Spark部署打包
Spark部署打包
目录
重点问题
Spark 2.4支持的部署模式
Spark 配置的优先级
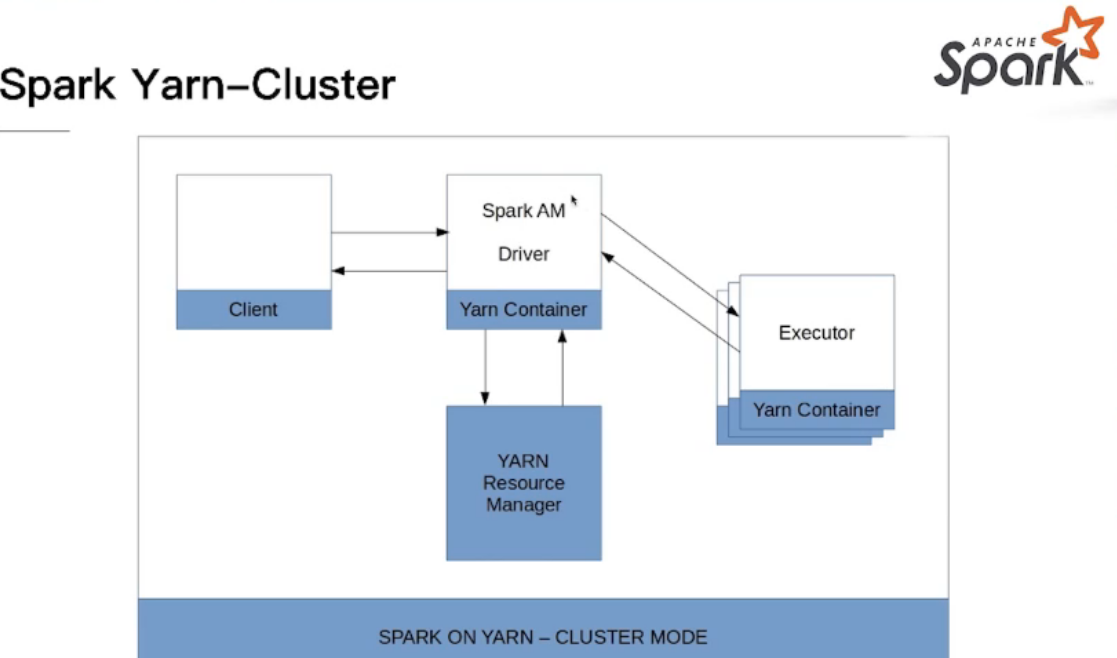
YARN Client模式和YARN Cluster模式
Spark部署模式及原理
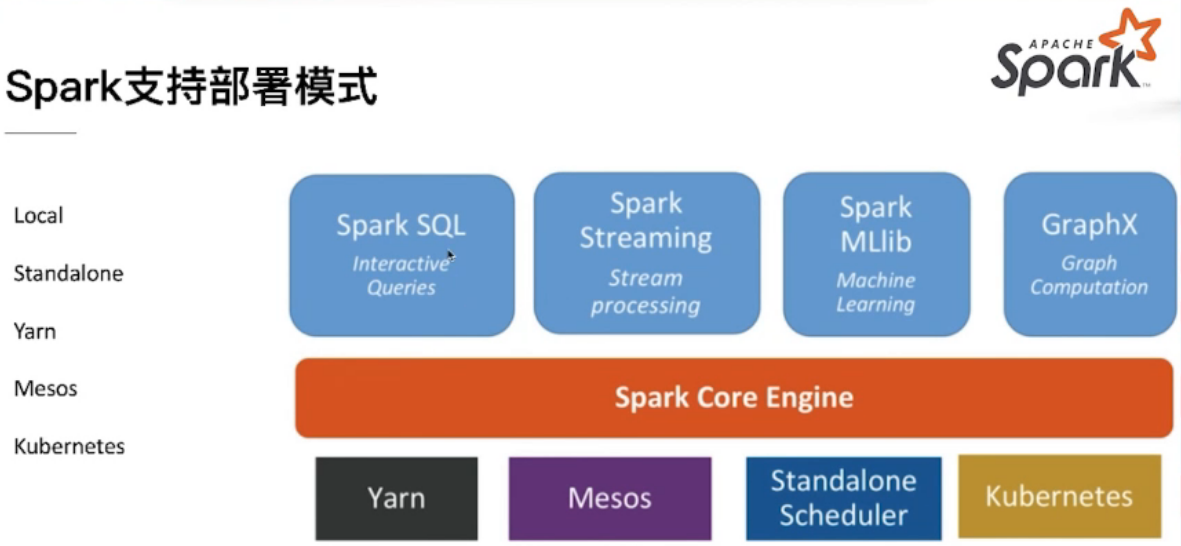
