Apache Spark 入门知识
Apache Spark 入门知识
目录
spark 生态系统
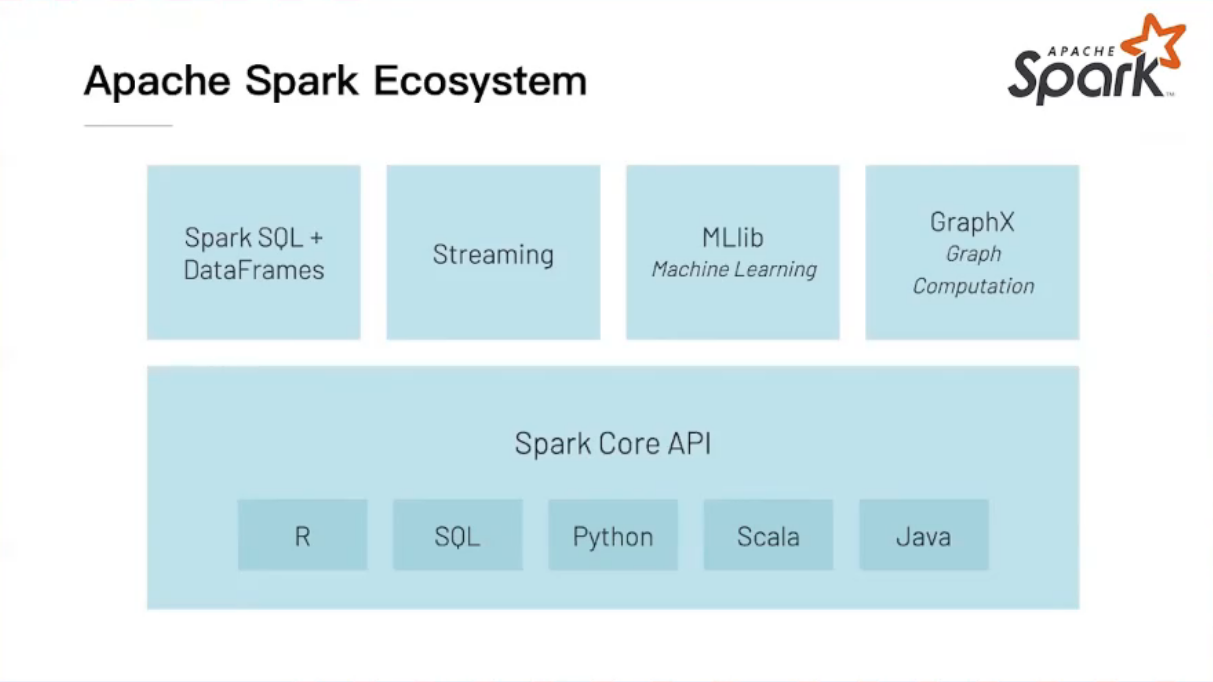
- sparksql,dataframes处理结构化数据
- streaming用于流式场景的模块
-
MLlib机器学习模块
-
GraphX图计算模块
-
