Redis 实战应用方案
一、经典面试篇
1.1、Redis 线程架构
1.1.1、Redis是单线程还是多线程?
不同版本,不同架构,不同情况。
- Redis 3.x ,单线程;
- Redis 4.x,引入多线程备份、异步删除等功能,但仍使用单线程处理客户端请求;
- Redis 6.x+,引入多IO线程处理网络请求,后台异步线程处理RDB、AOF、异步删除、集群同步等,但读写操作命今仍使用单线程。
1.1.2、Redis 的读写请求为啥不采用多线程?
影响 Redis 性能的主要三个因素:
- 机器的内存
- 网络带宽
- CPU
由于 Redis 是基于内存的,应用程序主要使用 O(N) 或 O(log(N) ) 命令,不会过多使用CPU,因此 CPU 不是瓶颈,也就没必要引入 多线程。引入多线程反而会增加 不必要的上下文切花 和 多线程竞争问题。
单线程也更容易保持 执行命令的 顺序性。
1.1.3、Redis 为啥要引入多线程?
-
Redis 6.x 之前引入多线程主要是处理:
- RDB备份、
- AOF处理、
- 大key删除、
- 集群同步
为了不使处理 读写请求 的线程处理过多的事情,导致 Redis 性能下降。
-
Redis 6.x 之后,还使用多线程处理了 socket 的读、写。
Redis 处理客户端的请求过程包括:获取(socket 读)、解析、执行、内容返回(socket 写) ,高并发下 socket 读、写的阻塞也是 Redis性能的瓶颈。
1.1.4、Redis为什么那么快?
不同版本,不同架构,不同情况。
-
Redis 3.x
- 基于内存;
- 数据结构简单(大部分查找和操作的复杂度都是 0(1));
- 使用多路复用和非阻塞 I/O监听多个 socket客户端,减少线程切换开销;
- 单线程处理连接和读写请求,避免不必要的上下文切换和多线程竞争。
-
Redis 4.x
- 引入多线程实现数据异步惰性删除等功能。
- unlink key、
- flushdb async、
- flushall async
- 引入多线程实现数据异步惰性删除等功能。
-
Redis 6.x +
网络硬件的性能提升使单个主线程处理网络请求的速度跟不上底层网络硬件的速度,网络IO成为 Redis 的性能瓶颈。- 采用多IO线程处理网络请求(IO多路复用+epoll函数使用),将最耗时的Socket的读取、请求解析、写入 独立出来。
- 多 IO线程 只用来处理网络请求,对于读写操作命今 Redis 仍然使用单线程。
- 使用单线程执读写,就不必为了保证Lua脚本、事各的原子性,额外开发多线程。
- O多路复用+epoll函数,避免了处理过程中数据从 内核态 到 用户态 的拷贝,减少了主线程的网络IO阻塞时间。
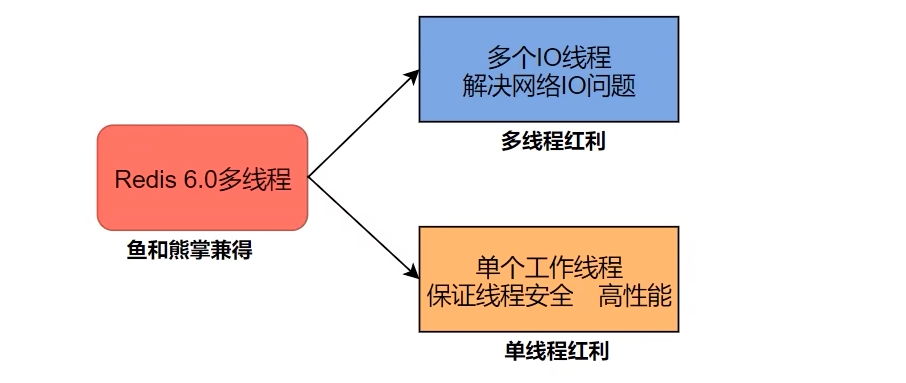
- 采用多IO线程处理网络请求(IO多路复用+epoll函数使用),将最耗时的Socket的读取、请求解析、写入 独立出来。
1.1.5、多IO线程处理网络请求大致过程



1.2、 Redis bigkey 文件
1.2.1、多大算 bigkey,怎么发现 bigkey?
