[Python学习]利用selenuim爬取漫画网站
注意事项
- 版本
Python版本为 Python-3.8.3
系统为 Windows10
浏览器为 Firefox-77.0
- 前置
- \(selenium\)
- \(BeautifulSoup4\)
- \(requests\)
以上前置都可以使用Python自带的pip进行安装
- 代码说明
文中除结尾出现的完整代码都为不完全代码,不能单独使用
因各网站有所不同,本文代码仅适用于单个特定网站
#0.0 引入
本人也是一位老二次元了,常常会在各种网站上浏览漫画,遇到自己喜欢的漫画就会想将其存下来,但大部分漫画大部分都有几十上百章,所以,手存是不可能的,这辈子都不可能的!
由于漫画网站加载多为js动态加载,一般的静态爬取方式无法完成,故需要使用\(selenuim\)
本次爬取的网站:OH漫画
本次爬取的漫画为:关于我转生成为史莱姆这档事
#1.0 获取章节地址
因为目录页为静态网页,所以我们首先使用\(requests\)获取网页源码
base_url = 'https://www.ohmanhua.com/14339'
html = requests.get(base_url)
然后做一碗美味汤
soup = BeautifulSoup(html.content,'lxml')
bs4(BeautifulSoup4) 是一个很好的工具,可以将获取到的网页源码转换成树的形式储存,并且可以快速定位、获取到很多信息,有关bs4入门的博客本人日后会进行补充
观察网页源码可以发现,所有章节链接都储存在class为fed-padding fed-col-xs6 fed-col-md3 fed-col-lg3的li标签中,漫画名称储存在class为fed-part-eone fed-font-xvi的h1标签中,故可以用bs4进行获取
liTags = soup.find_all('li',attrs={'class':'fed-padding fed-col-xs6 fed-col-md3 fed-col-lg3'})
name_a = (soup.find('h1',attrs={'class':'fed-part-eone fed-font-xvi'})).get_text()
bs4 中,
find_all()是寻找所有满足条件的标签并形成一个列表,而find()是获取寻找到的第一个满足条件的标签
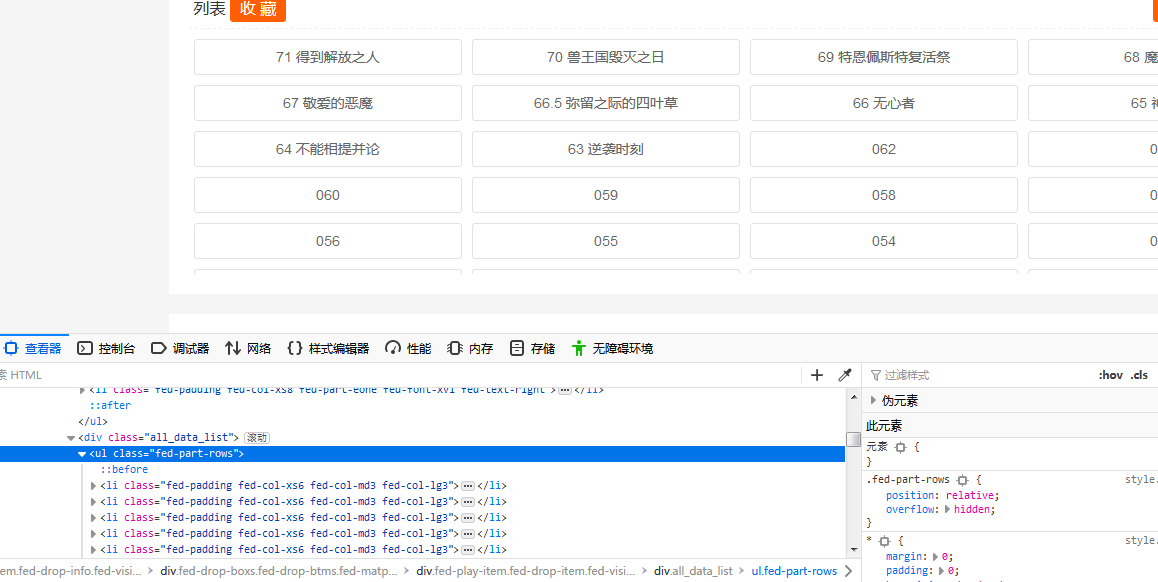
再次观察网页源码,发现所有的章节地址,都是该漫画网站主页地址加上刚才获取到的li标签下class为fed-btns-info fed-rims-info fed-part-eone的a标签的href中

因而,我们可以得到
i = 0
for li in liTags:
url_list.append("https://www.ohmanhua.com" + \
li.find('a',attrs={'class':'fed-btns-info fed-rims-info fed-part-eone'})['href'])
i = i + 1;
到这里,我们各章节网址获取就结束了,下一步要使用\(selenuim\)进行图片获取
#2.0 获取章节页数及名称进行图片获取
此时网页就成为了js加载的动态页面,所以要使用\(selenuim\)
Selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。
Selenuim 的安装与入门本人日后会专门写博客进行讨论
#2.1 获取章节页数及名称
我们先用selenium打开浏览器
browser = webdriver.Firefox()
browser.get(url)
browser.implicitly_wait(3)
本人使用的是 Firefox - 77.0,所以需要安装 geckodriver,如是chrome,因使用相应版本的 chromedriver(chrome更新较为频繁,相应driver也需更新,而Firefox则不用,所以本人在此并不建议使用chrome),读者可以自行搜索自己浏览器对应版本及相应安装方式
虽然网页是使用js加载的动态页面,但仍旧有静态加载的部分,我们可以发现,章节名称及页码的部分都属于静态加载的部分
我们先获取网页源码并做一份美味汤
html_each = requests.get(url)
soup = BeautifulSoup(html_each.content,'lxml')
观察网页源码发现,该章的页数等于option标签出现的次数减6除以2,所以可得
pageNum = (len(browser.find_elements_by_tag_name('option')) - 6) / 2
pageNum = int(pageNum) #由于进行了除法运算,会自动储存为浮点数,而在下方的循环中必须使用整数
观察网页源码发现,该章的名称位于class为mh_readtitle的div标签包裹的strong标签下,所以可得
name_div = soup.find('div',attrs={'class':'mh_readtitle'})
name = (name_div.find('strong')).get_text()
