JAVA程序使用Jsoup 爬取网页内容
本程序将展示使用Jsoup爬取51job招聘信息的示例,只是用于对Jsoup的学习,不会做其他使用
1. 新建一个springboot项目
添加Jsoup的依赖,以及mysql和mybatis的依赖,其中后面的依赖用于将爬取到的数据存入中mysql数据库中
1 <dependency>
2 <groupId>org.springframework.boot</groupId>
3 <artifactId>spring-boot-starter-web</artifactId>
4 </dependency>
5
6
7 <dependency>
8 <groupId>org.jsoup</groupId>
9 <artifactId>jsoup</artifactId>
10 <version>1.10.2</version>
11 </dependency>
12
13 <dependency>
14 <groupId>tk.mybatis</groupId>
15 <artifactId>mapper-spring-boot-starter</artifactId>
16 <version>2.0.4</version>
17 </dependency>
18
19 <dependency>
20 <groupId>org.springframework.boot</groupId>
21 <artifactId>spring-boot-starter-jdbc</artifactId>
22 <version>2.2.1.RELEASE</version>
23 </dependency>
24
25 <dependency>
26 <groupId>org.mybatis.spring.boot</groupId>
27 <artifactId>mybatis-spring-boot-starter</artifactId>
28 <version>2.0.1</version>
29 </dependency>
30
31 <dependency>
32 <groupId>mysql</groupId>
33 <artifactId>mysql-connector-java</artifactId>
34 <version>5.1.48</version>
35 </dependency>
36
37 <dependency>
38 <groupId>com.alibaba</groupId>
39 <artifactId>druid</artifactId>
40 <version>1.1.1</version>
41 </dependency>
2. 配置文件application.yml
主要配置数据库的链接字符串信息
1 server:
2 port: 7999
3 spring:
4 servlet:
5 multipart:
6 max-request-size: 100MB #最大请求文件的大小
7 max-file-size: 20MB #设置单个文件最大长度
8 http:
9 encoding:
10 charset: utf-8
11 force: true
12 enabled: true
13 datasource:
14 platform: mysql
15 type: com.alibaba.druid.pool.DruidDataSource
16 initialSize: 5
17 minIdle: 3
18 maxActive: 500
19 maxWait: 60000
20 timeBetweenEvictionRunsMillis: 60000
21 minEvictableIdleTimeMillis: 30000
22 validationQuery: select 1
23 testOnBorrow: true
24 poolPreparedStatements: true
25 maxPoolPreparedStatementPerConnectionSize: 20
26 driverClassName: com.mysql.jdbc.Driver
27 url: jdbc:mysql://localhost:3306/job?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=utf-8&useAffectedRows=true&rewriteBatchedStatements=true
28 username: root
29 password: root
3. springboot启动类
额外添加了对mybatis mapper的扫描
1 package com.devin.jobsearch;
2
3 import org.springframework.boot.SpringApplication;
4 import org.springframework.boot.autoconfigure.SpringBootApplication;
5 import tk.mybatis.spring.annotation.MapperScan;
6
7
8 @MapperScan("com.devin.jobsearch.mapper")
9 @SpringBootApplication
10 public class JobSearchApplication {
11
12 public static void main(String[] args) {
13 SpringApplication.run(JobSearchApplication.class, args);
14 }
15
16 }
4. 数据库表和对应的model
CREATE TABLE `job` (
`job_id` varchar(128) NOT NULL,
`job_name` varchar(512) DEFAULT NULL,
`job_detail` text,
`job_company_name` varchar(512) DEFAULT NULL,
`job_company_image` varchar(512) DEFAULT NULL,
`job_company_desc` text,
`job_company_url` varchar(512) DEFAULT NULL,
`job_url` varchar(512) DEFAULT NULL,
`job_location` varchar(128) DEFAULT NULL,
`job_location_detail` varchar(4000) DEFAULT NULL,
`job_salary` varchar(512) DEFAULT NULL,
`job_date` varchar(128) DEFAULT NULL,
`job_restrict_str` varchar(512) DEFAULT NULL,
PRIMARY KEY (`job_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
1 package com.devin.jobsearch.model;
2