- Local
- StandAlone
- Yarn
- Mesos
- Kubernetes
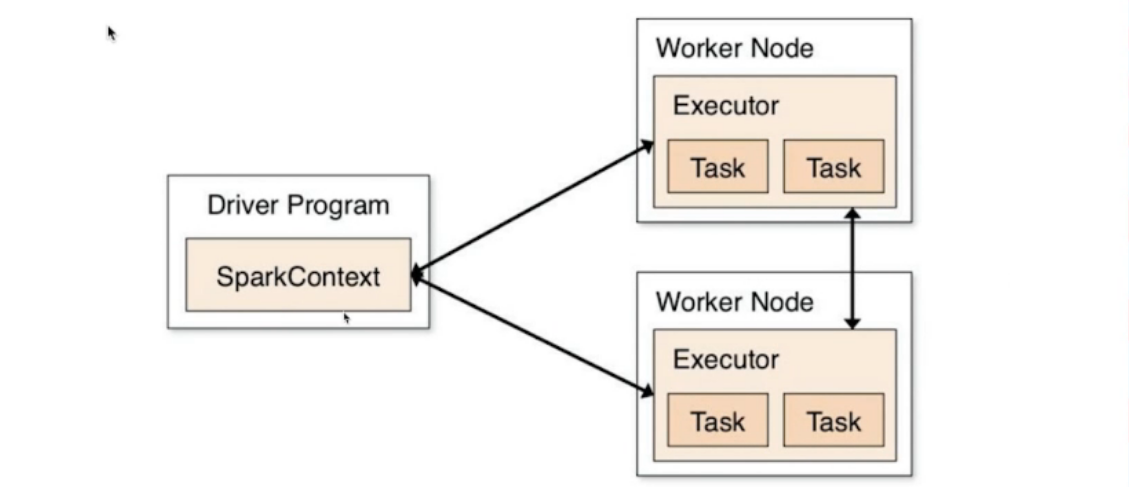

决定driver在什么地方运行,在客户端或者集群端
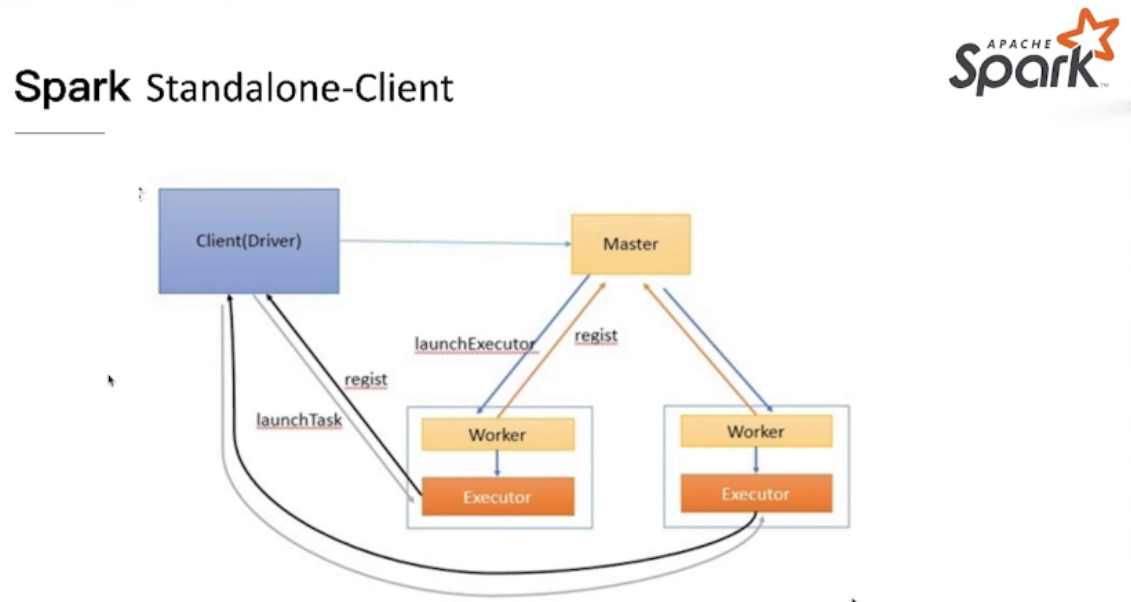
StandAlone Mode