- bigkey 定义
- string 类型:value 大于等于 10KB
- list、hash、set 和 zset类型:value 个数超过5000
- bigkey 发现
- 使用命令 :redis-cli --bigkey
## --bigkey 是通过 scan 命令实现统计的,建议在 从节点 上执行;
## 若没有从节点,推荐使用 -i xx 参数,则每隔100 条 scan 会休眠 xx秒,虽然增加了扫描时长,但避免了ops剧烈抬升。
redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 0.1
## 返回结果如下
Biggest string found 'user:1' has 5 bytes
Biggest list found 'taskflow:175448' has 97478 items
Biggest set found 'redisServerSelect:set:11597' has 49 members
Biggest hash found 'loginUser:t:20180905' has 863 fields
Biggest zset found 'hotkey:scan:instance:zset' has 3431 members
40 strings with 200 bytes (00.00% of keys, avg size 5.00)
2747619 lists with 14680289 items (99.86% of keys, avg size 5.34)
2855 sets with 10305 members (00.10% of keys, avg size 3.61)
13 hashs with 2433 fields (00.00% of keys, avg size 187.15)
830 zsets with 14098 members (00.03% of keys, avg size 16.99)
## 结果给出了 每种数据结构 top 1 bigkey,同时给出了 每种数据类型 的 键值个数 和 平均大小。
- memory usage
--bigkeys 无法查询出所有 大于10kb 的key,只能用 memory usage 计算每个键值的字节数。
可使用 scan + memory usage 的方式排查 bigkey。
## TODO
- 借助分析 RDB 快照文件的工具
- redis-rdb-tools
- rdb_bigkeys
1.2.2、bigkey 的 产生 和 危害?
- 如何产生?
- 社交类:粉丝数、关注列表等
- 报表类:经年累月的统计等
- 有何危害?
- 造成内存不均,集群迁移困难
- 删除超时
- 网络流量阻塞
1.2.3、针对 bigkey 操作应注意什么?
- 删除操作,不要使用 del
- string 类型:使用 unlink key。
- hash 类型:使用 hscan + hdel。hscan 每次获取适量 field-value,hdel 删除。
- list 类型:使用 ltrim。
- set 类型:使用 sscan + srem。sscan 每次获取适量元素,srem 依次删除。
- zset 类型:使用 zscan + zremrangebyrank。
- 同时要注意 bigkey 过期时间自动删除问题,此删除非异步,也在主线程中。
1.2.4、bigkey 调优
vi redis.conf
## 当 redis 内存达到阈值 maxmemory 并 设置有淘汰策略时,在淘汰键时,是否采用lazy free机制
lazyfree-lazy-eviction no
## 设置有 TTL 的键,过期 redis 清理时 是否采用 lazy free 机制
lazyfree-lazy-expire no
## 针对带有隐式 DEL 键的指令(如:rename),当目标键已存在,redis 会先删除,删除时 是否采用 lazy free 机制
lazyfree-lazy-server-del yes
## 是否在 slave 全量同步master 的RDB文件前,使用异步的 flushall 清理旧数据。
replica-lazy-flush yes
## 是否开启默认的 del 命令异步删除,使其等同于 unlink。
lazyfree-lazy-user-del yes
:wq
1.3、生产上可以使用 keys *吗?如果不可以,该怎么遍历多有key?
- 不可以。keys 命令无分页,会一次查出所有 key 数据,大数据量时会导致Redis服务卡顿、超时、甚至宕机。
- 可以使用 scan 命令。https://redis.com.cn/commands/scan.html
- scan 迭代键
- sscan 迭代 list 中的元素
- hscan 迭代 hash 中的键值对
- zscan 迭代 zset 中的 元素 及其 分值
1.4、如何保证数据库缓存一致性?
