
第一次个人编程作业
第一次个人编程作业
| 这个作业属于哪个课程 | 2023软件工程-双学位(广东工业大学-计算机学院) |
|---|---|
| 这个作业的要求在哪 | 个人项目作业-论文查重 |
| 这个作业的目标 | 论文查重算法代码实现、性能分析、单元测试; 使用PSP表格进行项目管理 |
目录
代码地址
本次作业代码已上传至个人Gitcode代码仓库:Gitcode代码仓库
所使用的模块接口
本次作业所使用编程语言为Python,所使用编译环境为PyCharm Community Edition 2022.3.2,并使用如jieba、gensim、viztracer等库以使编码更为简便,所使用第三方库及其版本号请以gitcode代码仓库中equipment.txt文件所述为准。
一、jieba库
jieba,是中文“结巴”一词的拼音,是支持Python的优秀中文分词第三方库。它通过内置的中文词库,能高效地确定汉字之间的关联概率,并将其中概率较大者组成词组,形成分词结果。
本次作业当中使用库中最为常用的精确模式进行分词,接口为jieba.lcut(),实例如下:
import jieba
print(jieba.lcut("中国是一个伟大的国家"))
# 注意,此处"lcut"表示将分词结果以列表的形式输出
以上实例输出结果:
['中国','是','一个','伟大','的','国家']
二、re库
re库是Python的标准库,用于正则表达式匹配,也可应用于字符串匹配中。本次作业中应用python中re库接口re.match以去除待查重文本中的标点符号及转义字符,并保留剩余的文本信息,其实例如下:
re.match(pattern, string, flags=0)
函数接口参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等 |
| 匹配成功 re.match 方法返回一个匹配的对象,否则返回 None。 |
