
为了方便对多个对象进行操作,就要对对象进行储存,而另一方面,使用Array储存对象方面具有一定的弊端,而java集合就像一个容器,
可以动态地把多个对象的引用放入到容器中。
一. 集合框架的概述
1. 集合、数组都是对多个数据进行储存操作的结构,简称java容器
说明:此时的存储,主要是指内存方面的储存,不涉及到持久化的储存
2.1. 数组在储存多个数据方面的特点:
- 一旦初始化完成后,其长度就确定了
- 数组一旦定义好,其元素的类型也确定了,我们也就只能操作指定类型的数据了,比如:String[] arr; int[] arr;
2.2. 数组在存储多个数据方面的缺点:
- 一旦初始化后,长度不能随便改
- 数组中提供的方法非常有限,对于添加、删除、插入数据等操作,非常不便
- 获取数组中实际元素的个数的需求,数组中没有现成的属性或者方法可以用(如:arr.length是调用数组整个的长度,而不是元素的长度!)
- 数组存储数据的特点:有序、可重复。对于无序、不可重复的需求,不能满足
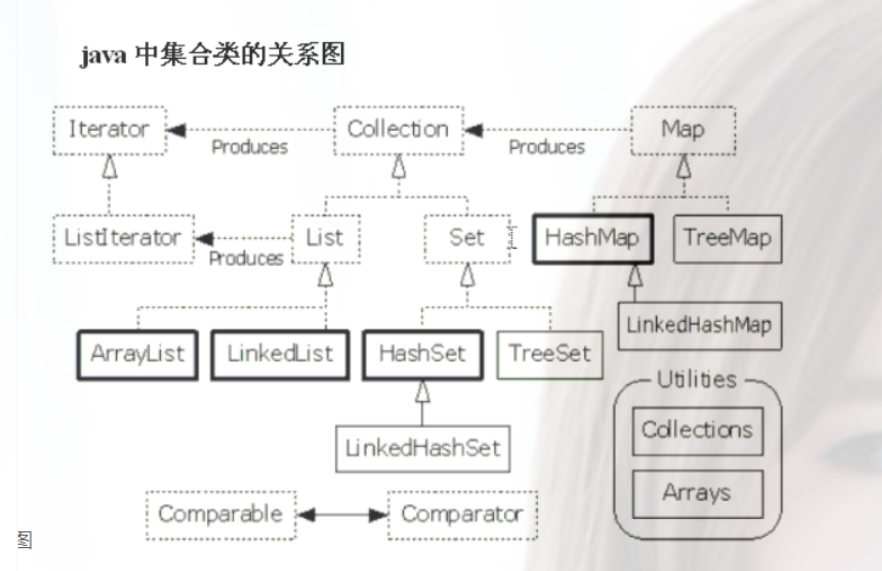
二. java集合框架概述
可分为:Collection接口和Map接口
- Collection接口:单列集合,定义了存取一组对象的方法的集合
- List接口:元素有序、可重复的集合。(动态数组——长度可以修改)
- ArrayList、LinkedList、Vector
- Set接口:元素无序、不可重复的集合。 (类似高中讲的“集合”——互异性、无序性、确定性)
- HashSet、LinkedHashSet、TreeSet
- Map接口:双列集合,保存具有映射关系的“key - value对”的集合。 (高中的函数:y = f(x),只能多对一,不能一对多,不同的key可以对应相同的value,但是相同的key不能对应多个value)
- HashMap、LinkedHashMap、TreeMap、HashTable、Properties
集合框架图:
三. Collection接口中的方法的使用(常用的API)
public void test1(){ //向Collection接口的实现类的对象中添加obj时,要求obj所在类要重写equals() Collection coll = new ArrayList(); //add(Object e):将元素添加到coll集合中 coll.add("AA"); coll.add("BB"); coll.add(123); //自动装箱 coll.add(new Date()); //size():获取添加元素的个数 System.out.println(coll.size()); //4 //addAll(Collection coll1):将coll1中的集合的元素添加到当前集合中 Collection coll1 = new ArrayList(); coll1.add(456); coll1.add("CC"); coll.addAll(coll1); System.out.println(coll1.size()); //6 //clear():清空集合元素 coll.clear(); //isEmpty():判断当前集合是否为空(是否有元素) System.out.println(coll.isEmpty()); //true //contains(Object obj):判断当前集合是否包含obj coll.add(123); coll.add(456); coll.add(false); // coll.add(new Person(23,"Tom")); coll.add(new String("Jerry")); coll.add(new Person(23,"Tom")); boolean contains = coll.contains(123); System.out.println(contains); System.out.println(coll.contains(new Person(23,"Tom"))); //这时候返回的是 true,因为重写了equals()和hashCode()方法 //containsAll(Collection coll1):判断形参coll1中的所有元素是否都存在于当前集合中 Collection coll2 = Arrays.asList(123,456); //直接在里面加 System.out.println(coll.containsAll(coll2)); //true //remove(Object obj):从当前集合中删除元素,删除成功返回true Collection coll3 = new ArrayList(); coll3.add(456); coll3.add("CC"); coll3.remove(456); //true:移出成功 //removeAll(Collection coll1):从当前集合中移出coll1中的元素 Collection coll4 = Arrays.asList(123,456); coll4.removeAll(coll3); System.out.println(coll4); //retainAll(Collection coll):获取当前集合和coll集合的交集,并返回当前集合 //equals(Object obj):必须是所有都一样,位置顺序都一样才是true } public void test2(){ Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new Person(23,"Jerry")); coll.add(new String("Tom")); coll.add(false); //hashCode():返回当前对象的哈希值 System.out.println(coll.hashCode()); //集合 ---》 数组:toArray() Object[] arr = coll.toArray(); for (int i = 0; i < arr.length; i++) { System.out.println(arr[i]); } //数组 ---》 集合:调用Arrays类的静态方法asList() List<String> list = Arrays.asList(new String[]{"AA","BB","CC"}); System.out.println(list); List<int[]> arr1 = Arrays.asList(new int[]{123,456}); System.out.println(arr1); //输出的时候认为是一个元素 System.out.println(arr1.size()); //1 List arr2 = Arrays.asList(new Integer[]{123,456});//用包装类 System.out.println(arr2); //2 //iterator():返回Iterator接口的实例,用于遍历集合元素 }
下面将iterator元素的遍历:
这个主要是用于遍历Collection集合的元素,他就是为容器而生!