3 import javax.persistence.Table;
4
5 /**
6 * @author Devin Zhang
7 * @className JobModel
8 * @description TODO
9 * @date 2020/4/22 9:42
10 */
11 @Table(name = "job")
12 public class JobModel {
13 private String jobId;
14 private String jobName;
15 private String jobDetail;
16 private String jobCompanyName;
17 private String jobCompanyImage;
18 private String jobCompanyDesc;
19 private String jobCompanyUrl;
20 private String jobUrl;
21 private String jobLocation;
22 private String jobLocationDetail;
23 private String jobSalary;
24 private String jobDate;
25 private String jobRestrictStr;
26
27 public String getJobId() {
28 return jobId;
29 }
30
31 public void setJobId(String jobId) {
32 this.jobId = jobId;
33 }
34
35 public String getJobName() {
36 return jobName;
37 }
38
39 public void setJobName(String jobName) {
40 this.jobName = jobName;
41 }
42
43 public String getJobDetail() {
44 return jobDetail;
45 }
46
47 public void setJobDetail(String jobDetail) {
48 this.jobDetail = jobDetail;
49 }
50
51 public String getJobCompanyName() {
52 return jobCompanyName;
53 }
54
55 public void setJobCompanyName(String jobCompanyName) {
56 this.jobCompanyName = jobCompanyName;
57 }
58
59 public String getJobCompanyDesc() {
60 return jobCompanyDesc;
61 }
62
63 public void setJobCompanyDesc(String jobCompanyDesc) {
64 this.jobCompanyDesc = jobCompanyDesc;
65 }
66
67 public String getJobCompanyUrl() {
68 return jobCompanyUrl;
69 }
70
71 public void setJobCompanyUrl(String jobCompanyUrl) {
72 this.jobCompanyUrl = jobCompanyUrl;
73 }
74
75 public String getJobUrl() {
76 return jobUrl;
77 }
78
79 public void setJobUrl(String jobUrl) {
80 this.jobUrl = jobUrl;
81 }
82
83 public String getJobLocation() {
84 return jobLocation;
85 }
86
87 public void setJobLocation(String jobLocation) {
88 this.jobLocation = jobLocation;
89 }
90
91 public String getJobLocationDetail() {
92 return jobLocationDetail;
93 }
94
95 public void setJobLocationDetail(String jobLocationDetail) {
96 this.jobLocationDetail = jobLocationDetail;
97 }
98
99 public String getJobSalary() {
100 return jobSalary;
101 }
102
103 public void setJobSalary(String jobSalary) {
104 this.jobSalary = jobSalary;
105 }
106
107 public String getJobDate() {
108 return jobDate;
109 }
110
111 public void setJobDate(String jobDate) {
112 this.jobDate = jobDate;
113 }
114
115 public String getJobCompanyImage() {
116 return jobCompanyImage;
117 }
118
119 public void setJobCompanyImage(String jobCompanyImage) {
120 this.jobCompanyImage = jobCompanyImage;
121 }
122
123 public String getJobRestrictStr() {
124 return jobRestrictStr;
125 }
126
127 public void setJobRestrictStr(String jobRestrictStr) {
128 this.jobRestrictStr = jobRestrictStr;
129 }
130
131 @Override
132 public String toString() {
133 return "JobModel{" +
134 "jobId='" + jobId + '\'' +
135 ", jobName='" + jobName + '\'' +
136 ", jobDetail='" + jobDetail + '\'' +
137 ", jobCompanyName='" + jobCompanyName + '\'' +
138 ", jobCompanyImage='" + jobCompanyImage + '\'' +
139 ", jobCompanyDesc='" + jobCompanyDesc + '\'' +
140 ", jobCompanyUrl='" + jobCompanyUrl + '\'' +
141 ", jobUrl='" + jobUrl + '\'' +
