本人是一个刚学spark的萌新,原理的东西没办法弄得很明白,但是希望在解决方法上能给予你们一点帮助。
udaf(UserDefinedAggregateFunction),通过继承 UserDefinedAggregateFunction 来实现用户自定义弱类型聚合函数。从 Spark3.0 版本后,UserDefinedAggregateFunction 已经不推荐使用了。可以统一采用强类型聚合函数Aggregator.
1. 使用UserDefinedAggregateFunction创建弱类型聚合函数,弱类型的聚合函数输入和输出都可以在函数中指定,属于可变化的那种
package com.phlink.bigdata.sql
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, LongType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object SparkSQL_UDAF {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession
.builder()
.appName("spark2Test")
// .config("hive.metastore.uris", "thrift://cdh1:9083,thrift://cdh2:9083,thrift://cdh3:9083")
// .config("spark.sql.warehouse.dir","/user/hive/warehouse")
.master("local[*]").getOrCreate()
//这里的spark不是包名含义,是SparkSession对象的名字
val df: DataFrame = sparkSession.read.json("datas/user.json")
df.createOrReplaceTempView("user")
sparkSession.udf.register("ageAvg",new MyAvgUDAF)
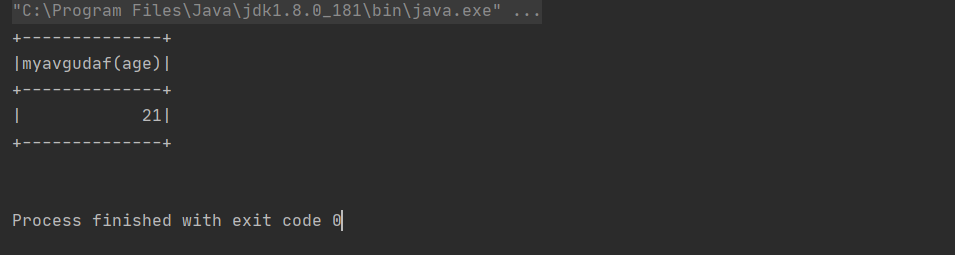
sparkSession.sql("select ageAvg(age) from user").show()
sparkSession.close()
}
class MyAvgUDAF extends UserDefinedAggregateFunction{
//输入的数据结构
override def inputSchema: StructType = {
new StructType().add("age",LongType)
}
//缓冲区
override def bufferSchema: StructType = {
StructType(StructField("sum",LongType) :: StructField("count",LongType) :: Nil)
}
//输出的数据结构
override def dataType: DataType = LongType
//函数的稳定性
override def deterministic: Boolean = true
//缓冲区初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
//根据输入的值更新缓冲区
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer.update(0,buffer.getLong(0)+input.getLong(0))
buffer.update(1,buffer.getLong(1)+1)
}
// 缓冲区合并
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0,buffer1.getLong(0)+buffer2.getLong(0))
buffer1.update(1,buffer1.getLong(1)+buffer2.getLong(1))
}
//计算逻辑
override def evaluate(buffer: Row): Any = {
buffer.getLong(0)/buffer.getLong(1)
}
}
}
2. 使用Aggregator创建强类型聚合函数,强类型的聚合函数输入和输出都在参数中设定了,属于不可变化的那种
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Dataset, Encoder, Encoders, SparkSession, TypedColumn}
object SparkSQL_UDAF_1 {
def main(args: Array[String]): Unit = {
// TODO 创建SparkSQL的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
val df = spark.read.json("datas/user.json")
val ds: Dataset[User] = df.as[User]
val udafColumn: TypedColumn[User, Long] = new MyAvgUDAF().toColumn
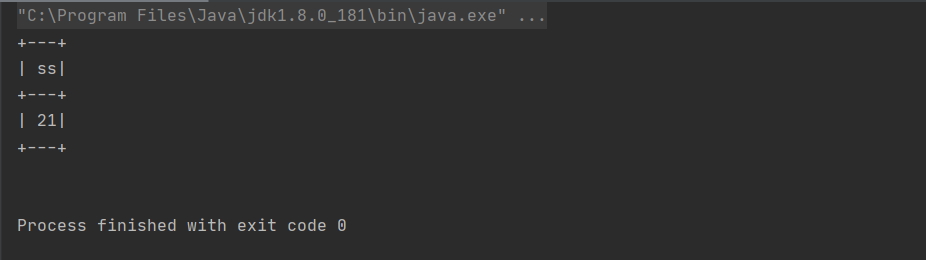
ds.select(udafColumn.name("ss")).show
// TODO 关闭环境
spark.close()
}
/*
自定义聚合函数类:计算年龄的平均值
1. 继承org.apache.spark.sql.expressions.Aggregator, 定义泛型
IN : 输入的数据类型 Long
BUF : 缓冲区的数据类型 Buff
OUT : 输出的数据类型 Long
2. 重写方法(6)
*/
case class User(username:String , age:Long)
case class Buff( var total:Long, var count:Long )
class MyAvgUDAF extends Aggregator[User, Buff, Long]{
// z & zero : 初始值或零值
// 缓冲区的初始化
override def zero: Buff = {
Buff(0L,0L)
}
// 根据输入的数据更新缓冲区的数据
override def reduce(buff: Buff, in: User): Buff = {
buff.total = buff.total + in.age
buff.count = buff.count + 1
buff
}
// 合并缓冲区
override def merge(buff1: Buff, buff2: Buff): Buff = {
buff1.total = buff1.total + buff2.total
buff1.count = buff1.count + buff2.count
buff1
}
//计算结果
override def finish(buff: Buff): Long = {
buff.total / buff.count
}
// 缓冲区的编码操作
override def bufferEncoder: Encoder[Buff] = Encoders.product
// 输出的编码操作
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号