


打个结点
class Solution { public int findDuplicate(int[] nums) { if(nums == null || nums.length<=1) return -1; int fast = 0, slow = 0; while (true){ fast = nums[nums[fast]]; slow = nums[slow]; if(fast == slow){ fast = 0; while(nums[slow] != nums[fast]){ fast = nums[fast]; slow = nums[slow]; } return nums[slow]; } } } }
链表转红黑树缺点或者叫代价或者怎么转的
提了一下红黑树
什么是脏读、幻读
mvcc(不会)
算法,n+1个树字,有1个重复,输出他
联合索引
命名规则:表名_字段名
需要加索引的字段,要在where条件中
数据量少的字段不需要加索引
如果where条件中OR关系,加索引不起作用
符合最左原则(Mysql从左到右使用索引中的字段,有一个查询可以只使用索引中的一部分,但只能是最左侧部分)
两个或更多个列上的索引被称作复合索引(利用索引中的附加列,可以缩小搜索的范围,但必须要按照最左原则,可以使用索引中一部分,但只能是从左侧字段开始)。
创建复合索引时,应该仔细考虑列的顺序。
创建索引
在CREATE TABLE时可以创建索引,也可以单独用CREATE INDEX或ALTER TABLE来为表增加索引
ALTER TABLE可以用来创建普通索引、UNIQUE索引(唯一)或PRIMARYT KEY索引
ALTER TABLE table_name ADD INDEX index_name(column_list)
ALTER TABLE table_name ADD UNIQUE(column_list)
ALTER TABLE table_name ADD PRIMARY KEY(column_list)
table_name是要真就更加索引的表名,colum_list指出哪些列进行索引,多列时格列之间用逗号分隔。索引名index_name 可选,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,一次你可以再同时创建多个索引。
CREATE INDEX 可对表增加普通索引或UNIQUE索引.
CREATE INDEX index_name ON table_name (column_list)
CREATE INDEX index_name ON table_name(column_list)
UNIQUE索引与PRIMARY KEY索引
PRIMARY KEY索引仅是一个具有PRIMARY的UNIQUE索引。这镖师,一个表只能包含一个PRIMARY KEY,因为一个表只能包含一个同名索引。
删除索引
DROP INDEX index_name ON table_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
查看索引
show index from tablename;
show keys from tablename;
btree与B+tree
btree的关键字索引与记录放在一起,叶子节点没有包括全部需要查找的信息
B+tree所有的叶子节点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子节点本身依关键字的大小自小而大的顺序链接
所有的非终端节点可以看成是索引部分,结点中含有其子树根结点中最大(或最小)关键字。而B树的非终结点也包含需要查找的有效信息
有关线程安全问题
老集合:
vecor:比arraylist多了同步化机制(线程安全),但效率低。
statck:堆栈类,先进后出原则,线程安全
hashtable:比hashmap多了线程安全,效率低(修改数据时锁住整个HashTable)默认size:11,key与value不可为null。
enumeration:枚举,相当于迭代器。
Collection包装方法
List<E> synArrayList = Collections.synchronizedList(new ArrayList<E>());
Set<E> synHashSet = Collections.synchronizedSet(new HashSet<E>());
Map<K,V> synHashMap = Collections.synchronizedMap(new HashMap<K,V>());
java.util.concurrent包中的集合
ConcurrentiHashMap
ConcurrentiHashMap与HashTable都是线程安全的,它们的不同主要是加锁粒度上的不同。HashTable的家加锁方式是全局锁,给每个方法加上synchronized关键字,这样锁住整个Table对象。
ConcurrentHashMap是更细粒度的加锁,JDK1.8以前是加分段锁,Segment锁,每个Segment含有整个trable的一部分,这样不同分段之间的并发操作就互不影响。1.8取消Segment字段,直接在table元素上加锁,实现每一行进行加锁,进一步减小了并发冲突的概率。
HashMap
底层结构是底层数组+链表实现,key与value均可为null但是key不可重复。
初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
扩容针对整个Map,每次扩容是,原来数组中的元素一次重新计算存放位置,并重新插入
当Map中元素超过Entry数组的75%,触发扩容操作,为了减少链表长度,通过hash()定位,元素分配更均匀
声明一个单例
public class Singleton{ private Singleto(){}; privatie static volatile Singleton instance; public static Singleton getInstance(){ if(instance == null){ synchronized(Singleton.class){ if(instance == null){ instance = new Singleton(); } } } return instance; } }
Java源文件产生的字节码文件的扩展名为.class
.class文件在到其他系统的虚拟机上编译为当前系统可识别的java代码文件。
布尔型与整数型比较
如果数值是包装类确实可以比较的
Cloneable
Serializable
通常一个类实现序列化的方式是实现序列化接口 Seralizable
什么是序列化:把数据长久的保存在磁盘中,磁盘和内存是不同的,内存一般在程序运行时占用,数据保存周期短,随程序结束而结束,磁盘可以长久保存数据
transisent关键字的作用,在已实现序列化的类中,有的变量不需要保存在磁盘中,就要transien关键字修饰,在已经序列化的类中使变量不再序列化。
Runnable
Comparable
假如某个JAVA进程的JVM参数配置如下:
-Xms1G -Xmx2G -Xmn500M -XX:MaxPermSize=64M -XX:+UseConcMarkSweepGC -XX:SurvivorRatio=3,
请问eden区最终分配的大小是多少?
