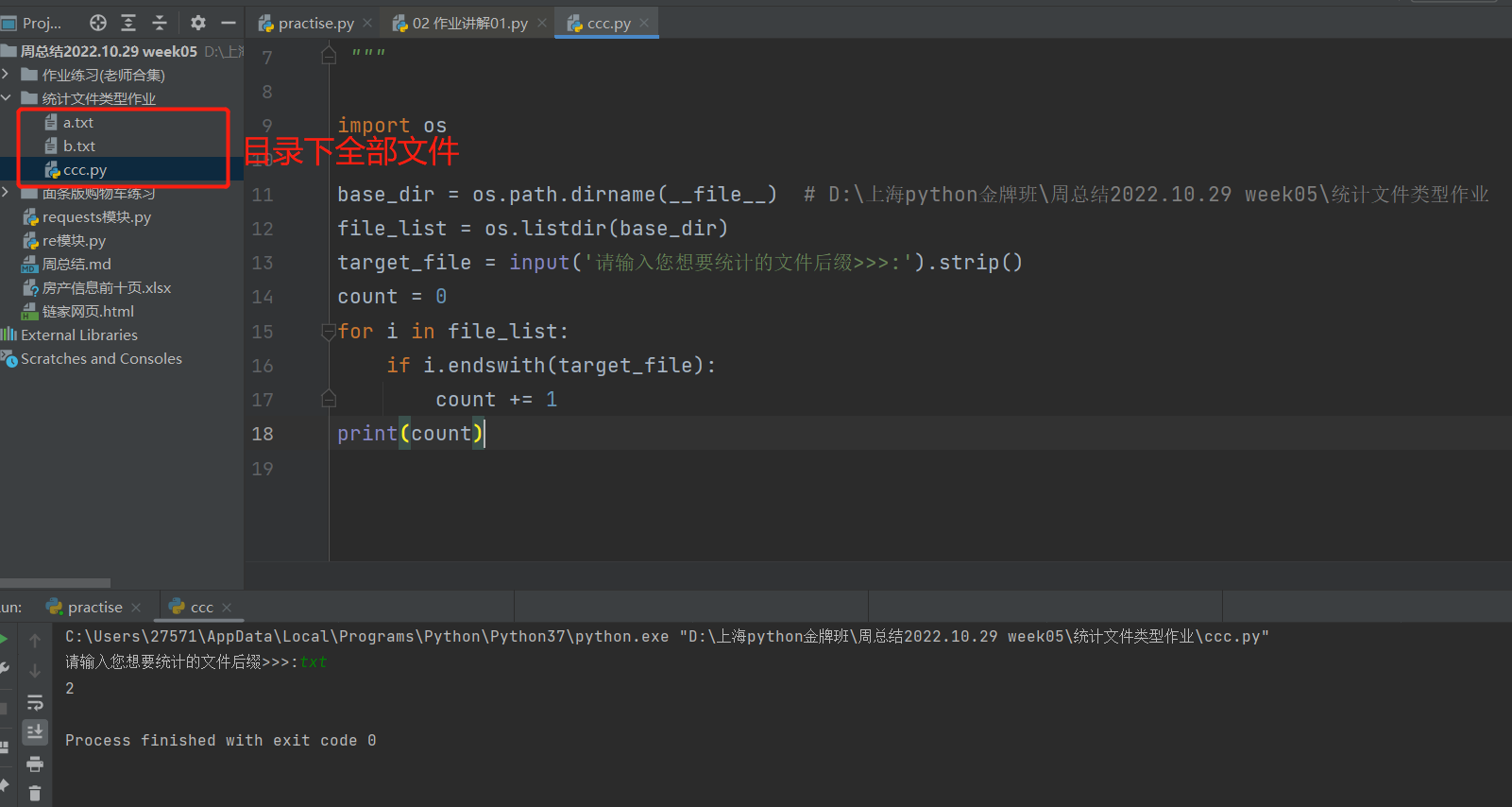
import os
base_dir = os.path.dirname(__file__) # D:\上海python金牌班\周总结2022.10.29 week05\统计文件类型作业
file_list = os.listdir(base_dir)
target_file = input('请输入您想要统计的文件后缀>>>:').strip()
count = 0
for i in file_list:
if i.endswith(target_file):
count += 1
print(count)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号