底层模块spark core api用于提供多语言支持,是spark最原始的模块,是所有模块的基础
spark架构
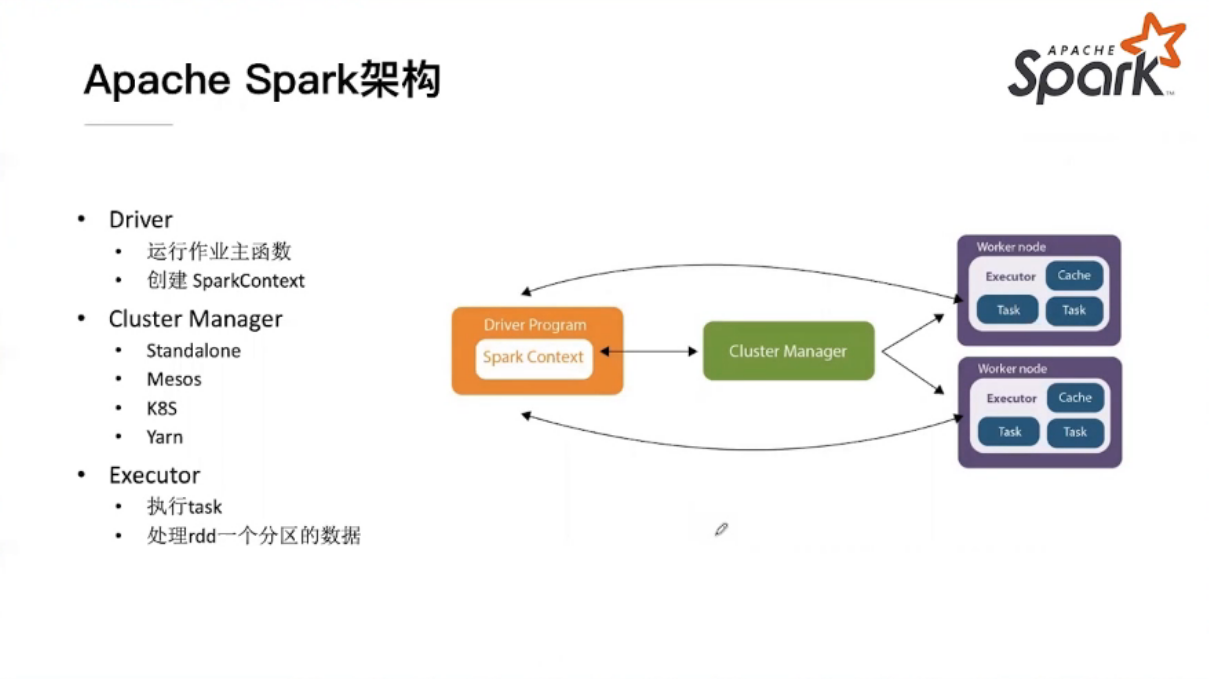
spark的总体执行流程:程序->在driver段运行->通过cluster manager(如yarn等)申请到硬件资源->任务调度至executor中运行
