【Robot Framework 项目实战 02】使用脚本生成统一格式的RF关键字
背景
在微服务化的调用环境下,测试数据及接口依赖的维护是一个问题,因为依赖的接口和数据可能不在同一个服务下,而这相关的多个服务往往是不同人员来测试的。
因此为了节省沟通成本,避免关键字的重复冗余。所以我们在RF框架推广之初就确定了接口关键字统一管理的基调,方便不同服务之间的调用。
脚本介绍
中间数据Excel
为了让关键字的格式统一,我们每一个业务线使用同一个关键字数据生成脚本,小伙伴们通过维护Excel来维护接口关键字。
被维护的Excel内容如下:
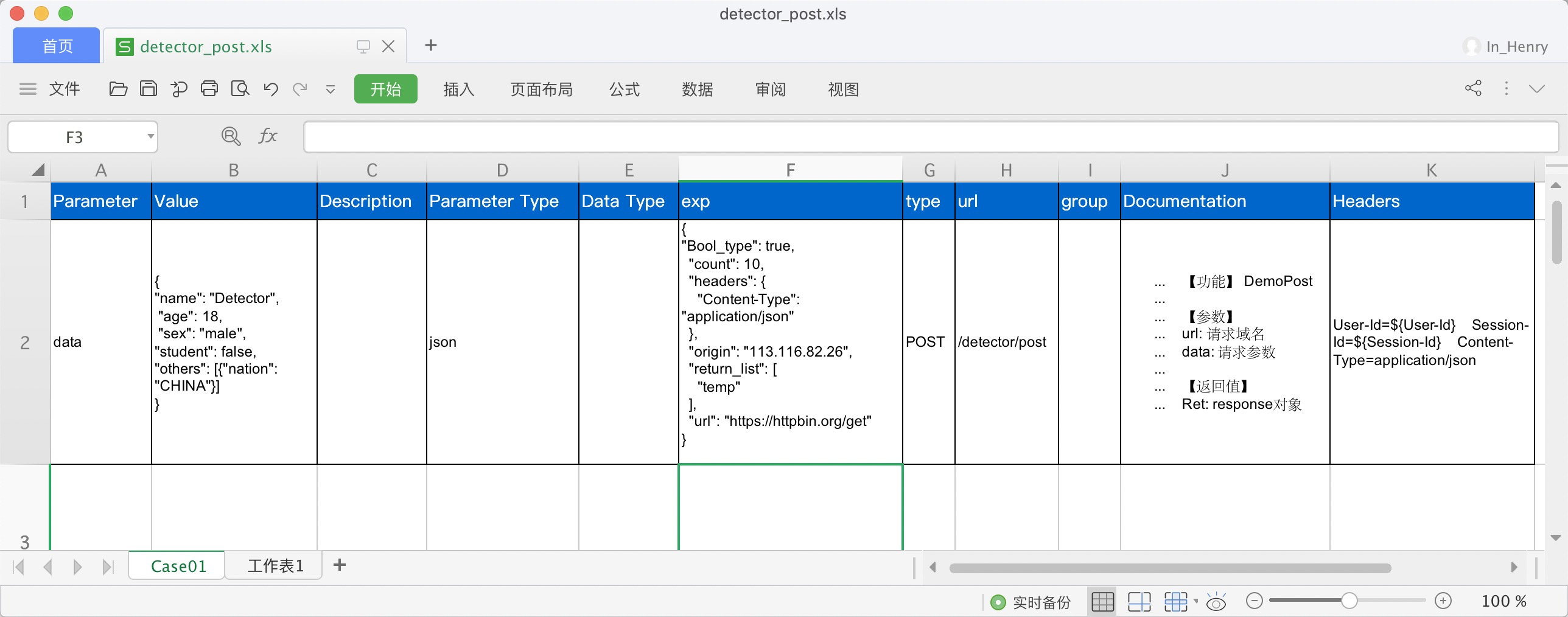
Excel文件名称规则: 为接口服务名称和path的组合,
Excel文件内容规则: 接口传递参数类型,请求参数,请求方式,path路径,预期返回,接口headers及接口描述等信息。
初期,关键字的生成由一人统一管理,发送数据及预期结果,主要用于检测数据
对应生成的关键字如下:
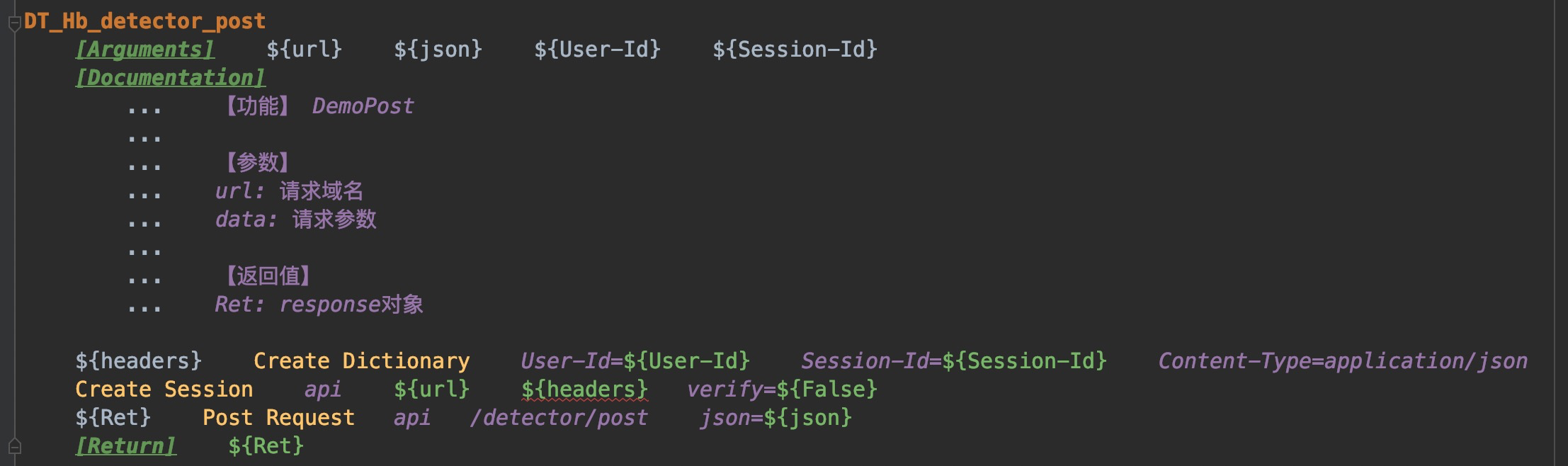
注:Excel中的Path及headers中存在${}时,关键字会将其作为传入参数
关键字命名规则: 公司代号_流水线(项目组)代号_服务名称_接口path(path相同时以请求方式区分)
完整脚本
具体的脚本较为简单: apitest/Common/Testscript/common/gen_rf_kw.py
#! /usr/bin/python
# coding:utf-8
"""
@author:Bingo.he
@file: gen_common_kw.py
@time: 2019/01/01
"""
import os
import re
from apitest.Common.Testscript.utils.logger import logger
from apitest.Common.Testscript.utils.operate_xls import OperateXls
class GenRFkw:
def __init__(self, xls_folder, demo_case_folder):
self.xls_folder = xls_folder
self.target_case_folder = demo_case_folder
@staticmethod
def kw_requests_init(target_robot_name):
with open(target_robot_name, 'a') as f:
f.write('*** Settings ***' + '\n')
f.write('Library TestLibrary' + '\n')
f.write('Library RequestsLibrary' + '\n')
f.write('\n')
f.write('*** Keywords ***' + '\n')
@staticmethod
def gen_kw(target_robot_name, param_type, req_method, url, document, headers, msg_type):
if param_type == "json" or param_type == "data":
# param_type = "data"
param_type = "json"
with open(target_robot_name, 'a', encoding="utf-8") as f:
f.write(' [Arguments] ${url}')
f.write(' ${' + param_type + '}')
# 允许url中传递可变参数
if "${" in url:
p = re.compile(r'{(.*?)}')
verify_urls = p.findall(url)
for verify_url in verify_urls:
f.write(" ${{{}}}".format(verify_url))
# 允许headers中传递可变参数
if "${" in headers:
sprint_str = headers
p = re.compile(r'{(.*?)}')
sprint_num = p.findall(sprint_str)
for s in sprint_num:
f.write(" ${{{}}}".format(s))
f.write('\n')
f.write(' [Documentation] ' + document + '\n')
# 兼容form-data请求
if "multipart/form-data" == msg_type:
f.write(' ${boundary}= xl boundary parse ${data}' + '\n')
f.write(' ${headers} Create Dictionary ' + headers + '\n')
f.write(' Create Session api ${url} ${headers} verify=${False}' + '\n')
if '' != param_type.strip(): # 接口输入参数个数不为零