Xms 起始内存 Xmx 最大内存 Xmn 新生代内存 Xss 栈大小。 就是创建线程后,分配给每一个线程的内存大小 -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4 -XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5 -XX:MaxPermSize=n:设置持久代大小 收集器设置 -XX:+UseSerialGC:设置串行收集器 -XX:+UseParallelGC:设置并行收集器 -XX:+UseParalledlOldGC:设置并行年老代收集器 -XX:+UseConcMarkSweepGC:设置并发收集器 垃圾回收统计信息 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:filename 并行收集器设置 -XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。 -XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间 -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n) 并发收集器设置 -XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。 -XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
关于Statement
Statement 每次执行sql语句,数据库都要执行sql语句的编译 ,最好用于仅执行一次查询并返回结果的情形,效率高于PreparedStatement.
PreparedStatement是预编译的,使用PreparedStatement有几个好处
a. 在执行可变参数的一条SQL时,PreparedStatement比Statement的效率高,因为DBMS预编译一条SQL当然会比多次编译一条SQL的效率要高。
b. 安全性好,有效防止Sql注入等问题。
c. 对于多次重复执行的语句,使用PreparedStament效率会更高一点,并且在这种情况下也比较适合使用batch;
d. 代码的可读性和可维护性。
CallableStatement接口扩展 PreparedStatement,用来调用存储过程,它提供了对输出和输入/输出参数的支持。CallableStatement 接口还具有对 PreparedStatement 接口提供的输入参数的支持。
加载驱动的方法protected Object clone () //创建并返回此对象的一个副本。 boolean equals (Object obj) //指示某个其他对象是否与此对象“相等”。 protected void finalize () //当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。 Class<? extends Object> getClass () //返回一个对象的运行时类。 int hashCode () //返回该对象的哈希码值。 void notify () //唤醒在此对象监视器上等待的单个线程。 void notifyAll () //唤醒在此对象监视器上等待的所有线程。 String toString () //返回该对象的字符串表示。 void wait () //导致当前的线程等待,直到其他线程调用此对象的 notify () 方法或 notifyAll () 方法。 void wait ( long timeout) //导致当前的线程等待,直到其他线程调用此对象的 notify () 方法或 notifyAll () 方法,或者超过指定的时间量。 void wait ( long timeout, int nanos) //导致当前的线程等待,直到其他线程调用此对象的 notify () 方法或 notifyAll () 方法,或者其他某个线程中断当前线程,或者已超过某个实际时间量。