三、Gensim库
经查找资料分析,本次作业中采用计算余弦相似度的方法来比较两篇带查重文章的相似程度。而在经过试错与资料翻阅后,笔者放弃了采用python的math来直接进行余弦函数计算,转而使用第三方的Gensim库中封装的Doc2Vec模型来进行向量生成与余弦相似度的计算,具体所用接口为gensim.corpora.Dictionary()与gensim.similarities.Similarity(),前者可将文本中的词组构建为字典并生成对应词组出现频率的向量,后者可用于实现余弦相似度的计算,在本次作业中所编写函数如下:
def similarity_calc(text1, text2):
texts=[text1,text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
test_corpus_1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
代码实现及结果
综上所述,本次个人项目——论文查重程序的代码实现如下:
import jieba #所用库声明
import re
import gensim
def filter(str): # 分词过滤函数
str = jieba.lcut(str) # lcut生成分词后的列表
result = []
for tags in str: #过滤特殊符号
if (re.match(u"[a-zA-Z0-9\u4e00-\u9fa5]", tags)):
result.append(tags)
else:
pass
return result
def similarity_calc(text1, text2): #余弦相似度计算函数
texts=[text1,text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
test_corpus_1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
def main(): #主体函数
print("注意:输入地址时无需双引号!")
path1 = input("请输入文件1的绝对路径:") # 文件路径键入,可手动输入待比较文件的绝对地址
path2 = input("请输入文件2的绝对路径:")
answer_save = input("请输入答案文件将要输出的完整绝对路径(路径以answer_save.txt结尾):") #键入答案文件输出地址,并命名答案文件
str1 = get_file(path1)
str2 = get_file(path2)
text1 = filter(str1)
text2 = filter(str2)
similarity = similarity_calc(text1, text2)
print("两文件文本相似度为: %.4f"%similarity)
f = open(answer_save, 'w', encoding="utf-8") #撰写答案文件answer_save
f.write("两文件文本相似度为: %.4f"%similarity)
f.close()
if __name__ == '__main__':
main_test()
籍由本次作业要求给出的测试文本,可给出代码运行结果如下:
1.orig.txt与orig_0.8_add.txt
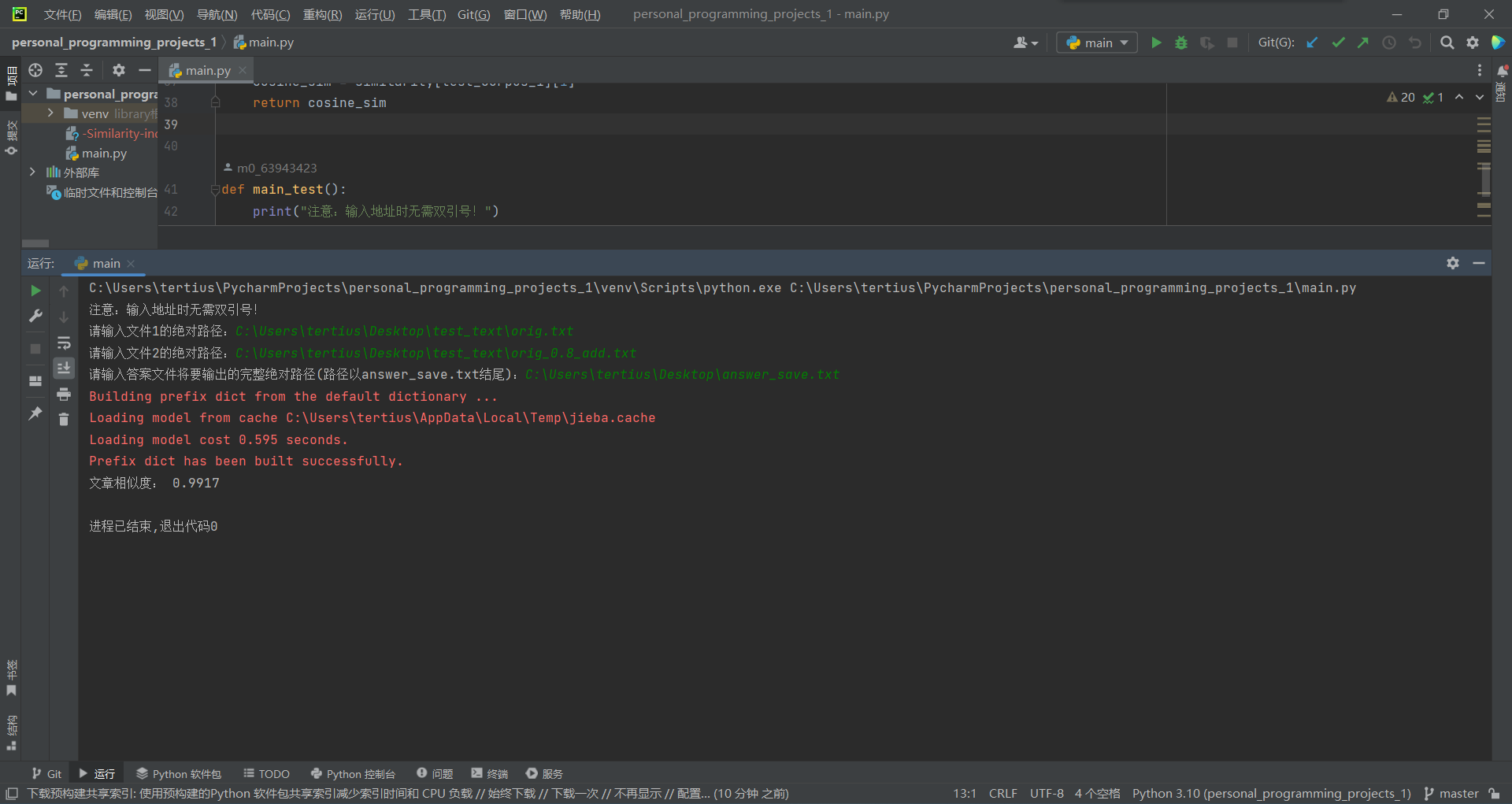
由此证明两文件相似程度较高。
2.orig.txt与orig_0.8_dis_10.txt
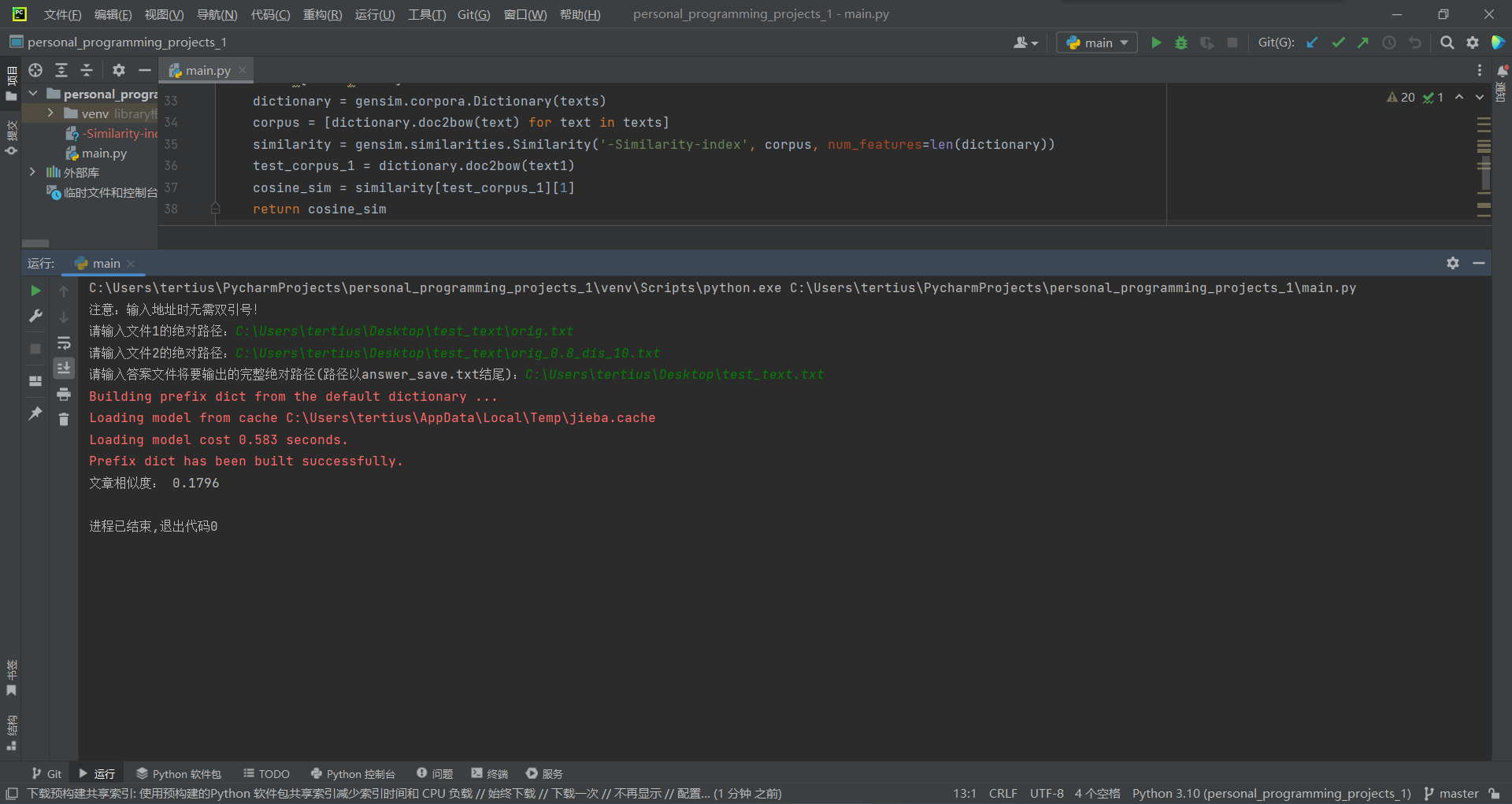
由此证明两文件相似程度较低。
综上,可认为该程序可基本实现作业需求中的功能。
