MapReduce的二次排序
附录之前总结的一个例子:
http://www.cnblogs.com/DreamDrive/p/7398455.html
另外两个有价值的博文:
http://www.cnblogs.com/xuxm2007/archive/2011/09/03/2165805.html
http://blog.csdn.net/heyutao007/article/details/5890103
一.MR的二次排序的需求说明
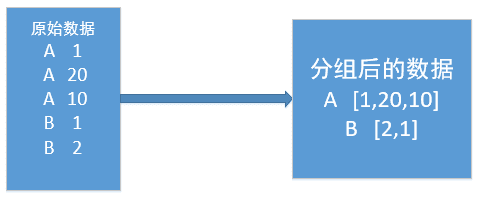
在mapreduce操作时,shuffle阶段会多次根据key值排序。但是在shuffle分组后,相同key值的values序列的顺序是不确定的(如下图)。如果想要此时value值也是排序好的,这种需求就是二次排序。
二.测试的文件数据
| a 1 a 5 a 7 a 9 b 3 b 8 b 10 |
三.未经过二次排序的输出结果
|
四.第一种实现思路
直接在reduce端对分组后的values进行排序。
reduce关键代码
1 @Override 2 public void reduce(Text key, Iterable<IntWritable> values, Context context) 3 throws IOException, InterruptedException { 4 5 List<Integer> valuesList = new ArrayList<Integer>(); 6 7 // 取出value 8 for(IntWritable value : values) { 9 valuesList.add(value.get()); 10 } 11 // 进行排序 12 Collections.sort(valuesList); 13 14 for(Integer value : valuesList) { 15 context.write(key, new IntWritable(value)); 16 } 17 18 }
输出结果:
a 1 a 5 a 7 a 9 b 3 b 8 b 10
很容易发现,这样把排序工作都放到reduce端完成,当values序列长度非常大的时候,会对CPU和内存造成极大的负载。
注意的地方(容易被“坑”)
在reduce端对values进行迭代的时候,不要直接存储value值或者key值,因为reduce方法会反复执行多次,但key和value相关的对象只有两个,reduce会反复重用这两个对象。需要用相应的数据类型.get()取出后再存储。
五.第二种实现思路
将map端输出的<key,value>中的key和value组合成一个新的key(称为newKey),value值不变。这里就变成<(key,value),value>,在针对newKey排序的时候,如果key相同,就再对value进行排序。
需要自定义的地方
1.自定义数据类型实现组合key
实现方式:继承WritableComparable
2.自定义partioner,形成newKey后保持分区规则任然按照key进行。保证不打乱原来的分区。
实现方式:继承partitioner
3.自定义分组,保持分组规则任然按照key进行。不打乱原来的分组
实现方式:继承RawComparator
自定义数据类型关键代码
1 import java.io.DataInput; 2 import java.io.DataOutput; 3 import java.io.IOException; 4 import org.apache.hadoop.io.WritableComparable; 5 6 public class PairWritable implements WritableComparable<PairWritable> { 7 // 组合key 8 private String first; 9 private int second; 10 11 public PairWritable() { 12 } 13 14 public PairWritable(String first, int second) { 15 this.set(first, second); 16 } 17 18 /** 19 * 方便设置字段 20 */ 21 public void set(String first, int second) { 22 this.first = first; 23 this.second = second; 24 } 25 26 /** 27 * 反序列化 28 */ 29 @Override 30 public void readFields(DataInput arg0) throws IOException { 31 this.first = arg0.readUTF(); 32 this.second = arg0.readInt(); 33 } 34 /** 35 * 序列化 36 */ 37 @Override 38 public void write(DataOutput arg0) throws IOException { 39 arg0.writeUTF(first); 40 arg0.writeInt(second); 41 } 42 43 /* 44 * 重写比较器 45 */ 46 public int compareTo(PairWritable o) { 47 int comp = this.first.compareTo(o.first); 48 49 if(comp != 0) { 50 return comp; 51 } else { // 若第一个字段相等,则比较第二个字段 52 return Integer.valueOf(this.second).compareTo( 53 Integer.valueOf(o.getSecond())); 54 } 55 } 56 57 public int getSecond() { 58 return second; 59 } 60 public void setSecond(int second) { 61 this.second = second; 62 } 63 public String getFirst() { 64 return first; 65 } 66 public void setFirst(String first) { 67 this.first = first; 68 }
自定义分区规则
