Spark Sql 介绍与实战
Spark Sql 介绍与实战
Spark Sql介绍


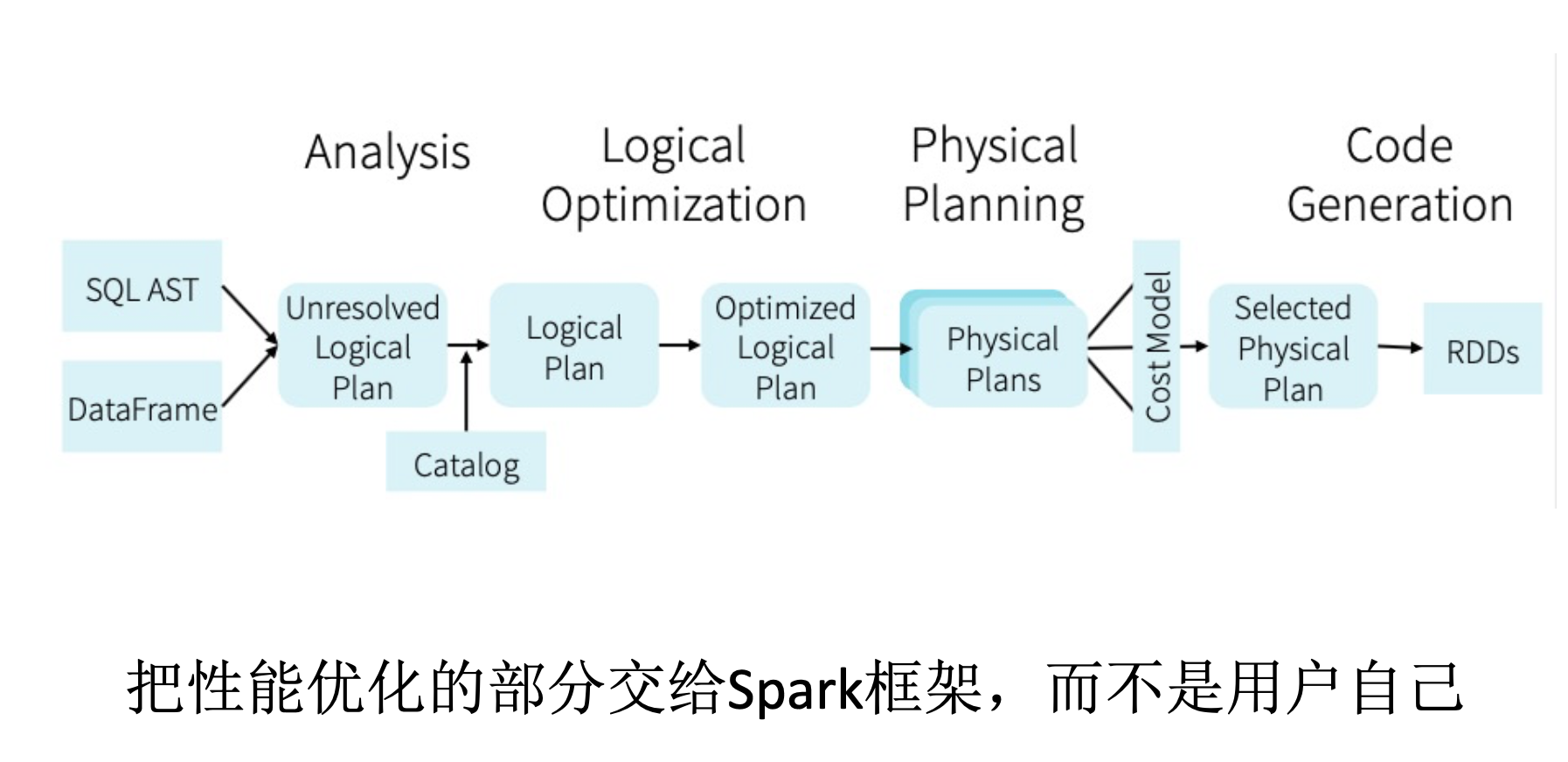
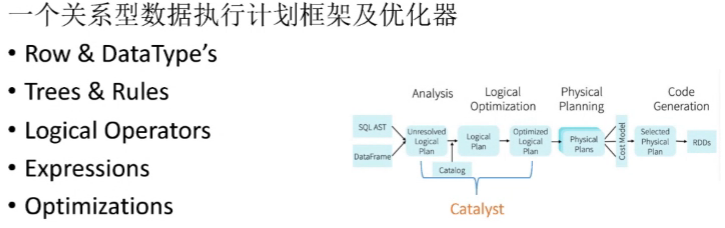
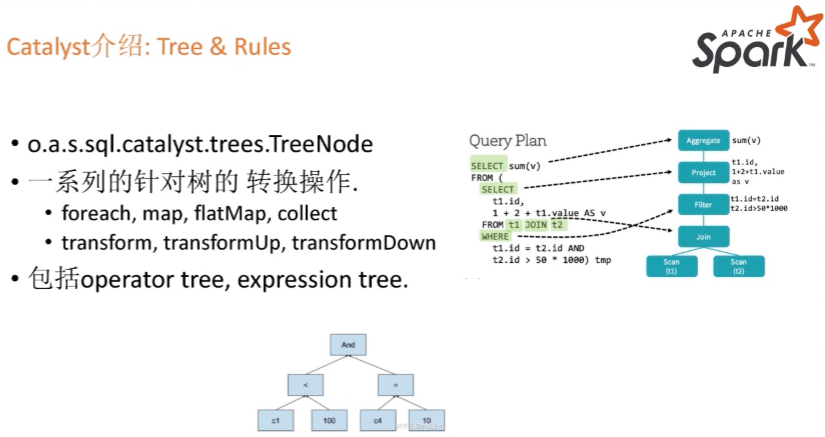
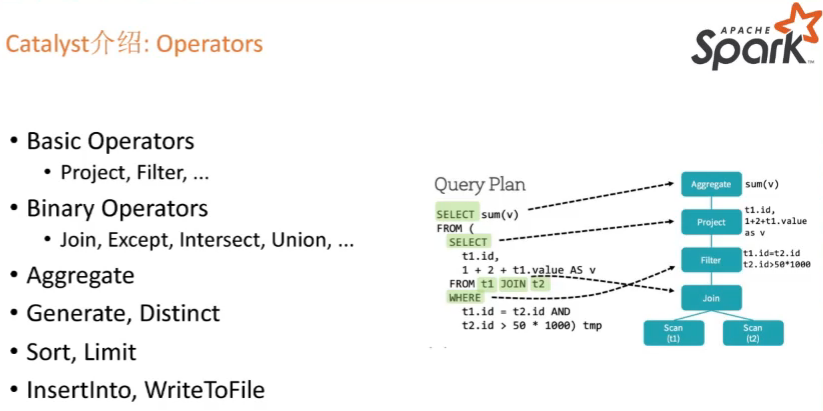
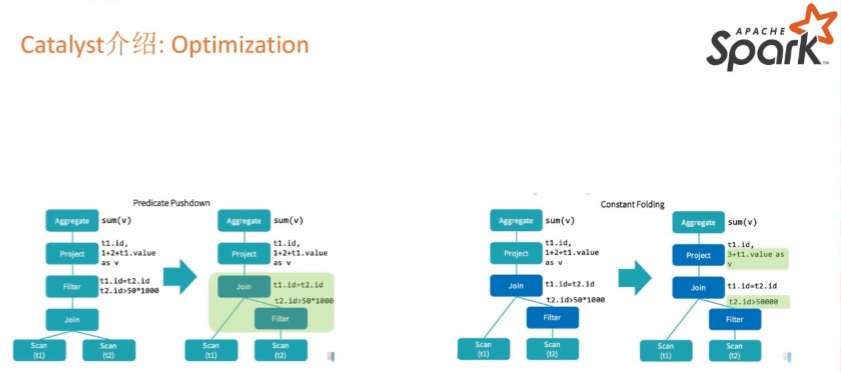
Catalyst




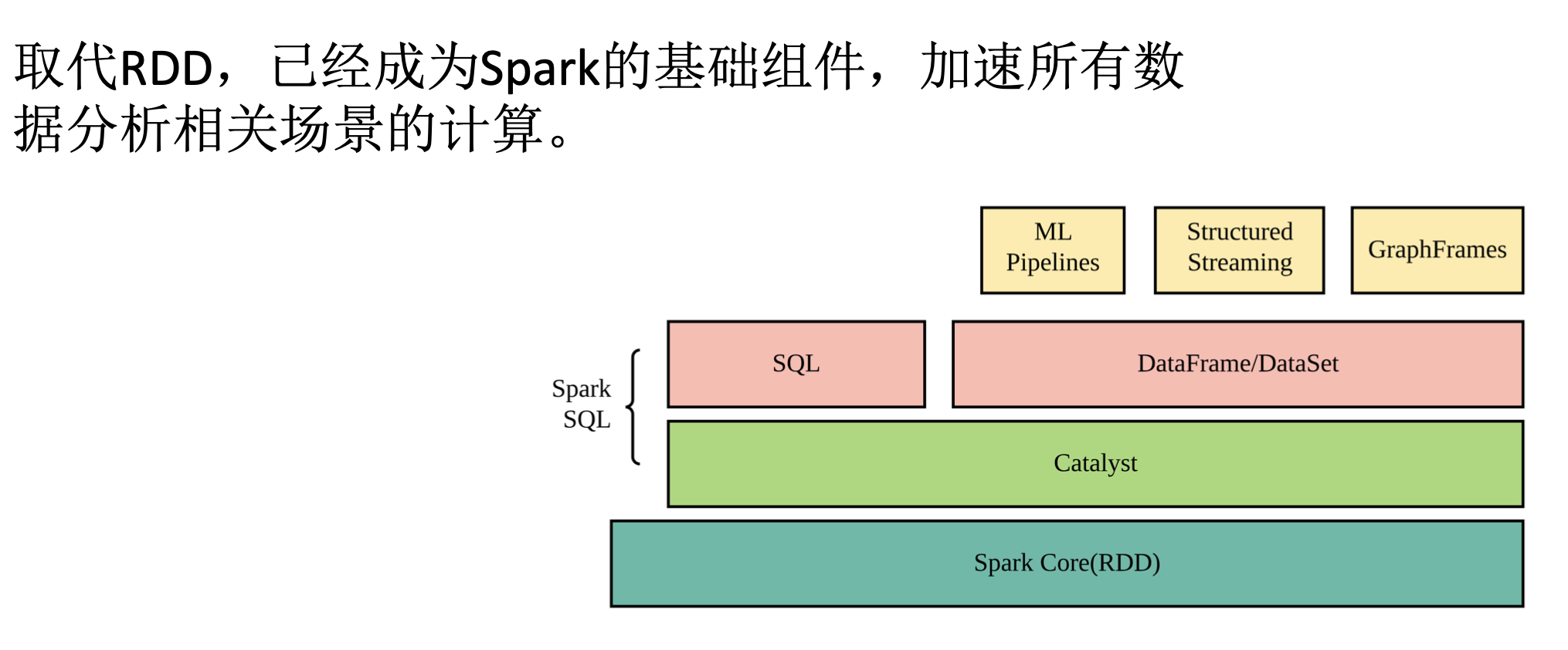
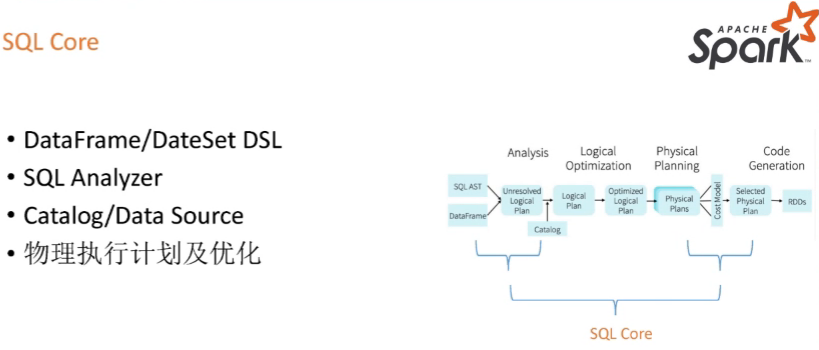
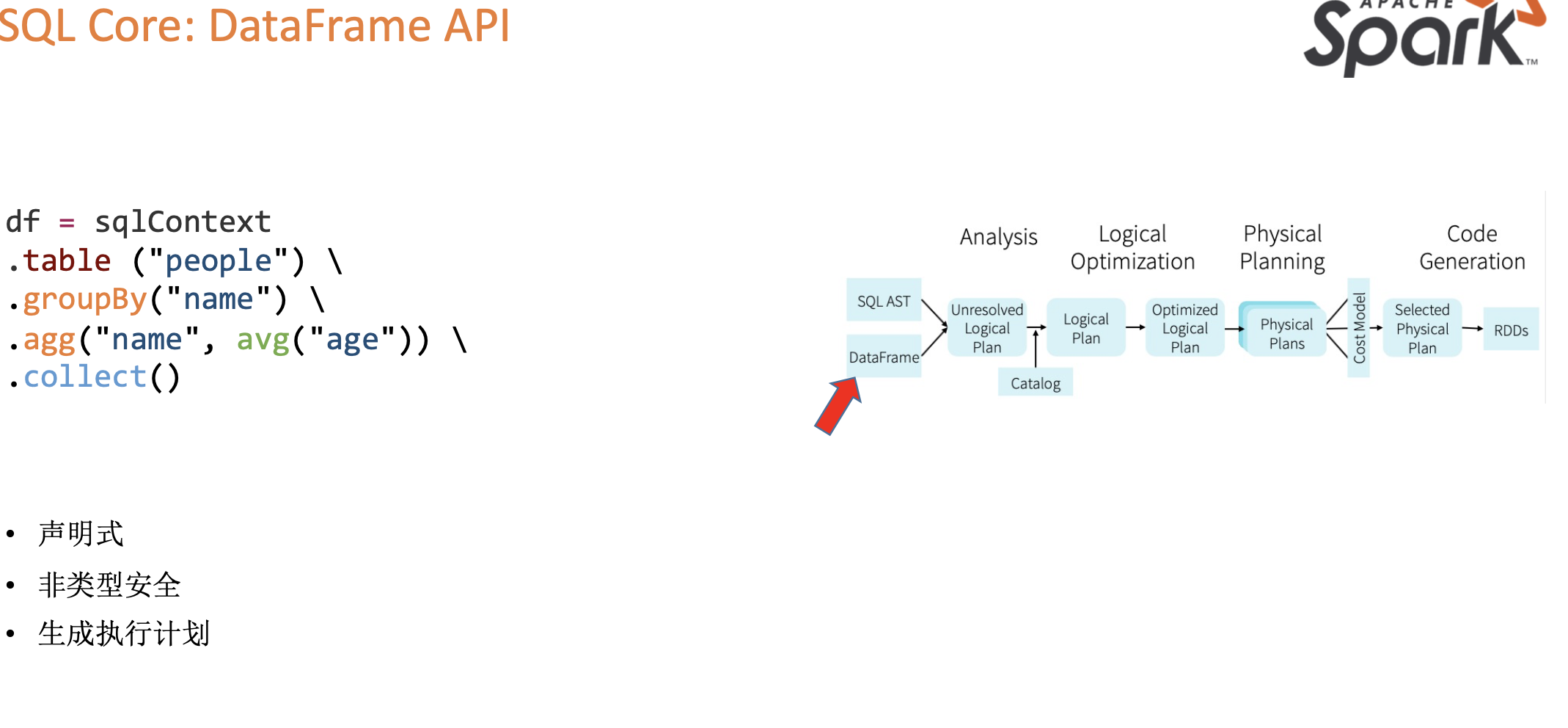
