使用共享内存查询纯真IP库[转]
【转载】
纯真IP库是网上一种比较完整的常用的ip库,基本上每5天更新一次。
我写了个程序通过把ip库加载到共享内存里,在42万条数据下,单次查询能够达到微秒级。
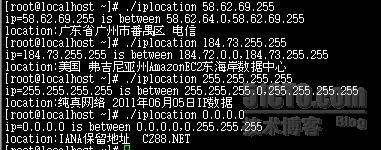
/***** iplocation.c 功能:本程序是把qq纯真ip数据库文件加载到共享内存里,通过参数查找出对应的所属的ip段,和地理位置,使用共享内存可以使查询一次在纳秒级。 qq纯真ip数据库文件格式可以查看:http://lumaqq.linuxsir.org/article/qqwry_format_detail.html qq纯真ip数据库官网下载地址:http://www.cz88.net/fox/ipdat.shtml,需要安装,安装完后把qqwry.dat拷出即可,也可从网上找。 作者:yifangyou 成功运行环境:CentOS 5 i386 gcc version 4.1.2 20071124 (Red Hat 4.1.2-42) 本次测试使用的ip库是 记录总数:429555条 更新日期:2011年06月05日 数据库版本:纯真 输入参数:ip 当输入255.255.255.255显示数据库版本 编译: gcc -o iplocation iplocation.c 运行: [root@localhost ~]# ./iplocation 58.62.69.255 ip=58.62.69.255 is between 58.62.64.0,58.62.69.255 location:广东省广州市番禺区 电信 [root@localhost ~]# ./iplocation 184.73.255.255 ip=184.73.255.255 is between 184.72.0.0,184.73.255.255 location:美国 弗吉尼亚州AmazonEC2东海岸数据中心 [root@localhost ~]# ./iplocation 255.255.255.255 ip=255.255.255.255 is between 255.255.255.0,255.255.255.255 location:纯真网络 2011年06月05日IP数据 [root@localhost ~]# ./iplocation 0.0.0.0 ip=0.0.0.0 is between 0.0.0.0,0.255.255.255 location:IANA保留地址 CZ88.NET *******/ #include <sys/mman.h> #include <fcntl.h> #include <sys/types.h> #include <math.h> #include <unistd.h> #include <stdio.h> #include <string.h> #include <sys/stat.h> #include <netinet/in.h> #include <errno.h> #define SHARE_MEMORY_FILE "/tmp/qqwry.dat" //共享内存路径.ip库路径 #define UNKNOWN "Unknown" #define SHARE_MEMORY_SIZE 10485760 //必须比ip库文件大 #define INET6_ADDRSTRLEN 46 #define RECORD_LEN 7 //单条记录长度 //共享内存指针 char *p_share; //第一条记录指针 char *p_begin; char *p_end; //总记录数 long total_record; //结果集 typedef struct { char *p_country; char *p_area; char beginip[INET6_ADDRSTRLEN]; // 用户IP所在范围的开始地址 char endip[INET6_ADDRSTRLEN]; // 用户IP所在范围的结束地址 }location; //把4字节转为整数 unsigned long getlong4(char *pos) //将读取的4个字节转化为长整型数 { unsigned long result=(((unsigned char )(*(pos+3)))<<24) +(((unsigned char )(*(pos+2)))<<16) +(((unsigned char )(*(pos+1)))<<8) +((unsigned char )(*(pos))); return result; } //把3字节转为整数 unsigned long getlong3(char *pos) //将读取的3个字节转化为长整型数 { unsigned long result=(((unsigned char )(*(pos+2)))<<16) +(((unsigned char )(*(pos+1)))<<8) +((unsigned char )(*(pos))); return result; } /** * 创建共享内存,并加载ip库进去 * * @return void */ void createshare() { int fd; long filesize=0; FILE *fp=fopen(SHARE_MEMORY_FILE,"rb"); //读取文件长度 fseek(fp,0,SEEK_END); filesize=ftell(fp); //归零 fseek(fp,0,SEEK_SET); //获得文件描述符,用于生成共享内存 fd=open(SHARE_MEMORY_FILE,O_CREAT|O_RDWR|O_TRUNC,00777); p_share = (char*) mmap(NULL,SHARE_MEMORY_SIZE,PROT_READ|PROT_WRITE,MAP_SHARED,fd,0 ); lseek(fd,0,SEEK_SET); //把文件内容读入共享内存 fread(p_share,filesize,1,fp); fclose(fp); close(fd); } /** * 打开共享内存指针 * * @return void */ void openshare() // map a normal file as shared mem: { int fd; fd=open(SHARE_MEMORY_FILE,O_RDWR,00777); //打开共享内存 p_share = (char*)mmap(NULL,SHARE_MEMORY_SIZE,PROT_READ,MAP_SHARED,fd,0); if(p_share==MAP_FAILED) { //若是不存在则创建 createshare(); } close(fd); //第一条记录位置 p_begin=p_share+getlong4(p_share); //最后一条记录位置 p_end=p_share+getlong4(p_share+4); //记录总数 total_record=(getlong4(p_share+4)-getlong4(p_share))/RECORD_LEN; } /** * 关闭共享内存指针 * * @return void */ void closeshare() { munmap( p_share, SHARE_MEMORY_SIZE); } /** * 返回地区信息 * * @char *pos 地区的指针 * @return char * */ char *getarea(char *pos) { char *byte=pos; // 标志字节 pos++; switch (*byte) { case 0: // 没有区域信息 return UNKNOWN; break; case 1: case 2: // 标志字节为1或2,表示区域信息被重定向 return p_share+getlong3(pos); break; default: // 否则,表示区域信息没有被重定向 return byte; break; } } //获得ip所属地理信息,isp void getipinfo(char *ipstr,location *p_loc) { char *pos = p_share; int record_len=10; char *firstip=0; // first record position //把ip转为整数 unsigned long ip=htonl(inet_addr(ipstr)); firstip=p_begin; long l=0; long u=total_record; long i=0; char* findip=firstip; unsigned long beginip=0; unsigned long endip=0; //二分法查找 while(l <= u) { i=(l+u)/2; pos=firstip+i*RECORD_LEN; beginip = getlong4(pos); pos+=4; if(ip<beginip) { u=i-1; } else { endip=getlong4(p_share+getlong3(pos)); if(ip>endip) { l=i+1; } else { findip=firstip+i*RECORD_LEN; break; } } } long offset = getlong3(findip+4); pos=p_share+offset; endip= getlong4(pos); // 用户IP所在范围的结束地址 pos+=4; unsigned long