性能分析与改进
由于本次作业使用编程环境的PyCharm Community Edition 2022.3.2并未搭载专业版所自带的图形化性能分析工具,本次作业所设计程序使用了由国人开发的第三方性能分析调试工具——VizTracer进行。
在进行性能分析之前,首先修改主函数main的部分代码如下:
path1 = "E:\学习\软件工程\软件工程作业\软工第二次作业-论文查重\test_text\orig.txt"
path2 = "E:\学习\软件工程\软件工程作业\软工第二次作业-论文查重\test_text\orig_0.8_dis_10.txt"
answer_save = "E:\学习\软件工程\软件工程作业\软工第二次作业-论文查重\test_save"
更改main函数读取测试文本地址的方式,由手动输入改为自动读取,此举是为了防止因人工输入地址而导致程序运行时间出现误差。另存为修改后的用于测试的程序文件为test_main.py。
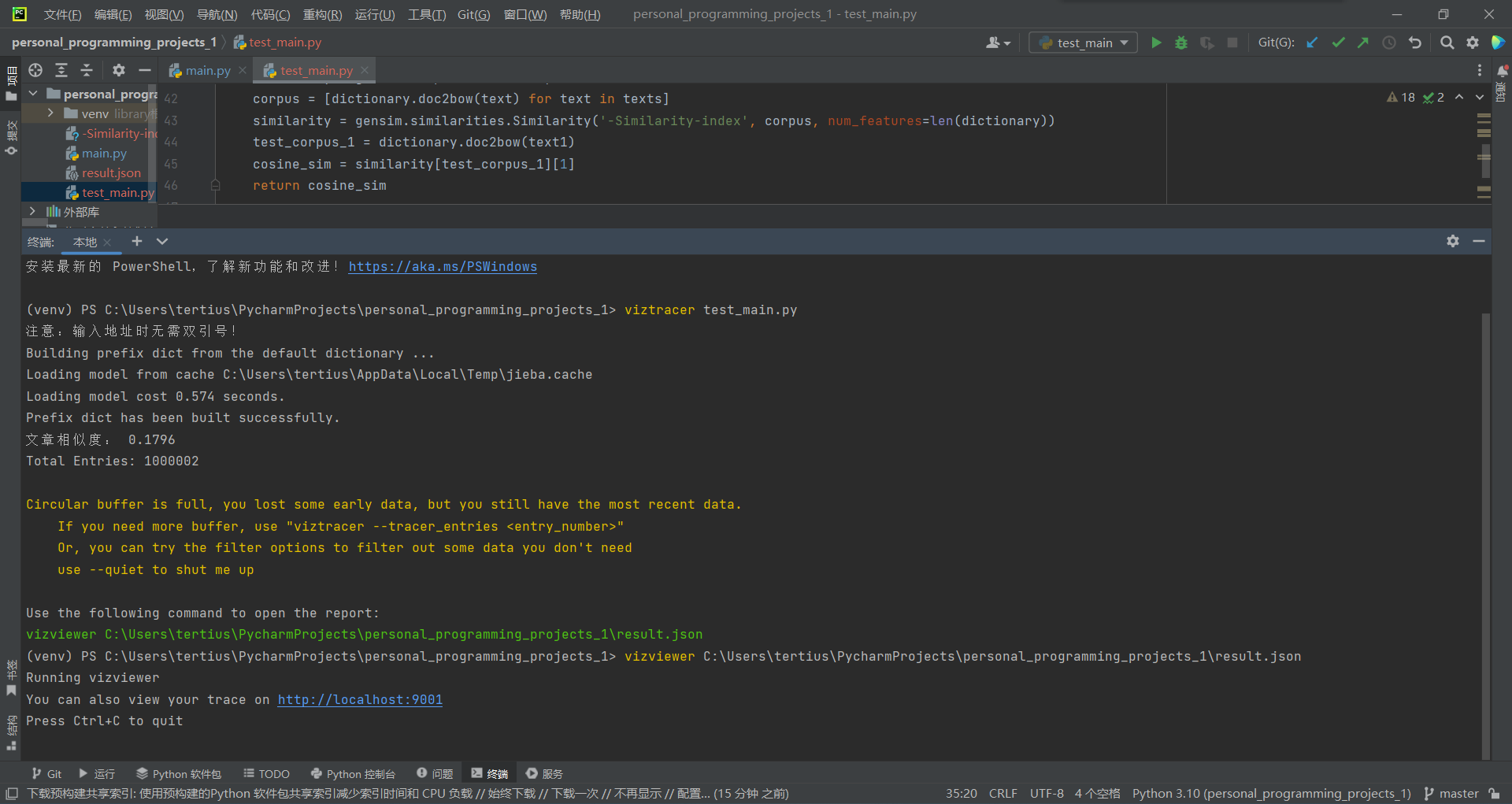
如上图,在Pycharm界面使用终端命令viztracer main.py即可使程序在VizTracer的监控下运行,此时已经可在界面上看到明显的程序总运行时间与调用函数次数,此时再使用命令:
vizviewer C:\Users\tertius\PycharmProjects\personal_programming_projects_1\result.json
即可打开如下图所示的可视化程序性能火焰图;
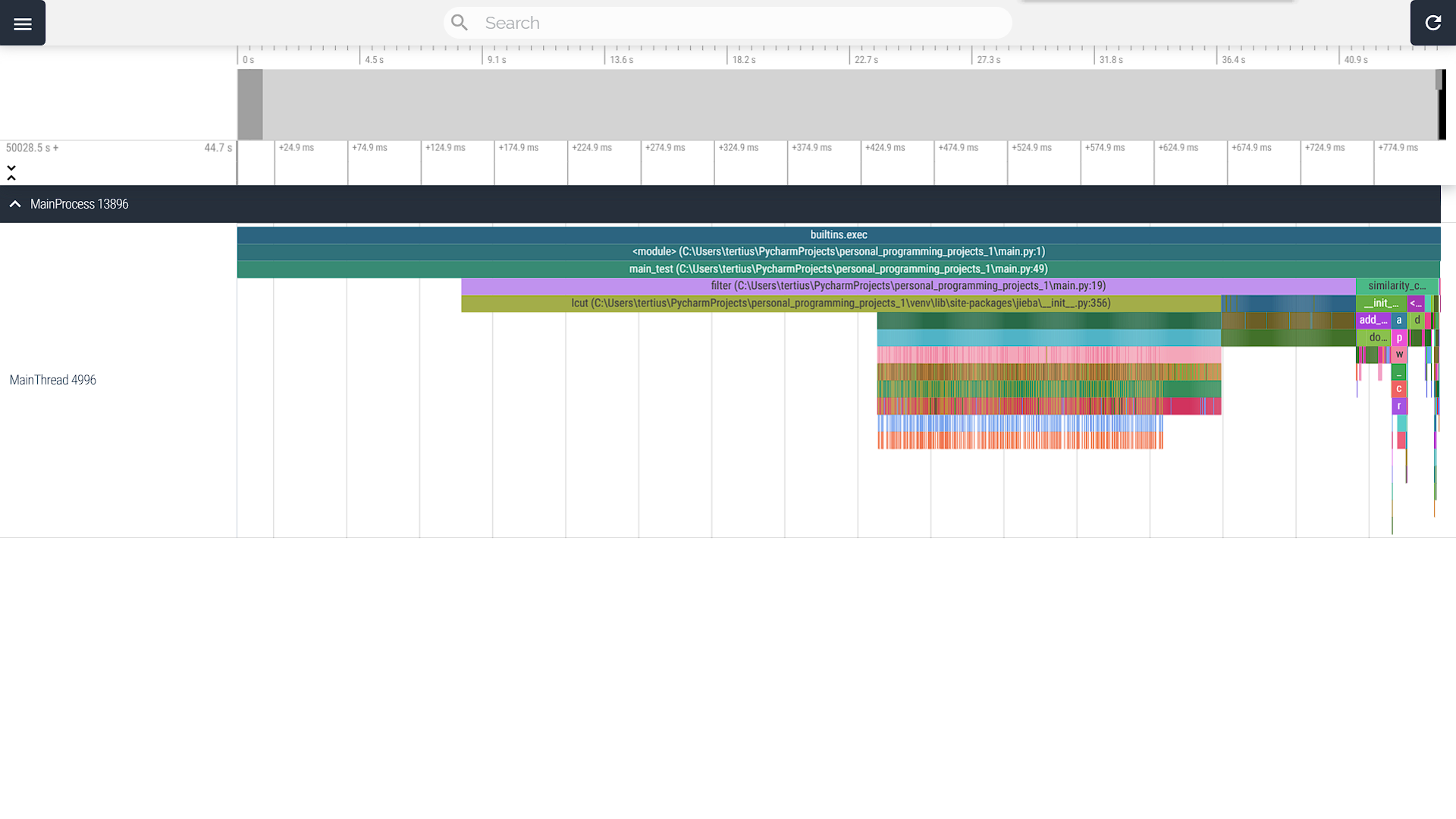
由阮一峰老师所著博客——如何读懂火焰图可知火焰图的读解方法。将图片适当拉伸可注意到图中除主函数main_test外占用运行时间最长的两个函数(按占用时间长度从大到小排序):filter、similarity_calc。
