
学习wavenet_vocoder之预处理、训练
一、预处理
1.在进行预处理时,如果不明白需要的参数,可以使用命令获取帮助,从这里我们可以看到可以具体的用法和对应的参数。
python preprocess.py --help
1 python preprocess.py ljspeech C:\test\DataSorce\LJSpeech-1.1\LJSpeech-1.1 C:\test\testOutput --preset=C:\test\Code\Python3\wavenet_vocoder\presets\ljspeech_mixture.json

2.接下来就直接输入命令来获取预处理的结果吧。
python preprocess.py ljspeech G:\DataSorce\LJSpeech-1.1\LJSpeech-1.1 G:\testOutput --preset=G:\Code\Python3\wavenet_vocoder-master\presets\ljspeech_mixture.json

3.最终得到的结果就是这些一堆的东西(还在研究有什么用)
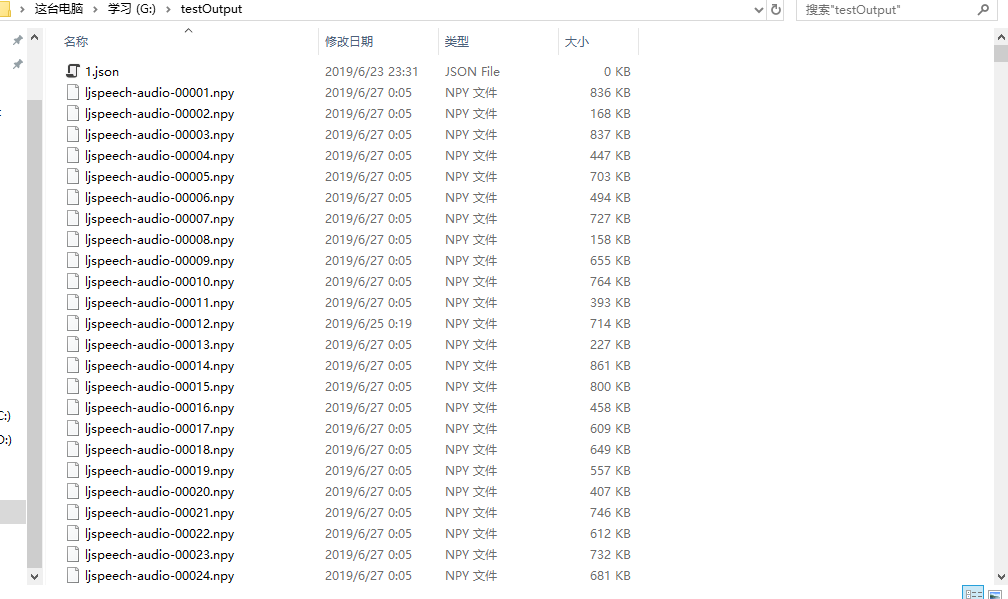
二、训练
1.在进行训练时,如果不明白需要的参数,我们也可以使用命令获取帮助,从这里我们可以看到可以具体的用法和对应的参数。
python preprocess.py --help

2.我们执行训练的命令,遇到了一个问题
python train.py --data-root=G:\testOutput --preset=G:\testOutput\1.json

这个问题遇到了是因为我使用的json没有使用对应的代码中的对应的标准json导致,其实路径就是代码中的/preset/文件夹中的对应json即可
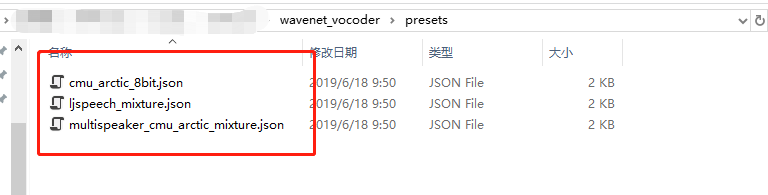
处理完这个问题之后,我们就可以进行训练了,训练的过程比较长,请大家耐心等待。个人使用的电脑cpu为i7 8700k锁频版本,4天生成一个训练模型,请大家酌情考虑。

图为检查点生成结果,因为占用的时间比较就,所以现在在研究具体怎么迁移到虚拟机里面执行和训练量的控制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号