VoxCPM:国产开源 TTS 的新标杆,真实感语音生成进入新时代
 国产开源TTS新标杆VoxCPM。仅 3 秒音频即可零样本克隆,5 亿参数可在消费级显卡高效运行。模型上下文感知,能生成富有情感的语音。适用于客服、配音等场景。提供部署及ComfyUI指南。
国产开源TTS新标杆VoxCPM。仅 3 秒音频即可零样本克隆,5 亿参数可在消费级显卡高效运行。模型上下文感知,能生成富有情感的语音。适用于客服、配音等场景。提供部署及ComfyUI指南。
VoxCPM:国产开源 TTS 的新标杆,真实感语音生成进入新时代
阅读原文
建议阅读原文,始终查看最新文档版本,获得最佳阅读体验:《VoxCPM:国产开源 TTS 的新标杆,真实感语音生成进入新时代》
https://alidocs.dingtalk.com/i/nodes/dxXB52LJqnrX6jrGi97ReQgd8qjMp697
介绍VoxCPM
零样本克隆,最少只需3秒音频即可完成声音克隆。5亿参数量,在消费级显卡上也能流畅运行。
🎙️ VoxCPM能用来做什么?这些场景太实用了!
想象一下:只需输入一段文字,就能生成富有情感、语调自然的语音;甚至只要提供几秒钟的参考音频,就能“克隆”出一个真实人声——这正是 VoxCPM 带来的革命性体验。
-
智能客服与虚拟助手:企业可快速为AI客服定制专属声音,让交互更亲切、专业,提升用户体验。
-
有声内容创作:自媒体人、播客创作者无需录音棚,输入脚本(SRT字幕文件)即可生成高质量配音,支持中英双语,节奏情感自动适配。
-
个性化语音助手:用户上传自己的一段语音,就能让手机、车载系统或智能家居“用你的声音说话”,真正实现私人定制。
-
影视与游戏配音:在原型开发或小成本制作中,VoxCPM可快速生成角色对白,大幅降低配音成本和周期。
-
无障碍应用:为视障人士提供更自然流畅的文本朗读服务,让信息获取更人性化。
得益于其 无分词器(Tokenizer-Free)架构 和 上下文感知能力,VoxCPM不仅能精准复刻音色,还能根据文本内容自动调整语气、节奏和情绪——比如读诗温柔婉转,播报新闻则清晰有力。再加上 仅需0.5B参数 就能在消费级显卡上实现实时合成(RTF低至0.17),它正成为开源TTS领域一颗耀眼的新星。
🚀 Key Features 🚀 核心功能
Context-Aware, Expressive Speech Generation - VoxCPM comprehends text to infer and generate appropriate prosody, delivering speech with remarkable expressiveness and natural flow. It spontaneously adapts speaking style based on content, producing highly fitting vocal expression trained on a massive 1.8 million-hour bilingual corpus.
上下文感知、富有表现力的语音生成 - VoxCPM 通过理解文本来推断并生成合适的韵律,提供极具表现力和自然流畅的语音。它能够根据内容自发地调整说话风格,生成高度契合的语音表达,其训练数据基于庞大的 180 万小时双语语料库。
True-to-Life Voice Cloning - With only a short reference audio clip, VoxCPM performs accurate zero-shot voice cloning, capturing not only the speaker’s timbre but also fine-grained characteristics such as accent, emotional tone, rhythm, and pacing to create a faithful and natural replica.
真实语音克隆 - 仅需一段简短的参考音频,VoxCPM 即可实现准确的零样本语音克隆,不仅捕捉说话人的音色,还能提取诸如口音、情感语调、节奏和语速等细节特征,从而创建出忠实且自然的语音复制品。
High-Efficiency Synthesis - VoxCPM supports streaming synthesis with a Real-Time Factor (RTF) as low as 0.17 on a consumer-grade NVIDIA RTX 4090 GPU, making it possible for real-time applications.