1.内部的方法:hasNext() 和 next()
2.集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前
3.内部定义了remove(),可以在遍历的时候,删除集合中的元素,此方法不同于集合直接调用remove(),这是两个方法
public class IteratorTest { /** * 集合元素遍历的操作,使用迭代器Iterator接口 */ public void test(){ Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(false); coll.add(new Person(23,"Jerry")); coll.add(new String("Jerry")); Iterator iterator = coll.iterator(); //方式一: System.out.println(iterator.next()); System.out.println(iterator.next()); System.out.println(iterator.next()); System.out.println(iterator.next()); System.out.println(iterator.next()); //System.out.println(iterator.next()); 越界了 //方式二:也不用 for (int i = 0; i < coll.size(); i++) { System.out.println(iterator.next()); } //方式三(推荐): while (iterator.hasNext()){ System.out.println(iterator.next()); } } }
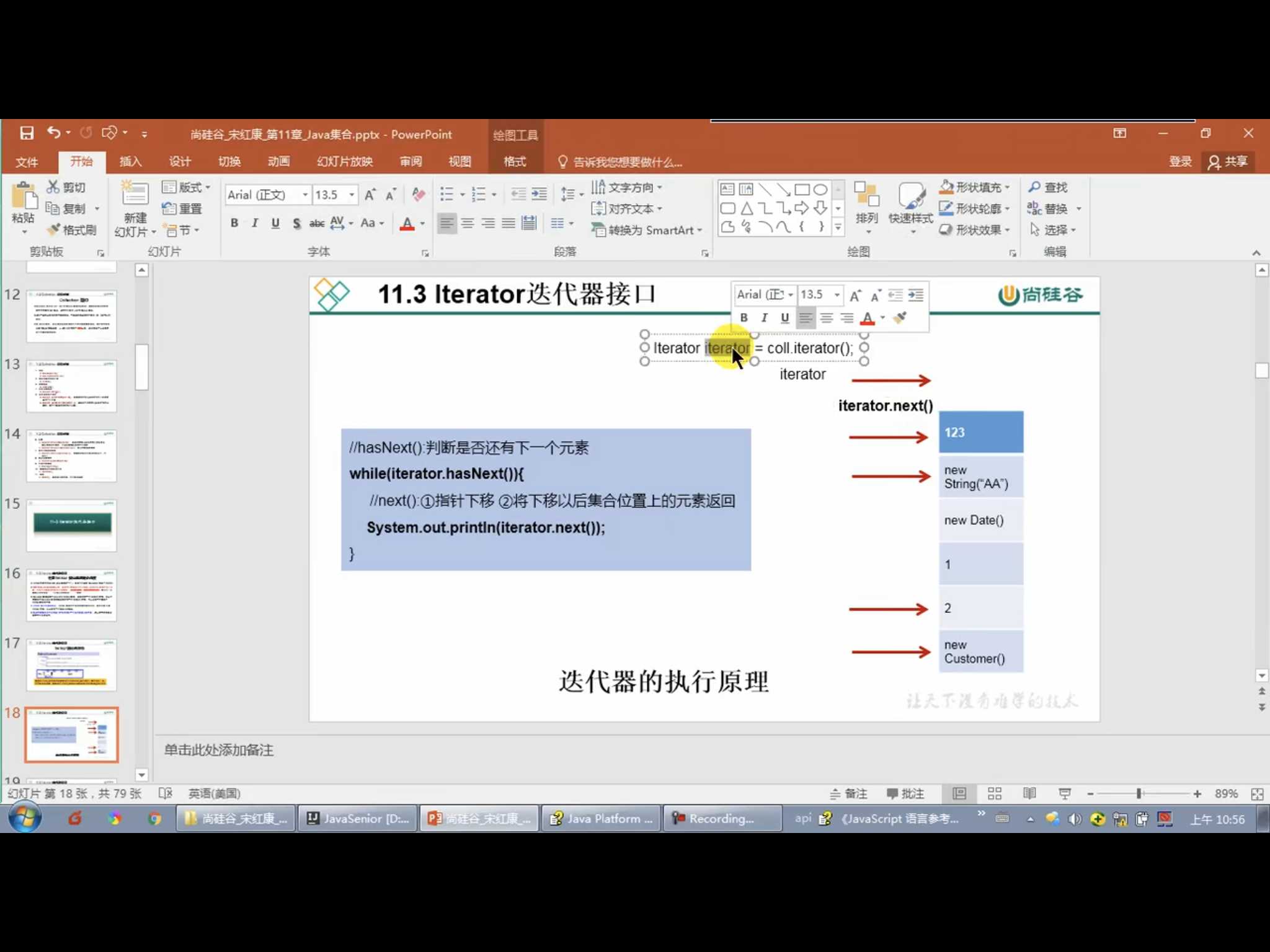
错误的写法:
//错误的方式一!!! while ((iterator.next()) != null){ System.out.println(iterator.next()); } //输出的时候会跳着输出!隔一个输出一个 //错误的方式二!!! while (coll.iterator().hasNext()){ System.out.println(coll.iterator().next()); } //输出的时候是死循环,不断地输出第一个值! //每次coll调用iterator()方法,都会新建一个iterator指针!!
