
第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业的要求在哪里 | 作业要求 |
| 这个作业的目标 | 了解PSP表格 + 继续熟悉Markdown + 锻炼个人编程能力 + 了解使用单元测试 + 了解如何测试模块性能 |
代码链接
计算模块接口的设计与实现过程
1.模块函数
该模块有5个函数,其调用关系如下
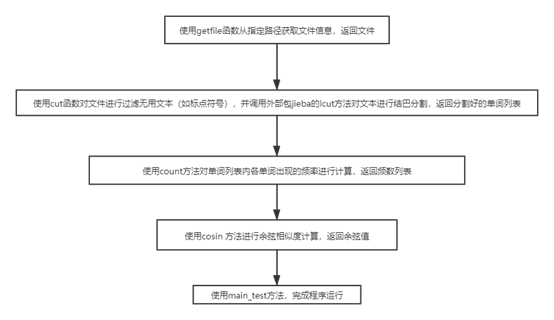
2.关键算法
这里采用了计算余弦相似度来比较两个文本之间的相似度。参考文档
1.jieba.lcut
采用结巴分割的算法,将文本进行分割成一个个词语,这里参考了CSDN里的方法:结巴分割 。这里采用了精准分割。
代码:
text = "我来到北京清华大学"
seg_list = jieba.lcut(text, cut_all=False)
print(seg_list)
运行结果:
我/ 来到/ 北京/ 清华大学
2.re.compile
这里采用re包里的compile方法,使用正则表达式,去除标点符号,仅对中英文文本和数字进行分割,其中中文按词语分割,英文按单词分割,数字按空格分割。
代码:
def cut(message):
# 使用正则表达式去除标点符号,但是为了分割单词和数字,暂时保留空格
comp = re.compile('[^A-Z^a-z0-9\u4e00-\u9fa5]')
words = jieba.lcut(comp.sub('', message), cut_all=False)
# 去掉空格
word = [w for w in words if len(w.strip()) > 0]
return word
3.计算词出现的频数
(1)举个例子:
句子A:这只皮靴号码大了。那只号码合适
句子B:这只皮靴号码不小,那只更合适
(2)进行分割后的所有的词的列表:
这只/皮靴/号码/大了/那只/合适/不/小/更
(3)写出两个句子的词频:
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
(4)写出词频向量:
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
4.计算两个向量的余弦值
这里还是使用上面的例子
使用公式:
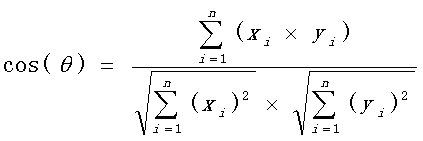
计算过程:
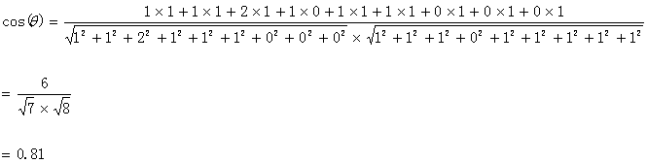
由此可见,两个句子的相似度为0.81,因此可以看出这两个句子基本相似
性能分析
1.耗费时间
利用pycharm的插件进行函数耗费时间分析
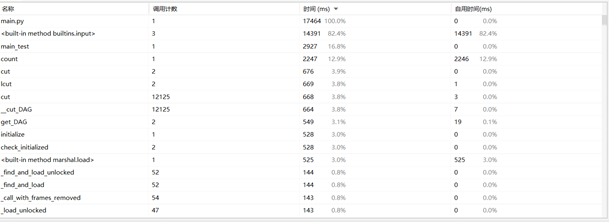
可以看出
耗费时间最多的函数是input函数,这说明大部分的时间花费在用户输入的文件路径。
当将文件路径在代码内提前赋值,函数耗费时间如下:
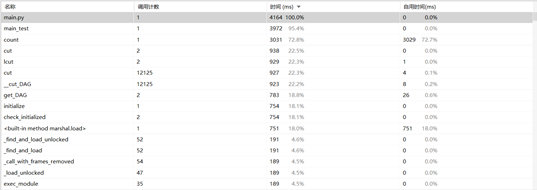
可见除输出函数main_test外,耗费时间最多的函数为计算频数的函数count
由此对count函数进行改进:
改进前代码:
# 对各词语出现次数进行统计
def count(text1, text2):
# 合并两个句子的单词
key_word = list(set(text1 + text2))
# 统计句子一的词频,依次遍历key_word和text1,如果出现一样的词语,则+1
vec1 = []
for i in range(len(key_word)):
vec1.append(0)
for j in range(len(text1)):
if key_word[i] == text1[j]:
vec1[i] += 1
# 统计句子二的词频,依次遍历key_word和text2,如果出现一样的词语,则+1
vec2 = []
for k in range(len(key_word)):
vec2.append(0)
for m in range(len(text2)):
if key_word[k] == text2[m]:
vec2[k] += 1
return vec1, vec2
改进后代码:
# 对各词语出现次数进行统计
def count(text1, text2):
# 合并两个句子的单词
key_word = list(set(text1 + text2))
# 统计句子一的词频,依次遍历key_word和text1,如果出现一样的词语,则+1
vec1 = []
for i in range(len(key_word)):
vec1.append(0)
for j in range(len(text1)):
if key_word[i] == text1[j]:
vec1[i] += 1
continue
# 统计句子二的词频,依次遍历key_word和text2,如果出现一样的词语,则+1
vec2 = []
for k in range(len(key_word)):
vec2.append(0)
for m in range(len(text2)):
if key_word[k] == text2[m]:
vec2[k] += 1
continue
return vec1, vec2