spark相关基本概念
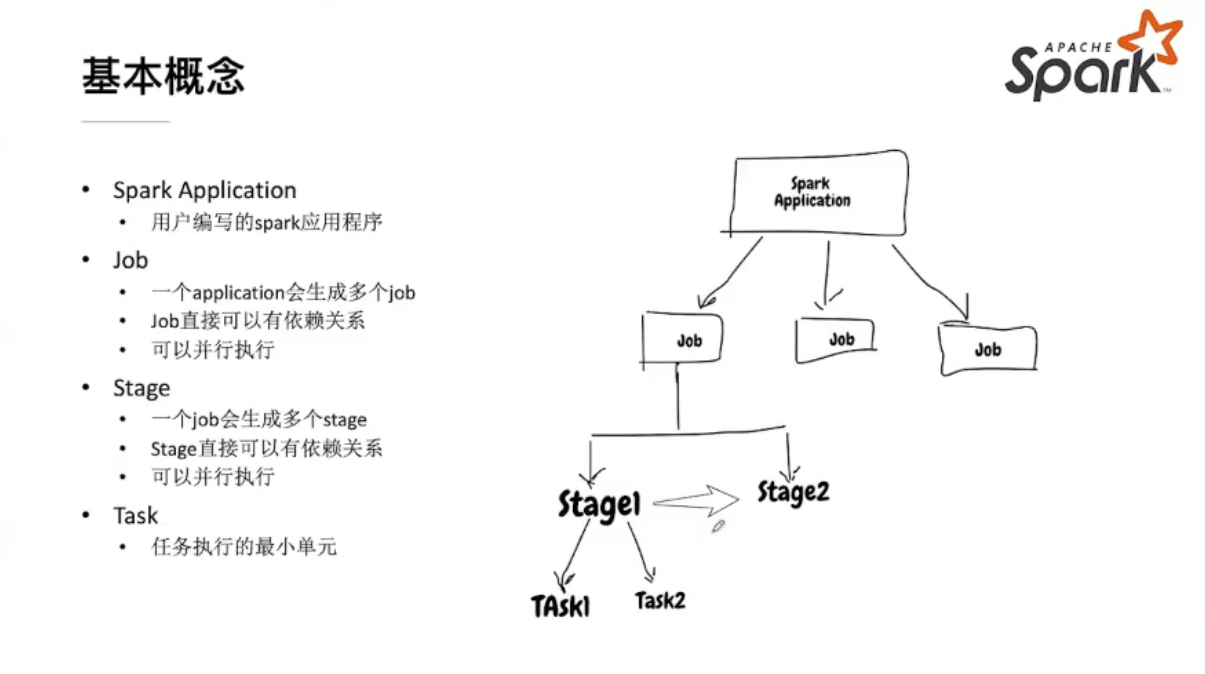
SparkContext && SparkSession

RDD
RDD历史及概念
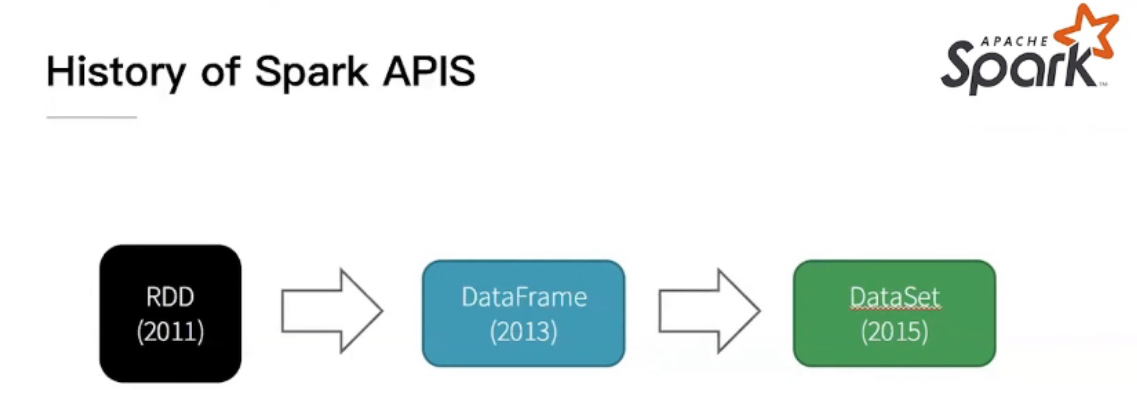
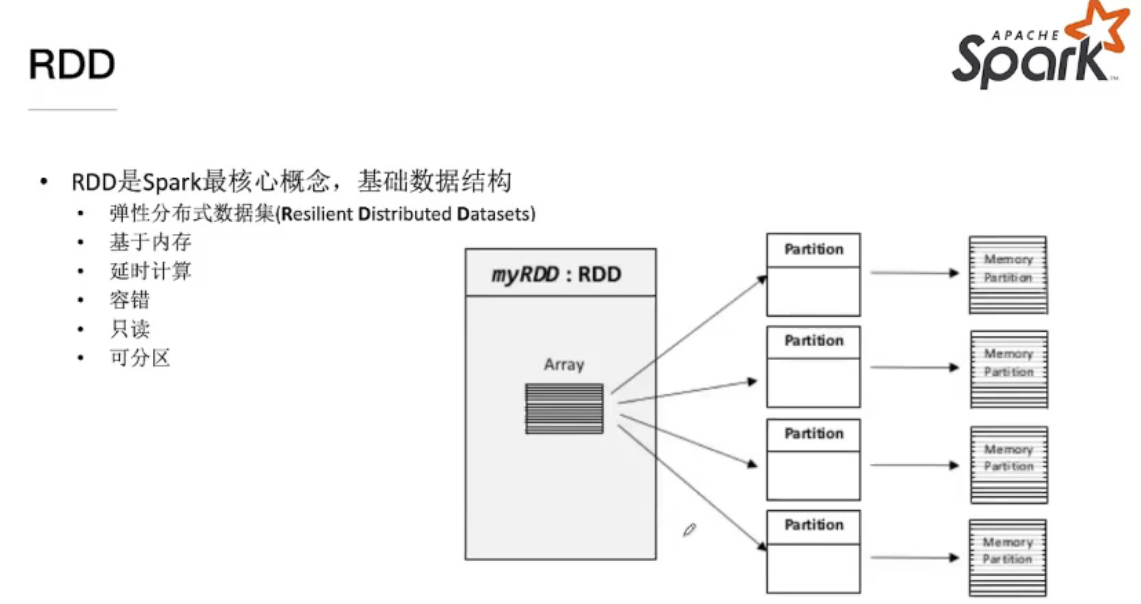