if req_method.upper() == 'GET' or req_method.upper() == 'DELETE':
f.write(' ${{Ret}} {} Request api '.format(req_method.capitalize()) + url)
f.write('${' + param_type + '}') # 发送GET请求,直接把EXCEL中读取出来的参数连接到URL后面
f.write('\n')
else:
f.write(' ${{Ret}} {} Request api '.format(req_method.capitalize()) + url)
f.write(' ' + param_type + '=${' + param_type + '}')
f.write('\n')
f.write(' [Return] ${Ret}' + '\n')
f.write('\n')
@staticmethod
def find_file_name(file_dir):
files = None
for root, dirs, files in os.walk(file_dir):
logger.info("当前目录路径" + root) # 当前目录路径
logger.info("当前路径下所有子目录" + str(dirs)) # 当前路径下所有子目录
logger.info("当前路径下所有非目录子文件" + str(files)) # 当前路径下所有非目录子文件
files = [file for file in files if ".xls" in file]
# 按照顺序排序
files.sort()
return files
@staticmethod
def interface_name(kw_excel):
return kw_excel.split(".")[0]
def run(self, **kwargs):
xls_files = self.find_file_name(self.xls_folder)
target_robot_name = os.path.join(self.target_case_folder, "DT_Hb_kwRequests.robot")
if os.path.exists(target_robot_name):
os.remove(target_robot_name)
self.kw_requests_init(target_robot_name)
for xls_file in xls_files:
interface_name = self.interface_name(xls_file)
with open(target_robot_name, 'a') as f:
f.write('DT_Hb_' + interface_name + '\n')
book = OperateXls(os.path.join(self.xls_folder, xls_file), index=0)
param_type = book.rf_xls_msg_type()
# param = book.rf_xls_param_value()
decode_type = book.rf_xls_msg_type()
url = book.rf_xls_url()
document = book.rf_xls_document()
headers = book.rf_xls_headers()
method = book.rf_xls_method()
self.gen_kw(target_robot_name, param_type, method, url, document, headers, decode_type)
依赖脚本: apitest/Common/Testscript/utils/operate_xls.py
#! /usr/bin/python
# coding:utf-8
"""
@author:Bingo.he
@file: operate_xls.py
@time: 2019/01/01
"""
import xlrd
from apitest.Common.Testscript.utils.logger import logger
class OperateXls:
def __init__(self, xls_ile, index):
self.book = xlrd.open_workbook(xls_ile, encoding_override='utf-8')
self.sheet = self.book.sheet_by_index(index) # 通过sheet索引获得sheet对象
def switch_sheet_index(self, count):
"""
通过index切换sheet对象
:param count:
:return:
"""
self.sheet = self.book.sheet_by_index(count)
def switch_sheet_by_name(self, sheet_name):
"""
通过sheet name 切换 sheet对象
:param sheet_name:
:return:
"""
self.sheet = self.book.sheet_by_name(sheet_name)