//测试Iterator中的remove() //如果还未调用next()或者在上一次调用next方法之后已经调用了remove方法 //再调用remove都会报IllegalStateException public void test2(){ Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(false); coll.add(new Person(23,"Jerry")); coll.add(new String("Jerry")); //删除“Tom” Iterator iterator = coll.iterator(); while (iterator.hasNext()){ Object obj = iterator.next(); if ("Tom".equals(obj)){ iterator.remove(); } } //遍历集合 iterator = coll.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } }
foreach遍历:
public void test3(){ Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(false); coll.add(new Person(23,"Jerry")); coll.add(new String("Jerry")); //for(集合元素的类型 局部变量 :集合对象)
//内部调用的依然是迭代器
for (Object obj : coll){ //自动取出coll中的元素 System.out.println(obj); } }
还可遍历数组:
public void test4(){ int[] arr = new int[]{1,2,3}; for (int i : arr){ System.out.println(i); } }
练习题:
public void test5(){ String[] arr = new String[]{"MM","MM"}; // 方式一:普通for循环 // for (int i = 0; i < arr.length; i++) { // arr[i] = "GG"; // }
//{“GG”,“GG”} //方式二:增强for循环 for (String s : arr){ s = "GG"; } //{"MM","MM"},这只是创建了一个新的String[] for (int i = 0; i < arr.length; i++) { System.out.println(arr[i]); } }
四. List接口
/** * 1.List接口框架 * List接口:储存有序的、可重复的数据。 --》 “动态数组”,替换原有的数组 * ArrayList:作为List接口的主要实现类;线程不安全的,效率高;底层使用Object[] elementData储存 * LinkedList:对于频繁地插入和删除操作,使用此类效率比ArrayList高;底层使用双向链表储存 * Vector:作为List接口的古老实现类;线程安全的,效率低;底层使用Object[]储存 elementData储存 * * * 2.ArrayList的源码分析: * 2.1.jdk 7 * ArrayList list = new ArrayList(); //底层创建了长度为10的Object[] 数组elementData * list.add(123); //elementAdta[0] = new Integer(123); * ... * list.add(11); //如果此次的添加导致底层elementData数组容量不够,则扩容 * 默认情况下,扩容为原来容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中 * * 结论:建议开发中使用带参的构造器:ArrayList list = new ArrayList(int capacity) * * 2.2.jdk 8 * ArrayList list = new ArrayList(); //底层没有创建了长度为10的Object[] * * list.add(123); //第一次调用add()时,底层才创建了长度为10的数组,并将123添加到elementData * ... * 后续和jdk 7一样 * * 2.3.小结:jdk 7 中的ArrayList的对象的创建类似于单例的饿汉式,而jdk 8 中的ArrayList对象的创建类似于 * 单例的饿汉式,延迟了数组的创建,节省了内存 * * 3.LinkedList的源码分析: * LinkedList list = new LinkedList(); //内部声明了Node类型的first和last属性,默认值为null * list.add(123); //将123封装到Node中,创建了Node对象 * * 4.Vector * 略... * * * 面试题:以上三者的异同? * 同:三个类都实现了List接口,储存数据的特点相同:储存有序的、可重复的数据 * 不同:见上 * */
Collection中有的方法List都能用,当然还有多出来的:
public void test1(){ ArrayList list = new ArrayList(); list.add(123); list.add(456); list.add("AA"); list.add(new Person(23,"Tom")); list.add(456); System.out.println(list); //void add(int index, Object ele):在index位置插入ele元素 list.add(1,"BB"); System.out.println(list); //boolean addAll(int index, Collection eles):从index位置开始将eles中的元素添加 List list1 = Arrays.asList(1,2,3); list.addAll(list1); System.out.println(list.size()); //Object get(int index):获取指定index位置的元素 System.out.println(list.get(0)); } public void test2(){ ArrayList list = new ArrayList(); list.add(123); list.add(456); list.add("AA"); list.add(new Person(23,"Tom")); list.add(456); //int indexOf(Object obj):返回obj在集合中首次出现的位置,如果不存在,返回-1 int index = list.indexOf(456); System.out.println(index); //如果有,返回当前位置 //没有,返回 -1 //int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置,如果不存在,返回-1 System.out.println(list.lastIndexOf(456)); //Object remove(int index):删除第index的元素,并返回此元素 Object obj = list.remove(0); System.out.println(obj); System.out.println(list); //Object set(int index, Object ele):设定指定index位置的元素ele list.set(1,"CC"); System.out.println(list); //List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的左闭右开区间 List subList = list.subList(2,4); System.out.println(subList); System.out.println(list); //本身不会对原数组产生影响 }
总结:常用的方法:
增:add(Object obj)
删:remove(int index) / remove(Object obj) --> 这个是Collection中定义的
改: set(int index, Object ele)
查:get(int index)
插:add(int index,Object ele)
长度:size()
遍历:1.Iterator迭代器方式 2.增强for循环方式 3.普通的循环
遍历:
public void test3(){ ArrayList list = new ArrayList(); list.add(123); list.add(456); list.add("AA"); //方式一:迭代器方式 Iterator iterator = list.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } //方式二:增强for循环 for (Object obj : list){ System.out.println(obj); } //方式三:普通的for训话 for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); }
练习题:
public class Good { public void testListRemove(){ List list = new ArrayList(); list.add(1); list.add(2); list.add(3); updateTest(list); //这时候调用的话,是删除索引位置为 2 的数据,因为要删除数据“2”,还要装箱拆箱! System.out.println(list); } public void updateTest(List list){ list.remove(2); } }
如果想要删除数据“2”,怎么办?