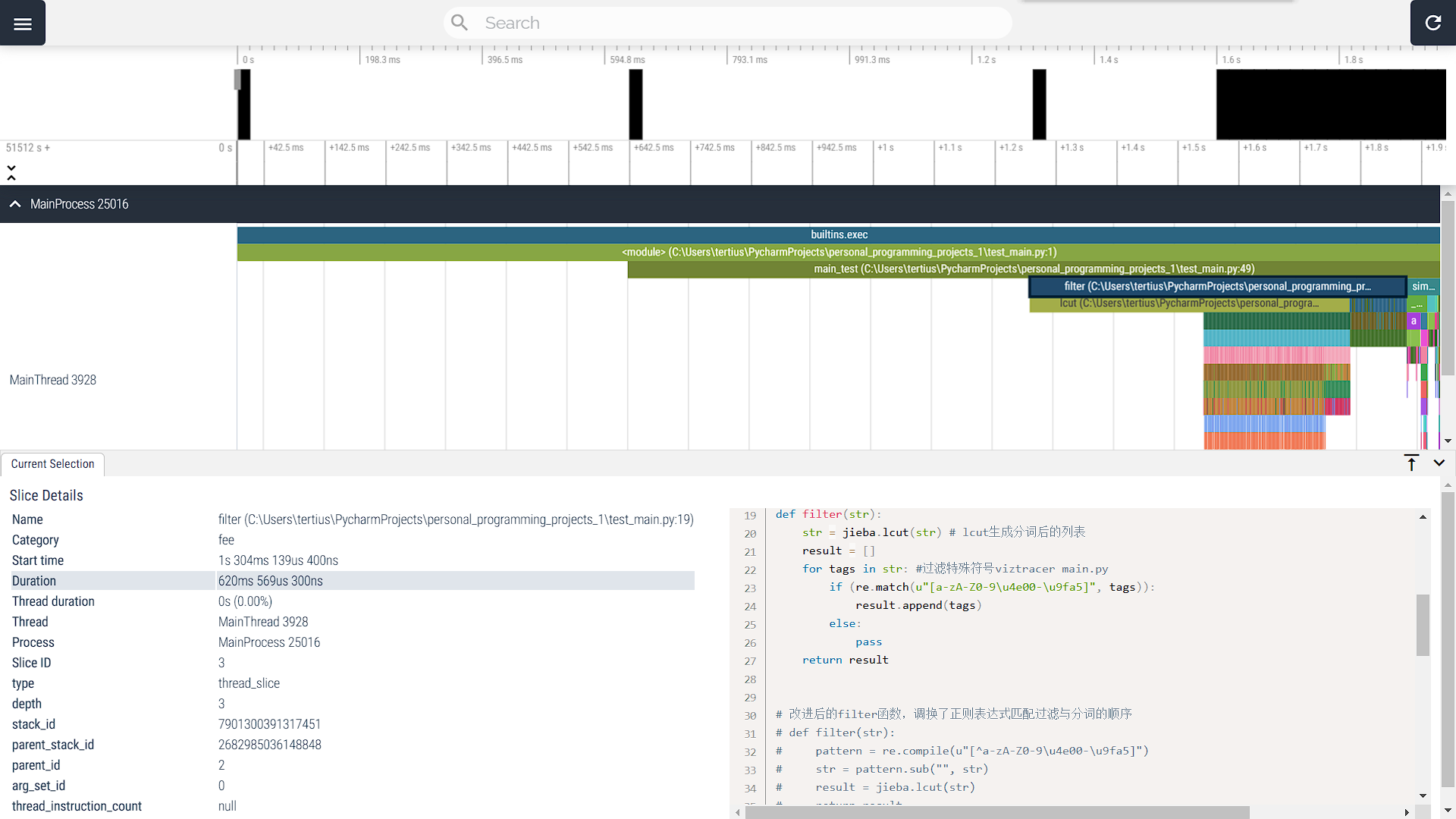
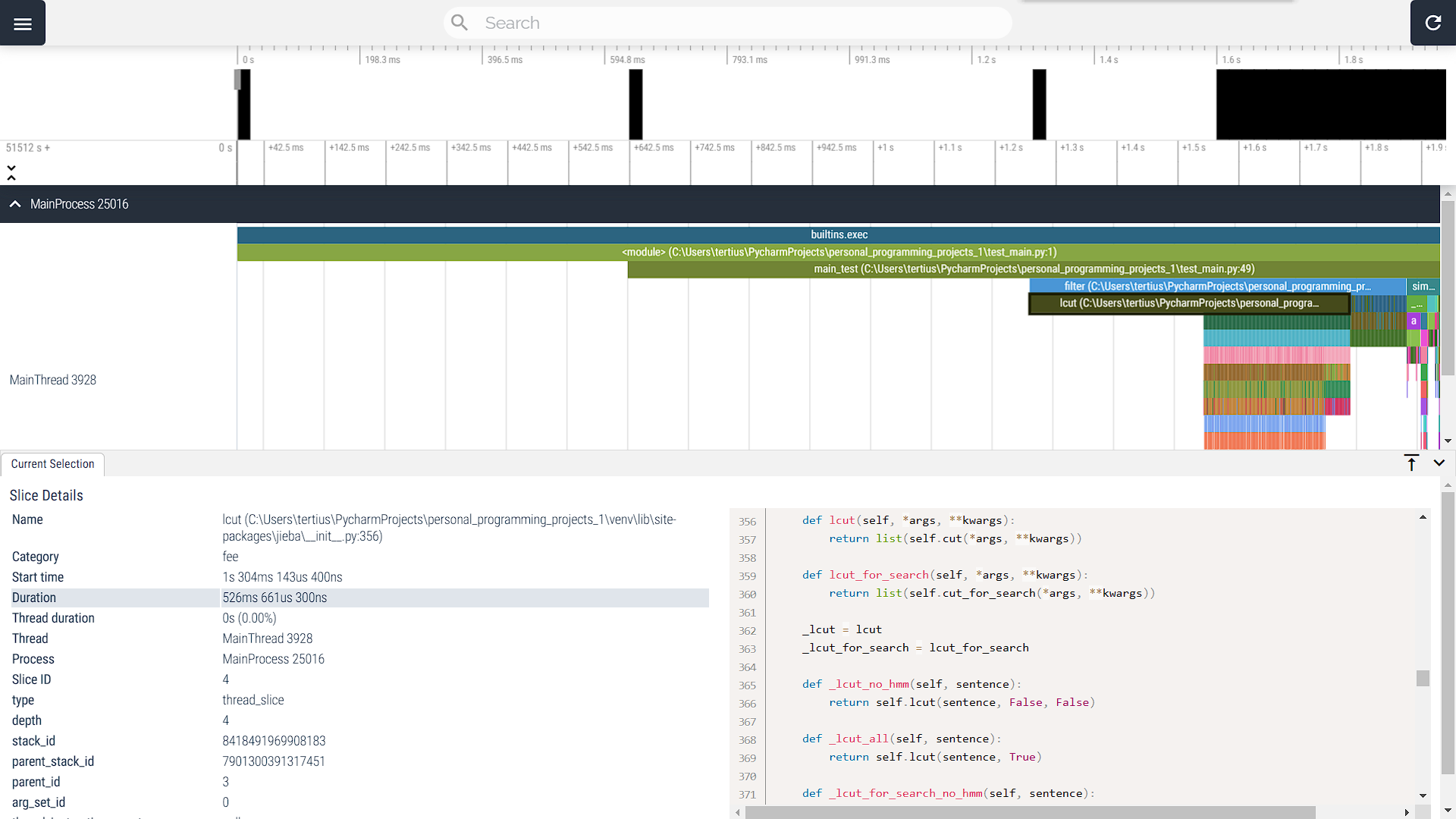
其中,对于similarity_calc函数,由于其内部存在对于gensim库的复杂调用,在尽可能保证程序完整性而不报错的前提下,笔者决定不对其进行修改。另一方面,对于filter函数,可明显看到其中对于lcut的调用占用时间较大(486ms704μs700ns),然而,由于此语句调用的jieba库本身性能如此,暂时无法进行进一步改进。在查阅资料后得知,可以对正则表达式匹配进行改进,预想如下:
def filter(string):
pattern = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]")
string = pattern.sub("", string)
result = jieba.lcut(string)
return result
预想通过调换正则表达式匹配过滤与lcut的顺序来缩短处理时间;完成更改后,以主函数main运行时间为基准进行比较如下:(上图为改进前,下图为改进后)
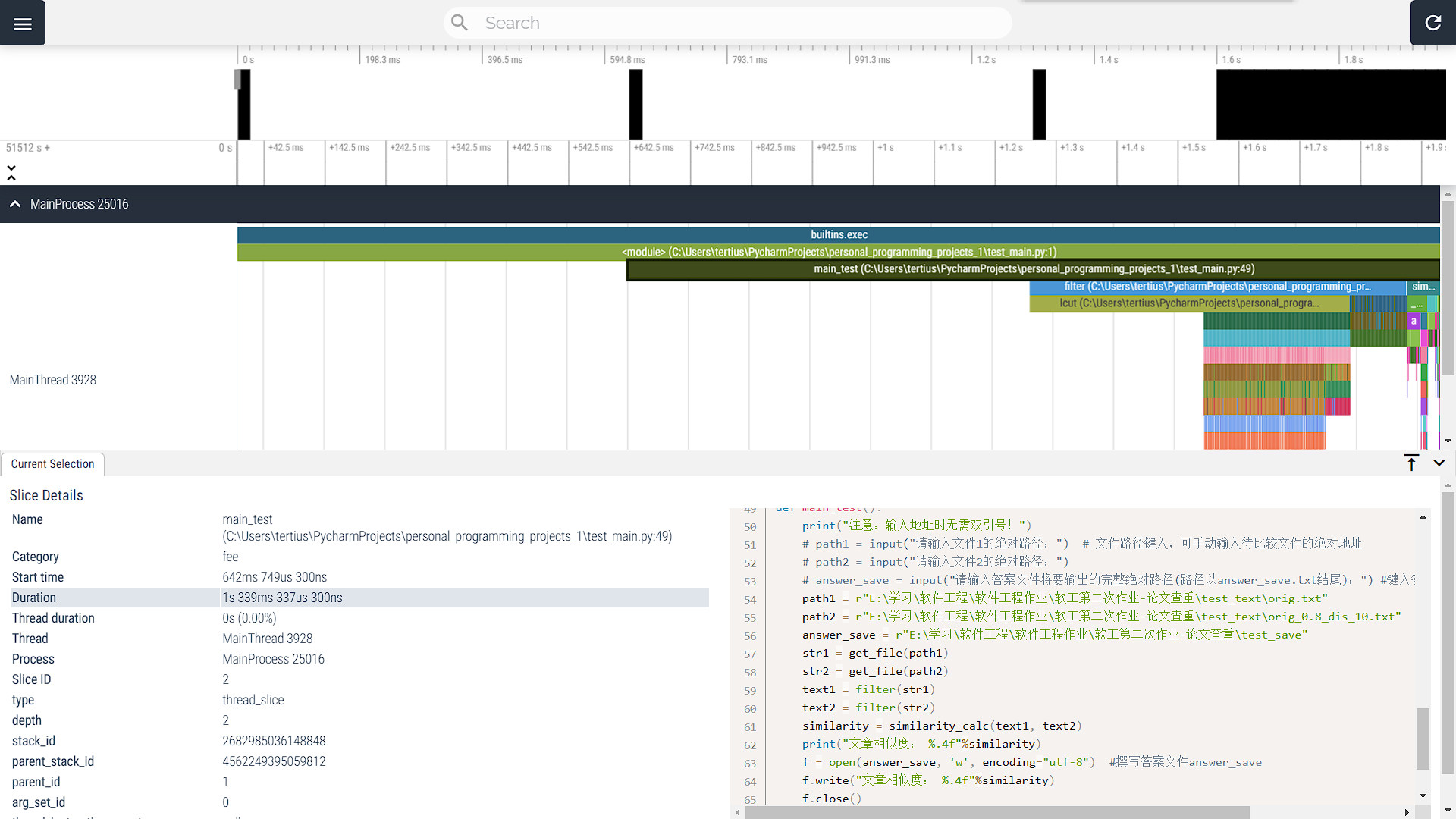
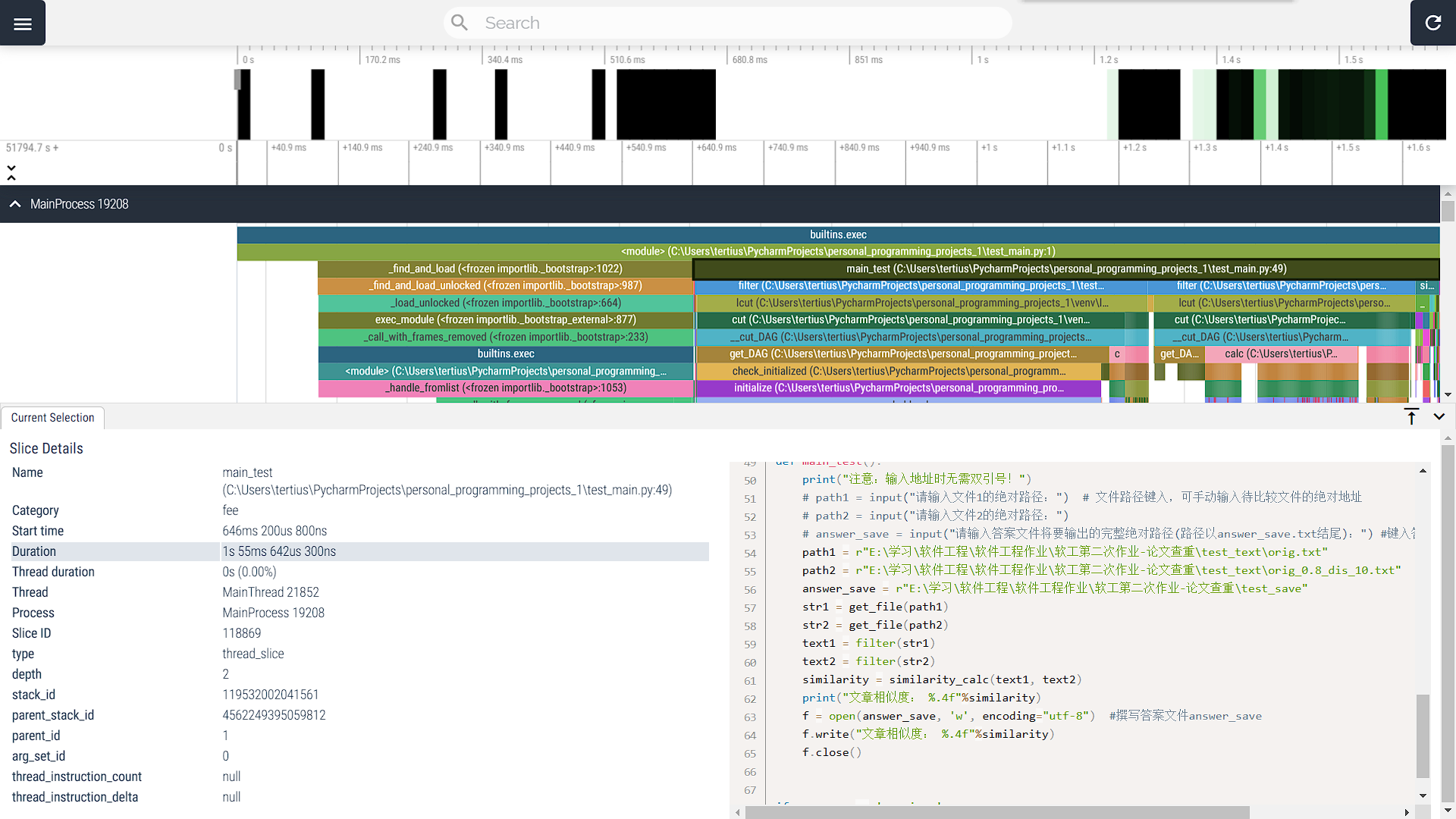
由上两图可知,改进前main整体函数运行时间为1s339ms337μs300ns,改进后main整体函数运行时间为1s55ms642μs300ns,总耗时明显缩短,证明改进有效。
单元测试展示
参照作业要求所给资料即邹欣老师的博客,以及上网查阅python单元测试相关资料后,决定采用unittest框架进行测试。因此,按要求修改main函数部分代码如下:
def main_test():
path1 = input("请输入文件1的绝对路径:")
path2 = input("请输入文件2的绝对路径:")