def sheet_name_by_index(self, count):
return self.book.sheet_names()[count] # 获得指定索引的sheet表名字
def get_value(self, rowx, colx):
return self.sheet.cell_value(rowx, colx)
def sheet_params_by_name(self, sheet_name):
"""
返回sheet页所有数据
:param sheet_name:
:return: sheet data format: {row_num:[data of column1,data of column2....]}
"""
all_data = {}
row_data = []
sheet = self.book.sheet_by_name(sheet_name) # 通过sheet名字来获取
row_num = sheet.nrows # 获取行总数
cols_num = sheet.ncols # 获取行总数
logger.info("有效数据行数: " + str(row_num))
logger.info("有效数据列数: :" + str(cols_num))
for i in range(0, row_num):
for c in range(cols_num):
row_data.append(sheet.cell_value(i, c)) # 获取指定EXCEL文件中,第一个SHEET中的接口字段名
all_data[i] = row_data
row_data = []
# logger.info(str(json.dumps(all_data, indent=4)))
logger.info(str(all_data))
return all_data
def sheet_params_by_index(self, index):
"""
返回sheet页所有数据
:param index:
:return: sheet data format: {row_num:[data of column1,data of column2....]}
"""
all_data = {}
row_data = []
sheet = self.book.sheet_by_index(index) # 通过sheet名字来获取
row_num = sheet.nrows # 获取行总数
cols_num = sheet.ncols # 获取行总数
logger.info("有效数据行数: " + str(row_num))
logger.info("有效数据列数: :" + str(cols_num))
for i in range(0, row_num):
for c in range(cols_num):
row_data.append(sheet.cell_value(i, c)) # 获取指定EXCEL文件中,第一个SHEET中的接口字段名
all_data[i] = row_data
row_data = []
# logger.info(str(json.dumps(all_data, indent=4)))
logger.info(str(all_data))
return all_data
class ReadRFExcel(OperateXls):
def rf_xls_param_type(self):
return self.get_value(1, 0) # 获取'B2'字段内容
def rf_xls_param_value(self):
return self.get_value(1, 1) # 获取'B2'字段内容
def rf_xls_msg_type(self):
return self.get_value(1, 3) # 获取'D2'字段内容
def rf_xls_method(self):
return self.get_value(1, 6) # 获取'G2'字段内容
def rf_xls_url(self):
return self.get_value(1, 7) # 获取'H2'字段内容
def rf_xls_group(self):
return self.get_value(1, 8) # 获取'I2'字段内容
def rf_xls_document(self):
return self.get_value(1, 9) # 获取'J2'字段内容
def rf_xls_headers(self):
return self.get_value(1, 10) # 获取'K2'字段内容
if __name__ == '__main__':
op = ReadRFExcel("test.xls", 0)
print(op.rf_xls_headers())
op.switch_sheet_index(1)
op.rf_xls_headers()
op.sheet_params_by_index(1)
op.sheet_name_by_index(1)
文中可能存在描述不正确,欢迎大神们指正补充!
感谢阅读,如果觉得对你有帮助,就在右下角点个赞吧,感谢!
合抱之木,生于毫末;九层之台,起于累土;千里之行,始于足下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号