高效合成 - VoxCPM 在消费级 NVIDIA RTX 4090 GPU 上支持流式合成,实时因子(RTF)低至 0.17,使得实时应用成为可能。
demo
可以直接进入这个网站线上体验VoxCPM Demo - a Hugging Face Space by openbmb
官网
github网址:发布 · OpenBMB/VoxCPM --- Releases · OpenBMB/VoxCPM
本地部署
mkdir voxcpm
cd voxcpm/
uv venv
uv pip install voxcpm
#下载VoxCPM模型
uv run python
from huggingface_hub import snapshot_download
snapshot_download("openbmb/VoxCPM-0.5B")
#下载 ZipEnhancer 和 SenseVoice-Small。使用 ZipEnhancer 来增强语音提示
from modelscope import snapshot_download
snapshot_download('iic/speech_zipenhancer_ans_multiloss_16k_base')
snapshot_download('iic/SenseVoiceSmall')

命令行方式使用voxcpm
官方的使用示例
# 1) Direct synthesis (single text)
voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." --output out.wav
# 2) Voice cloning (reference audio + transcript)
voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." \
--prompt-audio path/to/voice.wav \
--prompt-text "reference transcript" \
--output out.wav \
--denoise
# (Optinal) Voice cloning (reference audio + transcript file)
voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." \
--prompt-audio path/to/voice.wav \
--prompt-file "/path/to/text-file" \
--output out.wav \
--denoise
# 3) Batch processing (one text per line)
voxcpm --input examples/input.txt --output-dir outs
# (optional) Batch + cloning
voxcpm --input examples/input.txt --output-dir outs \
--prompt-audio path/to/voice.wav \
--prompt-text "reference transcript" \
--denoise
# 4) Inference parameters (quality/speed)
voxcpm --text "..." --output out.wav \
--cfg-value 2.0 --inference-timesteps 10 --normalize
# 5) Model loading
# Prefer local path
voxcpm --text "..." --output out.wav --model-path /path/to/VoxCPM_model_dir
# Or from Hugging Face (auto download/cache)
voxcpm --text "..." --output out.wav \
--hf-model-id openbmb/VoxCPM-0.5B --cache-dir ~/.cache/huggingface --local-files-only
# 6) Denoiser control
voxcpm --text "..." --output out.wav \
--no-denoiser --zipenhancer-path iic/speech_zipenhancer_ans_multiloss_16k_base
# 7) Help
voxcpm --help
python -m voxcpm.cli --help
真实示例
克隆声音,然后根据克隆的声音进行TTS(文本转语音)
#注意--prompt-text的值是提供的参考音频的转录文字,当然也可以用--prompt-file参数(如果文本内容很多的话)
sudo apt install -y ffmpeg #如果提供的参考音频是wav格式的,则需要安装ffmpeg和torchcodec
uv pip install torchcodec
uv run voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." \
--prompt-audio ./AI招聘官_17s.wav \
--prompt-text "今天我给大家介绍一款我利用Langchain和langgraph开发的AI招聘官。这是一个AI agent,然后Langchain和langgraph是主流的开发AI agent的框架。" \
--output ./AI招聘官_voxcpm.wav \
--denoise
我提供的参考音频是:
生成的最终合成音频是:
可以说,克隆的效果是非常好的。

VoxCPM也有Python SDK,便于与其他应用集成
import soundfile as sf
import numpy as np
from voxcpm import VoxCPM
model = VoxCPM.from_pretrained("openbmb/VoxCPM-0.5B")
# Non-streaming
wav = model.generate(
text="VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech.",
prompt_wav_path=None, # optional: path to a prompt speech for voice cloning
prompt_text=None, # optional: reference text
cfg_value=2.0, # LM guidance on LocDiT, higher for better adherence to the prompt, but maybe worse
inference_timesteps=10, # LocDiT inference timesteps, higher for better result, lower for fast speed
normalize=True, # enable external TN tool
denoise=True, # enable external Denoise tool
retry_badcase=True, # enable retrying mode for some bad cases (unstoppable)
retry_badcase_max_times=3, # maximum retrying times
retry_badcase_ratio_threshold=6.0, # maximum length restriction for bad case detection (simple but effective), it could be adjusted for slow pace speech
)
sf.write("output.wav", wav, 16000)
print("saved: output.wav")
# Streaming
chunks = []
for chunk in model.generate_streaming(
text = "Streaming text to speech is easy with VoxCPM!",
# supports same args as above
):
chunks.append(chunk)
wav = np.concatenate(chunks)
sf.write("output_streaming.wav", wav, 16000)
print("saved: output_streaming.wav")
与VoxCPM有关的ComfyUI自定义节点
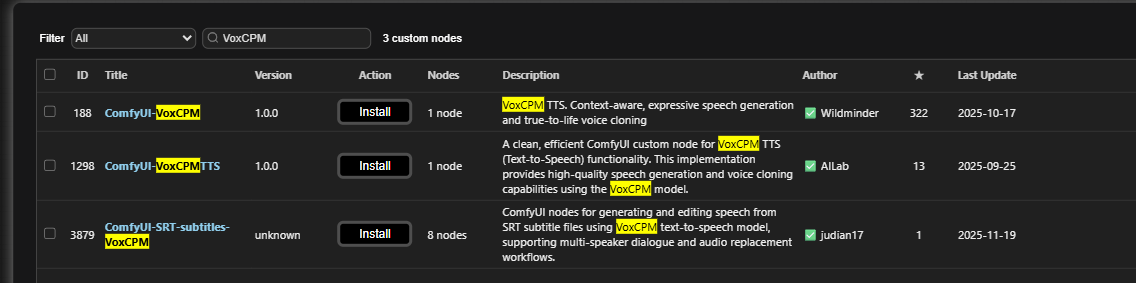
目前ComfyUI manager中有三个与VoxCPM有关的节点,借助这些节点,可以很方便的直接在ComfyUI中克隆语音,生成语音。设置还能直接将SRT字幕文件转换为音频,大大方便了音频与字幕对齐。
注:我写作本文时,TTS Audio Suite节点还不支持VoxCPM,我已经提交了issue,仓库维护者回复说以后会支持。
无论是VoxCPM还是IndexTTS2都不支持直接处理SRT字幕文件的,要借助ComfyUI自定义节点(比如《TTS Audio Suite》),或者自己开发一个软件来处理SRT字幕文件的。
故障诊断
torch.OutOfMemoryError: CUDA out of memory.
说明显存不足,其实VoxCPM对于GPU要求很低的,低显存也可以运行的,出现这个报错,通常是因为提供的参考音频太长了,其实6秒长度的音频足以,我的示例中,音频长度也只有17秒。
参考资料
https://mp.weixin.qq.com/s/D4wKeJZxQHllOKljXoZMvg
关于作者和DreamAI
关注微信公众号“AI发烧友”,获取更多IT开发运维实用工具与技巧,还有很多AI技术文档!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号