我们发现,应为该网页编写问题,想要直接从网页上获取图片url很困难,但本身的图片url极有规律,所以本人决定直接从图片url入手
#2.2 通过url获取图片
观察图片url可发现,组成为http://img.mljzmm.com/comic/+漫画编号+/+章节名+/+页码+.jpg,但若名称中含有空格,需转码为%20
l = list(name)
for o in range(len(l)):
if l[o] == ' ':
l[o] = '%20'
s = ''
for i in range(len(l)):
s = s + l[i]
for i in range(pageNum):
if i + 1 < 10:
pageNum_c = '000' + str(i + 1)
else:
pageNum_c = '00' + str(i + 1)
Pic_url = 'http://img.mljzmm.com/comic/14339/' + s + '/' + pageNum_c + '.jpg'
获取完记得关闭浏览器
browser.quit()
之后使用Python的文件读写进行储存即可
def Pic_save(path,url):
respone = requests.get(url)
with open(path,'wb') as f:
f.write(respone.content)
#3.0 检查及进行更新
我们进行存储的漫画很多时候并不是完结的,而是会更新,每次处理更新时,不能重复新建相同的文件夹,总不能全删掉重新爬取,那样太耗费时间了,于是,检查及进行更新的功能便是十分必要的
#3.1 检查更新
- 是否为更新状态
首先,我们需要确认这个漫画是否为更新状态,即原有一部分漫画,若是,该漫画的根目录是必定存在的,我们可以在创建根目录时进行检查
def Create(path):
if not os.path.exists(path): #检查该路径是否存在
os.makedirs(path) #如果不存在,创建
else: #存在,说明是进行更新
print('目标文件夹已存在, 3秒后进入更新状态')
return True
return False
- 确认是否有更新·update文件
之后,怎样确认是否有更新呢?我们已经得到了当前的章数\(i\),如果能与之前所有的章数进行比较,我们就可以轻易得到是否有更新,有几章更新,那么我们就需要一个文件 update.txt 记录之前的章数。
def Update(path,num):
s = str(num)
with open(path + 'update.txt','w') as f:
f.write(s)
我们在存储完所有章节后加上这一句:
Update(path_z,i) #path_z为该漫画根目录,i则为本次获取到的章节数
以
open()的方式写入,如果没有文件,会自动创建
- 确认是否有更新·update文件的读取
简单的文件读取,注意这里返回的是一个str类型的变量
def Get_ver(path):
with open(path + 'update.txt','r') as f:
line = f.readline()
line_num = line.split()
a = line_num[0]
return a
那么我们就可以在进行储存前加入以下语句:
ver = 0
path_z = path_a + name_a + '\\'
if Create(path_a + name_a):
time.sleep(3)
ver = Get_ver(path_z) #这里其实返回的是str
#3.2 进行更新
在储存时,存储章节数=当前章数-之前章数
#4.0 完整代码
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
import time
import os
def Pic_save(path,url): #图片存储
respone = requests.get(url)
with open(path,'wb') as f:
f.write(respone.content)
def Get_ver(path): #获取之前已有章节数
with open(path + 'update.txt','r') as f:
line = f.readline()
line_num = line.split()
a = line_num[0]
return a
def Update(path,num): #将更新写入update.txt文件
s = str(num) #open.write()只能写入str类型
with open(path + 'update.txt','w') as f:
f.write(s)
def Create(path):
if not os.path.exists(path): #当前路径不存在,该漫画为第一次爬取
os.makedirs(path)
else:
print('目标文件夹已存在, 3秒后进入更新状态')
return True
return False
def each(url,path_z,Num):
browser = webdriver.Firefox()
browser.get(url)