RDD、DATAFRAME、DATASET之间的关系不是更新换代,它们用于解决不同的问题,各有各的用处
RDD 主要创建方式


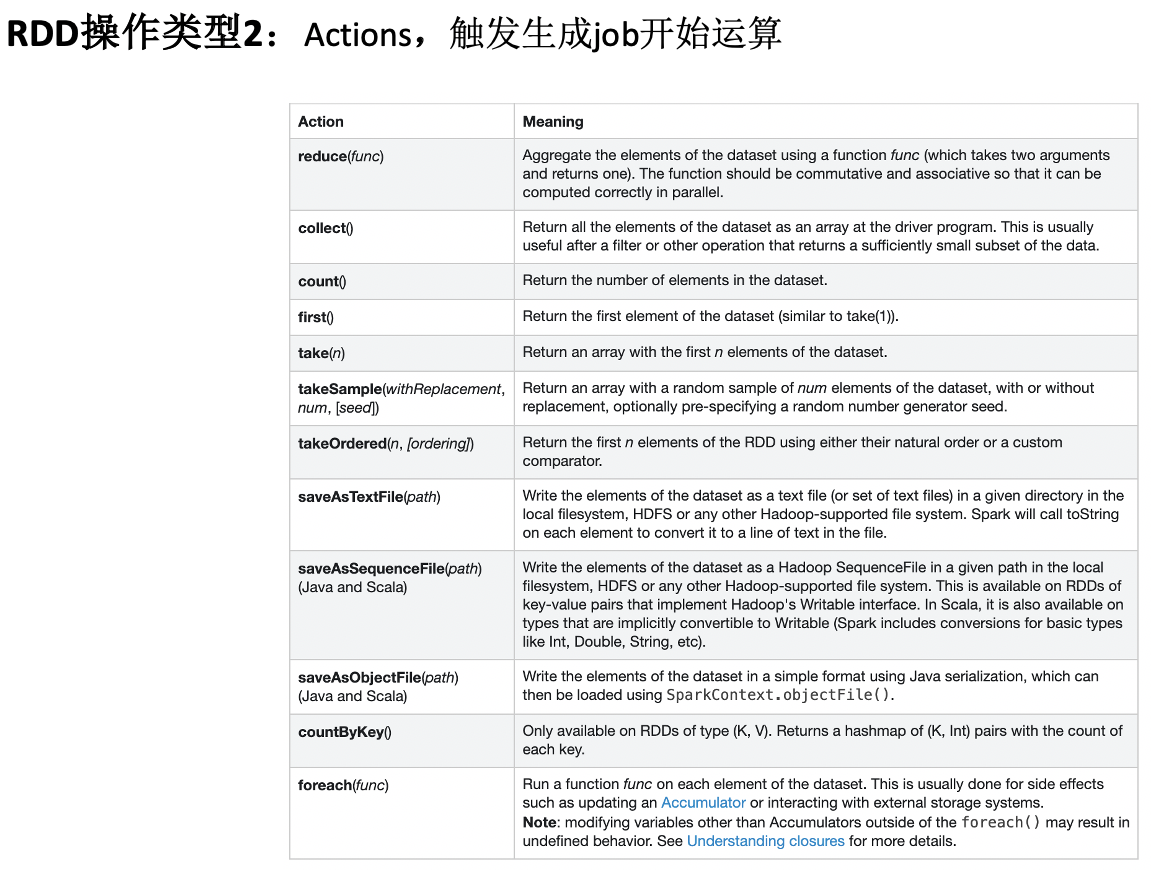
RDD Operations

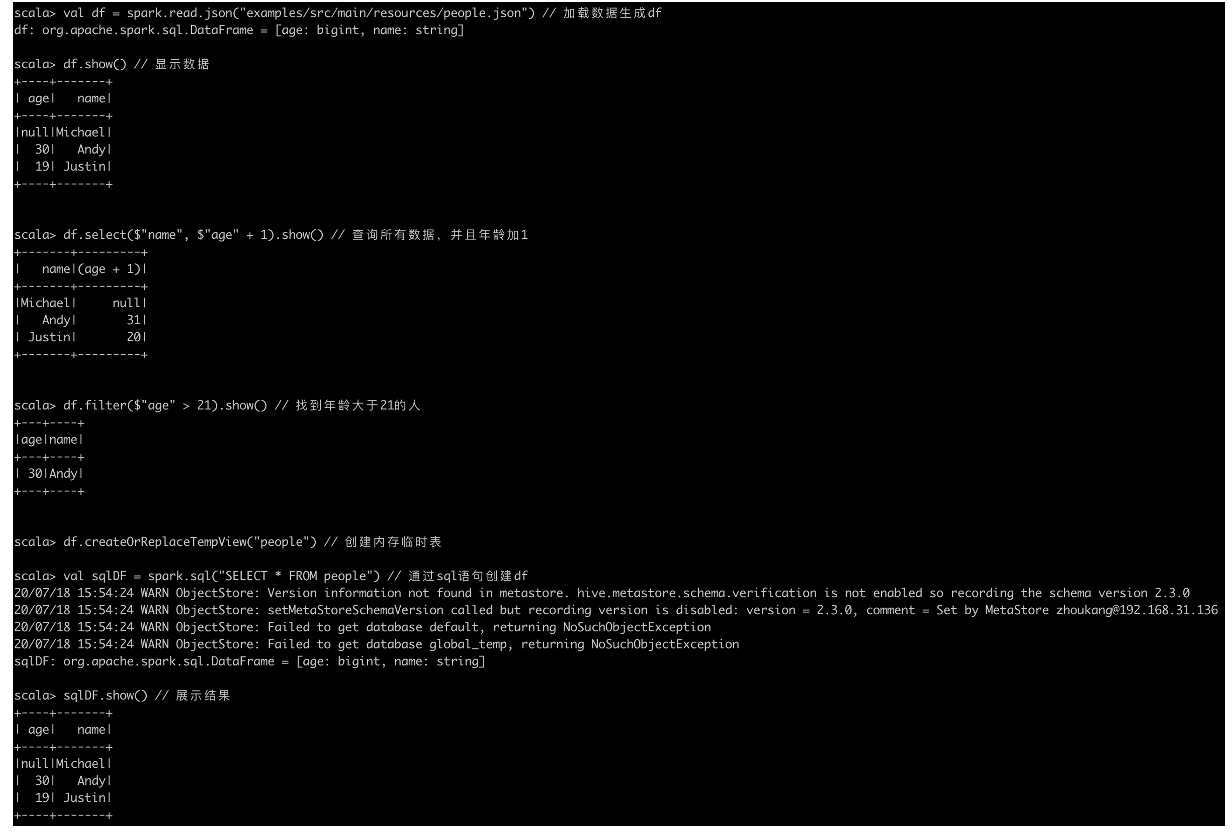
Spark Sql