public void updateTest(List list){ // list.remove(2); list.remove(new Integer(2)); }
核心:区分List中remove(int index)和remove(Object obj),要清楚想要删除什么!
(关于ArrayList的多态参数和泛型)
如果创建Animal抽象类,下面有Cat类和Dog类继承Animal类
abstract class Animal{ void eat(){ System.out.println("animal eating"); } } class Dog extends Animal{ void eat(){ System.out.println("eat shit"); } } class Cat extends Animal{ void eat(){ System.out.println("eat fish"); }
很容易我们可以知道:
public void go1(){ ArrayList<Animal> animals = new ArrayList<Animal>(); animals.add(new Dog()); animals.add(new Cat()); animals.add(new Dog()); takeAnimals(animals); } public void takeAnimals(ArrayList<Animal> animals){ for (Animal a : animals){ a.eat(); } }
可以得到:
eat shit
eat fish
eat shit
这是没问题的
但是如果是ArrayList<Dog>呢?
public void go2(){ ArrayList<Dog> dogs = new ArrayList<Dog>(); dogs.add(new Dog()); dogs.add(new Dog()); takeAnimals(dogs); //编译报错! } public void takeAnimals(ArrayList<Animal> animals){ for (Animal a : animals){ a.eat(); } }
java: 不兼容的类型: java.util.ArrayList<SetTest.Dog>无法转换为java.util.ArrayList<SetTest.Animal>
为什么?这看上去都非常正常啊!
其实不是,因为
public void takeAnimals(ArrayList<Animal> animals){ for (Animal a : animals){ a.eat(); } }
只能传入Animal类型的ArrayList,不能传入Dog或者Cat
否则如果这样写:
public void takeAnimals(ArrayList<Animal> animals){ animals.add(new Cat()); }
那么就成功加入了一个猫进了狗组!
ArrayList的本意是可以将任何的Animal传入到其中,但是!!!
如果这样的话,就应该将ArrayList定义成这样:ArrayList<Animal>,而不是ArrayList<Dog>!
因为如果你这样声明了ArrayList<Dog>,那么就默认你不想让除了Dog以外的任何类进这个ArrayList中!
如果你想要将你的ArrayList变得丰富多彩,你应该在定义的时候就定义为ArrayList<Animal>,
这样你就能成功地将猫猫狗狗放进这个组里。
(注意:ArrayList可以储存子类是因为源码中定义了可以储存。菱形括号中写的表示只能存这个类!)
这里和普通的数组要区分开来!
普通的数组:
public class NormalList { public static void main(String[] args) { new NormalList().go(); } public void go(){ Animals[] animals = {new Dogs(),new Cats(),new Dogs()}; Dogs[] dogs = {new Dogs(),new Dogs(),new Dogs()}; takeAnimals(dogs); takeAnimals(animals);
//这里可以调用!!! } public void takeAnimals(Animals[] animals){ for (Animals a : animals){ a.eat(); } } } abstract class Animals{ void eat(){ System.out.println("animal eating"); } } class Dogs extends Animals{ void eat(){ System.out.println("eat shit"); } } class Cats extends Animals { void eat() { System.out.println("eat fish"); } }
如果你对普通数组进行这样的操作:
public void go(){ Dogs[] dogs = {new Dogs(),new Dogs(),new Dogs()}; takeAnimals(dogs); } public void takeAnimals(Animals[] animals){ animals[0] = new Cats(); }
即在dog的数组里通过方法加入cat,这时候编译不会出问题
但是运行期间就会出问题:
Exception in thread "main" java.lang.ArrayStoreException: SetTest.Cats at SetTest.NormalList.takeAnimals(NormalList.java:14) at SetTest.NormalList.go(NormalList.java:10) at SetTest.NormalList.main(NormalList.java:5)
得出结论:
数组的类型检查是在运行期间检查的,但是集合的类型检查在编译期间就可以完成!
