word2vec
lanyu_01 《word2vec Parameter Learning Explained》论文学习笔记
词向量是用来表示词的向量,也就是词的特征向量。在NLP中,最细粒度的是词语,处理NLP问题,就是将它们转换为数值形式——嵌入到数学空间即词嵌入(word embedding),Word2vec就是词嵌入的一种方式。
语言模型
基本问题:计算一段文本序列在某种语言下出现的概率?
统计语言模型:对于一段文本序列\(S=w_1,w_2,…,w_T\),它的概率可以表示为:
前面是联合概率,后是条件概率的乘积。问题转换为如何去预测给定pervious words下的条件概率\(p(w_t|w_1,w_2,…,w_{t−1})\),常见的统计语言模型有:
马尔可夫假设:下一个词的出现仅依赖于前面的一个词或几个词。
不依赖前面的词:unigram:\(p(S)=p(w_1)p(w_2)p(w_3)…p(w_t)\)
依赖一个:bigram:\(p(S)=p(w_1)p(w_2|w_1)p(w_3|w_2)…p(w_n|w_{n-1})\)
依赖两个:trigram:\(=P(S)=p(w_1)p(w_2|w_1)p(w_3|w_1,w_2)…p(w_n|w_{n-1},w_{n-2})\)
依赖k个:k-gram:\(P(S)=p(w_1)p(w_2|w_1)p(w_3|w_1,w_2)…p(w_n|w_{n-k+1},w_{n-1})\)
CBOW(Continuous Bag-of-Word Model)
one-word context
设定context(预测目标单词的上下文)仅有一个单词,即使用一个单词的context去预测目标单词。
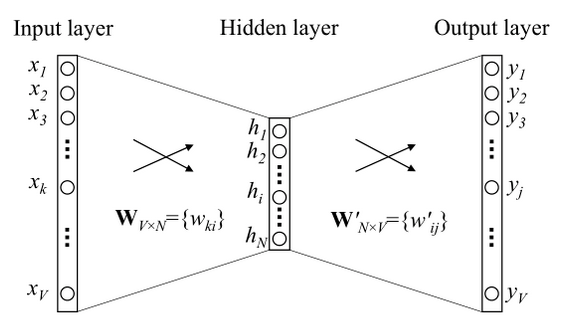
上图即为one-word context下的神经网络模型,相邻层为全连接,输入层使用one-hot encoder的单词向量\(\boldsymbol x=(x_1,...,x_k,...,x_V)^T\),权重矩阵\(W_{V\times N}\),则有:
由于\(\boldsymbol X\)中仅有一个\(x\)为1,设其中\(x_k=1\),则上式等于\(W\)的第\(k\)行,即\(h=V_{W_k}^T\),这就是输入向量。
隐藏层的激活函数是线性的,也就是对\(h=V_{W_k}^T\)不做任何处理。
隐藏层到输出层的权重矩阵为\(W_{N\times V}^{'}\),则有:
前面我们说了,对于输入层到隐藏层,\(h\)的结果其实是对于单词\(\boldsymbol x\)one-hot encoder中1的位置\(k\)索引的\(W\)的第\(k\)行的转置,那么对于词表中的每一个单词都可以计算出一个得分:
注意这里的\(v_{W_j^{'}}\)实际上是\(W^{'}\)的第\(j\)列,原因是最后得到的o是一个one-hot encoder形式的向量。
此时我们得到了context对应于其它所有单词向量的一个得分向量。再经过梯度下降等方法进行训练使概率其成为最大。
- 以上我们可以总结得到:输入向量是\(W\)的某一行,输出向量是\(w^{'}\)的某一列。
Multi-word context
对于Multi-word context:

将多个context相加平均再进行one-word context的步骤即可。
Optimizing Computational Efficiency(优化计算效率)
对于大型的词汇表,上述的方式计算成本是昂贵的,直观的方式便是去限制必须要更新的训练样例和输出向量的数目。
Negative Sampling(负采样)
在每次迭代的过程中,有大量的输出向量需要更新,负采样只需要更新其中一部分输出向量的解决方案。
显然最终需要输出的单词或者上下文(正样本)在采样的过程中应该被保留并更新,同时采集一些单词作为负样本(负采样),采样过程中,我们可任意选择一种概率分布,将这种概率分布称为“噪声分布”(the noise distribution),用\(P_n(w)\)来表示,可以根据经验选择较好的分布。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号