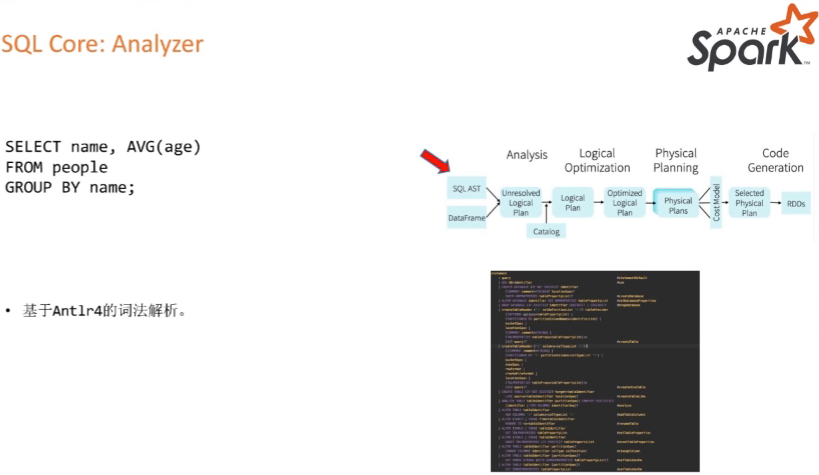
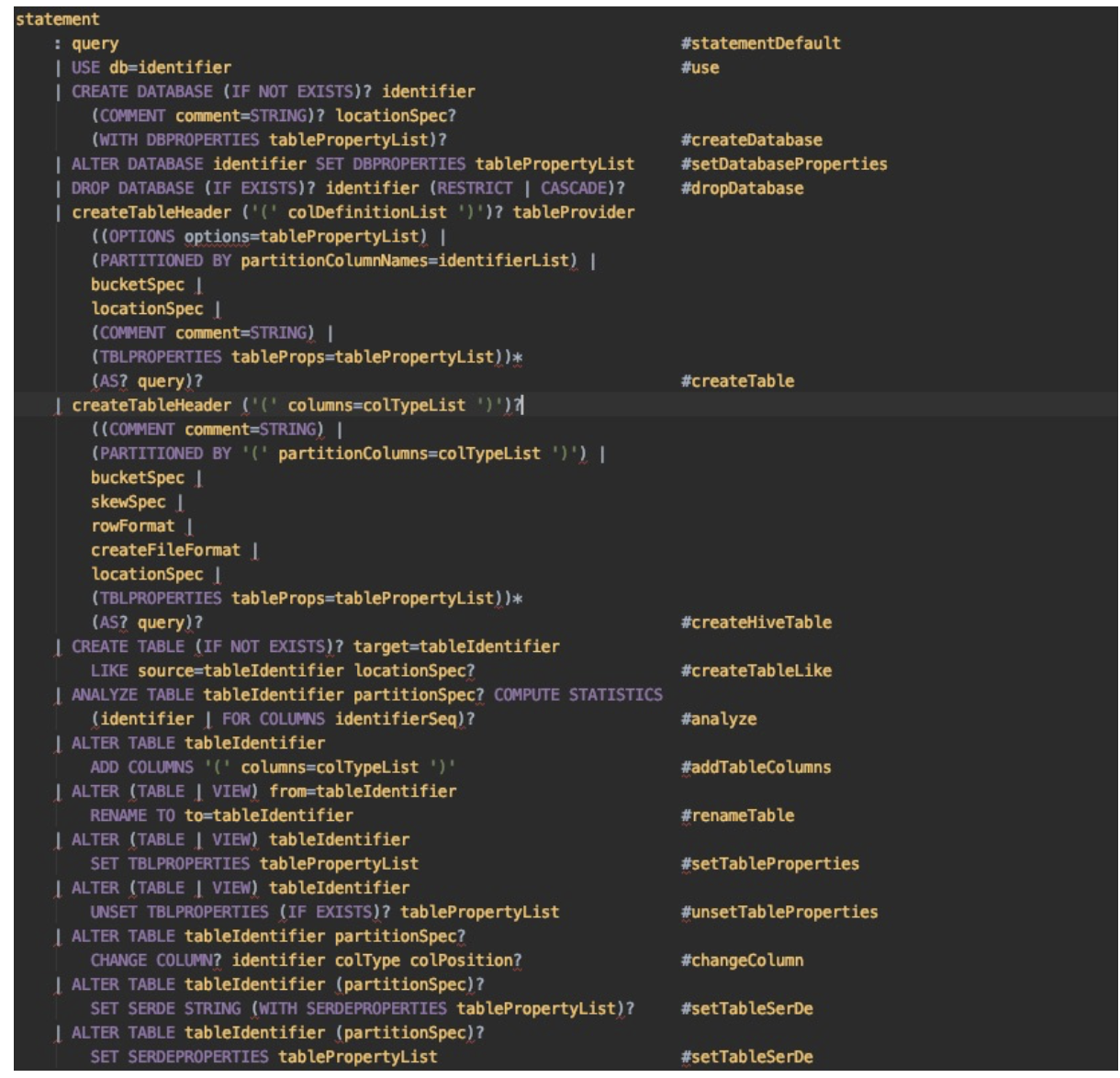
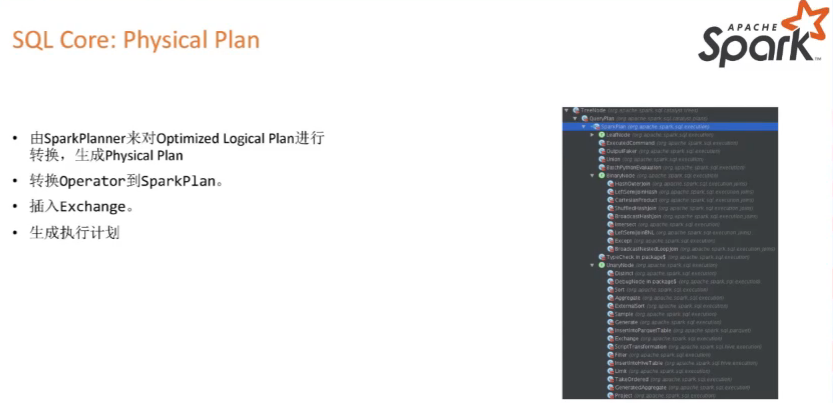
SQL Core

https://spark.apache.org/docs/latest/sql-data-sources.html

SQL实战
spark-sql#启动命令
show databases;
use ssb;
show tables;
desc customer;
desc extended customer; #更详细的信息
select c_region,count(*) from customer group by c_region;