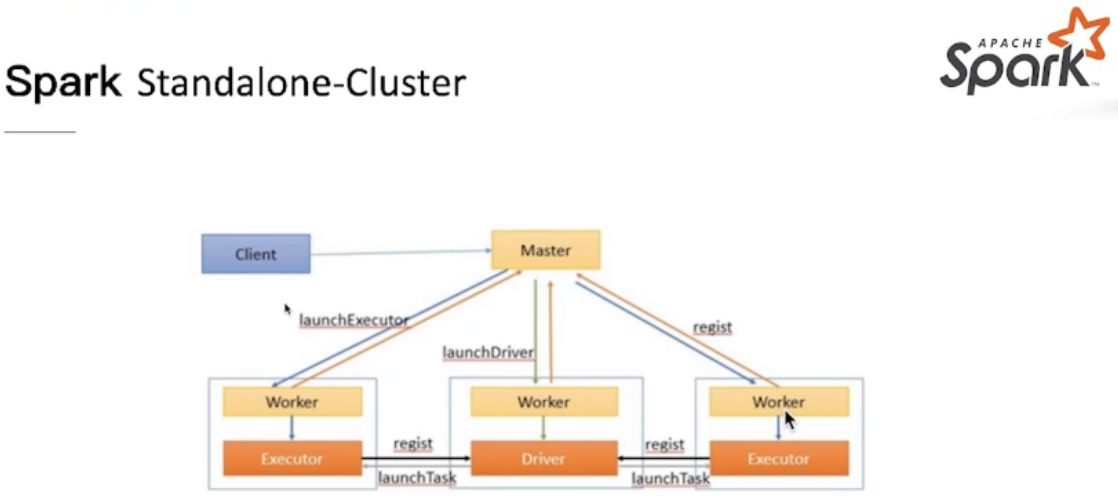
Spark on Yarn Mode
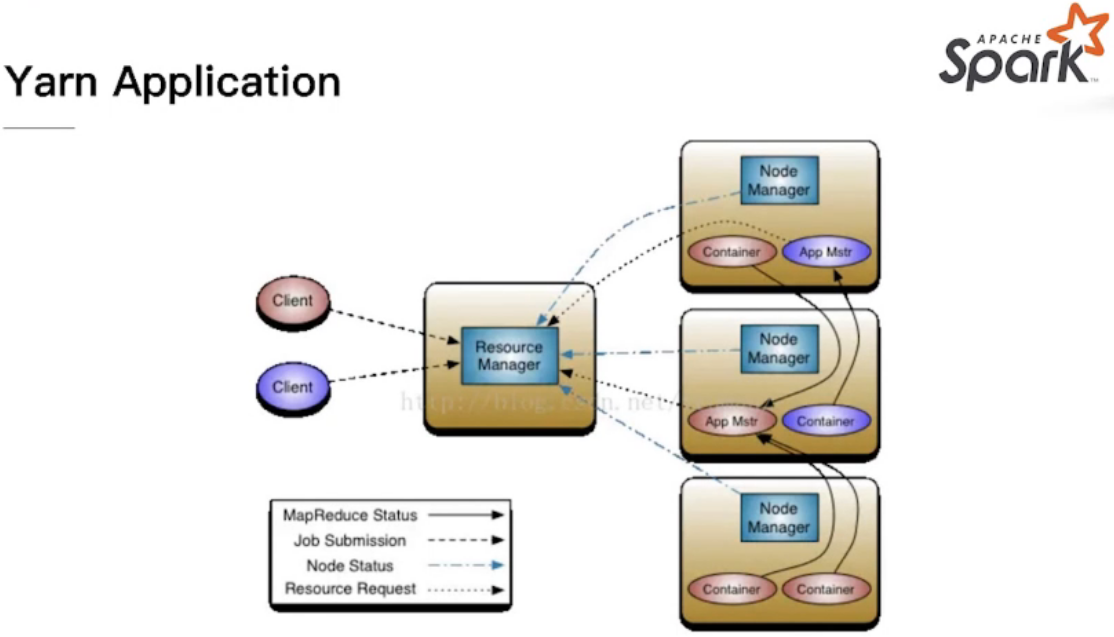
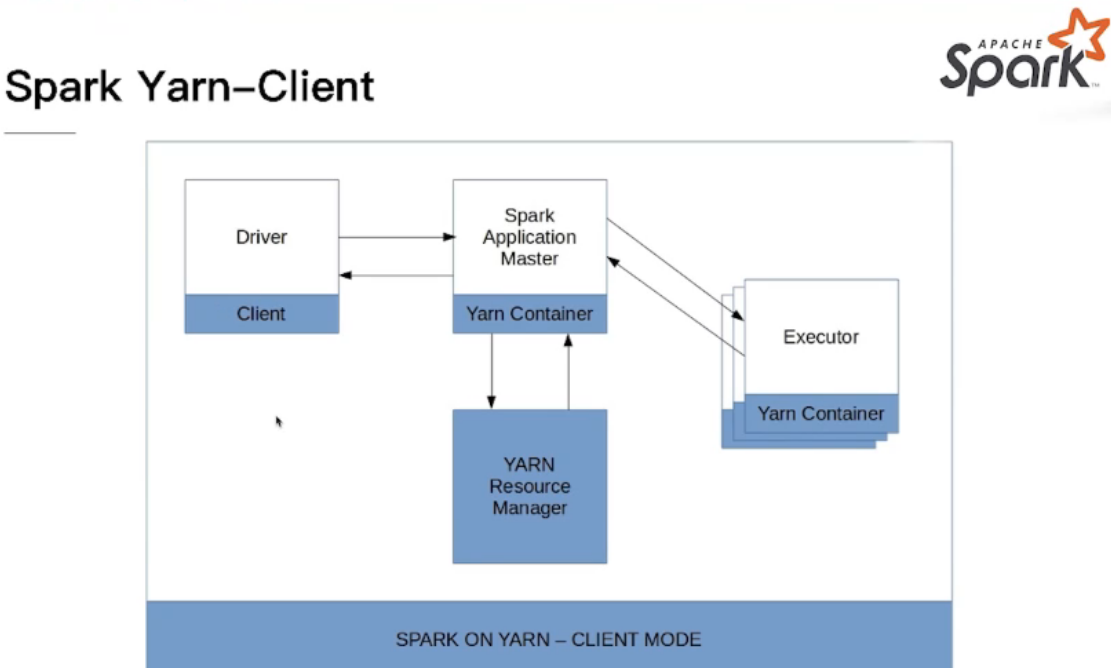
application master的启动是完全随机的,在有资源的机器上运行
Spark部署打包