142 ", jobLocation='" + jobLocation + '\'' +
143 ", jobLocatonDetail='" + jobLocationDetail + '\'' +
144 ", jobSalary='" + jobSalary + '\'' +
145 ", jobDate='" + jobDate + '\'' +
146 ", jobRestrictStr='" + jobRestrictStr + '\'' +
147 '}';
148 }
149 }
5. 数据库操作mapper类 和 mapper配置文件
因为使用了tkmybatis,所以mapper类 和 mapper配置文件中补需要额外添加任何代码和配置
JobMapper.java
1 package com.devin.jobsearch.mapper;
2
3 import com.devin.jobsearch.model.JobModel;
4 import tk.mybatis.mapper.common.Mapper;
5 import tk.mybatis.mapper.common.MySqlMapper;
6
7 /**
8 * @author Devin Zhang
9 * @className JobMapper
10 * @description TODO
11 * @date 2020/4/22 16:24
12 */
13
14 public interface JobMapper extends Mapper<JobModel>, MySqlMapper<JobModel> {
15 }
JobMapper.xml
1 <?xml version="1.0" encoding="UTF-8" ?> 2 <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > 3 <mapper namespace="com.devin.jobsearch.mapper.JobMapper" > 4 5 </mapper>
6. 工具类
SearchUtil.java 主要用于Jsoup加载url返回一个Document对象
1 package com.devin.jobsearch.util; 2 3 4 import org.jsoup.Jsoup; 5 import org.jsoup.nodes.Document; 6 import org.springframework.stereotype.Component; 7 8 /** 9 * @author Devin Zhang 10 * @className SearchUtil 11 * @description TODO 12 * @date 2020/4/22 10:07 13 */ 14 15 @Component 16 public class SearchUtil { 17 18 public Document getDocument(String url) throws Exception { 19 Document document = Jsoup 20 .connect(url) 21 .header("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36") 22 .get(); 23 return document; 24 } 25 }
FileUtil.java 主要用于记录错误信息
1 package com.devin.jobsearch.util; 2 3 import org.springframework.stereotype.Component; 4 5 import java.io.BufferedWriter; 6 import java.io.File; 7 import java.io.FileOutputStream; 8 import java.io.OutputStreamWriter; 9 10 /** 11 * @author Devin Zhang 12 * @className FileUtil 13 * @description TODO 14 * @date 2020/4/22 17:56 15 */ 16 @Component 17 public class FileUtil { 18 19 private String filePath = "D:\\data\\job\\fail.log"; 20 21 public void writeLog(String log) { 22 BufferedWriter bw = null; 23 try { 24 bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File(filePath), true))); 25 bw.write(log); 26 bw.flush(); 27 } catch (Exception e) { 28 e.printStackTrace(); 29 } finally { 30 try { 31 bw.close(); 32 } catch (Exception e) { 33 e.printStackTrace(); 34 } 35 } 36 } 37 }
7. 爬虫的逻辑处理
我们打开51job的搜索页,分别查看首页,第2页,第3页,可以看到变化只是在访问页码的参数上有变化,所以我们可以循环去爬取整个的职位信息
首页
https://search.51job.com/list/000000,000000,0000,00,9,99,%2B,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
第二页
https://search.51job.com/list/000000,000000,0000,00,9,99,%2B,2,2.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
第三页
https://search.51job.com/list/000000,000000,0000,00,9,99,%2B,2,3.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
代码实现:
首先创建一个接口,接口中定了两个方法,一个用于获取总的页数,一个用于循环去爬取数据
爬虫的方法实现了该接口,后续如果我们要爬取其他网站,只需要实现该接口,编写逻辑即可
IJobHandle.java
1 package com.devin.jobsearch.Service; 2 3 /** 4 * @author Devin Zhang 5 * @className IJobHandle 6 * @description TODO 7 * @date 2020/4/22 16:39 8 */ 9 10 public interface IJobHandle { 11 12 int getJobPage() throws Exception; 13 14 void handle() throws Exception; 15 }
Job51SearchHandle.java