equals在String里比较的才是值,因为String重写了equals方法,原本的equals方法比较的还是对象。
子类抛出异常小于等于父类方法抛出异常,
子类访问权限大于等于父类方法访问权限。
方法重写
参数列表必须完全与被重写方法的相同;
返回类型必须完全与被重写方法的返回类型相同;
访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为public,那么在子类中重写该方法就不能声明为protected。
父类的成员方法只能被它的子类重写。
声明为final的方法不能被重写。
声明为static的方法不能被重写,但是能够被再次声明。
子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为private和final的方法。
子类和父类不在同一个包中,那么子类只能够重写父类的声明为public和protected的非final方法。
重写的方法能够抛出任何非强制异常,无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
构造方法不能被重写。
如果不能继承一个方法,则不能重写这个方法。
方法重载
被重载的方法必须改变参数列表(参数个数或类型或顺序不一样);
被重载的方法可以改变返回类型;
被重载的方法可以改变访问修饰符;
被重载的方法可以声明新的或更广的检查异常;
方法能够在同一个类中或者在一个子类中被重载。
无法以返回值类型作为重载函数的区分标准。
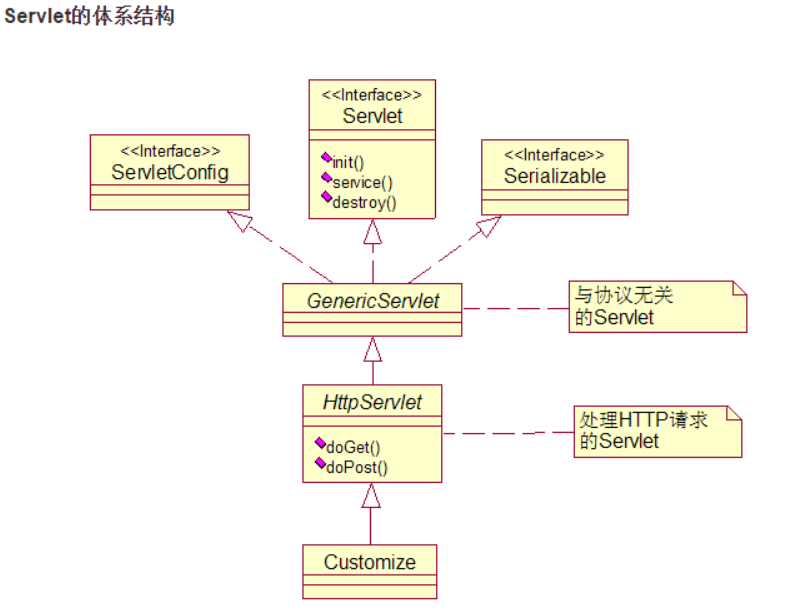
HttpServlet是GenericServlet的子类。
GenericServlet是个抽象类,必须给出子类才能实例化。它给
出了设计servlet的一些骨架,定义了servlet生命周期,还有一些得到名字、配置、初始化参数的方法,其设计的是和应用层协议无关的,也就是说 你有可能用非http协议实现它。
HttpServlet是子类,当然就具有GenericServlet的一切特性,还添加了doGet, doPost, doDelete,
doPut, doTrace等方法对应处理http协议里的命令的请求响应过程。
一般没有特殊需要,自己写的Servlet都扩展HttpServlet
Servlet生命周期
init初始化阶段:创建并加载Servlet对象、ServletConfig对象
service运行阶段:调用doGet()或者doPost(),构造ServletRequest对象与servletResponse
dostroy销毁阶段:停止Servlet,释放资源
类之间存在的关系
jre判断程序是否执行结束的标志,所有的前台线程执行完毕。
类加载是由类加载器完成的,类加载器包括:根加载器( BootStrap )、扩展加载器( Extension )、系统加载器( System )和用户自定义类加载器( java.lang.ClassLoader 的子类)。
- Bootstrap :一般用本地代码实现,负责加载 JVM 基础核心类库( rt.jar );
- Extension :从 java.ext.dirs 系统属性所指定的目录中加载类库,它的父加载器是 Bootstrap ;
- system class loader :又叫应用类加载器,其父类是 Extension 。它是应用最广泛的类加载器。它从环境变量 classpath 或者系统属性 java.class.path 所指定的目录中记载类,是用户自定义加载器的默认父加载器。
- 用户自定义类加载器: java.lang.ClassLoader 的子类
switch支持的数据类型
在Java7之前,switch只能支持 byte、short、char、int或者其对应的封装类以及Enum类型。在Java7中,也支持了String类型
String byte short int char Enum 类型
java常用包的类型
但是对于外部类而言,一个.java文件必须只能有一个public类,同时这个类的类名必须和.java的文件名一致(包括大小写)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号