改进方法:在key_word中的词与test1(或者test2)中的一致时,词频+1后,便可跳出test1(或者test2)循环,这样可以缩短一点时间。
改进后耗费的时间:
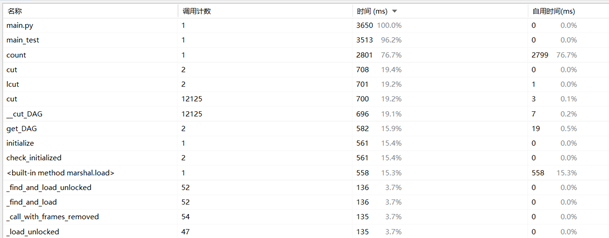
由此可见,改进后时间缩短了约0.5s
2.代码覆盖率
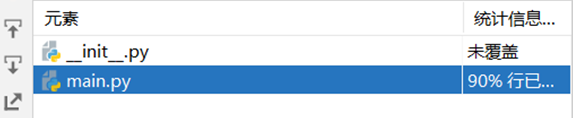
main.py的代码覆盖率为90%,剩下的10%未覆盖的代码为异常检测的代码,这部分在单元测试的时候会覆盖。
单元测试
1.单元测试代码
import unittest
from main.main import main_test
class MyTest(unittest.TestCase):
def error_path(self):
main_test('../textfile/orig.txt', '../orig.txt', '../result.txt')
raise FileNotFoundError("文件不存在。")
# 文件输入错误的单元测试
def test1(self):
with self.assertRaises(FileNotFoundError):
self.error_path()
# 测试空白文档
def void_file(self):
main_test('../textfile/orig.txt', '../textfile/void.txt', '../result.txt')
raise ZeroDivisionError("文档空白")
def test2(self):
with self.assertRaises(ZeroDivisionError):
self.void_file()
# 测试orig.txt与orig_0.8_add.txt
def test3(self):
main_test('../textfile/orig.txt', '../textfile/orig_0.8_add.txt', '../result.txt')
# 测试orig.txt与orig_0.8_del.txt
def test4(self):
main_test('../textfile/orig.txt', '../textfile/orig_0.8_del.txt', '../result.txt')
# 测试orig.txt与orig_0.8_dis_1.txt
def test5(self):
main_test('../textfile/orig.txt', '../textfile/orig_0.8_dis_1.txt', '../result.txt')
# 测试orig.txt与orig_0.8_dis_10.txt
def test6(self):
main_test('../textfile/orig.txt', '../textfile/orig_0.8_dis_10.txt', '../result.txt')
# 测试orig.txt与orig_0.8_dis_15.txt
def test7(self):
main_test('../textfile/orig.txt', '../textfile/orig_0.8_dis_15.txt', '../result.txt')
# 测试orig_0.8_add.txt与orig_0.8_del.txt
def test8(self):
main_test('../textfile/orig_0.8_add.txt', '../textfile/orig_0.8_del.txt', '../result.txt')
# 测试orig_0.8_dis_1.txt与orig_0.8_dis_10.txt
def test9(self):
main_test('../textfile/orig_0.8_dis_1.txt', '../textfile/orig_0.8_dis_10.txt', '../result.txt')
# 测试orig.txt与orig.txt
def test10(self):
main_test('../textfile/orig.txt', '../textfile/orig.txt', '../result.txt')
if __name__ == '__main__':
unittest.main()
2.单元测试代码覆盖率
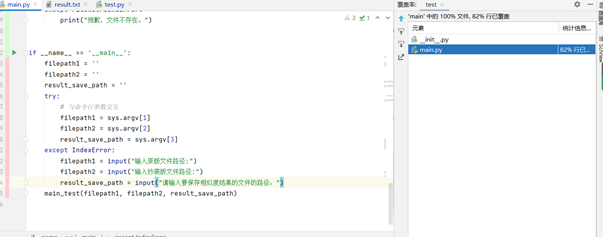
main.py中,82%行代码已覆盖,未覆盖代码为从命令行交互获取参数或者用户在编译器内输入参数,其余函数代码均已覆盖
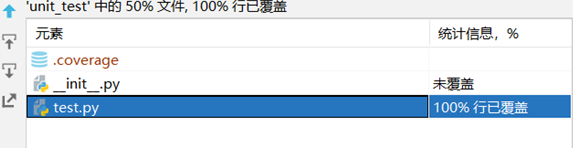
单元测试代码test.py代码覆盖率为100%
异常处理
1.FileNotFoundError
文件路径错误:
在读取文件时,可能存在路径不存在而出现FileNotFoundError异常,采用try...except FileNotFoundError捕捉异常
代码:
try:
file1 = getfile(path1)
file2 = getfile(path2)
cut1 = cut(file1)
cut2 = cut(file2)
count1, count2 = count(cut1, cut2)
result = cosin(count1, count2)