Spark API

Maven
添加maven依赖

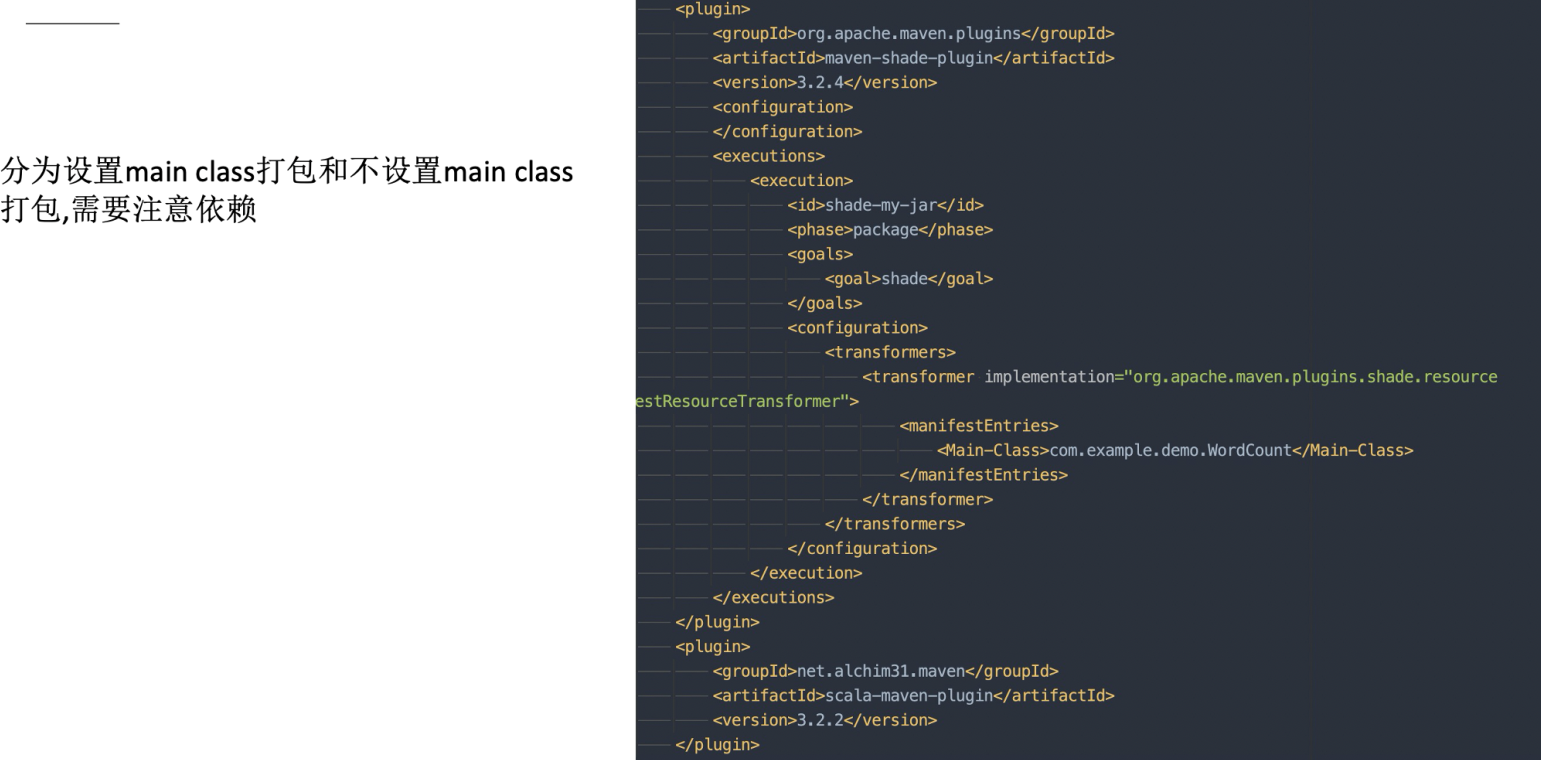
打包
简单的wordcount
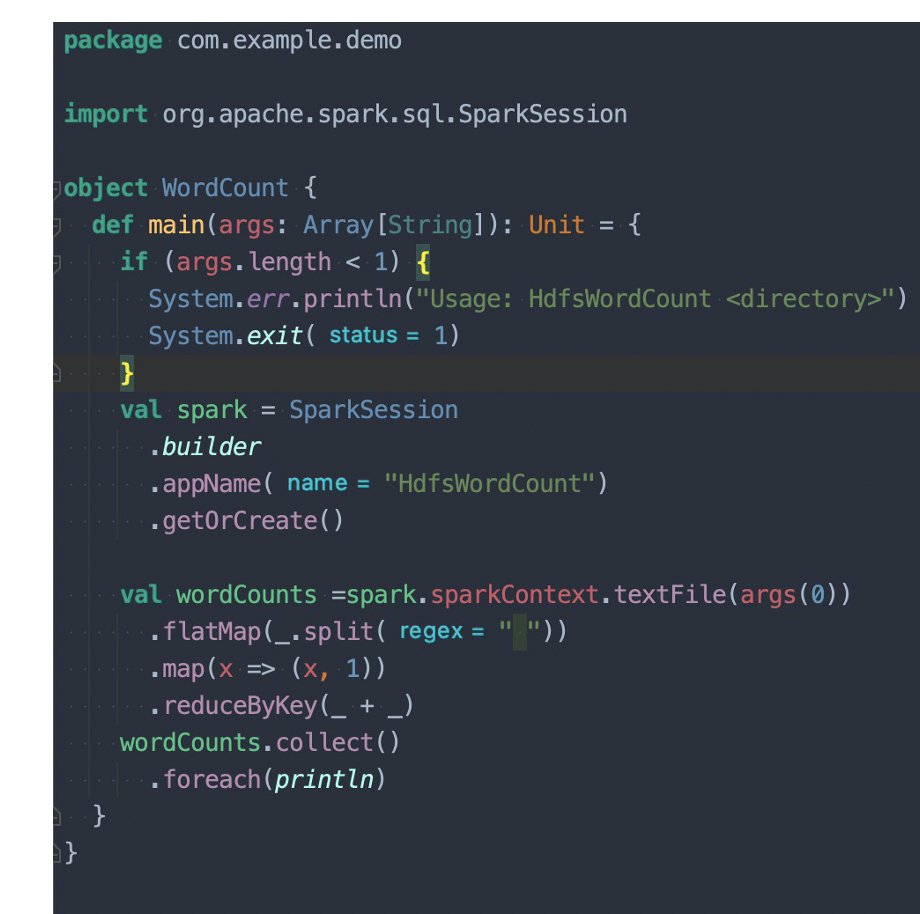
配置




QA
集群模式怎么查看日志?
driver日志可以看 yarn 里面的 application master 日志, executor日志 spark-ui/executors可以看
运行结束得程序可以yarn logs -applicationId
spark在涉及读取hdfs上数据的时候是把数据加载到worker节点上,还是在数据所在的节点上启动计算的进程
spark里面task读取文件一般是通过filesystem的流来读取得, 可以读取本机器hdfs或者其他文件系统得文件 也可以读取其他机器的文件.spark 的schedule会优先把task调度到这个task需要读取文件的机器上,这样的话就不会产生网络流量,减少集群带宽压力,而且读取当前机器的文件这个行为在不同的文件系统可能还会有更多的优化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号