- 先更新数据库,再更新缓存(不推荐)
- 先更新缓存,再更新数据库(不推荐)
- 先删除缓存,再更新数据库(不推荐)
- 先更新数据库,再删除缓存(常用)
- 延时双删策略
- 难点在与业务应用中读取数据库和写缓存的时间不好估算,延迟双删的等待时间不好设置。
- 可采用 订阅binlog + 消息队列 大方式保证缓存一致性。
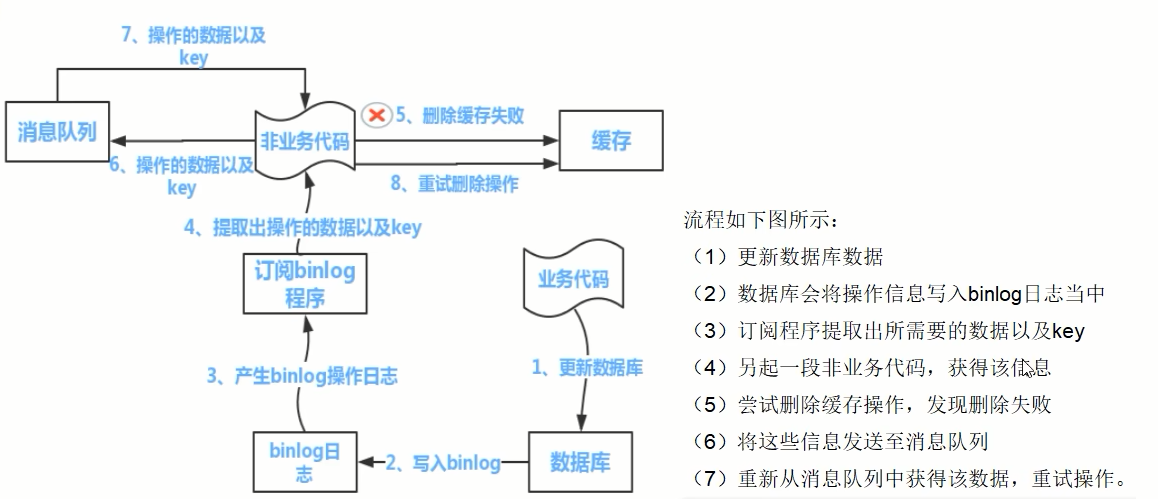
只能保证最终一致性。
参考:
- https://gitcode.com/Romantic-Lei/Learning-in-practice/blob/master/Redis/12.Redis高阶篇/3.缓存双写一致性更新策略探讨/3.数据库和缓存一致性的几种更新策略.md
- https://gitcode.com/Romantic-Lei/Learning-in-practice/tree/master/Redis/12.Redis高阶篇/4.Redis和MySQL数据双写工程落地
1.5、集群架构相关
1.5.1、为什么Redis集群有16384个槽
https://www.cnblogs.com/rjzheng/p/11430592.html
1.6、布隆过滤器
1.6.1、什么是布隆过滤器?
-
是什么?
布隆过滤器由一个初值都为零的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素。 -
能干什么?
- 用于判断具体数据是否存在于一个大的集合中。判断 在,不一定在(哈希冲突);判断 不在,一定不在。
- 用于解决海量数据的去重问题;
- 黑名单校验,识别垃圾邮件。
-
具体是怎么干的?
- 写入数据
- 初始化bitmap,值均为:0;
- 添加数据时,对数据进行多个 hash 函数运算,
再使用得到的多个 hash 值对 位数组长度 进行取模运算,得到一组位置; - 再把 位数组 中对应的这几个位置都置为 1,完成 add 操作。
- 查询数据
- 对查询的数据进行多个 hash 函数运算,
再使用得到的多个 hash 值对 位数组长度 进行取模运算,得到一组位置; - 判断 位数组 中对应的这几个位置是否都为1,
都为1,则可能存在;有一个为0,则必不存在。
- 对查询的数据进行多个 hash 函数运算,
- 写入数据
-
优点
- 能实现数据的高效 插入 和 查询;
- 占用空间少。
-
缺点
- 返回的结果是不确定性;
- 不能删除元素,删除元素会导致误判率增加;
- 当实际元素数量超过初始化数量时,应重建过滤器,重新分配 更大size的过滤器,并将所有历史元素批量add。
1.6.2、布隆过滤器应用?