1 package com.devin.jobsearch.Service; 2 3 import com.devin.jobsearch.mapper.JobMapper; 4 import com.devin.jobsearch.model.JobModel; 5 import com.devin.jobsearch.util.FileUtil; 6 import com.devin.jobsearch.util.SearchUtil; 7 import org.jsoup.nodes.Document; 8 import org.jsoup.nodes.Element; 9 import org.jsoup.select.Elements; 10 import org.springframework.stereotype.Service; 11 import org.springframework.util.CollectionUtils; 12 import org.springframework.util.StringUtils; 13 14 import javax.annotation.Resource; 15 import java.util.ArrayList; 16 import java.util.List; 17 import java.util.regex.Matcher; 18 import java.util.regex.Pattern; 19 20 /** 21 * @author Devin Zhang 22 * @className Job51SearchHandle 23 * @description TODO 24 * @date 2020/4/21 16:41 25 */ 26 27 @Service 28 public class Job51SearchHandle implements IJobHandle { 29 30 @Resource 31 private SearchUtil searchUtil; 32 @Resource 33 private JobMapper jobMapper; 34 @Resource 35 private FileUtil fileUtil; 36 37 private static final String PAGEPATTERN = "pagePattern"; 38 private static final String JOB51URL = "https://search.51job.com/list/000000,000000,0000,00,9,99,%2B,2,pagePattern.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare="; 39 40 41 /** 42 * 获取51job总共有多少页 43 * 44 * @return 45 * @throws Exception 46 */ 47 @Override 48 public int getJobPage() throws Exception { 49 String url = JOB51URL; 50 url = url.replace(PAGEPATTERN, "1"); 51 Document document = searchUtil.getDocument(url); 52 return Integer.parseInt(document.getElementById("hidTotalPage").val()); 53 } 54 55 56 /** 57 * 分页爬取51job 58 */ 59 @Override 60 public void handle() throws Exception { 61 //目标地址 62 int pageTotal = this.getJobPage(); 63 List<JobModel> jobModelList = null; 64 for (int page = 1; page <= pageTotal; page++) { 65 try { 66 jobModelList = new ArrayList(); 67 System.out.println("开始爬取第:" + page + "页的数据"); 68 String url = JOB51URL; 69 url = url.replace(PAGEPATTERN, page + ""); 70 Document document = searchUtil.getDocument(url); 71 // 右侧导航栏 72 Elements nav_com = document.getElementsByClass("el"); 73 for (Element element : nav_com) { 74 if (element.children().first().tagName("p").hasClass("t1") && 75 element.children().first().tagName("p").children().hasClass("check")) { 76 77 String jobName = element.children().first().tagName("p").children().tagName("span").text(); 78 String jobUrl = element.children().first().tagName("p").child(2).child(0).attr("href"); 79 String companyName = element.child(1).text(); 80 String companyUrl = element.child(1).child(0).attr("href"); 81 String jobLocation = element.child(2).text(); 82 String jobSalary = element.child(3).text(); 83 String jobDate = element.child(4).text(); 84 85 JobModel jobModel = new JobModel(); 86 jobModel.setJobName(jobName); 87 jobModel.setJobUrl(jobUrl); 88 jobModel.setJobCompanyName(companyName); 89 jobModel.setJobCompanyUrl(companyUrl); 90 jobModel.setJobLocation(jobLocation); 91 jobModel.setJobSalary(jobSalary); 92 jobModel.setJobDate(jobDate); 93 94 //爬取明细 95 Document detailDocument = searchUtil.getDocument(jobUrl); 96 97 String jobRestrict = detailDocument.getElementsByClass("msg ltype").text(); 