DataFrames&&DataSet

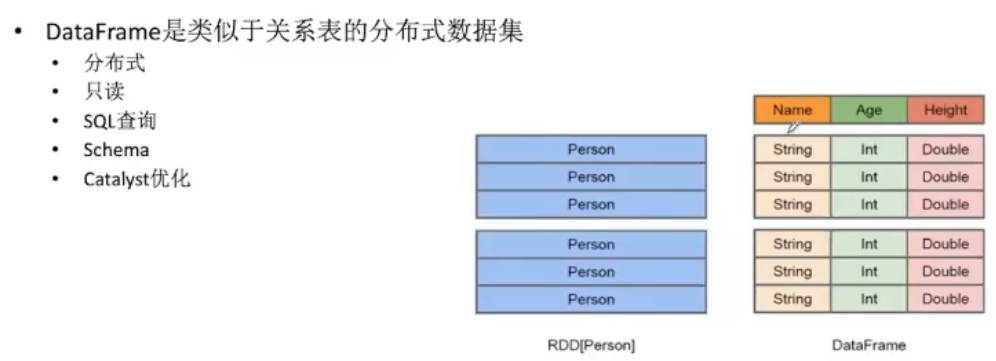
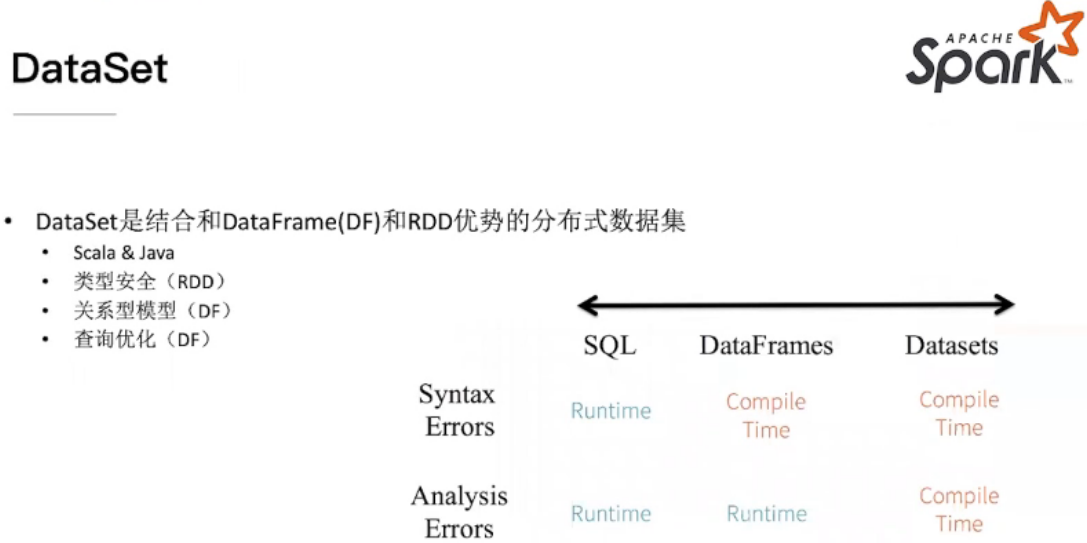
dataframes在编写时就能进行一定的错误判断,因此开发时对于datasets相对高效
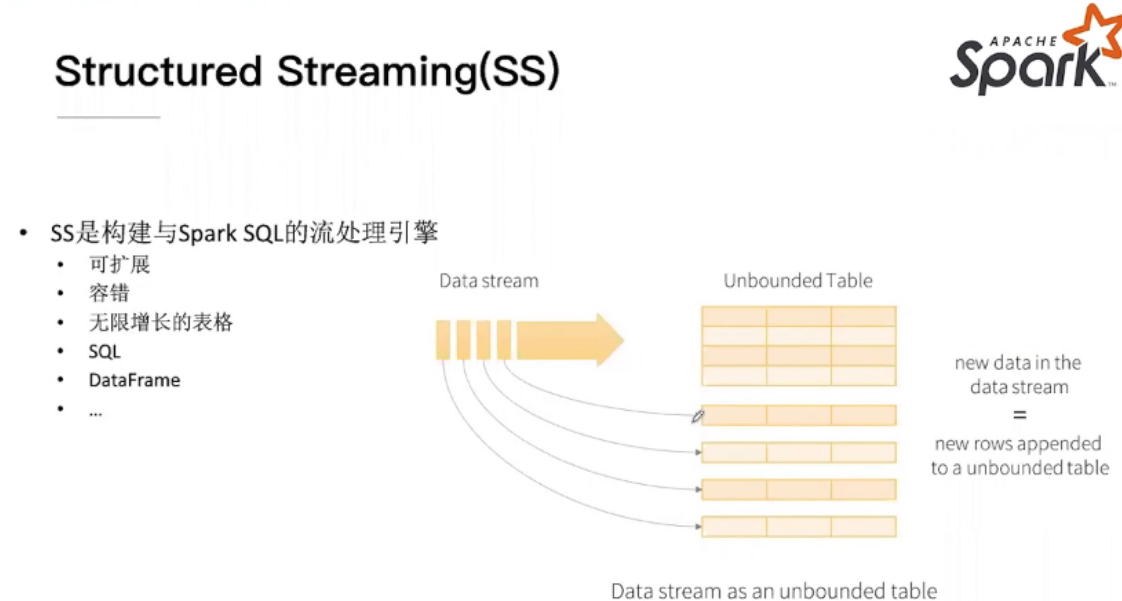