-
用于判断具体数据是否存在于一个大的集合中。判断 在,不一定在(哈希冲突);判断 不在,一定不在。
-
用于解决海量数据的去重问题;
-
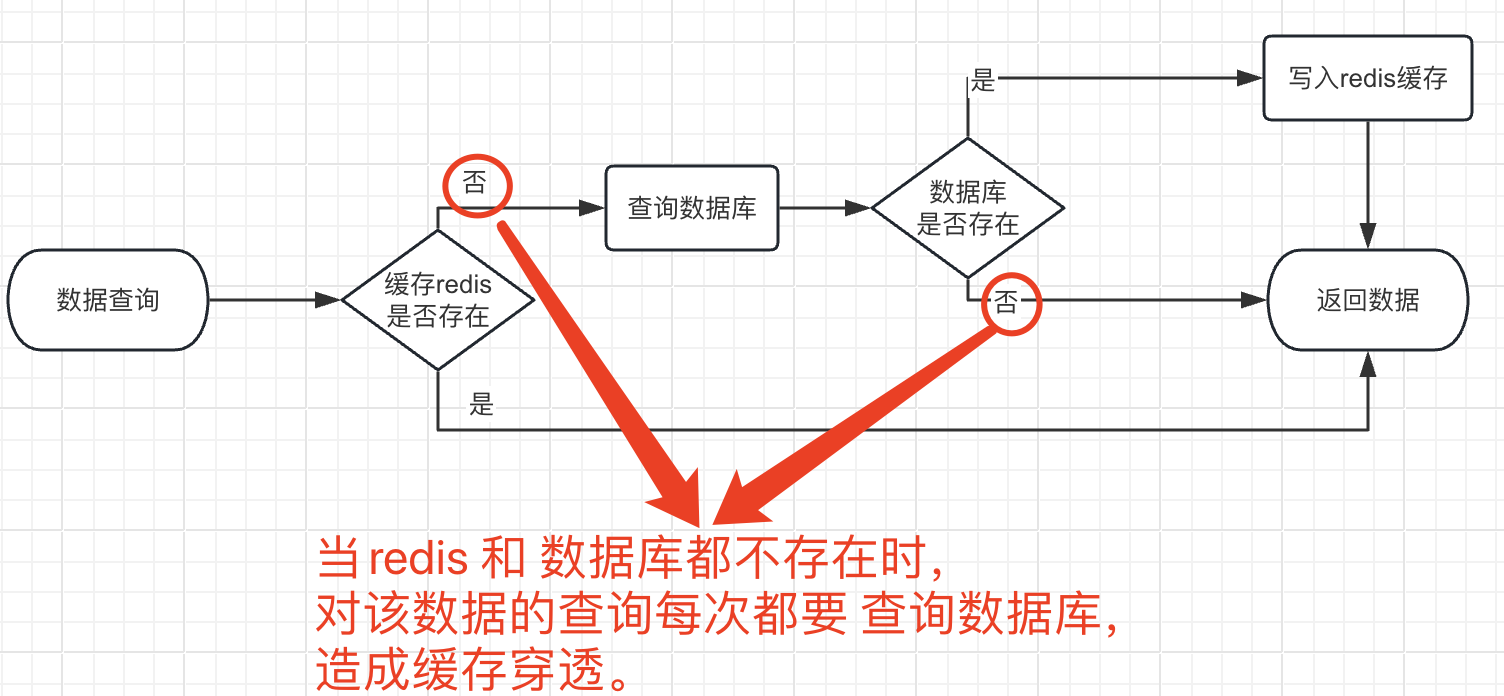
解决缓存穿透问题。
一般查询数据流程:
使用布隆过滤器解决缓存穿透问题。
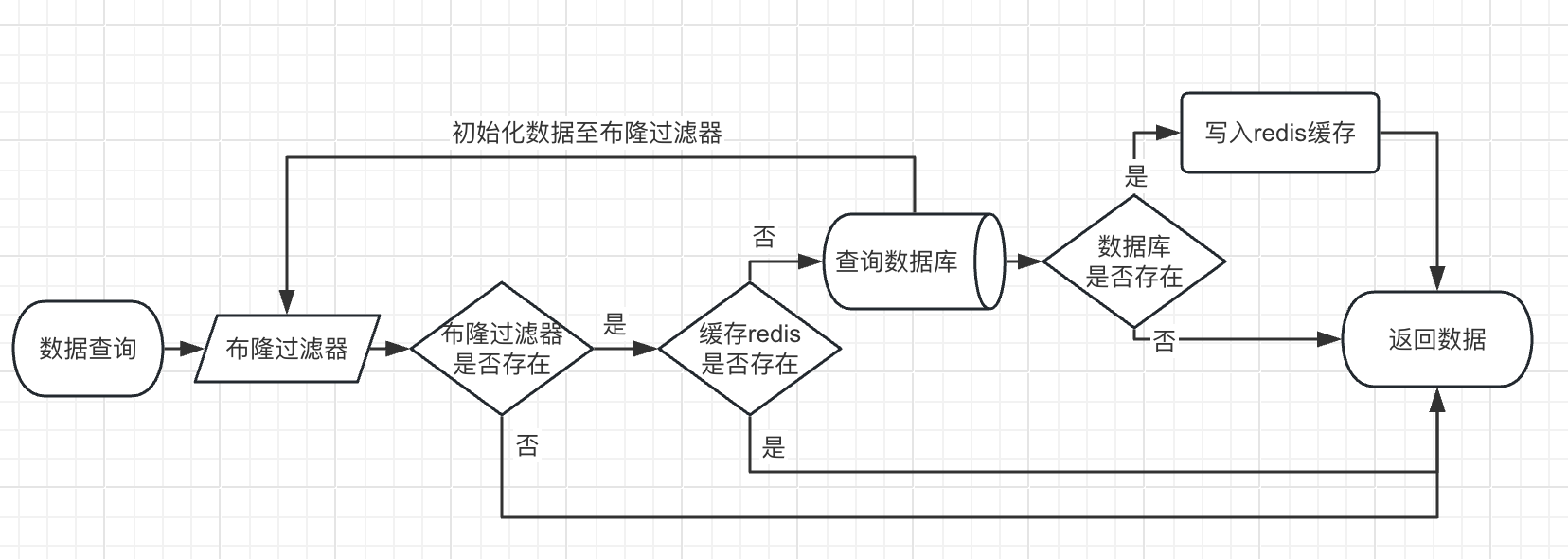
1.6.3、用Redis如何实现布隆过滤器?