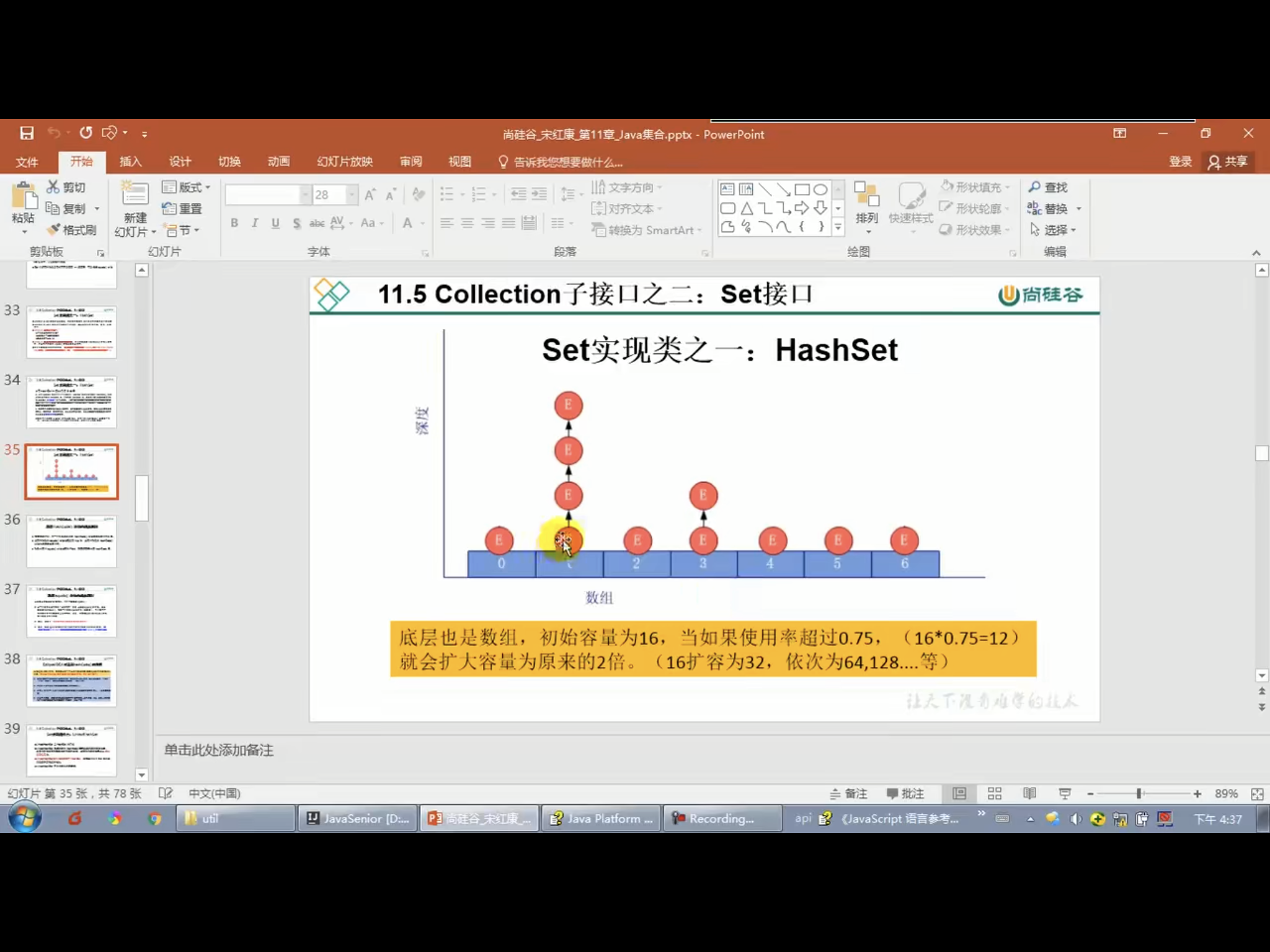
五.Set接口
package SetTest; import java.util.HashSet; import java.util.Iterator; import java.util.LinkedHashSet; import java.util.Set; public class SetTest1 { /** * Collection接口:单列集合,用来储存一个一个的对象 * Set接口:储存无序的、不可重复的数据——“集合” * HashSet:作为Set接口的主要实现类;线程不安全的;可以储存null值 * LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历 * 对于频繁的遍历操作,LinkedHashSet的效率高于HashSet * TreeSet:可以按照添加对象的指定属性,进行排序 * * 1.Set接口总没有额外定义的新方法,使用的都是Collection中的方法 * * 2.要求:向Set中添加的数据,其所在的类一定要重写hashCode()和equals(),以实现对象相等规则,即相等的对象一定要有相同的散列码 * 重写hashCode()方法的基本原则: * - 在程序运行时,同一个对象多次调用hashCode()方法应该返回相同的值 * - 当两个对象的equals()方法比较返回true时,这两个对象的hashCode()方法返回的值也相同 * - 对象中用作equals()方法比较的Field,都应该用来计算hashCode值 * */ /** * * 一. Set:存储无序的、不可重复的数据 * 以HashSet为例 * 1.无序性:不等于随机性,重复运行完后每次都是一个顺序。 * 存放的话,底层还是数组,每次存放都是放在数组的一个位置上,但是不是按照数组的索引的顺序添加 * 而是根据数据的哈希值来添加 * * 2.不可重复性:保证添加的元素按照equals()判断时,不能返回true,即:相同的元素只能添加一个 * * * 二. 添加元素的过程:以HashSet为例: * (如果按照常规方法,想要放进去的数是前面没有的,那么就要一个一个比对,非常麻烦!) * 我们向HashSet中添加a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,此哈希值 * 接着通过某种算法计算出在HashSet底层数组中的存放位置(即:索引位置),判断数组此位置上是否 * 已经有元素: * 如果此位置上没有其他元素,则a添加成功 * 如果此位置上有其他元素b(或以链表的形式存在的多个元素),则比较元素a与元素b的hash值: * 如果hash值不相同,则元素a添加成功 * 如果hash值相同,进而需要调用元素a所在类的equals()方法: * equals()返回true,元素a添加失败 * equals()返回false,则元素a添加成功 */ public void test1(){ Set set = new HashSet(); set.add(456); set.add(123); //set.add(123);不会加进去 set.add("AA"); set.add("CC"); set.add(129); set.add(new User("Tom",23)); set.add(new User("Tom",23)); //这时候会有两个!为什么? //因为没有重写equals() //现在重写equals(),现在还是出现两个 //现在再重写hashCode(),现在是一个了 Iterator iterator = set.