j=ntohl(beginip); inet_ntop(AF_INET,&j,p_loc->beginip, INET6_ADDRSTRLEN);// 获得开始地址的IP字符串类型 j=ntohl(endip); inet_ntop(AF_INET,&j,p_loc->endip, INET6_ADDRSTRLEN);// 获得结束地址的IP字符串类型 char *byte = pos; // 标志字节 pos++; switch (*byte) { case 1:{ // 标志字节为1,表示国家和区域信息都被同时重定向 long countryOffset = getlong3(pos); // 重定向地址 pos+=3; pos=p_share+countryOffset; byte = pos; // 标志字节 pos++; switch (*byte) { case 2: // 标志字节为2,表示国家信息又被重定向 { p_loc->p_country=p_share+getlong3(pos); pos=p_share+countryOffset+4; p_loc->p_area = getarea(pos); } break; default: // 否则,表示国家信息没有被重定向 { p_loc->p_country=byte; p_loc->p_area = getarea(p_loc->p_country+strlen(p_loc->p_country)+1); } break; } } break; case 2: // 标志字节为2,表示国家信息被重定向 { p_loc->p_country=p_share+getlong3(pos); p_loc->p_area=p_share+offset+8; } break; default:{ // 否则,表示国家信息没有被重定向 p_loc->p_country=byte; p_loc->p_area=getarea(p_loc->p_country+strlen(p_loc->p_country)+1); } break; } } int main(int argc, char** argv) { if(argc<2) { printf("please enter the checked ip.\n"); } location loc={0}; //打开共享内存 openshare(); getipinfo(argv[1],&loc); printf("ip=%s is between %s,%s\n",argv[1],loc.beginip,loc.endip); printf("location:%s %s\n",loc.p_country,loc.p_area); //关闭共享内存 // closeshare(); return 0; }
版权归原作者所有,转载自https://blog.51cto.com/yifangyou/617658
纯真IP数据库格式详解 附demo【转载】
转载自:https://www.cnblogs.com/kjcy8/p/5787723.html
纯真版IP数据库,优点是记录多,查询速度快,它只用一个文件QQWry.dat就包含了所有记录,方便嵌入到其他程序中,也方便升级。缺点是你想要编辑它却是比较麻烦的,由于其文件格式的限制,你要直接添加IP记录就不容易了
基本结构
QQWry.dat 文件在结构上分为3块:文件头,记录区,索引区。一般我们要查找IP时,先在索引区查找记录偏移,然后再到记录区读出信息。由于记录区的记录是不定长的, 所以直接在记录区中搜索是不可能的。由于记录数比较多,如果我们遍历索引区也会是有点慢的,一般来说,我们可以用二分查找法搜索索引区,其速度比遍历索引 区快若干数量级。图1是QQWry.dat的文件结构图。
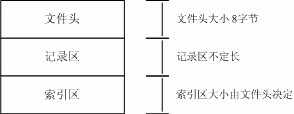
图1. QQWry.dat文件结构
要注意的是,QQWry.dat里面全部采用了little-endian字节序
一. 了解文件头
QQWry.dat的文件头只有8个字节,其结构非常简单,首四个字节是第一条索引的绝对偏移,后四个字节是最后一条索引的绝对偏移。
二. 了解记录区
每 条IP记录都由国家和地区名组成,国家地区在这里并不是太确切,因为可能会查出来“清华大学计算机系”之类的,这里清华大学就成了国家名了,所以这个国家 地区名和IP数据库制作的时候有关系。所以记录的格式有点像QName,有一个全局部分和局部部分组成,我们这里还是沿用国家名和地区名的说法。
于 是我们想象着一条记录的格式应该是: [IP地址][国家名][地区名],当然,这个没有什么问题,但是这只是最简单的情况。很显然,国家名和地区名可能会有很多的重复,如果每条记录都保存一 个完整的名称拷贝是非常不理想的,所以我们就需要重定向以节省空间。所以为了得到一个国家名或者地区名,我们就有了两个可能:第一就是直接的字符串表示的 国家名,第二就是一个4字节的结构,第一个字节表明了重定向的模式,后面3个字节是国家名或者地区名的实际偏移位置。对于国家名来说,情况还可能更复杂 些,因为这样的重定向最多可能有两次。