print(str(path1) + "与" + str(path2) + "的相似度:%.2f%%\n" % (result * 100))
f = open(save_path, 'a', encoding="utf-8")
f.write(str(path1) + "与" + str(path2) + "的相似度:%.2f%%\n" % (result * 100))
f.close()
# 捕捉文件路径错误
except FileNotFoundError:
print("抱歉,文件不存在。")
当出现文件路径错误的问题时,会输出:抱歉,文件不存在。
单元测试代码:
def error_path(self):
main_test('../textfile/orig.txt', '../orig.txt', '../result.txt')
raise FileNotFoundError("文件不存在。")
# 文件输入错误的单元测试
def test1(self):
with self.assertRaises(FileNotFoundError):
self.error_path()
2.ZeroDivisionError
由于文件为空白文件,因此其词频必定为0,所以向量为0,因此会出现除数为0的错误
代码:
try:
cos = (add / ((math.sqrt(squ1)) * (math.sqrt(squ2))))
return cos
except ZeroDivisionError:
print('文本空白。')
return 0
单元测试代码:
# 测试空白文档
def void_file(self):
main_test('../textfile/orig.txt', '../textfile/void.txt', '../result.txt')
raise ZeroDivisionError("文档空白")
def test2(self):
with self.assertRaises(ZeroDivisionError):
self.void_file()
附录
1.接受命令行参数
这里采用sys.argv方法,来让程序接受命令行参数。
代码:
try:
# 与命令行参数交互
filepath1 = sys.argv[1]
filepath2 = sys.argv[2]
result_save_path = sys.argv[3]
except IndexError:
filepath1 = input("输入原版文件路径:")
filepath2 = input("输入抄袭版文件路径:")
result_save_path = input("请输入要保存相似度结果的文件的路径:")
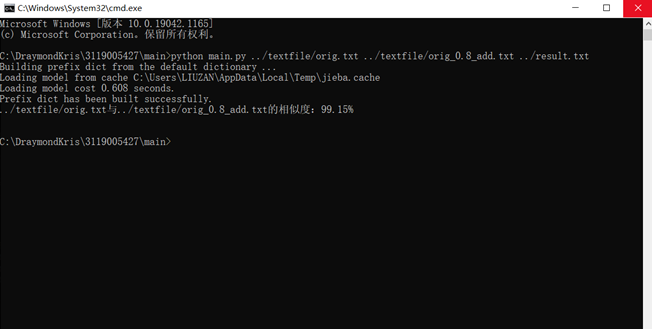
P.s.由于在编译器内直接运行时,没有接受到命令行参数,程序会出现IndexError的异常,这里采用try...except IndexError解决既可以在编译器内运行,也可以接受命令行参数。
命令行参数运行结果
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 90 |
| ·Estimate | · 估计这个任务需要多少时间 | 60 | 90 |
| Development | 开发 | 675 | 1080 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 240 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 30 |
| · Design | · 具体设计 | 60 | 90 |
| · Coding | · 具体编码 | 300 | 480 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 240 | 290 |
| · Test Repor | · 测试报告 | 180 | 200 |
| · Size Measurement | · 计算工作量 | 50 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 30 |
| · 合计 | 975 | 1460 |
3.项目源码
# encoding=utf-8
import math
import re
import jieba
import sys
# 从指定路径获取文本信息
def getfile(path):
file = open(path, 'r', encoding='utf-8')
message = file.read()
file.close()
return message
# 对字符串进行分割,分割规则:中文按词语分割,英文按单词分割,数字按空格分割,其中去掉标点符号
def cut(message):
# 使用正则表达式去除标点符号,但是为了分割单词和数字,暂时保留空格
comp = re.compile('[^A-Z^a-z0-9\u4e00-\u9fa5]')
words = jieba.lcut(comp.sub('', message), cut_all=False)
# 去掉空格
word = [w for w in words if len(w.strip()) > 0]
return word
# 对各词语出现次数进行统计
def count(text1, text2):