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } } //LinkedHashSet的使用 //LinkedHashSet作为HashSet的子类,在添加数据的同时,每个数据还维护了两个引用 //记录此数据前一个数据和后一个数据 //目的也是优点是:对于频繁的遍历操作,LinkedHashSet的效率高于HashSet public void test2(){ Set set = new LinkedHashSet(); set.add(456); set.add(123); set.add(123); set.add("AA"); set.add("CC"); set.add(129); set.add(new User("Tom",23)); set.add(new User("Tom",23)); Iterator iterator = set.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } } }
package SetTest; import java.util.Comparator; import java.util.Iterator; import java.util.TreeSet; public class TreeSetTest { /** * 1.向TreeSet中添加的数据,要求是相同类的对象。 * <p> * 2.两种排序方式: * - 自然排序(实现Comparable接口) * - 定制排序 * <p> * 3.自然排序中,比较两个对象是否相同的标准为:compareTo()返回0,不再是equals(). * <p> * 4.定制排序中,比较两个对象是否相同的标准为:compare()返回0,不再是equals(). */ public static void main(String[] args) { TreeSetTest t = new TreeSetTest(); t.test1(); } public void test1() { TreeSet set = new TreeSet(); //失败!不能添加不同类的对象 // set.add(123); // set.add(456); // set.add("AA"); // set.add(new User("Tom",23)); //举例一: //相同的类型:OK! set.add(34); set.add(-34); set.add(43); set.add(11); set.add(8); //举例二: //String类型 //举例三: set.add(new User("Tom", 23)); set.add(new User("Jack", 223)); set.add(new User("Fuck", 232)); set.add(new User("Suck", 323)); set.add(new User("Jack", 56)); //如果添加一个新元素,名字一样,但是年龄不一样,能加吗? //按照重写的compareTo()方法,可以达到加进去 Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } //遍历的顺序是从小到大排序! } public void test2() { Comparator com = new Comparator() { //按照年龄从小到大排列 @Override public int compare(Object o1, Object o2) { if (o1 instanceof User && o2 instanceof User){ User u1 = (User)o1; User u2 = (User)o2; return