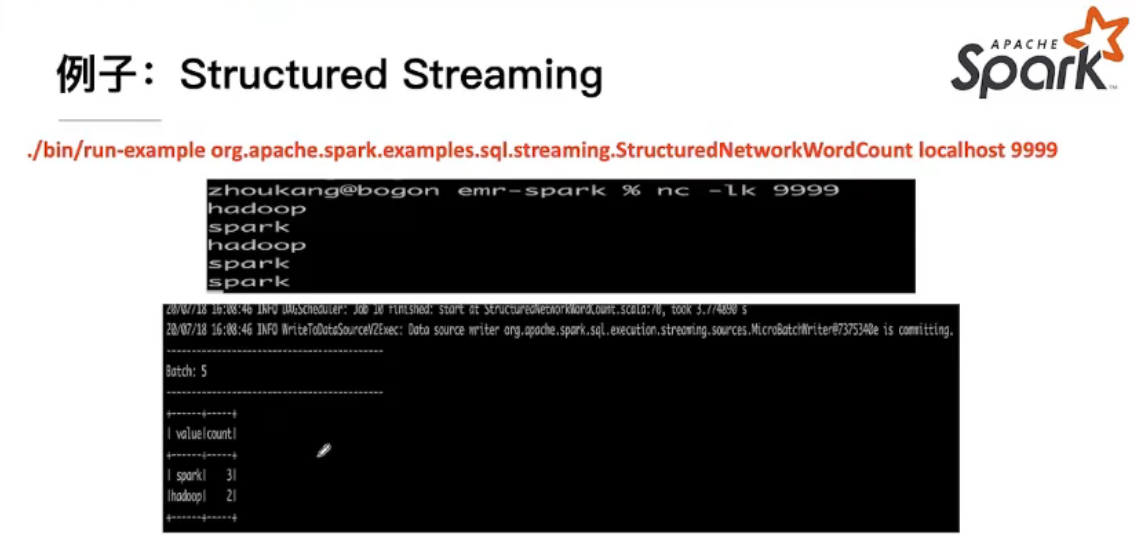
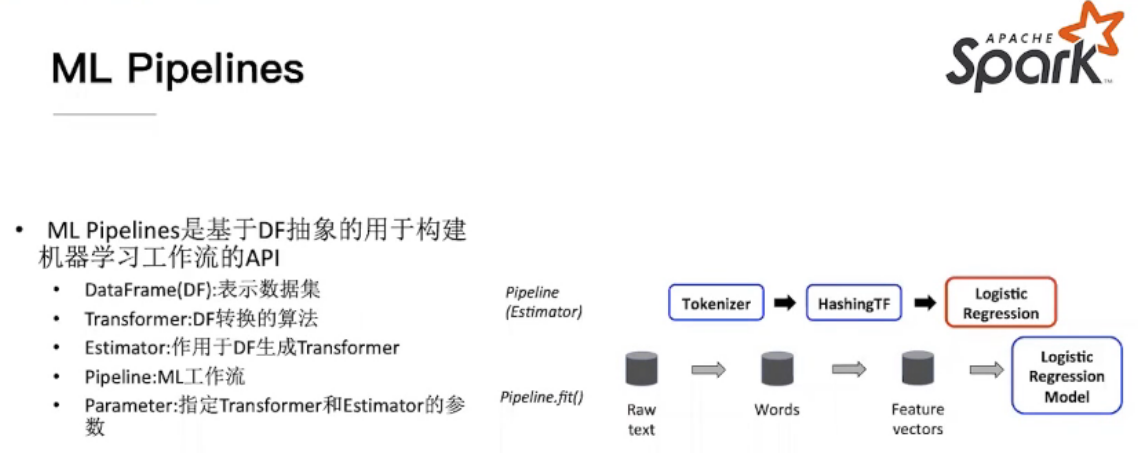
Structured Streaming && ML Pipline
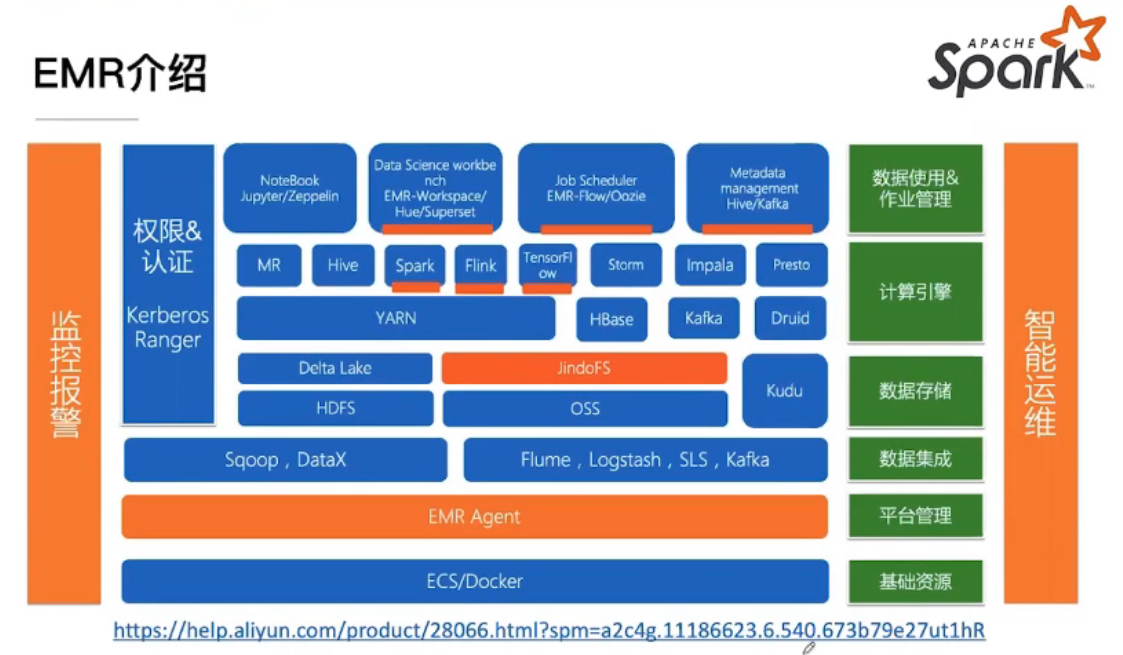
阿里云EMP架构
QA
同样的数据处理,Spark相对Hive消耗的内存比值大概是多少?
spark发展到现在版本,内存使用做了非常多的优化。所以,其实总体还好。建议能上spark就上spark。hive毕竟慢。综合下来,spark成本肯定要低的。
现在spark3.0版本的话,shuffle用的是sorted shuffle吗?
默认还是sort based
如果立马处理几亿条数据。大约能好久出结果。还是在流中慢慢处理结果感觉快?
看逻辑和资源量了。如果是离线数据,走batch模式就好了。
在sparksql里面,对计算的分区是不是更多交给spark内部去优化?
spark3.0有了ae(自适应执行)框架,会更自动化一些

 浙公网安备 33010602011771号
浙公网安备 33010602011771号