1 import org.apache.hadoop.io.IntWritable; 2 import org.apache.hadoop.mapreduce.Partitioner; 3 4 public class SecondPartitioner extends Partitioner<PairWritable, IntWritable> { 5 6 @Override 7 public int getPartition(PairWritable key, IntWritable value, int numPartitions) { 8 /* 9 * 默认的实现 (key.hashCode() & Integer.MAX_VALUE) % numPartitions 10 * 让key中first字段作为分区依据 11 */ 12 return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions; 13 } 14 }
自定义分组比较器
1 import org.apache.hadoop.io.RawComparator; 2 import org.apache.hadoop.io.WritableComparator; 3 4 public class SecondGroupComparator implements RawComparator<PairWritable> { 5 6 /* 7 * 对象比较 8 */ 9 public int compare(PairWritable o1, PairWritable o2) { 10 return o1.getFirst().compareTo(o2.getFirst()); 11 } 12 13 /* 14 * 字节比较 15 * arg0,arg3为要比较的两个字节数组 16 * arg1,arg2表示第一个字节数组要进行比较的收尾位置,arg4,arg5表示第二个 17 * 从第一个字节比到组合key中second的前一个字节,因为second为int型,所以长度为4 18 */ 19 public int compare(byte[] arg0, int arg1, int arg2, byte[] arg3, int arg4, int arg5) { 20 return WritableComparator.compareBytes(arg0, 0, arg2-4, arg3, 0, arg5-4); 21 } 22 }
map关键代码
1 private PairWritable mapOutKey = new PairWritable(); 2 private IntWritable mapOutValue = new IntWritable(); 3 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 4 String lineValue = value.toString(); 5 String[] strs = lineValue.split("\t"); 6 7 //设置组合key和value ==> <(key,value),value> 8 mapOutKey.set(strs[0], Integer.valueOf(strs[1])); 9 mapOutValue.set(Integer.valueOf(strs[1])); 10 11 context.write(mapOutKey, mapOutValue); 12 }
reduce关键代码
1 private Text outPutKey = new Text(); 2 public void reduce(PairWritable key, Iterable<IntWritable> values, Context context) 3 throws IOException, InterruptedException { 4 //迭代输出 5 for(IntWritable value : values) { 6 outPutKey.set(key.getFirst()); 7 context.write(outPutKey, value); 8 } 9 10 }
输出结果:
a 1 a 5 a 7 a 9 b 3 b 8 b 10
原理:
在map阶段:
使用job.setInputFormatClass定义的InputFormat将输入的数据集分割成小数据块splites,同时InputFormat提供一个RecordReder的实现。
本例子中使用的是TextInputFormat,他提供的RecordReder会将文本的一行的行号作为key,这一行的文本作为value。这就是自定义Map的输入是<LongWritable, Text>的原因。
然后调用自定义Map的map方法,将一个个<LongWritable, Text>对输入给Map的map方法。注意输出应该符合自定义Map中定义的输出<IntPair, IntWritable>。最终是生成一个List<IntPair, IntWritable>。
在map阶段的最后,会先调用job.setPartitionerClass对这个List进行分区,每个分区映射到一个reducer。每个分区内又调用job.setSortComparatorClass设置的key比较函数类排序。
可以看到,这本身就是一个二次排序。如果没有通过job.setSortComparatorClass设置key比较函数类,则使用key的实现的compareTo方法。
在reduce阶段:
reducer接收到所有映射到这个reducer的map输出后,也是会调用job.setSortComparatorClass设置的key比较函数类对所有数据对排序。
然后开始构造一个key对应的value迭代器。这时就要用到分组,使用jobjob.setGroupingComparatorClass设置的分组函数类。
只要这个比较器比较的两个key相同,他们就属于同一个组,它们的value放在一个value迭代器,而这个迭代器的key使用属于同一个组的所有key的第一个key。
最后就是进入Reducer的reduce方法,reduce方法的输入是所有的(key和它的value迭代器)。同样注意输入与输出的类型必须与自定义的Reducer中声明的一致。
|
作者:SummerChill 出处:http://www.cnblogs.com/DreamDrive/ 本博客为自己总结亦或在网上发现的技术博文的转载。 如果文中有什么错误,欢迎指出。以免更多的人被误导。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号