
最近在看CUDA,讲到C++是怎么调用CUDA函数进而加载进GPU内核进行运行的,网上基本上全部都是一样的资料,只讲Grid包含很多Thread block,每个Thread block只能加载到一个SM中进行并行运算,然后就是线程分类到warp中进行分组计算,网上大多讲的是这些,具体thread block怎么分配到SM就没讲清楚,今天来点自己的分析。
显卡的硬件配置,只有3个SM单元,总共只有12个硬件warp,但是运行软件调试发现,至少有一百多个软件warp同时运行,如果按照每个Thread Block只配置到一个SM来计算,总共应该只有12个软件warp才对,多出来的warp哪来的?其实这只是一种软件模拟实现的“并行"计算,用比硬件数目多的软件warp提高硬件的计算吞吐量,另一方面,一个SM可以同时支持多个Thread block的运行,这是很多文档都没有介绍的内容,也是本文的重点。
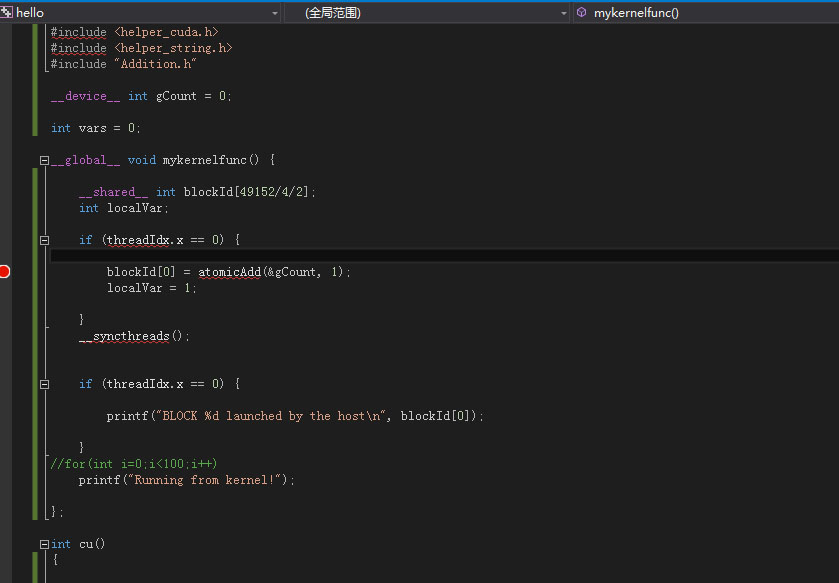
首先看代码,代码很简单,只是个普通的kernel函数。下面的分析用到Cuda Toolkit里面自带的profile工具nvvp.
首先在host端调用上述代码:
mykernelfunc <<< 2, 1>>> ();用nvvp查看如下图所示,
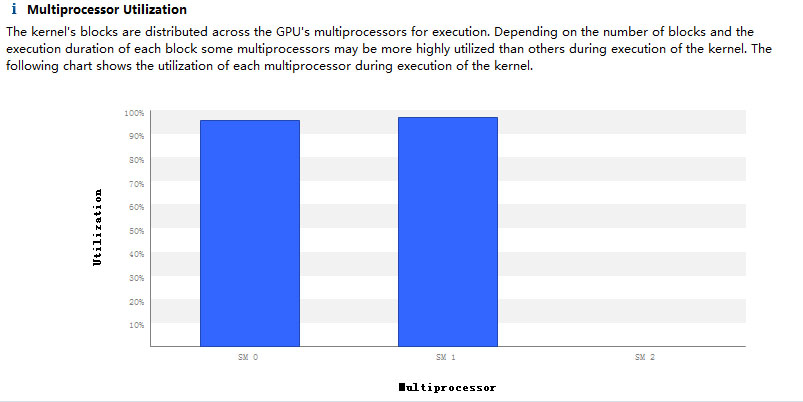
一共就3个SM,两个Thread block用了两个,说明Thread block在分配SM的时候是首先挑选空余的SM来运行,并没有两个Thread block运行到一个SM的情况。
mykernelfunc <<< 4, 1>>> ();这个有4个Thread block,显然3个SM不够分,肯定多出来一个。
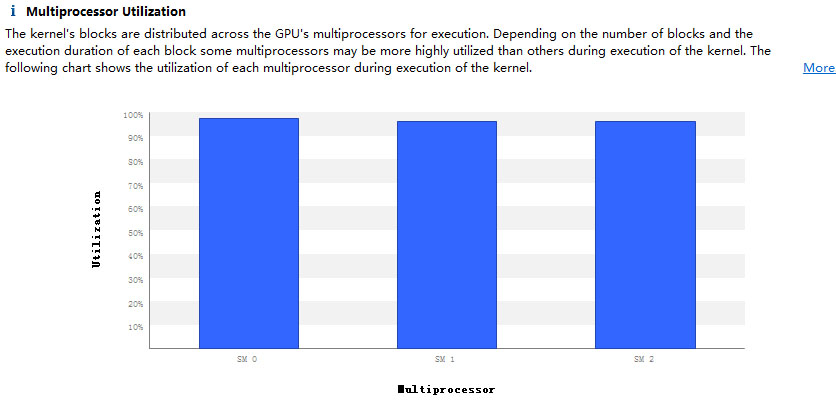
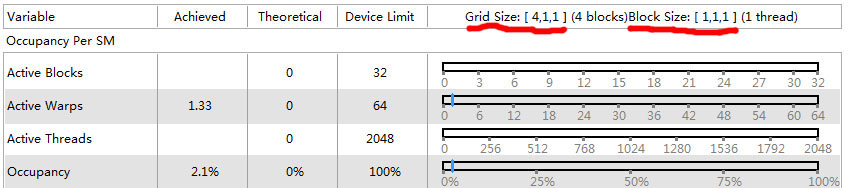
从上图能看出来,三个SM已经全部被占用了,平均下来每个SM有1.33个warp,说明多出来的那个warp,已经被分配进某个SM里面。
这个取4个thread block分到3个SM,不好分,我们换个:
mykernelfunc <<< 96, 64>>> ();
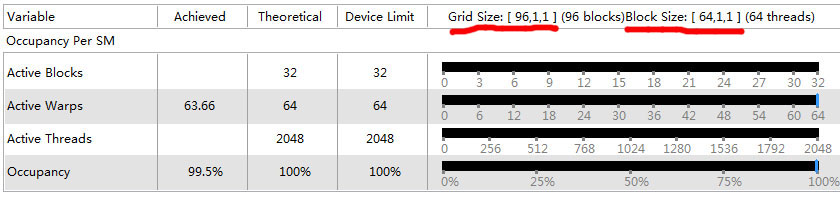
这里取了96个thread block,分到3个SM里,每一个可以分到32个,64表示64个线程,这样一共是64个warp,已经达到硬件极限了,理论上达到100%的硬件占用率,实际测试达到99.5%的Occupancy.