Integer.compare(u1.getAge(),u2.getAge()); }else { throw new RuntimeException("输入的数据类型不匹配"); } } }; TreeSet set = new TreeSet(com); set.add(new User("Tom", 23)); set.add(new User("Jack", 223)); set.add(new User("Fuck", 232)); set.add(new User("Suck", 323)); set.add(new User("Jack", 56)); Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } } }
package SetTest; import java.util.Objects; public class User implements Comparable{ private String name; private int age; public User(){ } public User(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "User{" + "name='" + name + '\'' + ", age=" + age + '}'; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; User user = (User) o; return age == user.age && Objects.equals(name, user.name); } @Override public int hashCode() { return Objects.hash(name, age); } //按照姓名从小到大排序 @Override public int compareTo(Object o) { if (o instanceof User) { User user = (User) o; // return this.name.compareTo(user.name); int compara = -this.name.compareTo(user.name); if (compara != 0){ return compara; }else{ return Integer.compare(this.age,user.age); } }else { throw new RuntimeException("输入的类型不匹配"); } } }
六. Map接口
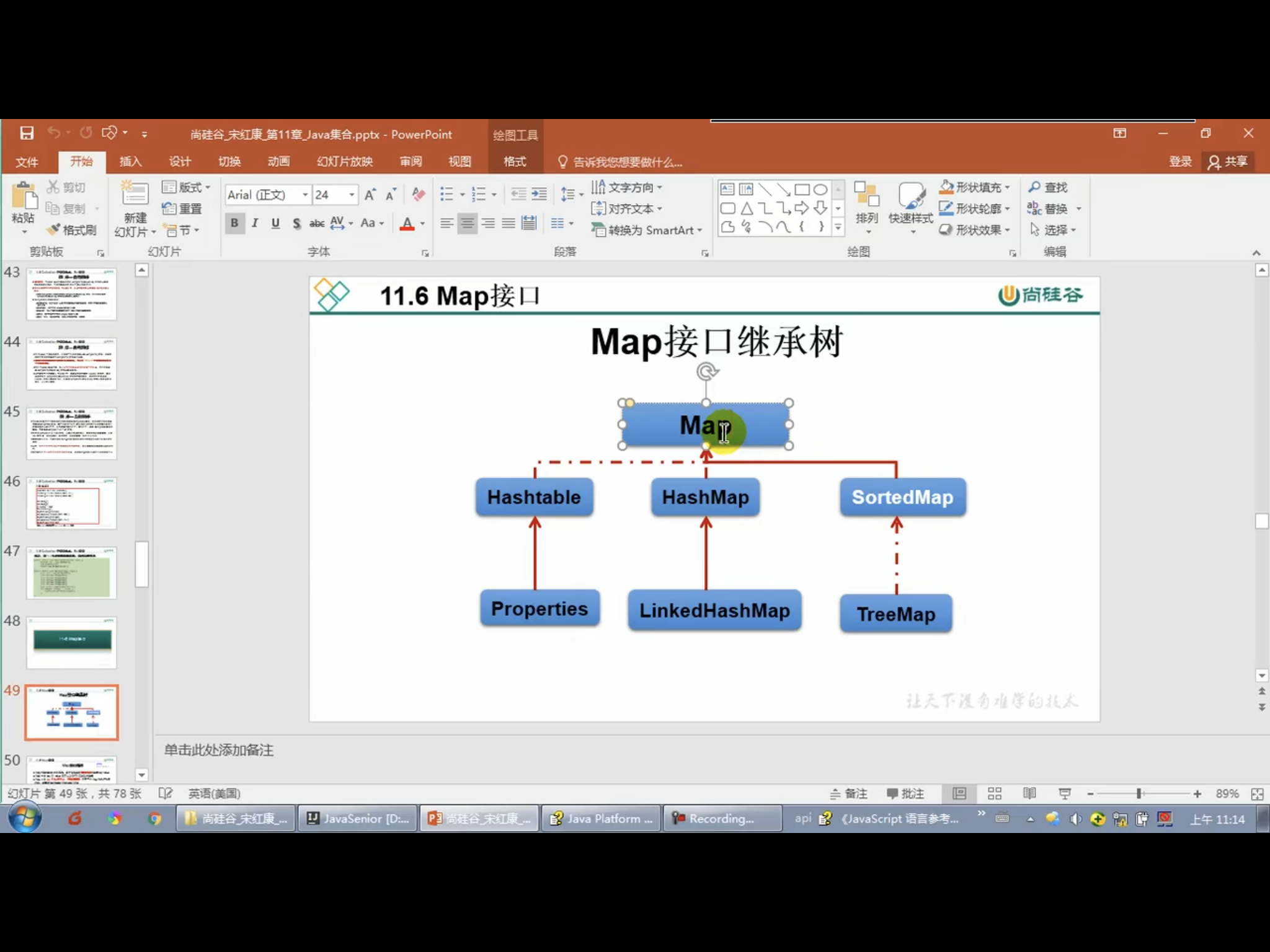
只能多对一,不能一对多
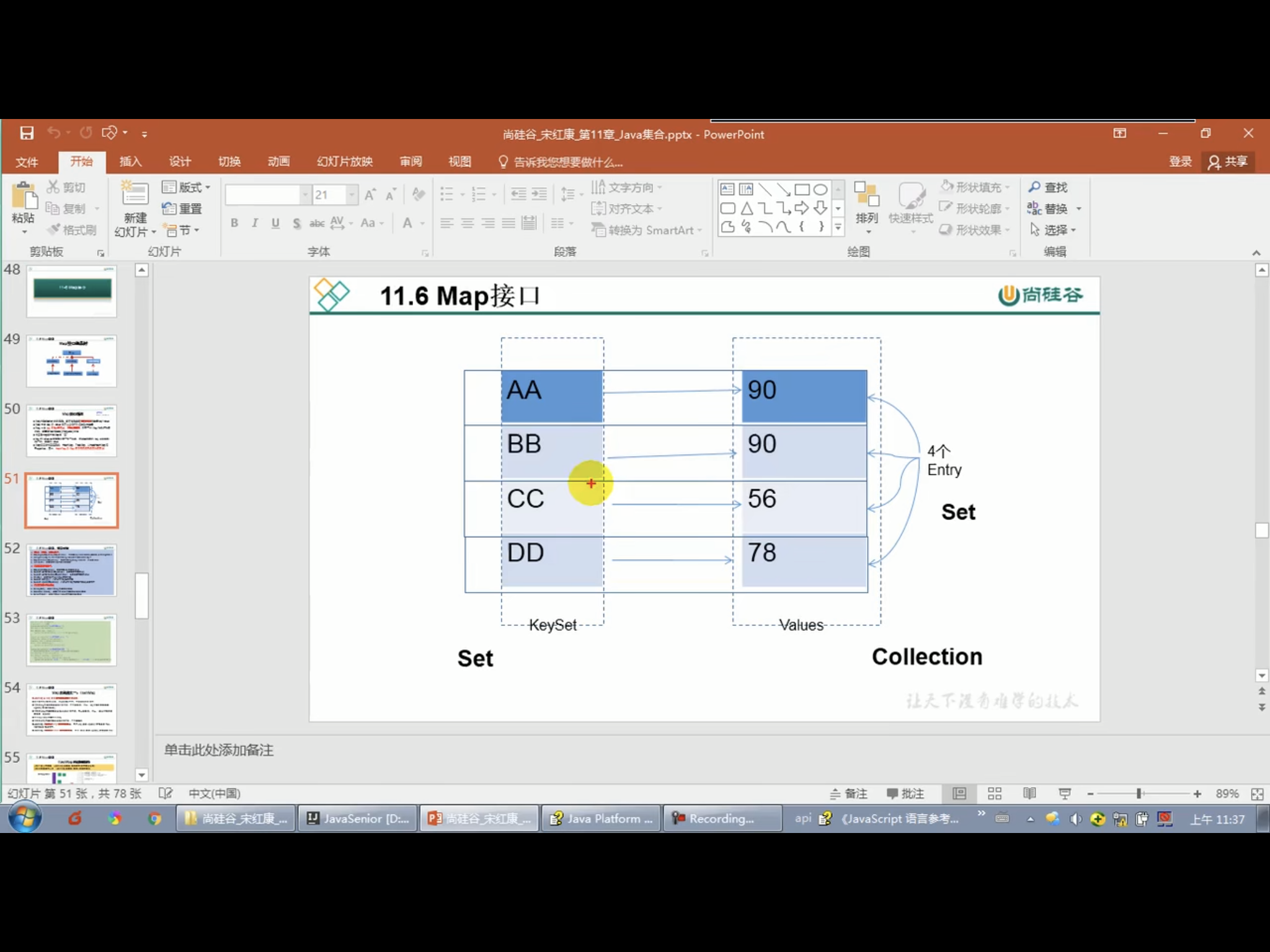
package MapTest; import java.util.HashMap; import java.util.Map; /** * 一. Map的实现类 * Map:双列数据,储存key - value对的数据 * HashMap:作为Map的主要实现类,线程不安全,效率高;可以存储null的key或者value * LinkedHashMap:在原有的基础上,加了一对指针,保证在遍历map元素时,可以按照添加的顺序实现遍历 * 这一对指针,指向前一个和后一个元素 * 对于频繁地遍历,LinkedHashMap效率要更高 * TreeMap:保证按照添加的key - value对进行排序,实现排序遍历。此时考虑key的自然排序或定制排序 * 底层使用红黑树 * HashTable:作为古老的实现类,线程安全,效率低;不能存储null的key或者value * Properties:常用来处理配置文件。