browser.implicitly_wait(3)
html_each = requests.get(url)
soup = BeautifulSoup(html_each.content,'lxml')
# print(soup.prettify())
pageNum = (len(browser.find_elements_by_tag_name('option')) - 6) / 2 #获取页数
pageNum = int(pageNum)
# print(pageNum)
name_div = soup.find('div',attrs={'class':'mh_readtitle'})
name = (name_div.find('strong')).get_text() #获取章节名称
# print(name)
# space = ' '
# new = '%20'
l = list(name)
for o in range(len(l)):
if l[o] == ' ':
l[o] = '%20'
s = ''
for i in range(len(l)):
s = s + l[i]
# print(s)
print('开始保存' + name + '!')
# b = os.getcwd()
os.mkdir(path_z + name)
path_s = path_z + name + '\\'
for i in range(pageNum): #利用url存储图片
if i + 1 < 10:
pageNum_c = '000' + str(i + 1)
else:
pageNum_c = '00' + str(i + 1)
Pic_url = 'http://img.mljzmm.com/comic/' + Num + '/' + s + '/' + pageNum_c + '.jpg'
# print(Pic_url)
Pic_save(path_s + pageNum_c + '.jpg',Pic_url)
print(name + '保存完毕!')
browser.quit()
def mulu(base_url,path_a,Num):
url_list = []
html = requests.get(base_url)
soup = BeautifulSoup(html.content,'lxml')
liTags = soup.find_all('li',attrs={'class':'fed-padding fed-col-xs6 fed-col-md3 fed-col-lg3'}) #获取每章节url存在的li标签
name_a = (soup.find('h1',attrs={'class':'fed-part-eone fed-font-xvi'})).get_text() #获取漫画名称
ver = 0
path_z = path_a + name_a + '\\'
if Create(path_a + name_a): #检查更新
time.sleep(3)
ver = Get_ver(path_z)
i = 0
for li in liTags: #获取每章节地址及章节数目
url_list.append("https://www.ohmanhua.com" + \
li.find('a',attrs={'class':'fed-btns-info fed-rims-info fed-part-eone'})['href'])
i = i + 1
if i - int(ver) == 0:
print('无可更新章节,3秒后自动退出')
time.sleep(3)
return
print('共' + str(i) + '章节,需更新' + str(i - int(ver)) + '章,获取各章节地址成功!')
j = i - int(ver) - 1
while j >= 0:
each(url_list[j],path_z,Num)
j = j - 1
Update(path_z,i) #写入更新
def main():
base_url = str(input('请输入漫画首页地址: \n'))
path_a = 'c:\\' #存储根目录,自行更改
url_l = list(base_url)
s = ''
num = 0
for a in url_l: #获取漫画编号
if num == 3:
num = num + 1
if a == '/':
num = num + 1
if num == 5:
break
if num > 3:
s = s + a
mulu(base_url,path_a,s)
print('Finished saving!')
if __name__ == '__main__':
main()
更新日志及说明
更新
- 初次完成编辑 - \(2020.6.9\)
- 对代码进行了一定更新 - \(2020.6.11\)
- 增添了5.0检查及进行更新章节并添加部分注释 - \(2020.7.6\)
本文若有更改或补充会持续更新
说明
本文出现的源码已储存至本人的Github中,可自行访问获取
传送门

 浙公网安备 33010602011771号
浙公网安备 33010602011771号