二、解决方案篇
2.1、 Redis 分布式锁
- 实现原理
## key 不存在时,新增 并设置 12s 过期时间。成功返回 1,失败返回 0
set key value nx ex 12
- 分布式锁需满足的条件
## 1. 互斥性
## 2. 无死锁
## 3. 解锁 需 加锁对象执行
## 4. 加锁和解锁必须具有原子性
- Java 实现
@GetMapping("tryLock")
public void tryLock() {
// 1. 定义锁的 key 为 资源唯一主键,
String resId = "25";
String lockKey = "lock:" + resId;
// 2. 定义锁的 value 为 uuid,释放锁时进行校验,防止误释放其他线程的锁
String lockValue = UUID.randomUUID().toString();
// 3. 获取锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent(lockKey, lockValue, 10, TimeUnit.SECONDS);
if (lock) {
// 4. 执行业务逻辑开始
Object value = redisTemplate.opsForValue().get("num");
if (StringUtils.isNotEmpty(value)) {
int num = Integer.parseInt(value + "");
redisTemplate.opsForValue().set("num", String.valueOf(++num));
}
// 5. 定义 lua 脚本,释放锁。保证判断 lockValue 一致 与删除 lockKey 的原子性
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// 设置返回值类型为 Long,防止结果判断错误
redisScript.setResultType(Long.class);
redisTemplate.execute(redisScript, Arrays.asList(lockKey), lockValue);
} else {
try {
Thread.sleep(1000);
tryLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
参考博客:https://blog.csdn.net/qq_46370017/article/details/126374547
2.2、Redis7 配置开启多线程
若应用中发现 Redis 实例 CPU 开销不大但吞吐量却没有提升,可以考虑开启多线程,加速网络处理,提升吞吐量。
## 默认多线程配置是关闭的,开启配置如下
vi redis.conf
## 开启多线程
io-thread-do-reads yes
## 设置多线程个数。建议:4核 建议 2-3,8核 建议 6。
io-threads 6
:wq
2.3、Redis 配置禁用命令
vi redis.conf
rename-command keys ""
rename-command flushdb ""
rename-command flushall ""
:wq
2.4、Redis 创建 MoreKey 测试数据命令脚本
## shell 脚本生成 批量 set 命令文件
for((i=1;i<=100*10000;i++)); do echo "set ksi v$i" >> /tmp/redisMoreKey.txt ;done;
## 使用 redis 管道命令 -pipe 将数据入库
cat /tmp/redisMoreKey.txt | /opt/redis/src/redis-cli -h 127.0.0.1 -p 6379 -a 269527 --pipe
## 查看库内 keys 总数量
redis-cli -h 127.0.0.1 -p 6379 -a 269527 dbsize
2.5、Redis 清理 bigkey Java代码
// TODO
2.6、数据库与缓存双写一致性实现方案
双检加锁策略
public User findUserByIds(Integer id){
User user = null;
String userKey = CACHE_KEY_USER + id;
if (user == null){
// 防止高 QPS 下 Redis 缓存击穿
synchronized (UserService.class){
user = (User) redisTemplate.opsForValue().get(key);
if(user == null){
user = userMapper.selectByPrimaryKey(id);
if (user == null){
return null;
}
redisTemplate.opsForValue().setIfAbsent(key, user, 7L, TimeUnit.DAYS);
}
}
}
return user;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号