str1 = get_file(path1)
str2 = get_file(path2)
text1 = filter(str1)
text2 = filter(str2)
similarity = similarity_calc(text1, text2)
result=round(similarity.item(),2)
return result
此处为便于确定预期值,将借助round(flout,2)来使返回的相似度值只去到小数点后2位,且由于生成的similarity类型为<class 'numpy.float32'>,应使用xxx.item()将其转换为<class 'float'>类型。
新建Python单元测试文件,代码如下:
import unittest
from test_main import main_test
class MyTestCase(unittest.TestCase):
def test_something(self):
self.assertEqual(main_test(),0.99)
if __name__ == '__main__':
unittest.main()
取代码实现及结果一节中的相同样本进行测试,结果如下:
1.orig.txt与orig_0.8_add.txt
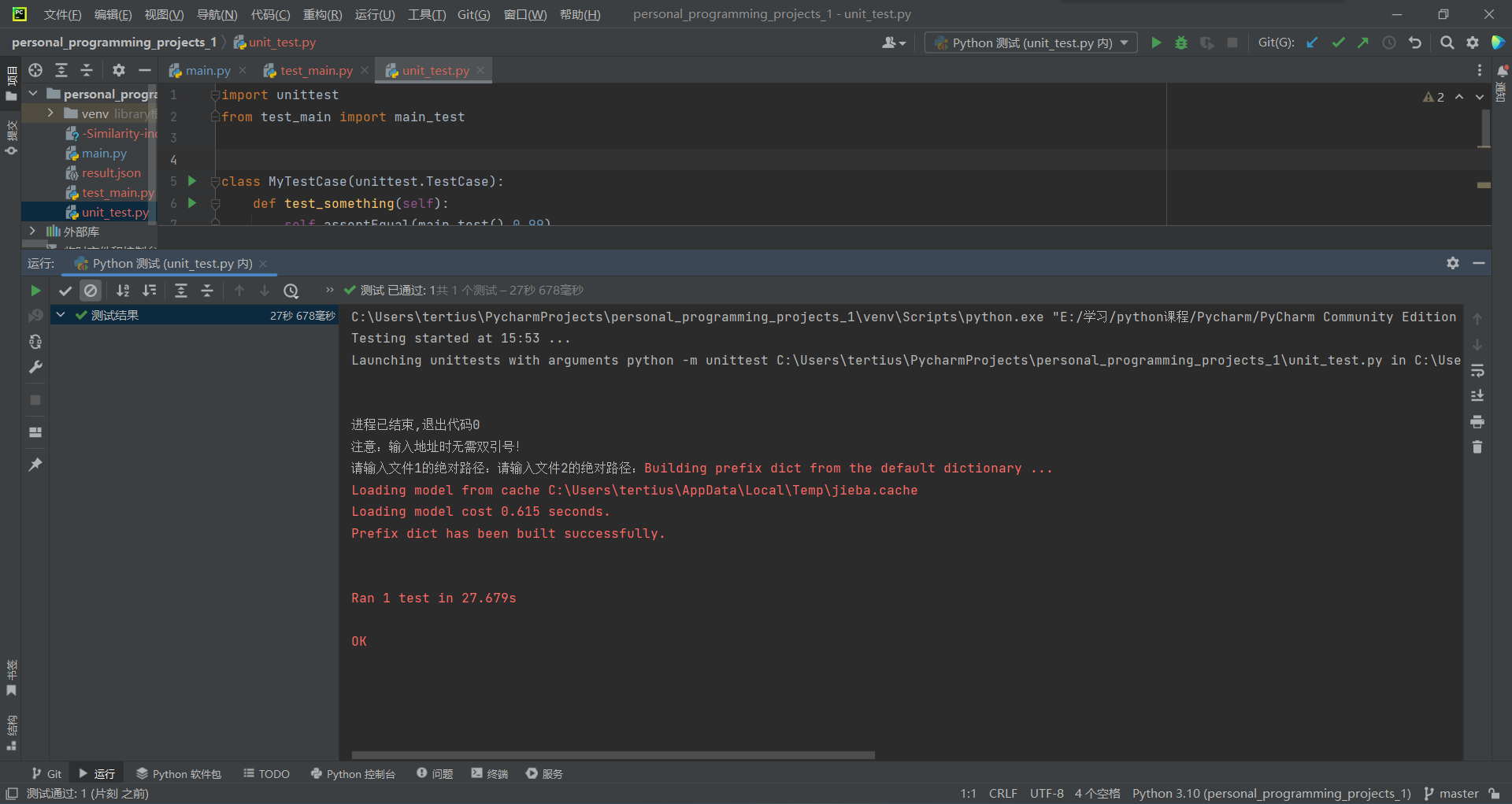
由上图可知,在预测值为0.99的情况下,测试结果预测正确,程序通过测试。更换样本为第二组,并保持预测值不变进行测试;
2.orig.txt与orig_0.8_dis_10.txt
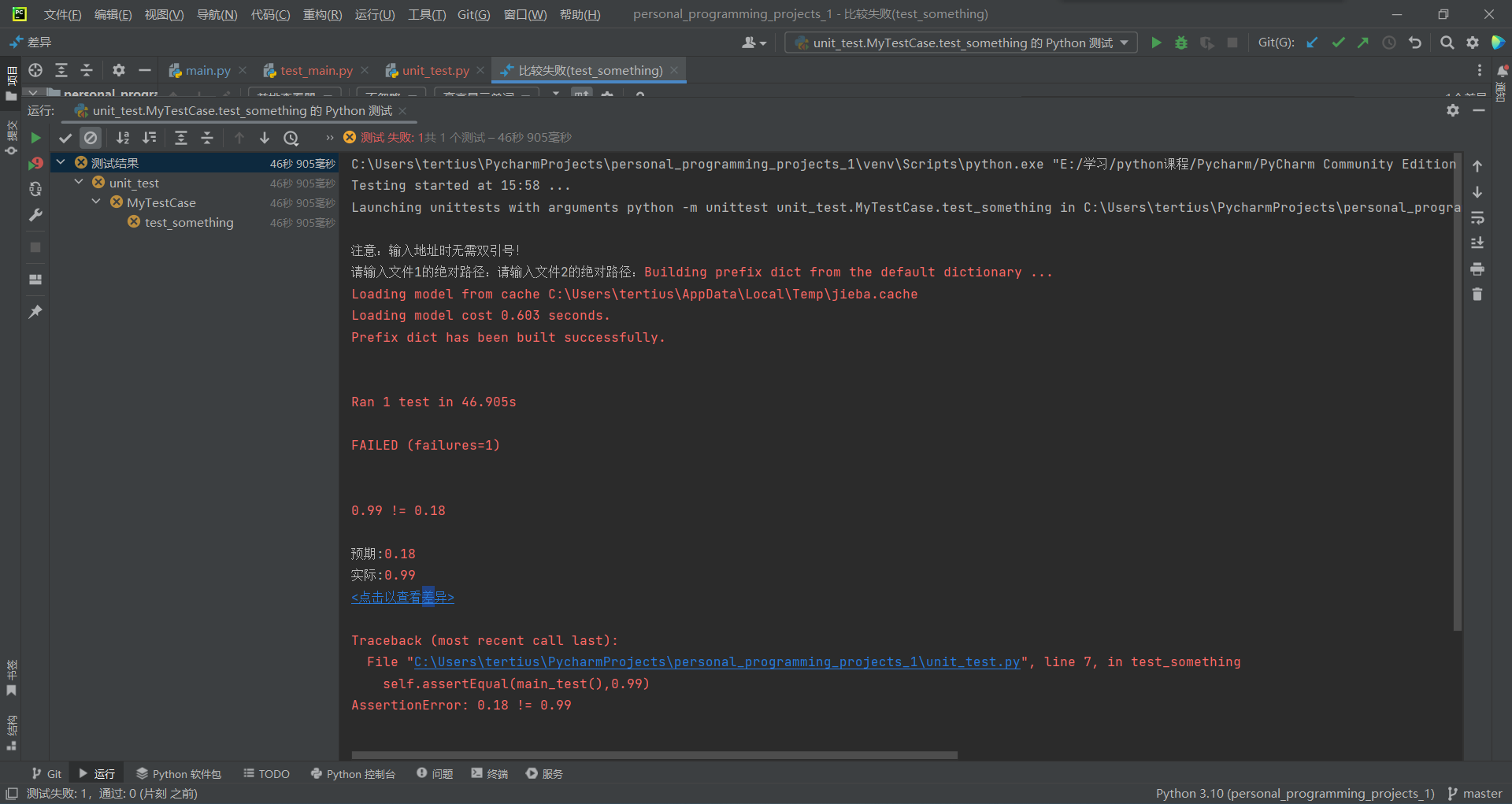
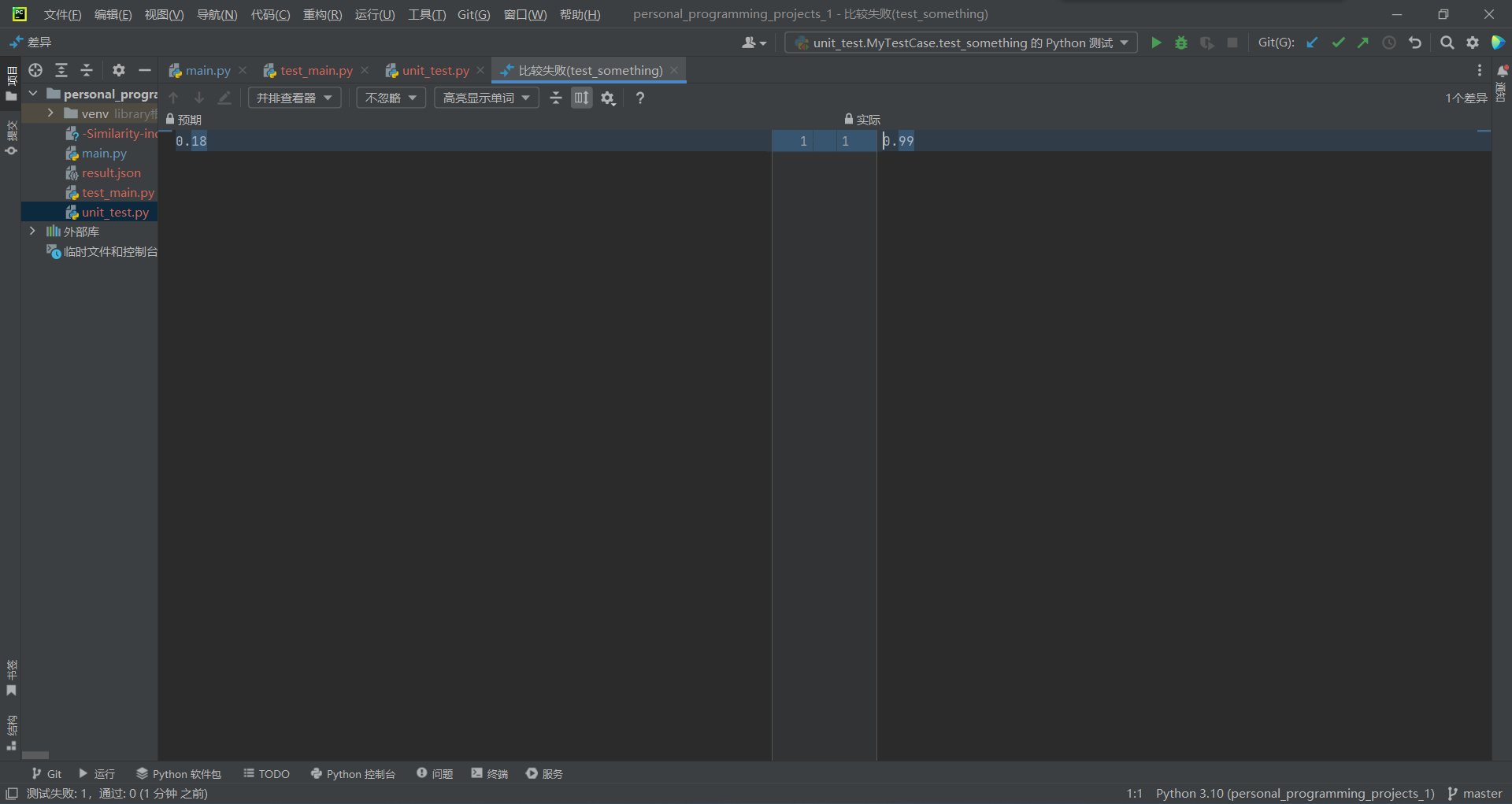
由上两图可知,在预测值仍然为0.99的情况下,测试结果预测失败,测试通过。