98 String jobDesc = detailDocument.getElementsByClass("bmsg job_msg inbox").text(); 99 String jobLocationDetail = ""; 100 if (detailDocument.getElementsByClass("bmsg inbox").size() > 0) { 101 jobLocationDetail = detailDocument.getElementsByClass("bmsg inbox").first().child(0).text(); 102 } 103 String companyDesc = detailDocument.getElementsByClass("tmsg inbox").text(); 104 String companyImage = ""; 105 if (detailDocument.getElementsByClass("com_name himg").size() > 0) { 106 companyImage = detailDocument.getElementsByClass("com_name himg").first().child(0).attr("src"); 107 } 108 109 110 jobModel.setJobRestrictStr(jobRestrict); 111 jobModel.setJobDetail(jobDesc); 112 jobModel.setJobLocationDetail(jobLocationDetail); 113 jobModel.setJobCompanyDesc(companyDesc); 114 jobModel.setJobCompanyImage(companyImage); 115 116 String jobId = ""; 117 String patternStr = "/[0-9]*.html"; 118 Pattern pattern = Pattern.compile(patternStr); 119 Matcher matcher = pattern.matcher(jobUrl); 120 if (matcher.find()) { 121 jobId = matcher.group(); 122 jobId = jobId.replaceAll(".html", "").replaceAll("/",""); 123 } 124 if (StringUtils.isEmpty(jobId)) { 125 patternStr = "jobid=[0-9]*"; 126 pattern = Pattern.compile(patternStr); 127 matcher = pattern.matcher(jobUrl); 128 if (matcher.find()) { 129 jobId = matcher.group(); 130 jobId = jobId.replaceAll("jobid=", ""); 131 } 132 } 133 if (StringUtils.isEmpty(jobId)) { 134 patternStr = "#[0-9]*"; 135 pattern = Pattern.compile(patternStr); 136 matcher = pattern.matcher(jobUrl); 137 if (matcher.find()) { 138 jobId = matcher.group(); 139 jobId = jobId.replaceAll("#", ""); 140 } 141 } 142 jobModel.setJobId(jobId); 143 System.out.println(jobModel); 144 jobModelList.add(jobModel); 145 } 146 } 147 if (!CollectionUtils.isEmpty(jobModelList)) { 148 System.out.println("第" + page + "页数据,开始插入数据"); 149 jobMapper.insertList(jobModelList); 150 } 151 Thread.sleep(3000); //sleep 3 秒,防止访问太频繁,被禁掉 152 } catch (Exception e) { 153 e.printStackTrace(); 154 if (null != jobModelList) { 155 fileUtil.writeLog(jobModelList.toString()); 156 } 157 } 158 } 159 } 160 161 }
8. 调用
我们新建一个controller,访问直接调用弄
1 package com.devin.jobsearch.controller; 2 3 import com.devin.jobsearch.Service.Job51SearchHandle; 4 import org.springframework.web.bind.annotation.GetMapping; 5 import org.springframework.web.bind.annotation.RequestMapping; 6 import org.springframework.web.bind.annotation.RestController; 7 8 import javax.annotation.Resource; 9 10 /** 11 * @author Devin Zhang 12 * @className JobController 13 * @description TODO 14 * @date 2020/4/22 16:36 15 */ 16 @RestController 17 @RequestMapping("/job") 18 public class JobController { 19 20 @Resource 21 private Job51SearchHandle job51SearchHandle; 22 23 @GetMapping("/51jobHandle") 24 public String handle51JobController() throws Exception { 25 job51SearchHandle.handle(); 26 return "success"; 27 } 28 }
访问: localhost:7999/job/51jobHandle 即可触发爬取,可以看到爬取到的数据已经存到数据库了
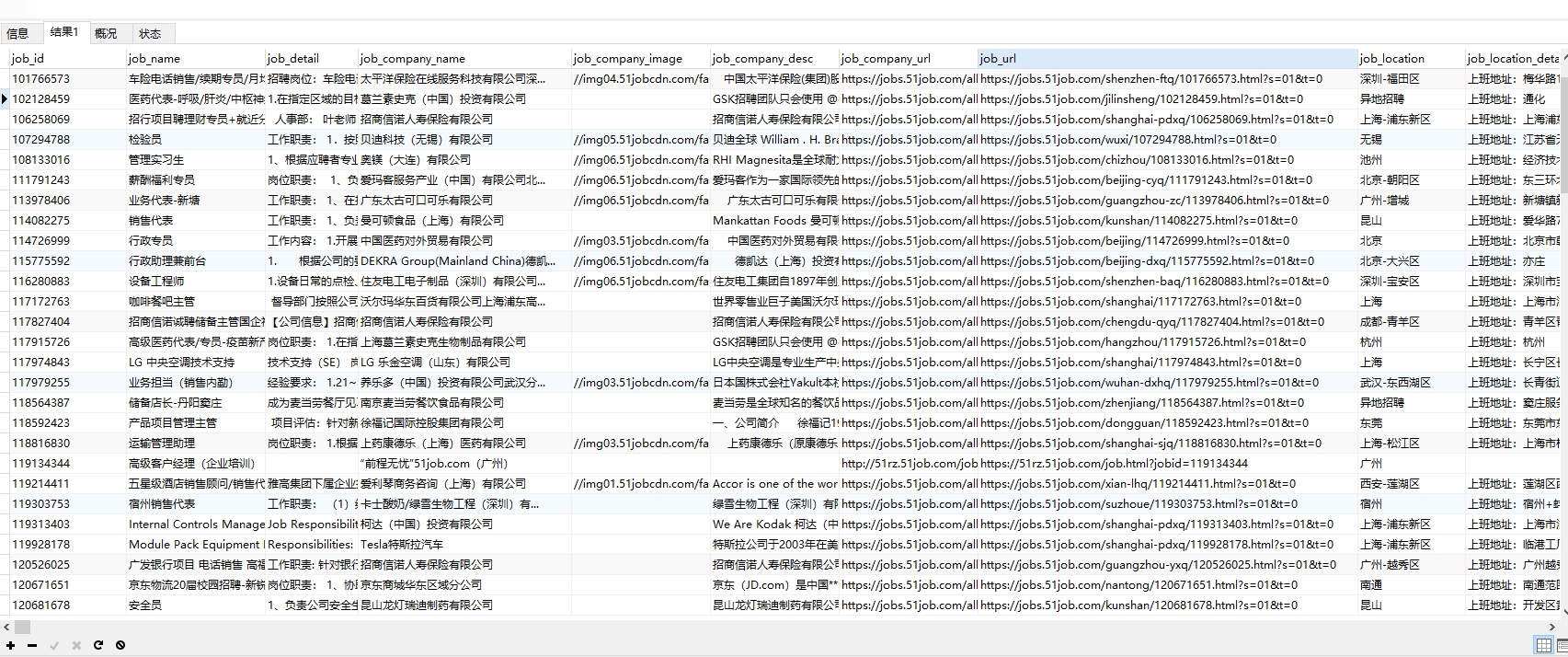
github地址: https://github.com/devinzhang0209/jobsearch.git
最后,再次说明,本文章的目的只是为了学习Jsoup,爬取到的数据也不会用作其他使用,毕竟爬虫爬的好,牢饭吃的饱。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号