为什么随机森林不完全按照那四个(x_train、y_train、x_test、y_test)做出来的结果也是正确的???
train数据集包括x_train和y_train
1、代码不完全按照那四个来处理
没有train.names[0:-1]去除最后一列
model1 = H2ORandomForestEstimator() # 初始化(建立)模型
model1.train(x = train.names,y = 'Catrgory',training_frame = train) # 训练模型
没有test[test.names[0:-1]]删除最后一列
predict=H2ORandomForestEstimator.predict(model1 ,test) # 对测试集进行预测
tmp = predict[predict['predict'] == test['Catrgory']].nrow
accuracy = tmp/test.nrow
accuracy
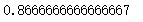
2、代码完全正确,完全按照那四个来处理
train.names[0:-1]去除最后一列
model1 = H2ORandomForestEstimator() # 初始化(建立)模型
model1.train(x = train.names[0:-1],y = 'Catrgory',training_frame = train) # 训练模型 train.names[0:-1]去除最后一列
test[test.names[0:-1]]删除最后一列
predict=H2ORandomForestEstimator.predict(model1 ,test[test.names[0:-1]]) # 对测试集进行预测 test[test.names[0:-1]]删除最后一列
tmp = predict[predict['predict'] == test['Catrgory']].nrow
accuracy = tmp/test.nrow
accuracy
大家好,我是[爱做梦的子浩](https://blog.csdn.net/weixin_43124279),我是东北大学大数据实验班大三的小菜鸡,非常向往优秀,羡慕优秀的人,已拿两个暑假offer,欢迎大家找我进行交流😂😂😂
这是我的博客地址:[子浩的博客https://blog.csdn.net/weixin_43124279]
——
版权声明:本文为CSDN博主「爱做梦的子浩」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号