异常处理
1.计算相似度异常
在性能分析与改进一节中,针对filter()函数耗时较长的问题,笔者曾对其中的正则表达式匹配进行改进,但是经过反复测试后发现,该函数经过改进后,可能会对余弦相似度的计算结果产生影响,从而导致计算结果准确性存疑,为此,考虑到改进前后性能改进的程度并不大的情况下,最终笔者考虑将filter()函数回滚至最初版本。
2.文件地址输入异常
在本次作业的程序中,倘若所输入的文件绝对地址有误,程序将会出现异常,因而应在程序读取文件内容之前判断待读取文件地址是否存在、正确,若出现异常应自动切断程序运行。
故对main函数代码修改如下:
import os
def main():
print("注意:输入地址时无需双引号!")
path1 = input("请输入文件1的绝对路径:") # 文件路径键入,可手动输入待比较文件的绝对地址
path2 = input("请输入文件2的绝对路径:")
if not os.path.exists(path1): #检测输入的文件路径是否存在,不存在即输出报错
print("文件1不存在!")
exit()
if not os.path.exists(path2):
print("文件2不存在!")
exit()
answer_save = input("请输入答案文件将要输出的完整绝对路径(路径以answer_save.txt结尾):") #键入答案文件输出地址,并命名答案文件
str1 = get_file(path1)
str2 = get_file(path2)
text1 = filter(str1)
text2 = filter(str2)
similarity = similarity_calc(text1, text2)
print("两文件文本相似度为: %.4f"%similarity)
f = open(answer_save, 'w', encoding="utf-8") #撰写答案文件answer_save
f.write("两文件文本相似度为: %.4f"%similarity)
f.close()
引入os模块,使用os.path.exists()函数来检测输入的文件路径是否有效即可。
附录
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(min) | 实际耗时(min) |
|---|---|---|---|
| Planning | 计划 | 120 | 120 |
| ·Estimate | 估计这个任务需要多少时间 | 120 | 120 |
| Development | 开发 | 1345 | 1685 |
| ·Analysis | 需求分析 (包括学习新技术) | 300 | 360 |
| ·Design Spec | 生成设计文档 | 60 | 80 |
| ·Design Review | 设计复审 | 120 | 180 |
| ·Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 55 |
| ·Design | 具体设计 | 120 | 150 |
| ·Coding | 具体编码 | 400 | 520 |
| ·Code Review | 代码复审 | 45 | 60 |
| ·Test | 测试(自我测试,修改代码,提交修改) | 240 | 280 |
| Reporting | 报告 | 210 | 240 |
| Test Report | 测试报告 | 120 | 110 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 100 |
| Total | 合计 | 1675 | 2045 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号