#合并两个句子的单词
key_word = list(set(text1 + text2))
#统计句子一的词频,依次遍历key_word和text1,如果出现一样的词语,则+1
vec1 = []
for i in range(len(key_word)):
vec1.append(0)
for j in range(len(text1)):
if key_word[i] == text1[j]:
vec1[i] += 1
continue
#统计句子二的词频,依次遍历key_word和text2,如果出现一样的词语,则+1
vec2 = []
for k in range(len(key_word)):
vec2.append(0)
for m in range(len(text2)):
if key_word[k] == text2[m]:
vec2[k] += 1
continue
return vec1, vec2
# 计算文本的余弦相似度
def cosin(vec1, vec2):
add = 0
squ1 = 0
squ2 = 0
for i in range(len(vec1)):
add += vec1[i] * vec2[i]
squ1 += vec1[i] ** 2
squ2 += vec2[i] ** 2
try:
cos = (add / ((math.sqrt(squ1)) * (math.sqrt(squ2))))
return cos
except ZeroDivisionError:
print('文本空白。')
return 0
def main_test(path1, path2, save_path):
try:
file1 = getfile(path1)
file2 = getfile(path2)
cut1 = cut(file1)
cut2 = cut(file2)
count1, count2 = count(cut1, cut2)
result = cosin(count1, count2)
print(str(path1) + "与" + str(path2) + "的相似度:%.2f%%\n" % (result * 100))
f = open(save_path, 'a', encoding="utf-8")
f.write(str(path1) + "与" + str(path2) + "的相似度:%.2f%%\n" % (result * 100))
f.close()
# 捕捉文件路径错误
except FileNotFoundError:
print("抱歉,文件不存在。")
if __name__ == '__main__':
filepath1 = ''
filepath2 = ''
result_save_path = ''
try:
# 与命令行参数交互
filepath1 = sys.argv[1]
filepath2 = sys.argv[2]
result_save_path = sys.argv[3]
except IndexError:
filepath1 = input("输入原版文件路径:")
filepath2 = input("输入抄袭版文件路径:")
result_save_path = input("请输入要保存相似度结果的文件的路径:")
main_test(filepath1, filepath2, result_save_path)
4.个人总结
- 1.通过这次的个人项目作业,锻炼了自己的编程能力,但同时发现自己对很多内容还不熟悉,通过不断查阅资料,了解到一些外部包对这次的项目有很大的帮助。
- 2.通过这次的作业,了解到一个项目不仅仅是写代码,还需要对代码进行测试,对程序进行性能分析,对程序进行改进,书写项目报告等,这些都是必不可少的。
5.参考文章
- https://blog.csdn.net/haishu_zheng/article/details/80430106
- https://blog.csdn.net/weixin_44208569/article/details/90315904
- https://www.cnblogs.com/dsgcBlogs/p/8619566.html
- https://blog.csdn.net/lwc5411117/article/details/84109580
- https://blog.csdn.net/ezreal_tao/article/details/107359217?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163152183516780262539055%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=163152183516780262539055&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2
- https://docs.python.org/zh-cn/3/library/unittest.html
- https://www.liaoxuefeng.com/wiki/1016959663602400/1017604210683936

 浙公网安备 33010602011771号
浙公网安备 33010602011771号