但是如果使用了shared memory,情况就会有很大的不同。

这里分配了24k的共享内存,但实际的warp就降到了24个。
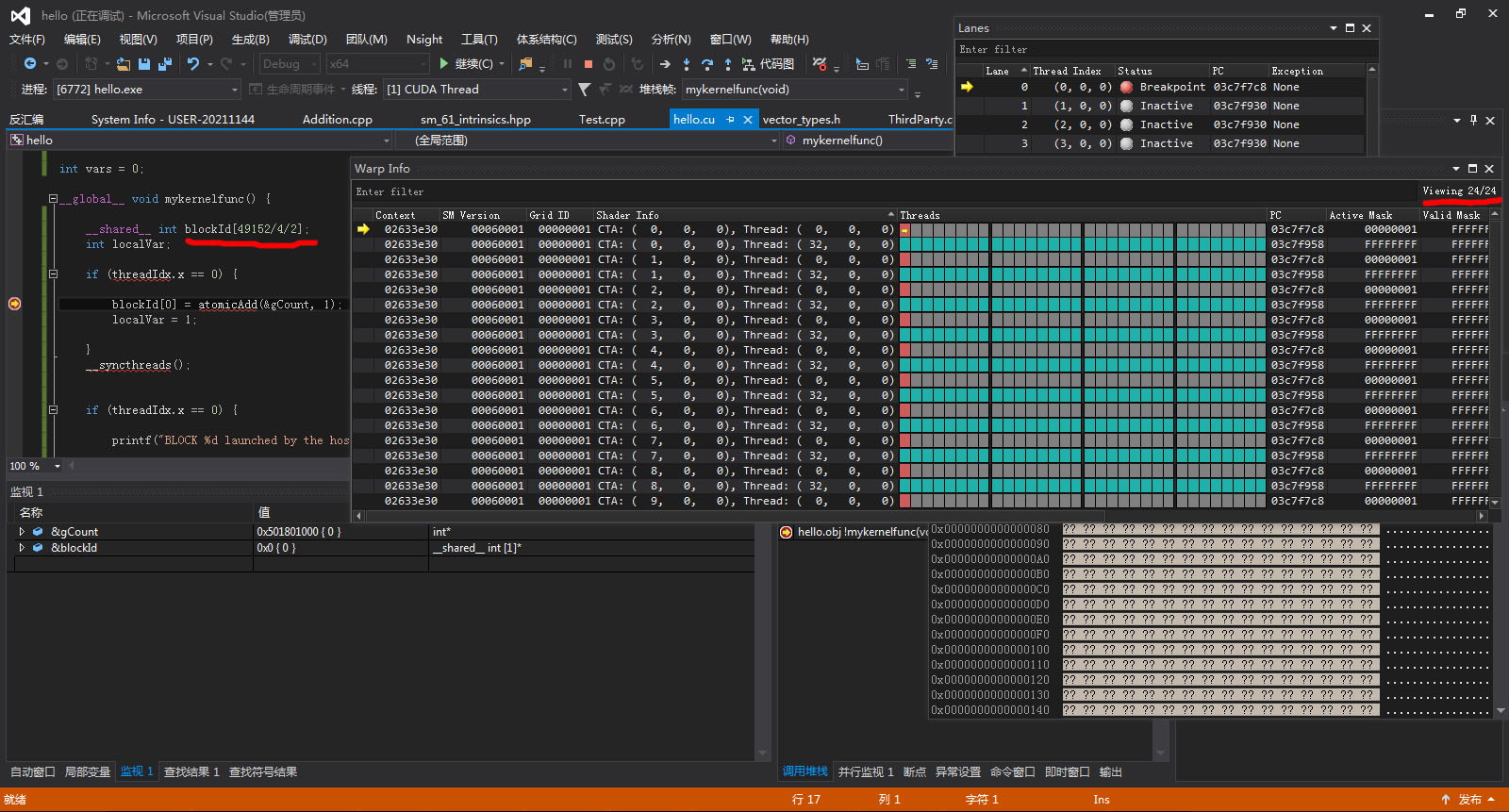
仔细看上面关于GPU utility的说明,这里其实是关键所在,kernel代码使用了24k的shared memory,而每个SM的最大shared memory是96k,正好是4倍,而运行的Thread block数目也是4个,这说明什么?这说明,Thread block在分配SM的时候,首先参考kernel中使用的shared memory的大小,整个SM的shared memory能装下几个kernel的shared memory就使用几个Thread block,这其实是make sense的,因为kernel占用的shared memory属于硬件要求,不满足自然无法运行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号