那么什么是重定向模式?根据上面所说,一条记录的格式是[IP地址][国家记录][地区记录],如果国家记录是重定向的话,那么地区记录是有可能没有的,于是就有了两种情况,我管他叫做模式1和模式2。我们对这些格式的情况举图说明:

图2. IP记录的最简单形式
图2表示了最简单的IP记录格式,我想没有什么可以解释的
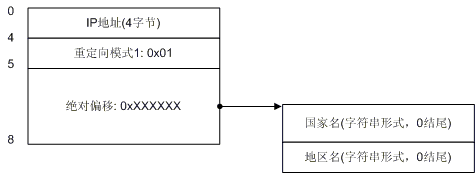
图3. 重定向模式1
图3演示了重定向模式1的情况。我们看到在模式1的情况下,地区记录也跟着国家记录走了,在IP地址之后只剩下了国家记录的4字节,后面3个字节构成了一个指针,指向了实际的国家名,然后又跟着地址名。模式1的标识字节是0x01。
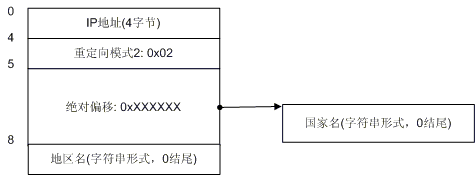
图4. 重定向模式2
图 4演示了重定向模式2的情况。我们看到了在模式2的情况下(其标识字节是0x02),地区记录没有跟着国家记录走,因此在国家记录之后4个字节之后还是有 地区记录。我想你已经明白了模式1和模式2的区别,即:模式1的国家记录后面不会再有地区记录,模式2的国家记录后会有地区记录。下面我们来看一下更复杂 的情况。

图5. 混和情况1
图 5演示了当国家记录为模式1的时候可能出现的更复杂情况,在这种情况下,重定向指向的位置仍然是个重定向,不过第二次重定向为模式2。大家不用担心,没有 模式3了,这个重定向也最多只有两次,并且如果发生了第二次重定向,则其一定为模式2,而且这种情况只会发生在国家记录上,对于地区记录,模式1和模式2 是一样的,地区记录也不会发生2次重定向。不过,这个图还可以更复杂,如图7:
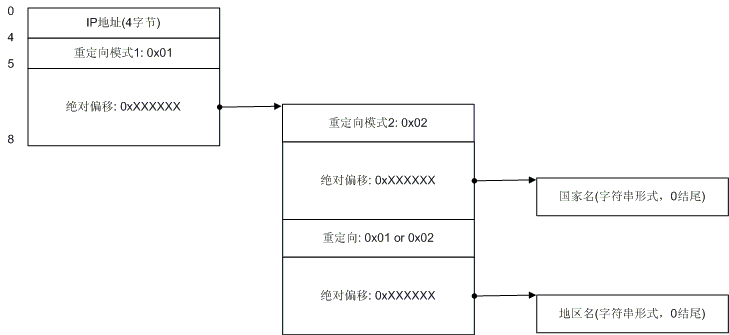
图6. 混和情况2
图6是模式1下最复杂的混和情况,不过我想应该也很好理解,只不过地区记录也来重定向而已,有一点我要提醒你,如果重定向的地址是0,则表示未知的地区名。
所 以我们总结如下:一条IP记录由[IP地址][国家记录][地区记录]组成,对于国家记录,可以有三种表示方式:字符串形式,重定向模式1和重定向模式 2。对于地区记录,可以有两种表示方式:字符串形式和重定向,另外有一条规则:重定向模式1的国家记录后不能跟地区记录。按照这个总结,在这些方式中合理 组合,就构成了IP记录的所有可能情况。
设计的理由
在我们继续去了解索引区的结构之前,我们先来了解一下为何记录区的结构要如此设 计。我想你可能想到了答案:字符串重用。没错,在这种结构下,对于一个国家名和地区名,我只需要保存其一次就可以了。我们举例说明,为了表示方便,我们用 小写字母代表IP记录,C表示国家名,A表示地区名:
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2, A1 = A2,那么我们就可以使用图3显示的结构来实现重用
有三条记录a(C1, A1), b(C2, A2), c(C3, A3),如果C1 = C2, A2 = A3,现在我们想存储记录b,那么我们可以用图6的结构来实现重用
有两条记录a(C1, A1), b(C2, A2),如果C1 = C2,现在我们想存储记录b,那么我们可以采用模式2表示C2,用字符串表示A2
你可以举出更多的情况,你也会发现在这种结构下,不同的字符串只需要存储一次。
了解索引区
在"了解文件头"部分,我们说明了文件头实际上是两个指针,分别指向了第一条索引和最后一条索引的绝对偏移。如图8所示:
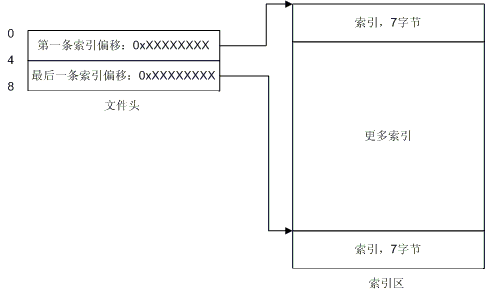
图8. 文件头指向索引区图示
实 在是很简单,不是吗?从文件头你就可以定位到索引区,然后你就可以开始搜索IP了!每条索引长度为7个字节,前4个字节是起始IP地址,后三个字节就指向 了IP记录。这里有些概念需要说明一下,什么是起始IP,那么有没有结束IP? 假设有这么一条记录:166.111.0.0 - 166.111.255.255,那么166.111.0.0就是起始IP,166.111.255.255就是结束IP,结束IP就是IP记录中的那头 4个字节,这下你应该就清楚了吧。于是乎,每条索引配合一条记录,构成了一个IP范围,如果你要查找166.111.138.138所在的位置,你就会发 现166.111.138.138落在了166.111.0.0 - 166.111.255.255 这个范围内,那么你就可以顺着这条索引去读取国家和地区名了。那么我们给出一个最详细的图解吧:
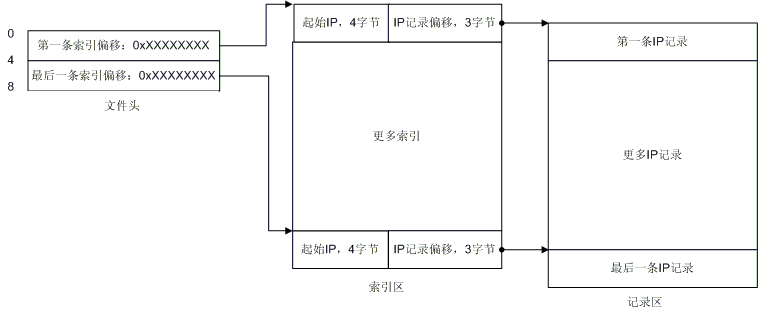

 浙公网安备 33010602011771号
浙公网安备 33010602011771号