explain select c_region,count(*) from customer group by c_region; #不会真正去执行sql语句,只是展示物理的执行计划
explain extended select c_region,count(*) from customer group by c_region; #更加详细
beeline -u jdbc:hive2://localhost:10001 -n hadoop
show databases;
use ssb_5;
show tables;
select c_region,count(*) from customer group by c_region;
explain select * from lineorder,customer where lo_custkey=c_custkey; #查看物理执行计划,进行分析优化
desc extended customer/lineorder; #查看数据量
cache table xxx as sql...; #进行临时表缓存
broadcast join == map join小表进行广播到每个executor以实现mapjoin,可以减少shuffle,大表就不用shuffle了
重点问题
DataFrame API的write接口Catalyst优化的API开发的Spark任务Spark中支持的不同Join类型、场景
QA
spark 的输出的 INFO信息太多了
设置日志级别:sparkSession.sparkContext.setLogLevel("warn")
比如需要统计某个时间范围内,客服对用户的消息回复率,用sparksql这块处理是否合适呢
怎么写mysql,就怎么写sparksql,业务逻辑的表达都是一样的
在hive里面演示explain, 跟在spark-sql的里面用是一样的吗?
explain可以加在所有query前面,是通用的
Broadcast Hash join Shuffle Hash Join Sort-Merge Join Shufffle Nested Loop Join 对应的应用场景吗
按shuffle类型分为map, shuffle,bucket join.按执行算子可以分为sortmerge, hash, nestedloop,这两种是正交的
dataframe和dataset,这两个区别
dataframe=dataset[row],是种特殊类型的dataset,专门处理关系型数据,处理的数据有schema信息,所以可以优化执行计划
Catalyst 会进行sql的优化,那么是否sql可以不必优化只要表达出想做的的操作就可以么?sparksql既然通过优化以后会转化成RDD去执行计划,是否RDD在处理速度上会更有优势?尤其是面对复杂的逻辑的时候。
SQL就是个表达式的语言,具体一个SQL怎么变成一个高效的分布式spark任务就是catalyst做的事情。理论上自己基于rdd可以做到最优,但是绝大部分人没有这个水平,不如用sparkSQL,简单高效
spark 开发效率比hadoop高,感觉像写本地程序。那hadoop能做的mr,spark都能完成嘛?
都能,而且支持更丰富的算子类型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号