key和value都是String类型 * * HashMap的底层:数组 + 链表 * 数组 + 链表 + 红黑树 (jdk 8) * * * * * 面试题: * 1. HashMap的底层实现原理? * 2. HashMap和HashTable的异同? * 3. CurrentHashMap和HashTable的异同?(暂时不讲) * * * *二. Map结构的理解 * Map中的key:无序的、不可重复的,使用Set储存所有的key ---》 key所在的类要重写equals()和hashCode() (以HashMap为例说明) * Map中的value:无序的、可重复的,使用Collection储存所有的value ---》 value所在的类重写equals() * 一个键值对:key - value构成了一个Entry对象 * Map中的entry:无序的、不可重复的,使用Set储存所有的entry * * *三. HashMap的底层实现原理(以jdk 7 为例) * HashMap map = new HashMap(); * 在实例化以后,底层创建了长度为16的一维数组Entry[] table。 * ...可能已经执行过多次put... * map.put(key1,value1): * 首先,调用key1所在类的hashCode()计算key1的哈希值,次哈希值经过某种算法计算后,得到Entry数组中的存放位置 * 如果此位置上的数据为空,此时的key - value1添加成功 ---情况一 * 如果此位置上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在)),比较当前key1和已经存在的一个或多个数据的哈希值: * 如果key1的哈希值与已经存在的数据的哈希值都不相同,此时的key1 - value1添加成功 ---情况二 * 如果key1的哈希值和已经存在的某一个数据(key1 - value1)的哈希值相同,继续比较:调用key1所在类的equals()方法,比较: * 如果equals()返回false:此时的key1 - value1添加成功 ---情况三 * 如果equals()返回true:使用value1替换相同key的value值 * * 补充:关于情况二和情况三:此时的key1 - value1和原来的数据以链表的方式存储 * * 在不断地添加中,会涉及到扩容问题,默认的扩容方式:扩容为原来容量的2倍,并将以前所有数据拷贝 * * jdk 8 相较于 7 来说,底层实现原理的不同: * 1. new HashMap():底层没有创建一个长度为16的数组 * 2. jdk 8 的底层的数组是:Node[],而非Entry[] * 3. 首次调用put()方法时,底层创建长度为16的数组 * 4. jdk 7 底层结构只有:数组 + 链表。jdk 8 中则是:数组 + 链表 + 红黑树 * 当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组长度 > 64时, * 此时索引位置上的所有数据改用红黑树存储 * */ public class MapTest { public static void main(String[] args) { MapTest m = new MapTest(); m.test1(); } public void test1(){ Map map = new HashMap(); // map = new Hashtable(); map.put(null,null); } }
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号